Python Functions and Jupyter Notebook
Have you ever wondered how top data scientists manage to tackle complex projects with such ease? The answer often lies in their proficiency with two powerful tools: Python functions and Jupyter Notebook. These aren't just fancy tech terms―they're practical skills that can significantly enhance your data analysis workflow.
As a seasoned data scientist, I've seen firsthand how these tools of the trade can elevate your coding skills and transform your data projects. From automating tedious tasks to creating interactive, shareable analyses, these tools are essential for any data analyst looking to improve their workflow.
Python functions are reusable blocks of code that help you avoid repetition, keep your programs organized, and break down complex problems into manageable pieces. One of the most impressive aspects of functions is their ability to take inputs (arguments) and return outputs (return values).
Jupyter Notebook is the perfect companion to Python functions. This tool allows you to write code, run it, see the results, and then refine it―all in real-time. When working on just about any project, Jupyter Notebook is my go-to. I can test each of my custom functions individually, ensuring they work as expected before I add them to my main script. But it's not just ideal for testing―it's a powerhouse for data analysis too!
With Jupyter Notebook, you can combine code with explanatory text, creating a document that's part code, part narrative. This makes it easy to share your analysis with others, even if they're not coders themselves. You can run code in small chunks, create visualizations on the fly, and iterate on your ideas quickly.
In this tutorial, we'll explore how to create efficient, reusable code with Python functions and how to use Jupyter Notebook to develop interactive, shareable analyses. Whether you're just starting out in data science or looking to enhance your skills, mastering these tools can set you up for success.
First up on our list are Python functions. We'll start off with the basics: using built-in functions and then look at how you can create your own custom functions. As you gain more experience with them, you'll find that they become an indispensable part of your data science toolkit.
Lesson 1 – Using Built-in Functions and Creating Functions
When working with Python, you'll quickly realize that writing the same code over and over is a waste of your time. If you find yourself repeating code like the example below does, it's usually a sign that there's a better way:

Python Built-in Functions
Situations like these are where Python functions will come to your rescue―they're reusable tools that simplify your code and make it more maintainable. Let's start with built-in functions, the ready-made tools that Python provides.
Not a big surprise, but Python comes with a sum() function that can handle this calculation for us. It returns the sum of the items in an iterable (e.g., list, dictionary, tuple, set, etc.) containing numeric data. Here's an example of how we can use the sum() function to avoid having to repeatedly create a for loop to manually find the sum of the three lists above:

Notice how we went from 9 lines of code down to just 3! This is the beauty of functions―they abstract away the steps required to carry out an operation so you can focus on the bigger picture.
Creating Custom Functions
While built-in functions like sum() are powerful, you'll soon realize that Python doesn't have one for every situation. That's when creating your own functions might be necessary. Custom functions allow you to package up a set of operations, define them in a function, and then call the function as often as you'd like. This makes your code more efficient and easier to understand.
Let's say you regularly need to square numbers in your data analysis. Instead of writing the same calculation over and over, you can create a custom square() function instead:

Once the helper function above has been defined, you can call it again and again:
squared_6 = square(6)
squared_4 = square(4)
squared_9 = square(9)
print(squared_6)
print(squared_4)
print(squared_9)Running the code above produces the following output:
36
16
81The square() function takes a number, multiplies it by itself, and returns the result. Now you can easily square any number without rewriting the calculation each time. It might seem like a simple example, but imagine how useful this could be when you're working with complex calculations or data transformations that you need to apply repeatedly in your analysis.
I often use functions like this in my work at Dataquest. One time, when I was developing our course on large language models, I created a function to calculate the average completion rate for a set of prerequisite lessons. This made it much easier to see if our learners were ready for the new course I was developing and identify areas that needed improvement. Instead of writing out the calculation each time, I could simply call the function with different lesson sets as inputs.
Pro tip: If you find yourself writing the same code more than twice, it's probably a sign that you should turn it into a function. This saves you time and reduces the chance of errors creeping into your code.
Remember, functions are essential tools in data analysis. They help you break down complex problems into manageable pieces, make your code more readable, and allow you to reuse your work efficiently. In other words, functions make your code modular. As you continue to work with data, you'll likely find yourself creating more and more functions to handle specific tasks in your analysis workflow.
In the next lesson, we'll explore how to make your functions even more powerful by using arguments and parameters. We'll also discuss some debugging techniques that will help you troubleshoot when things don't go as planned. These skills will take your function-writing abilities to the next level, allowing you to create more flexible and robust code for your data analysis projects.
Lesson 2 – Arguments, Parameters, and Debugging
Now that we've covered the basics of Python functions, let's explore some concepts that can enhance them: function arguments, parameters, and debugging techniques. These tools can make your functions more flexible and powerful, and they're not as scary as they might seem at first.
Function Arguments and Parameters
These are the building blocks that enable you to create versatile, reusable functions. Here's an example function from a recent project I worked on:
def freq_table(data_set, index):
frequency_table = {}
for row in data_set[1:]: # slice the dataset to remove the header
key = row[index] # extract the key element
if key in frequency_table:
frequency_table[key] += 1
else:
frequency_table[key] = 1
return frequency_table
keyword_arguments = freq_table(data_set=apps_data, index=7)
positional_arguments = freq_table(apps_data, 7)In this function, data_set and index are parameters. They act like variables that the function can use in the body of the function to carry out operations. When we call the function, we pass in arguments that give these parameters specific values. In this case, we're passing the apps_data argument as the data_set parameter, and 7 (argument) as the index (parameter).
One of Python's strengths is its flexibility with argument passing when calling a function. You can use either keyword arguments (like specifically setting data_set=apps_data) or use positional arguments (like just passing apps_data in the appropriate position) when calling a function. Personally, I've found that keyword arguments make your code more readable, especially when dealing with functions that have multiple parameters. This approach has saved me from many headaches over time, particularly when revisiting code I wrote months ago.
Pro tip: I've noticed that many new learners get confused between the terms parameter and argument. Here's a simple way to remember the difference:
- Parameters are the placeholders defined in the function header and body.
- Arguments are the actual values you pass in when you call the function.
I know it can be a little confusing at first, but once you see it in action a few times, it starts to click. Here's a diagram to help you visualize the difference:

Combining Functions
This is where things get really fun! Take a look at this example of how we can use custom functions inside another custom function:
def find_sum(a_list):
a_sum = 0
for element in a_list:
a_sum += float(element)
return a_sum
def find_length(a_list):
length = 0
for element in a_list:
length += 1
return length
def mean(a_list):
sum_list = find_sum(a_list)
len_list = find_length(a_list)
mean_list = sum_list / len_list
return mean_list
list_1 = [10, 5, 15, 7, 23]
print(mean(list_1))Running this code will find the mean of list_1:
12.0Here, we're using two helper functions (find_sum and find_length) inside our mean function. This modular approach makes our code more organized and easier to maintain. It's like building with blocks―each function is a block that we can combine in different ways to create more complex structures.
