
Complete Guide to Data Cleaning in Python
A collection of tutorials, practice problems, cheat sheet, guided projects, and frequently asked questions.
This comprehensive guide offers everything you need for an introduction to data cleaning in Python with tutorials that build foundational skills, practice problem exercises to reinforce learning, a handy cheat sheet for quick reference, and projects that provide practice in real-world data science scenarios. The included FAQs address common challenges, making it an essential resource for anyone serious about learning Python for data science.
Data Cleaning Tutorials
The three tutorials summarized below will help support you on your journey to learning data cleaning in Python for data science. Check out the associated full tutorials for more details. If you're just starting out and want to actively learn these concepts directly in your browser, enroll in Dataquest's Data Analyst in Python career path for free.
1. Data Cleaning and Analysis in Python

Messy datasets with inconsistent formats, missing values, and duplicate entries often stand between analysts and meaningful insights. Converting temperatures between Celsius and Fahrenheit, standardizing date formats, or reconciling varying text entries can consume hours of valuable analysis time. Python's pandas library transforms these common data cleaning challenges into manageable tasks, allowing analysts to prepare their data efficiently and focus on extracting valuable insights.
Whether you're an analyst working with survey responses, a researcher processing experimental data, or a data scientist preparing datasets for machine learning models, understanding data cleaning techniques in Python will significantly improve your workflow. These essential skills enable you to handle real-world datasets confidently, automate repetitive cleaning tasks, and ensure your analyses are built on reliable, well-prepared data.
Data Cleaning and Analysis in Python — here's a breakdown of what this data cleaning tutorial teaches:
Lesson 1 – Data Aggregation
- Use
groupby()to summarize and understand dataset structure - Calculate statistics to identify patterns and potential issues
- Apply aggregation techniques to validate data quality
Lesson 2 – Combining Data Using Pandas
- Merge multiple datasets using
concat()andmerge()functions - Align data from different sources effectively
- Validate combined datasets for completeness and accuracy
Lesson 3 – Transforming Data with Pandas
- Convert data between formats using
map()andapply() - Standardize values across multiple columns
- Create consistent categories from numerical data
Lesson 4 – Working with Strings in Pandas
- Clean and standardize text data using string methods
- Extract relevant information from complex text fields
- Process text data efficiently with vectorized operations
Lesson 5 – Working With Missing and Duplicate Data
- Identify and handle missing values strategically
- Remove or fill gaps in datasets appropriately
- Detect and eliminate duplicate entries
Guided Project: Clean and Analyze Employee Exit Surveys
- Apply data cleaning techniques to real HR survey data
- Standardize response formats across multiple surveys
- Extract meaningful insights from cleaned survey responses
By learning these data cleaning techniques, you'll be equipped to handle complex datasets with confidence and efficiency. You'll be able to combine data from multiple sources, standardize inconsistent formats, handle missing values appropriately, and prepare clean datasets for analysis. These skills will enable you to spend less time wrestling with data quality issues and more time uncovering valuable insights that drive informed decision-making.
2. Advanced Data Cleaning in Python

Messy datasets with inconsistent formats, missing values, and non-standardized text can derail even the most sophisticated data analysis projects. Through practical experience at Dataquest and working with real-world data, these advanced Python techniques transform chaotic data into clean, analysis-ready datasets. From standardizing text with regular expressions to handling missing values intelligently, these methods significantly reduce the time spent on data preparation while improving analysis accuracy.
This tutorial is designed for data analysts and scientists who want to spend less time cleaning data and more time uncovering insights. Whether you're working with survey responses, customer data, or machine learning datasets, these advanced Python techniques will help you create efficient, reproducible data cleaning workflows that scale across projects and teams.
Advanced Data Cleaning in Python — here's a breakdown of what this data cleaning tutorial teaches:
Lesson 1: Regular Expression Basics
- Create flexible text patterns using the
remodule for standardizing inconsistent data - Use character classes and quantifiers to match variations in text data
- Apply the
re.search()andre.sub()functions for finding and replacing text patterns
Lesson 2: Advanced Regular Expressions
- Implement capture groups to extract specific components from complex text strings
- Use lookaround assertions for context-aware pattern matching
- Apply the
str.extract()method with regex patterns in pandas
Lesson 3: List Comprehensions and Lambda Functions
- Write concise list comprehensions to replace complex
forloops in data transformation - Create efficient lambda functions for one-off data operations
- Combine list comprehensions with regex patterns for powerful text processing
Lesson 4: Working with Missing Data
- Analyze missing data patterns using visualization techniques
- Apply context-appropriate strategies for handling missing values
- Use pandas methods like
fillna()andmask()to implement missing data solutions
By learning these advanced data cleaning techniques, you'll be able to handle complex data challenges with confidence and efficiency. You'll know how to standardize inconsistent text data using regular expressions, write concise and powerful data transformations with list comprehensions and lambda functions, and implement intelligent strategies for handling missing data. These skills will enable you to create robust, reproducible data cleaning workflows that prepare your data for accurate analysis while saving valuable time in your data science projects.