I remember when I first started using this approach at Dataquest. We were analyzing student progress data, and I created separate functions for extracting data, calculating totals, and computing averages. By combining these functions, we were able to quickly generate insights about completion rates across different courses and topics. This modular approach made it easy to reuse code and adapt our analysis as new questions came up.
Debugging Functions
So, what happens when things go wrong? Debugging is an essential skill that you'll use often. Here's a technique I use regularly: adding well-placed print() statements inside functions to check what's happening at each step. For example:
def mean(a_list):
sum_list = find_sum(a_list)
print(f"Sum of list: {sum_list}")
len_list = find_length(a_list)
print(f"Length of list: {len_list}")
mean_list = sum_list / len_list
return mean_listThese print() statements help you see what's happening inside the function as it's being executed. If something's not working as expected, you can quickly identify where the problem is happening. I can't tell you how many times this simple technique has saved me hours of frustration when debugging complex functions.
In your own data projects, I encourage you to start by writing simple functions and gradually make them more complex. Use keyword arguments to make your code more readable, and don't hesitate to combine functions for more powerful operations. When something's not working as expected, add some print() statements to see what's going on inside your function.
Remember, the goal is to create code that's functional, modular, readable, and maintainable. By implementing these concepts, you'll be able to write more efficient, flexible code for your data analysis projects. In the next lesson, we'll explore how to further leverage built-in functions and how to work with multiple return statements to enhance your data science toolkit.
Lesson 3 – Built-in Functions and Multiple Return Statements
As we continue to expand our understanding of Python functions, I want to share two concepts that have made a huge difference in my data analysis work: leveraging built-in functions and using multiple return statements in custom functions. These tools have helped me write more efficient and flexible code, and I think they can do the same for you.
Built-in Functions
As mentioned earlier, these are the ready-made tools that Python provides right out of the box. In my daily work at Dataquest, I frequently use built-in functions like len(), sum(), max(), and min(). They're incredibly useful when working with datasets, saving you time and reducing the chance of errors in your code. For example, using len() to get the length of a list is much faster and more reliable than creating a custom function like the one we saw in the last lesson.
That said, I learned an important lesson early in my career about built-in functions; I once made the mistake of creating a custom function named sum() in one of my data analysis scripts. Although it was nothing like the example below, it proves my point just the same:
def sum(a_list):
return "This function doesn't really return the sum"
list_1 = [5, 10, 15, 7, 23]
print(sum(list_1))If you were to run the code above, it would produce the following output:
This function doesn't really return the sumAs you can see, this overwrote (or shadowed) the built-in sum() function. This led to some very confusing bugs in our analysis, and it took us a while to figure out what was going wrong. Since then, I've always been careful to use unique names for my custom functions. I highly recommend you do the same to avoid similar headaches in your projects. To ensure you're not shadowing a Python built-in function or keyword, you can quickly check for names to avoid using this code:
import builtins
print(dir(builtins))
import keyword
print(keyword.kwlist)This will output a list of all the Python built-in functions (e.g., print, type, sum, etc.) as well as a list of reserved keywords (e.g., if, True, return, etc.). Before defining a variable or function, you can manually check whether the name is already in the builtins module to avoid accidental shadowing using this handy function:
import builtins
def is_builtin(name):
return name in dir(builtins)
print(is_builtin('print')) # True, meaning 'print' is a built-in
print(is_builtin('my_function')) # False, meaning 'my_function' is not a built-inMultiple Return Statements
This feature of Python has been incredibly useful for me in creating flexible functions that can handle different scenarios.
As a thought experiment, how could you modify the code below so that we can get either the sum or the difference of two numbers, depending on which one we wanted?

Did you think of a solution? Here's an example of how it could be done:
def sum_or_difference(a, b, return_sum=True):
if return_sum:
return a + b
else:
return a - b
print(sum_or_difference(10, 5, return_sum=True))
print(sum_or_difference(10, 5, return_sum=False))Running the code above produces the following output:
15
5This function can either add or subtract two numbers based on the boolean return_sum parameter. While this is a simple example, it shows how flexible functions with multiple return statements can be. You can adapt this concept to create functions that perform different operations based on input parameters, making your code more versatile and reusable.
In my work at Dataquest, I've found multiple return statements particularly useful when dealing with complex data processing tasks. I once created a function that analyzed student progress data. Depending on the input parameters, it could return either a detailed breakdown of a student's performance or a high-level summary. This flexibility allowed us to use the same function for both in-depth analysis and quick overviews, significantly streamlining our code.
When you're using multiple return statements, I recommend structuring your function logically. Make sure each possible return is clear, and the function's behavior is predictable based on its inputs. This will make your code easier to understand and maintain, both for yourself and for others who might work with it.
Here are a few tips I've picked up for using multiple return statements effectively:
- Use them when you have distinct outcomes based on different conditions. This can make your functions more versatile and reduce the need for multiple similar functions.
- Keep the logic simple. If you find yourself with too many
returnstatements, it might be time to break the function into smaller parts. This helps maintain readability, modularity, and makes debugging your functions a lot easier. - Document your function clearly, explaining what it returns and under what conditions. This is especially important when the function can return different types of data.
- Consider using type hinting to make it clear what type of data the function will return. This can help prevent errors and make your code more self-documenting.
By taking advantage of built-in functions and using multiple return statements in your custom functions, you'll be well-equipped to handle a wide range of data analysis tasks. These techniques allow you to write more efficient, flexible code that can adapt to different scenarios.
So, take some time to experiment with these techniques in your own projects. Try refactoring some of your existing functions to use multiple return statements where it makes sense. You might be surprised at how much cleaner and more flexible your code becomes!
In the next lesson, we'll explore how to return multiple variables from a function and discuss the impact of function scopes, further expanding our Python toolbox for data analysis. These concepts will give you even more flexibility in how you structure your data processing functions, allowing you to return related pieces of information together in a more organized way.
Lesson 4 – Returning Multiple Variables and Function Scopes
First, let's discuss returning multiple variables. This feature of Python allows you to create functions that provide multiple values with a single call. Consider the following example:
def sum_and_difference(a, b):
a_sum = a + b
difference = a - b
return a_sum, difference
sum_diff = sum_and_difference(15, 5)
print(sum_diff)This code will output:
(20, 10)As you can see, we're getting two results stored in a tuple from a single function call. This can be incredibly useful when you need to perform multiple calculations or transformations on your data and want to return the results together. We can also take advantage of tuple unpacking so that these values are directly assigned to separate variables:
sum_result, diff_result = sum_and_difference(15, 5)
print(f"Sum: {sum_result}, Difference: {diff_result}")This code will output:
Sum: 20, Difference: 10I frequently use this technique when analyzing course performance. Sometimes I might want to know both the average score and the completion rate for a lesson. Instead of writing separate functions or making multiple function calls, I can get both values at once. This makes my code more efficient and keeps related information together, which can be very helpful when you're working with complex datasets.
Function Scopes
Understanding function scopes is another important concept that can help you write cleaner, more efficient code. Take a look at this interesting example:
def print_constant():
x = 3.14
print(x)
print_constant()
print(x)This code will output:
3.14
NameError: name 'x' is not definedYou might be surprised by that error. The variable x is defined inside the function, but it only exists within that function's local scope. Once the function is done, the variable is no longer accessible from the main program's global scope. This concept of local and global scopes is important for managing your variables and ensuring that your functions don't have unintended side effects on other parts of your code.
Now here's where it gets interesting! While the main program can't access the value of x inside the function, a function can access variables from the global scope. Here's an example of what I mean:

Now, some of you might be wondering: "What happens if I define variables in both the main program and in the function; which one will get used?" That's a great question and if you thought of it, you might be able to guess the answer: the local scope is always prioritized relative to the global scope.
If we define a_sum and length with different values within the local scope, Python uses those values, and we'll get a different result than what we see above. For example, if we define a_sum and length both in the main program and within the function definition, and we see that the local scope gets priority:

I learned this lesson the hard way a number of years ago. I was working on a script to track student progress through our SQL courses. I had a variable that was supposed to keep a running total of completed lessons inside my main program, but it kept resetting to zero. It turned out that I was initializing it to 0 inside a function I was using, assuming its value would persist from the main program. Once I understood how scopes work, I was able to fix my code and get an accurate count.
Understanding scopes isn't just about avoiding errors; it's also about writing more efficient code. For instance, when working with large datasets, I often use functions to process chunks of data. By keeping variables local to these functions, I can free up memory as soon as each chunk is processed. This can be a big performance boost when you're dealing with really large datasets that push the limits of your computer's memory.
Here are some tips about local vs. global scopes I've learned along the way:
- Use multiple return values when calculating related values. This approach makes your code more intuitive and saves you from writing extra functions. It's particularly useful in data analysis when you often need to return multiple statistics or processed datasets together.
- Be mindful of your variable scopes, especially in larger projects. It's easy to lose track of where things are defined, which can lead to unexpected behavior in your code.
- If you need a variable to be accessible outside a function, consider passing it as an argument and returning the modified value. This approach makes your function's behavior more explicit and can help prevent bugs related to global variables.