3. Data Cleaning Project Walk-Through
Messy data stands between analysts and meaningful insights. Missing values, inconsistent formats, and scattered information across multiple files prevent effective analysis and lead to unreliable conclusions. Through systematic data cleaning techniques, you can transform raw, messy datasets into reliable sources for analysis, revealing patterns and relationships that would otherwise remain hidden.
Whether you're an aspiring data scientist or current analyst, knowing some data cleaning techniques will significantly enhance your ability to work with real-world datasets. These skills are essential for anyone who needs to prepare data for analysis, create accurate visualizations, or build reliable machine learning models. Learning systematic approaches to data cleaning will help you tackle complex datasets with confidence and extract meaningful insights efficiently.
Data Cleaning Project Walk-Through — here's a breakdown of what this data cleaning tutorial teaches:
Lesson 1 - Data Cleaning Walk-through
- Load and examine multiple data files using
pandasfor initial assessment - Standardize identifiers and data formats across different sources
- Handle missing values and inconsistencies in raw data effectively
Lesson 2 - Data Cleaning Walk-through: Combining the Data
- Merge multiple datasets using appropriate join operations
- Validate combined data through row count verification
- Fill missing values using means and appropriate substitutions
Lesson 3 - Data Cleaning Walk-through: Analyzing and Visualizing the Data
- Calculate correlations between variables to identify relationships
- Create meaningful visualizations to validate cleaning steps
- Analyze patterns and trends in the cleaned dataset
Challenge: Cleaning Data
- Apply data cleaning techniques to a new dataset independently
- Handle complex data issues through systematic problem-solving
- Validate results using visualizations and statistical methods
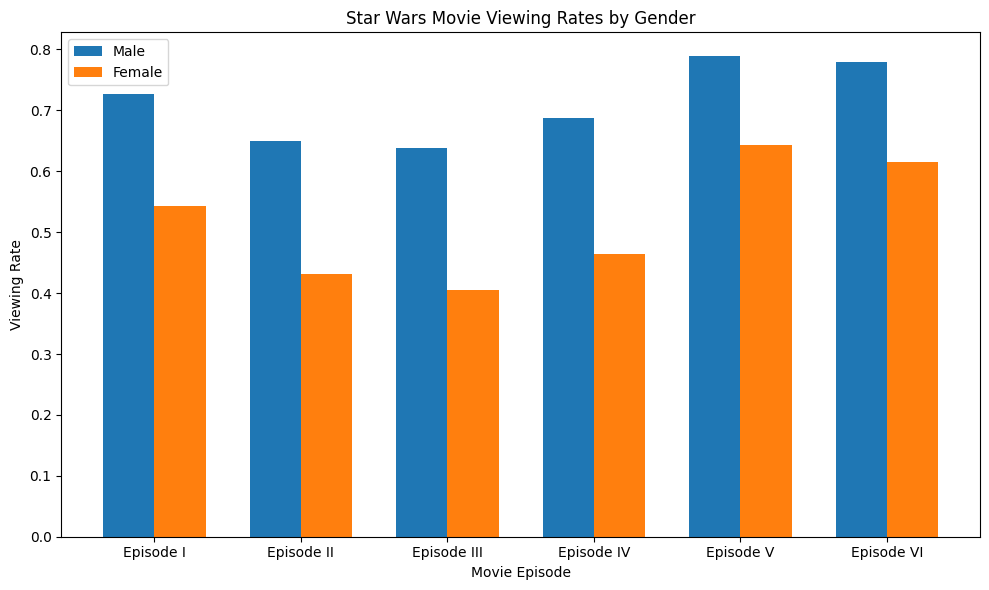
Guided Project: Star Wars Survey Analysis
- Clean and standardize survey response data
- Convert categorical responses into analyzable formats
- Create visualizations to communicate findings effectively
By learning these data cleaning techniques, you'll be equipped to handle complex, real-world datasets with confidence. You'll be able to load and examine multiple data sources, standardize formats, handle missing values, and combine information effectively. These skills will enable you to prepare reliable datasets for analysis, create accurate visualizations, and extract meaningful insights that drive informed decision-making in any data-focused role.
Data Cleaning Practice Problems
Test your knowledge with the data cleaning exercises below. For additional practice problems and real-time feedback, try our interactive coding environment, great for Python practice online.
1. Formating People Names
In this practice problem, you'll write a function to properly format the name of a person. The name is represented as a string containing the person's first and last names, separated by a space character. Here are some examples:
rachel Sprout
shayndel sibley
Gail sinclAIr
Ariel shimmy
These names are not all formatted in the same way. We want our function to transform the names so that all letters are in lowercase, except for the first letter in the first and last names:
Rachel Sprout
Shayndel Sibley
Gail Sinclair
Ariel Shimmy
To make all characters of a string uppercase, you can use the str.upper() method. Here’s an example:
name = 'Gail Sinclair'
name_in_uppercase = name.upper()
print(name_in_uppercase)
GAIL SINCLAIR
Instructions
- Write a function
clean_name()with the following argument:name: A string containing the first and last names of a person, separated by a space.
- Transform
nameso that:- The first character of each name is uppercase and the other characters are lowercase.
- Test your function on
test_nameand compare the result toexpected_answer.test_name = "AsIL sEnDo" expected_answer = "Asil Sendo"
Hint
- Use
str.split()to separate the first and last names. - Select the first character with
s[0]and the rest withs[1:].
Answer
def clean_name(name):
names = name.split()
firstname = names[0][0].upper() + names[0][1:].lower()
lastname = names[1][0].upper() + names[1][1:].lower()
return firstname + ' ' + lastname
# Test the function
test_name = "AsIL sEnDo"
expected_answer = "Asil Sendo"
print(clean_name(test_name) == expected_answer) # Should print True
Practice solving this data cleaning exercise using our interactive coding environment designed for Python practice online with real-time feedback.
2. Fixing a Music Playlist
Isn't it annoying when we play our favorite music album, but the songs do not play in order? Out of order playback can happen if we play the songs in alphabetical order. Imagine that we have an album with the following (made-up) songs:
1 - Thoughts Of Time
2 - Passion Of The Night
3 - Amused By Her Strength
4 - Get My Friends
5 - Broken Life
6 - Super Song
7 - Darling, Remember The Times
8 - Baby, You are Strange And I Like It
9 - She Said I Will Try
10 - In Love With You
12 - Hat Of The South
13 - Friends Of My Dreams
14 - Dream His Luck
Imagine that we open these songs in a music player that plays songs in alphabetical order. Then the first song that will play is 1 - Thoughts Of Time. However, the second song will be 10 - In Love With You because its name comes next in alphabetical order. The second song, 2 - Passion Of The Night, will only be played after song 14 - Dream His Luck is played.
We can fix this by changing the way we number the songs. If instead of using 1, 2, ..., 14 we use 01, 02, ..., 14 then this problem won't happen. For example, 1 - Thoughts Of Time would become 01 - Thoughts Of Time.
If we had 100 songs instead of 14, we would need to use three digits for each number instead. So 001, ..., 009, 101, 011, ..., 099, 100. For example, 1 - Thoughts Of Time would become 001 - Thoughts Of Time.
In this practice problem, you'll write a function, format_songs(), that takes as input a list of song names numbered from 1 to the number of songs (as above). The function should then format those names by adding the corrent number of zeros to the left of the names, based on the total number of songs.
For example:
songs = ["1 - Thoughts Of Time", "2 - Passion Of The Night", "3 - Amused By Her Strength", "4 - Get My Friends", "5 - Broken Life", "6 - Super Song", "7 - Darling, Remember The Times", "8 - Baby, You are Strange And I Like It", "9 - She Said I Will Try", "10 - In Love With You", "12 - Hat Of The South", "13 - Friends Of My Dreams", "14 - Dream His Luck"]
formatted_songs = format_songs(songs)
for song in formatted_songs:
print(song)
01 - Thoughts Of Time
02 - Passion Of The Night
03 - Amused By Her Strength
04 - Get My Friends
05 - Broken Life
06 - Super Song
07 - Darling, Remember The Times
08 - Baby, You are Strange And I Like It
09 - She Said I Will Try
10 - In Love With You
12 - Hat Of The South
13 - Friends Of My Dreams
14 - Dream His Luck
Instructions
- Write a function
format_songs()with the following argument:songs: A list containing song names. Each song's name starts with a number from 1 to the number of songs, as shown in the above examples.