- When working with data, use local scopes to your advantage. They can help you manage memory more effectively, especially when dealing with large datasets. By keeping variables local to functions, you ensure they're cleaned up when the function finishes executing.
By understanding these concepts, you'll be able to write cleaner, more efficient code for your data analysis projects. You'll be able to create functions that return multiple related values, keeping your analysis organized and easy to understand. And by being mindful of scope, you'll avoid common pitfalls and write code that's more predictable and easier to debug.
In the next lesson, we'll explore how to apply these skills in Jupyter Notebook, a powerful tool for interactive data analysis. By combining these Python techniques with Jupyter Notebook, you'll be able to create dynamic, shareable analyses that can really bring your data to life. Get ready to take your data analysis skills to the next level!
Lesson 5 – Learn and Install Jupyter Notebook
Now that we have a good grip on Python functions, let's venture into the interactive world of Jupyter Notebook. This tool has revolutionized my approach to data analysis, and I'm excited to introduce you to it!
Jupyter Notebook is essentially a digital workspace for data scientists, allowing you to write and execute code in small segments, view results instantly, and integrate explanatory text. This combination makes it ideal for data experimentation, documenting your analysis process, and sharing insights with colleagues.
One aspect I really appreciate about Jupyter Notebook is its accessibility. I recommend installing it through the Anaconda distribution, which includes Python and a suite of other useful data science tools. You can download Anaconda from their official website and follow the installation guide for your specific operating system.
Once installed, you're ready to start coding. Here's a simple example of how you might use Jupyter for the first time:
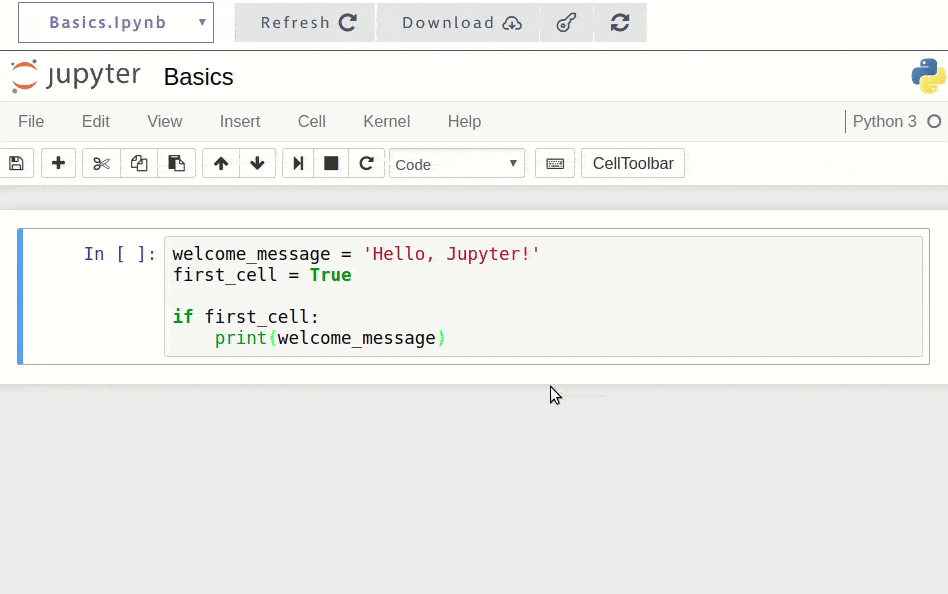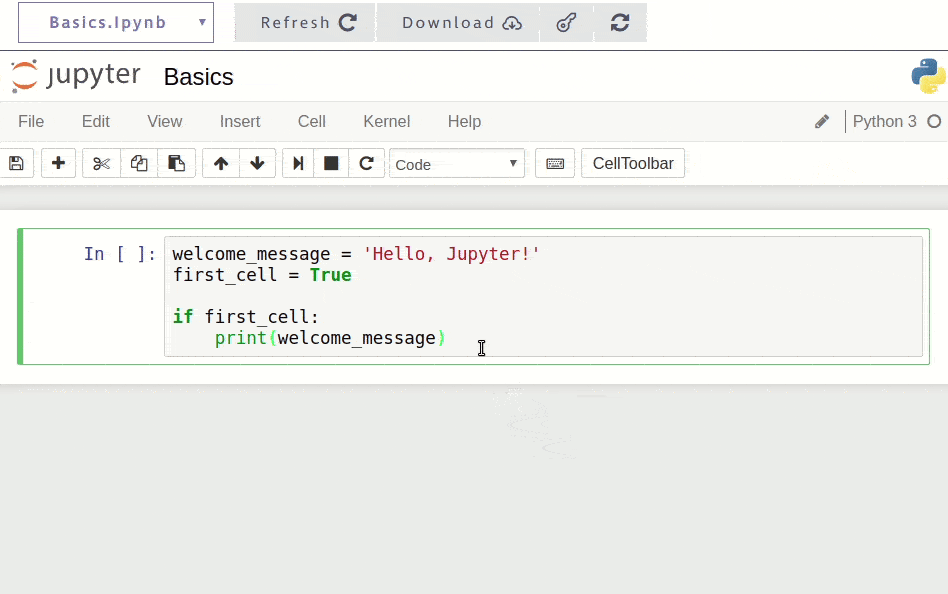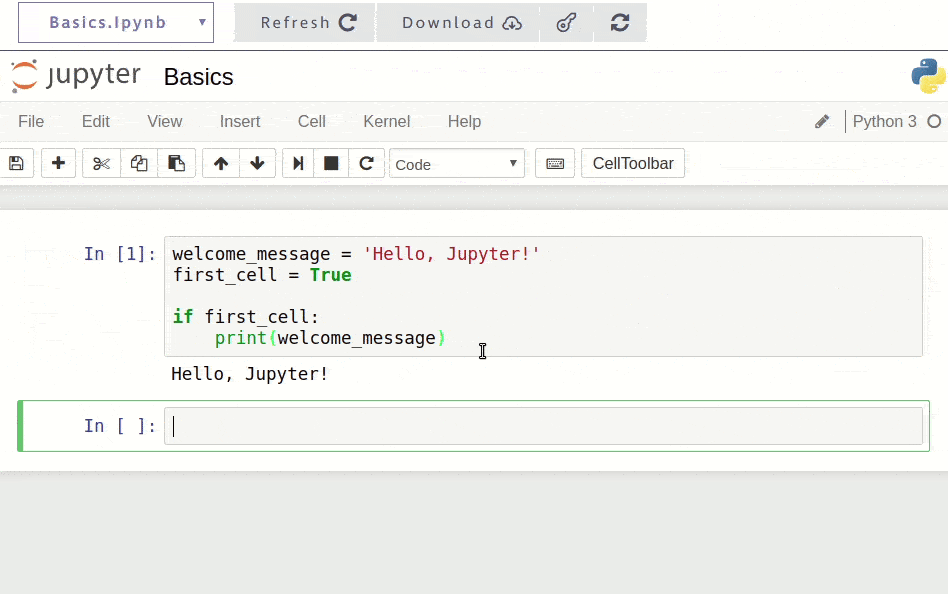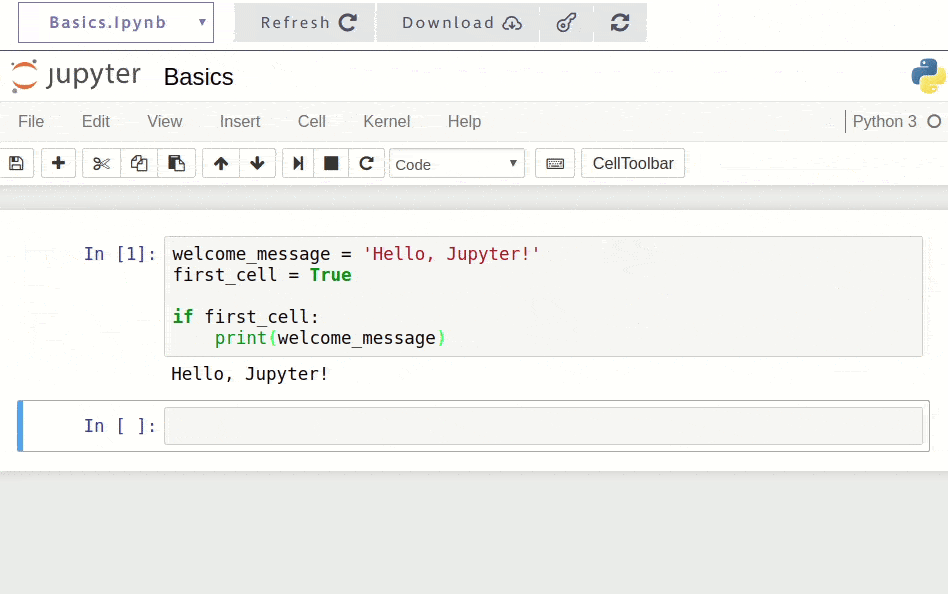
When you run this code in Jupyter (by pressing Shift + Enter), you'll see the output immediately below the cell: Hello, Jupyter!
This instant feedback is what I find so valuable about Jupyter for learning and experimentation. You can quickly test ideas and see results, which has helped me iterate on data analysis techniques much faster than before.
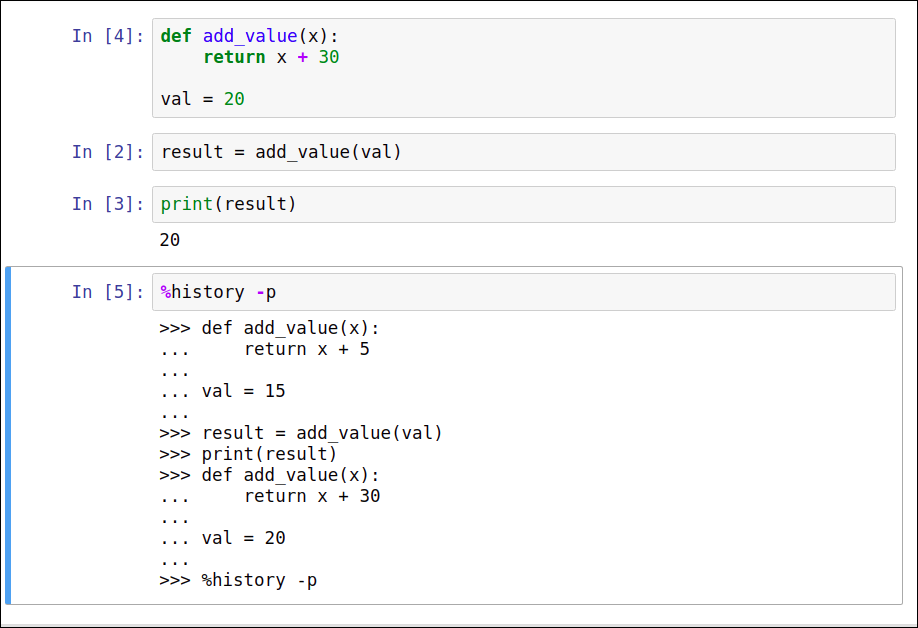
Jupyter also offers special features called 'magic commands'. One I use frequently is %history -p, which displays a history of the commands you've run:
%history -pThis command will output all of your previous code in the order in which it was executed:
>>> welcome_message = 'Hello, Jupyter!'
... first_cell = True
...
... if first_cell:
... print(welcome_message)
...
>>> %history -pI can't tell you how many times this command has saved me when I'm trying to recall a specific line of code I wrote earlier in a long analysis session but accidentally deleted it at some point. It's like having a record of your thought process as you work through a problem.
At Dataquest, Jupyter Notebook is an integral part of our workflow. When I'm developing new courses, I often start in Jupyter. When creating our advanced SQL course, I used Jupyter to experiment with different ways of explaining complex joins. I could write the SQL queries, execute them, and then add markdown cells with explanations and visualizations of the results. This allowed me to refine the course content iteratively, ensuring that each concept was explained clearly and backed up with practical examples.
If you're new to Jupyter Notebook, here's my advice: experiment freely. Try running various types of code, use markdown cells to add explanatory text, and explore the menu options. I've found that the more I use Jupyter, the more I discover its capabilities.
I recently learned about the %%timeit magic command, which has been incredibly useful for optimizing my code. When placed at the top of a code cell, this command runs your code multiple times and gives you the average execution time, helping you identify performance bottlenecks and compare different approaches efficiently. You can also use it on just a single line of code using %timeit, as this example demonstrates:
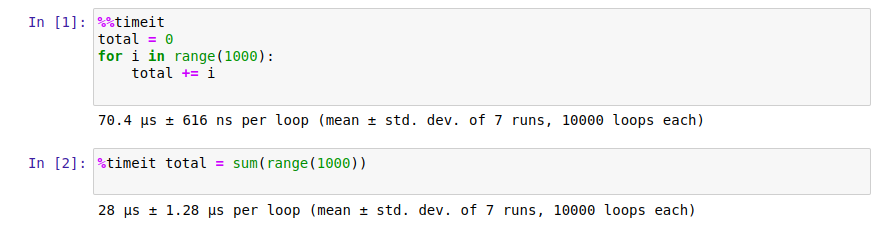
One of the most powerful features of Jupyter Notebook is its ability to combine code, text, and visualizations in a single document. This makes it an excellent tool for creating comprehensive, shareable reports of your data analysis. I often use this feature when presenting findings to our course development team. Instead of creating a separate PowerPoint presentation, I can walk them through my analysis step-by-step, showing the code, results, and my interpretation all in one place.
Pro tip: take advantage of Jupyter's ability to run code in any order. This non-linear execution can be really helpful when you're exploring data and want to try different approaches. Just be mindful of the state of your variables as you jump around―it's easy to lose track of what's been defined and what hasn't. This is another situation where the %history -p magic command can be really helpful:
As you get more comfortable with Jupyter Notebook, you might want to explore some of its more advanced features. For example, you can use cell tags to hide code cells in your final report, showing only the results and your explanations. This is great for creating polished reports for non-technical audiences.
In the final section of this tutorial, we'll bring together everything we've learned about Python functions and Jupyter Notebook in a guided project. You'll see firsthand how these tools can work in tandem to create an efficient and insightful data analysis workflow. We'll be analyzing app store data to identify profitable app profiles, a real-world scenario that will give you practical experience with these powerful tools.
Guided Project: Profitable App Profiles for the App Store and Google Play Markets
Let's put our Python skills into practice with a guided project. We'll analyze data from the App Store and Google Play to identify app profiles that are likely to attract more users. This project will show you how to apply data analysis concepts to real-world problems, and it's a great opportunity to see how Python functions and Jupyter Notebook can work together to create an efficient analysis workflow.
Our goal is to help our company develop free apps that generate revenue through in-app ads. The more users an app has, the more revenue it can generate. We'll use Python functions and Jupyter Notebook to analyze data from both app stores to find the types of apps that are popular in both markets.
Let's start by exploring our datasets. We'll use a function called explore_data() to get a quick look at our data:
def explore_data(dataset, start, end, rows_and_columns=False):
dataset_slice = dataset[start:end]
for row in dataset_slice:
print(row)
print('\n') # adds a new (empty) line after each row
if rows_and_columns:
print('Number of rows:', len(dataset))
print('Number of columns:', len(dataset[0]))This function is incredibly handy for getting a quick overview of our data's structure and content. Here's how we might use it:
explore_data(android, 0, 3, True)This would print the first three rows of our Android dataset and show us the total number of rows and columns. It's a simple yet effective way to start understanding our data.
Next, we'll need to create frequency tables to understand the distribution of app categories. Here's a function we'll use for that:
def freq_table(dataset, index):
table = {}
total = 0
for row in dataset:
total += 1
value = row[index]
if value in table:
table[value] += 1
else:
table[value] = 1
table_percentages = {}
for key in table:
percentage = (table[key] / total) * 100
table_percentages[key] = percentage
return table_percentagesThis function creates a frequency table for any column in our dataset, showing the percentage of apps in each category. We might use it like this:
genres = freq_table(android, 9)
for genre in genres:
print(genre, ':', genres[genre])This would print out the percentage of apps in each genre for our Android dataset. It's a powerful tool for identifying trends in our data. I've used similar functions countless times in my work, particularly when trying to understand the distribution of different features in a dataset.
Using these functions, we can quickly analyze our datasets and start to draw insights. For example, we might find that educational apps make up a significant portion of the App Store market but a smaller portion of the Google Play market. This could suggest an opportunity for educational app development on Google Play.
I've used similar techniques when developing our course on large language models at Dataquest. By analyzing the completion rates of different sections, we were able to identify areas where students were struggling. We found that the section on tokenization had a much lower completion rate than others. This insight led us to revamp that section, breaking it down into smaller, more digestible parts and adding more practical examples. After these changes, we saw a significant increase in the completion rate for that section.
As you work through this project, remember that the goal isn't just to analyze numbers, but to tell a story with your data. What trends do you see? What surprising insights have you uncovered? How might these findings influence app development strategies?
Here are some practical tips as you tackle this project:
- Start by cleaning your data. Look for any inconsistencies or missing values that might skew your analysis. Data cleaning is often the most time-consuming part of data analysis, but it's crucial for ensuring accurate results.
- Use the
explore_data()function to get familiar with your dataset before diving into deeper analysis. This will help you understand the structure of your data and spot any obvious issues. - Create frequency tables for different columns to understand the distribution of app categories, prices, and ratings. This will give you a good overview of the app landscape in each store.
- Compare the results between the App Store and Google Play. Look for similarities and differences. Are certain types of apps more popular on one platform than the other? This could reveal interesting market dynamics.
- Don't just look at the numbers―think about what they mean in the context of app development and user behavior. If you see a high number of gaming apps, consider whether this indicates market saturation or ongoing demand.
This project is a great opportunity to practice your skills and build something you can add to your portfolio. It demonstrates your ability to use Python functions for data analysis, work with real-world datasets, and derive actionable insights from your analysis.
Keep digging into the data; you might be surprised by some of the patterns you uncover. As a random example, you might find that apps with simple, clear names tend to have higher download rates across both platforms. You'll never know until you get your hands dirty with the data and look at it from as many angles as possible.
As you work through your analysis, don't be afraid to go beyond the basic requirements. If you see something interesting, go deeper. Maybe you'll notice a correlation between app size and user ratings, or perhaps you'll spot a trend in how app descriptions affect download rates. These kinds of insights can really make your analysis stand out.
Remember to leverage the power of Jupyter Notebook as you work. Use markdown cells to document your thought process and explain your findings. This not only helps others understand your work but also reinforces your own understanding of the analysis.
By completing this project, you're not just learning about app markets―you're developing a repeatable process for data analysis that you can apply to any dataset. You're learning to ask the right questions, clean and explore data effectively, and draw meaningful conclusions from your analysis.
Don't get discouraged if you run into challenges along the way. Debugging and problem-solving are key skills in data analysis. When I was working on my first big data project at Dataquest, I spent hours trying to figure out why my frequency table function wasn't working correctly. It turned out I had a small typo in my code. These experiences, frustrating as they can be, are valuable learning opportunities. Everyone, including myself, has been there―just keep going and you'll reap the rewards.
Pro tip: As you wrap up your analysis, think about how you would present your findings to a non-technical audience. What are the key takeaways? What recommendations would you make based on your analysis? This kind of thinking will help you translate your technical work into business value―a crucial skill for any data analyst.
Remember, the skills you're developing here―using Python functions, working with Jupyter Notebook, cleaning and analyzing data―are fundamental to data science and can be applied to a wide range of problems. Whether you're analyzing app markets, stock prices, or customer behavior, the process remains largely the same.
Advice from a Python Expert
As we've seen, Python functions and Jupyter Notebook are powerful tools that can significantly improve your data analysis workflow. By streamlining repetitive tasks and creating interactive, shareable analyses, these skills form the foundation of efficient and insightful data science work.
At Dataquest, we've seen how Python functions and Jupyter Notebook empower our students to tackle real-world challenges. Whether it's analyzing app market data to inform business strategies or cleaning large datasets for machine learning models, these powerful resources provide the flexibility and capabilities needed to derive meaningful insights from complex data.
One piece of advice I always give to aspiring data analysts is to practice regularly. The more you work with these tools, the more intuitive they become. Start with small projects and gradually increase their complexity. Don't be afraid to make mistakes―they're often the best learning opportunities. We've all been there, myself included. I remember spending hours debugging a function, only to realize I had a simple syntax error. Sure, I probably grew a few grey hairs because of it, but that experience taught me valuable debugging skills that I still use today.
Another tip I have for you is to always keep your end goal in mind. It's easy to get lost in the technical details, but remember that the purpose of data analysis is to derive actionable insights. When you're writing functions or authoring Jupyter notebooks, think about how your work will be used and interpreted by others. This mindset will help you create more effective, user-friendly analyses.
As you continue on your data science journey, I encourage you to keep experimenting with these resources. Each function you write and every analysis you conduct in Jupyter Notebook is an opportunity to refine your skills and deepen your understanding. If you're looking to further develop your expertise, you might find our Python Functions and Jupyter Notebook course helpful. It's designed to help you apply these concepts to real-world data projects.
Remember, becoming proficient in data science is a continuous process. Stay curious, embrace challenges, and don't be afraid to make mistakes―they often lead to the most valuable learning experiences. With these resources at your disposal, you'll be better prepared to tackle the challenges and opportunities in data science.
Keep pushing yourself to learn and grow. The field of data science is constantly evolving, and there's always something new to discover. Whether you're just starting out or you're a seasoned professional, there's always room to improve your skills and expand your knowledge. Who knows? The next function you write or Jupyter notebook you create could lead to a breakthrough insight that changes the way we understand data.
Good luck on your data science journey, and happy coding!
Frequently Asked Questions
What are the key advantages of using Python functions and Jupyter Notebook together for data analysis?
As a data scientist, I've found that using Python functions and Jupyter Notebook together makes my work more efficient and effective. Here's why this combination is so useful:
-
Interactive experimentation: Jupyter Notebook allows me to write and test Python functions in small, manageable chunks. This gives me instant feedback, which is especially helpful when I'm developing complex functions or exploring new datasets.
-
Comprehensive documentation: I can intersperse my Python functions with markdown cells containing explanatory text, creating a narrative around my analysis. This makes it easier for me to document my thought process and for others to understand my work.
-
Visual insights: Jupyter Notebook's ability to display visualizations alongside my Python functions is extremely helpful. I can create a function to process data, then immediately visualize the results in the next cell. This integration helps me spot patterns and trends more quickly.
-
Efficient workflow: The combination of Python functions and Jupyter Notebook streamlines my data analysis process. I can define reusable functions in one notebook cell and apply them to different datasets or scenarios in subsequent cells. This modularity saves time and reduces errors.
-
Shareable results: Jupyter Notebooks containing my Python functions, analysis, and visualizations are easy to share with colleagues. This has been particularly useful when I'm collaborating on projects or presenting findings to non-technical team members.
For example, when I did the project on analyzing app store data, I defined a function to quickly create frequency tables:
def freq_table(dataset, index):
table = {}
total = 0
for row in dataset:
total += 1
value = row[index]
if value in table:
table[value] += 1
else:
table[value] = 1
table_percentages = {}
for key in table:
percentage = (table[key] / total) * 100
table_percentages[key] = percentage
return table_percentagesI was able to use this function multiple times in my notebook to analyze different aspects of the data, adding explanations and visualizations between each analysis. This approach made my work more organized and easier to follow.
Overall, the combination of Python functions and Jupyter Notebook has been incredibly useful for a wide range of tasks I perform regularly, from analyzing course completion rates to identifying lesson screens that need my attention. It's a powerful combination that allows for flexible, iterative, and transparent data analysis.
How can custom Python functions improve code efficiency in data science projects?
Custom Python functions are a powerful tool for improving code efficiency in data science projects. By breaking down complex problems into manageable pieces, these reusable blocks of code help you avoid repetition, keep your programs organized, and make your analysis more efficient. When used with Jupyter Notebook, custom functions become even more effective for interactive data analysis.
One of the main advantages of using custom functions is the ability to automate repetitive tasks. For example, you can create a function to explore datasets or calculate frequency tables, which can be reused multiple times throughout your analysis without rewriting the code. This saves time, reduces the risk of errors, and makes your code more maintainable.
In Jupyter Notebook, you can define custom functions in one cell and use them across multiple cells, making your analysis more modular and easier to debug. For instance, you might create a function to clean data, another to perform calculations, and a third to visualize results. By combining these functions, you can create a streamlined workflow that's both efficient and easy to understand.
Here's a simple example of how a custom function can improve efficiency:
def explore_data(dataset, start, end, rows_and_columns=False):
dataset_slice = dataset[start:end]
for row in dataset_slice:
print(row)
print('\n') # adds a new (empty) line after each row
if rows_and_columns:
print('Number of rows:', len(dataset))
print('Number of columns:', len(dataset[0]))This function allows you to quickly examine different parts of your dataset without writing repetitive code. You can use it multiple times in your notebook to explore various datasets or different sections of the same dataset.
When creating custom functions, keep the following tips in mind:
- Use descriptive names for your functions to make your code more readable.
- Keep functions focused on a single task to improve modularity.
- Use parameters to make your functions more flexible and reusable.
- Include docstrings to explain what your function does and how to use it.
By incorporating custom functions into your data science projects, you can create more efficient, readable, and maintainable code. This enables you to focus on extracting insights from your data, rather than getting bogged down in repetitive coding tasks. As you become more comfortable using custom functions in Python and Jupyter Notebook, you'll find that your overall productivity as a data scientist improves.
What's the difference between function arguments and parameters in Python?
In Python programming, understanding the difference between function arguments and parameters is essential for writing effective code. When you define a function, you specify parameters, which are the variables that will receive values when the function is called. These parameters act as placeholders for the actual values that will be passed to the function.
To illustrate this concept, consider a frequency table function:
def freq_table(data_set, index):
frequency_table = {}
# Function body...In this function, data_set and index are parameters. When you call the function, you pass arguments, which are the actual values that correspond to the parameters. For example:
keyword_arguments = freq_table(data_set=apps_data, index=7)In this example, apps_data and 7 are arguments that correspond to the data_set and index parameters, respectively.
A helpful way to remember the difference between arguments and parameters is to think of it like this: parameters are defined in the function, while arguments are passed to the function.
Understanding this distinction can help you write more flexible and reusable functions, which is especially valuable when analyzing large datasets or creating complex data processing pipelines. In Jupyter Notebook, this understanding can also help you write cleaner, more modular code cells that are easy to modify and rerun as you explore different aspects of your data.
By grasping this concept, you'll be better equipped to write efficient Python code, avoid common errors related to function calls, and enhance your data analysis capabilities. Whether you're creating custom functions for data cleaning, analysis, or visualization, keeping this distinction in mind will help you write more effective and maintainable code.
How can you effectively debug Python functions when working on data analysis tasks?
When working on data analysis tasks, debugging Python functions is an essential part of ensuring accurate results. Here are some techniques that can help:
-
Add print statements strategically: I often insert print statements inside my functions to check variable values at different stages. This helps me see what's happening inside the function as it's being executed, making it easier to identify where things might be going wrong.
-
Understand function scopes: Knowing the difference between local and global scopes is vital. Variables defined inside a function are local and can't be accessed outside unless explicitly returned. This knowledge has saved me from many headaches when debugging complex functions.
-
Leverage Jupyter Notebook's cell-by-cell execution: I find Jupyter's cell-by-cell execution feature incredibly useful for testing individual parts of my functions. This allows for quick iterations and immediate feedback, which is invaluable when debugging data analysis code.
-
Verify function inputs and outputs: I always check that my functions are receiving the expected inputs and returning the correct outputs. This is especially important when working with complex data structures common in data analysis.
-
Use assertion statements: Adding assertion statements can be very helpful. They allow you to check if certain conditions are met and can catch errors early in your data processing pipeline.
Remember, debugging is a process that takes time and practice. Don't get discouraged if you don't find the issue immediately. With experience, you'll become more efficient at identifying and fixing bugs in your Python functions and Jupyter Notebook cells, leading to more robust and reliable data analyses.
Which built-in Python functions are commonly used for data analysis?
In my experience with data analysis, I've found that certain built-in Python functions are extremely useful. These functions are like versatile tools that can handle a variety of tasks efficiently.
The functions I rely on most often are:
sum(): For quickly calculating totalslen(): To count items in a datasetmax()andmin(): To find extreme values
These functions are particularly helpful when working with large datasets. For example, when analyzing app store data, I might use a combination of these functions to get a quick overview:
print('Number of apps:', len(dataset))
print('Highest rating:', max(app[7] for app in dataset[1:]))
print('Total reviews:', sum(int(app[5]) for app in dataset[1:]))This snippet gives me the number of apps, the highest rating, and the total number of reviews across all apps―all in just three lines of code!
What I appreciate about these built-in functions is how they simplify data analysis tasks. They're optimized for performance, which makes a big difference when working with massive datasets. Plus, they make your code more readable and less prone to errors compared to writing custom functions for every operation.
One important thing to keep in mind is to avoid accidentally overriding these built-in functions. I once created a custom function called sum() and couldn't figure out why my totals were off until I realized I had shadowed the built-in sum() function. Now, I always use unique names for my custom functions to avoid this pitfall.
By learning to use these built-in functions effectively, you'll be able to perform quick analyses and data summaries efficiently, allowing you to focus more on interpreting results and deriving insights. In data analysis, the goal is not just to crunch numbers, but to tell a compelling story with your data.
How can multiple return statements be used in Python functions for data processing?
Multiple return statements in Python functions offer a flexible way to handle different scenarios in data analysis. By allowing a function to return different values based on specific conditions, you can create more efficient code and simplify complex logic.
When processing data with Python functions, multiple return statements can be beneficial in several ways. For instance, they enable you to:
- Avoid unnecessary computations by exiting the function early
- Handle different cases or data types within a single function
- Provide clear exit points for complex logic
Consider this example function that can either add or subtract two numbers:
def sum_or_difference(a, b, return_sum=True):
if return_sum:
return a + b
else:
return a - bIn data processing, you can apply this concept to create functions that handle various data types or perform different calculations depending on the input. For example, you might create a function that returns different statistical measures (mean, median, or mode) based on the characteristics of the input data.
When using multiple return statements in your Python functions, keep the following tips in mind:
- Use them when you have distinct outcomes based on different conditions
- Keep the logic simple and easy to follow
- Document your function clearly, explaining what it returns and under what conditions
- Consider using type hinting to make it clear what type of data the function will return
Jupyter Notebook provides an excellent environment for developing and testing functions with multiple return statements. Its interactive nature allows you to quickly experiment with different inputs and see the results immediately, making it easier to refine your functions for various data processing scenarios.
By incorporating multiple return statements in your Python functions, you can create more flexible and efficient data processing workflows. This technique, when combined with the interactive capabilities of Jupyter Notebook, enables you to handle various scenarios within a single function, making your code more adaptable to different data analysis tasks.
Why is understanding function scope important when writing Python code for data analysis?
Understanding function scope is essential when writing Python code for data analysis because it affects how variables are accessed and manipulated within your programs. Proper use of function scope can significantly improve the efficiency and reliability of your analyses.
In Python, variables defined inside a function have a local scope, meaning they're only accessible within that function. This isolation is beneficial for data analysis because it prevents unintended modifications to variables and allows for more modular code. For example, when analyzing app store data, I created a function to calculate frequency tables:
def freq_table(dataset, index):
table = {}
total = 0
for row in dataset:
total += 1
value = row[index]
if value in table:
table[value] += 1
else:
table[value] = 1
# More code here...In this function, table and total are local variables. Their scope is limited to the function, ensuring they don't interfere with other parts of my analysis.
I've learned that understanding function scope helps avoid common pitfalls in data analysis. For instance, I once spent hours debugging a script because I accidentally used a global variable name inside a function, leading to unexpected results. Now, I'm careful to use parameters to pass data into functions and return values instead of modifying global variables.
When working in Jupyter Notebook, function scope becomes even more important. The interactive nature of notebooks means variables can persist across cells, potentially causing confusion if you're not mindful of scope. I always make sure to define my functions clearly and use them consistently throughout my analysis.
To effectively manage function scope in your data analysis code, follow these best practices:
- Keep functions focused on specific tasks
- Use parameters to pass data into functions
- Return values from functions instead of modifying global variables
- Use clear, descriptive variable names
By applying these principles, you can write more robust and efficient Python code for your data analysis projects. This, in turn, will lead to more reliable results and easier-to-maintain codebases, making your work as a data analyst more effective and efficient.
How do AI researchers typically use Jupyter Notebook in their work?
AI researchers often use Jupyter Notebook to enhance their work, leveraging its interactive nature and Python functions to streamline their research process. This powerful tool allows researchers to execute code, visualize results, and document their findings all in one place.
One of the primary ways AI researchers use Jupyter Notebook is for rapid prototyping and experimentation. They can write and execute Python functions in small chunks, immediately seeing the results. This iterative approach is essential in AI research, where small adjustments to model parameters or algorithms can significantly impact performance.
For example, a researcher might use custom Python functions to preprocess data, implement different model architectures, and evaluate results. They could define a function like this:
def evaluate_model(model, test_data):
# Evaluation code here
return accuracy, lossThen, they can easily call this function with different models and datasets, comparing results efficiently.
Jupyter Notebook's support for inline visualizations is another key feature for AI researchers. They can use Python libraries like matplotlib or seaborn to create complex graphs and charts, helping them gain insights more quickly and communicate findings effectively.
The combination of code, visualizations, and explanatory text in a single document makes Jupyter Notebook excellent for documenting research processes. Researchers can create comprehensive, reproducible records of their experiments, including the rationale behind certain decisions and the conclusions drawn from the data.
Collaboration is another area where Jupyter Notebook shines in AI research. Researchers can share their notebooks with colleagues, allowing for easy review and feedback. This is particularly valuable when tackling complex AI problems that require input from multiple experts.
In my experience developing advanced machine learning courses, I've found Jupyter Notebook invaluable for creating interactive tutorials on complex AI algorithms. The ability to combine explanatory text with executable Python functions allows learners to experiment with concepts in real-time, enhancing their understanding.
Overall, Jupyter Notebook serves as a versatile tool for AI researchers, supporting their need for interactive experimentation, clear documentation, effective visualization, and seamless collaboration. Its flexibility and integration with Python functions make it an essential part of many AI researchers' toolkits, enabling more efficient work and effective communication of findings.
What are the steps to install Jupyter Notebook on your computer?
Installing Jupyter Notebook is a straightforward process that sets you up to work with Python functions and data analysis. Here's how to do it:
-
Download Anaconda by visiting the official Anaconda website and selecting the version for your operating system.
-
Run the installer and follow the on-screen instructions. This will install Python, Jupyter Notebook, and other data science tools.
-
To launch Jupyter Notebook, open Anaconda Navigator and click on the Jupyter Notebook icon, or type 'jupyter notebook' in your command prompt or terminal.
-
In the Jupyter interface, click 'New' and select 'Python 3' to start a new notebook.
I recommend using Anaconda because it simplifies the installation process and manages package dependencies effectively. Once you've installed Jupyter Notebook, you can start exploring its features. For example, you can use the %history -p command to display your command history, which can be really helpful when you need to recall a specific line of code.
The best way to become comfortable with Jupyter Notebook and Python functions is to practice regularly. Don't be afraid to try new things―every new notebook is an opportunity to improve your data analysis skills.
How can you combine multiple Python functions for complex data operations in Jupyter Notebook?
As a data scientist, I've found that combining multiple Python functions for complex data operations in Jupyter Notebook can be a powerful way to streamline your workflow. Think of it like building with blocks―each function is a block that you can combine in different ways to create more complex structures.
In Jupyter Notebook, you can define functions in separate cells and then use them together to perform sophisticated analyses. For instance, let's say you're working on a project and you need to explore your data and create frequency tables. You can define two separate functions to do these tasks, and then combine them to create a more streamlined process.
Here's an example of how you might define these functions:
def explore_data(dataset, start, end, rows_and_columns=False):
dataset_slice = dataset[start:end]
for row in dataset_slice:
print(row)
print('\n')
if rows_and_columns:
print('Number of rows:', len(dataset))
print('Number of columns:', len(dataset[0]))
def freq_table(dataset, index):
table = {}
total = 0
for row in dataset:
total += 1
value = row[index]
if value in table:
table[value] += 1
else:
table[value] = 1
table_percentages = {}
for key in table:
percentage = (table[key] / total) * 100
table_percentages[key] = percentage
return table_percentagesYou can then combine these functions to explore your data and create frequency tables in just a couple of lines of code:
explore_data(android, 0, 3, True)
genres = freq_table(android, 9)
for genre in genres:
print(genre, ': ', genres[genre])This approach has several benefits. For one, it keeps your code organized and readable. You can also easily reuse and modify individual functions, which makes it simpler to debug your code. Additionally, complex operations become more manageable when you break them down into smaller, more focused functions.
When combining Python functions in Jupyter Notebook, here are some tips to keep in mind:
- Give your functions clear, descriptive names.
- Keep each function focused on a single task.
- Use comments or markdown cells to explain your thought process.
- Test your functions individually before combining them.
By following these tips, you can create more efficient and effective data analysis workflows. For example, I once used this approach to analyze course completion rates at Dataquest. By combining functions for data cleaning, analysis, and visualization, I was able to quickly identify areas for improvement and make changes that significantly boosted our completion rates.
By combining Python functions in Jupyter Notebook, you can tackle complex data analysis tasks with more ease and confidence. So don't be afraid to experiment with this approach in your next project―you might be surprised at how much it simplifies your workflow!
What is the timeit magic command in Jupyter Notebook and how can it improve your code?
timeit magic command in Jupyter Notebook and how can it improve your code?The timeit magic command in Jupyter Notebook is a valuable tool for optimizing your Python functions and improving code efficiency. By using timeit, you can measure the execution time of your code and identify areas for improvement.
To use timeit, simply add %%timeit at the top of a code cell to time the entire cell, or %timeit before a single line of code. For example:
%timeit sum(range(1000))This command runs the code multiple times and gives you the average execution time. This information can help you pinpoint where your code is slowing down and make targeted improvements.
I have found timeit to be particularly helpful when working with large datasets. By using timeit to compare different approaches, I can choose the most efficient method and improve the performance of my code.
One tip for using timeit effectively is to focus on specific parts of your code. This way, you can identify exactly where improvements can be made and make targeted changes.
By incorporating timeit into your Jupyter Notebook workflow, you can create more efficient Python functions and speed up your data analysis projects.