- Implement the
format_songs()function so that it outputs a list of formatted song names. You must format those names by adding the corrent number of zeros to the left of the names, based on the total number of songs. - Execute your function on
test_songs. Compare the result toexpected_answerto ensure it gives the right answer.test_songs = [ "1 - Thoughts Of Time", "2 - Passion Of The Night", "3 - Amused By Her Strength", "4 - Get My Friends", "5 - Broken Life", "6 - Super Song", "7 - Darling, Remember The Times", "8 - Baby, You are Strange And I Like It", "9 - She Said I Will Try", "10 - In Love With You", "12 - Hat Of The South", "13 - Friends Of My Dreams", "14 - Dream His Luck"] expected_answer = ["01 - Thoughts Of Time", "02 - Passion Of The Night", "03 - Amused By Her Strength", "04 - Get My Friends", "05 - Broken Life", "06 - Super Song", "07 - Darling, Remember The Times", "08 - Baby, You are Strange And I Like It", "09 - She Said I Will Try", "10 - In Love With You", "12 - Hat Of The South", "13 - Friends Of My Dreams", "14 - Dream His Luck"]
Hint
- The total number of digits that each number should have is equal to
len(str(len(songs))). - You can create a string with
nzeros using'0' * n.
Answer
def format_songs(songs):
number_digits = len(str(len(songs)))
formatted_songs = []
for song in songs:
parts = song.split(" - ", 1)
number = parts[0]
title = parts[1]
padded_number = number.zfill(number_digits)
formatted_songs.append(f"{padded_number} - {title}")
return formatted_songs
# Test the function
test_songs = [
"1 - Thoughts Of Time", "2 - Passion Of The Night",
"3 - Amused By Her Strength", "4 - Get My Friends",
"5 - Broken Life", "6 - Super Song",
"7 - Darling, Remember The Times",
"8 - Baby, You are Strange And I Like It",
"9 - She Said I Will Try", "10 - In Love With You",
"12 - Hat Of The South", "13 - Friends Of My Dreams",
"14 - Dream His Luck"
]
expected_answer = [
"01 - Thoughts Of Time", "02 - Passion Of The Night",
"03 - Amused By Her Strength", "04 - Get My Friends",
"05 - Broken Life", "06 - Super Song",
"07 - Darling, Remember The Times",
"08 - Baby, You are Strange And I Like It",
"09 - She Said I Will Try", "10 - In Love With You",
"12 - Hat Of The South", "13 - Friends Of My Dreams",
"14 - Dream His Luck"
]
print(format_songs(test_songs) == expected_answer) # Should print True
Practice solving this data cleaning exercise using our interactive coding environment designed for Python practice online with real-time feedback.
3. Cleaning Messages
A spam filter is a machine learning algorithm that automatically detects whether a given message is spam or not. One of the steps to build a spam filter is to count the word frequencies in a message, that is, the number of times each word occurs in the message.
The word frequencies can be computed as a dictionary where each key is a word, and the value is the number of occurrences of that word in the message.
For example:
message = 'Free money! Get money for free by clicking this link. Get it right now.'
frequencies = {'free': 2, 'money': 2, 'get': 2, 'for': 1, 'by': 1, 'clicking': 1, 'this': 1, 'link': 1, 'right': 1, 'it': 1, 'now': 1}
One way to compute the above dictionary is to split the message and do a frequency table on the resulting word list. However, for it to work, we first need to clean the message by:
- Removing punctuation. For example
!,.,?, etc. If we didn't do this, in the above message, we would not count the wordmoneytwice because one occurrence appears asmoney!(note the exclamation mark) and the other asmoney. - Making the whole message lowercase. If we didn't do this we would not count
freetwice because one occurrence is written asFreeand the other asfree.
The string.punctuation property from the string module contains a list of all punctuation marks that we want to remove:
import string
print(string.punctuation)
!"#$%&'()*+,-./:;<=>?@[]^_`{|}~
You can set a string to lowercase using the str.lower() method:
message = 'Free money! Get money for free by clicking this link. Get it right now.'
print(message.lower())
free money! get money for free by clicking this link. get it right now.
Instructions
- Write a function
clean_message()with the following argument:message: A string containing the message we want to clean.
- Implement the
clean_message()function so that it outputs the string resulting from puttingmessagein lowercase and removing all punctuation characters from it. - Execute your function on
test_message. Compare the result toexpected_answerto ensure it gives the right answer.test_message = "WIN MONEY!!!! We Need YOUR Expert Opinion! EASY money. Click >HERE<" expected_answer = "win money we need your expert opinion easy money click here" print(clean_message(test_message) == expected_answer) # Should print True
Hint
- Use the
str.replace()method to delete all occurrences of a given character in a string. - You can iterate over all punctuation characters using a
forloop.
Answer
import string
def clean_message(text):
for char in string.punctuation:
text = text.replace(char, '')
return text.lower()
# Test the function
test_message = "WIN MONEY!!!! We Need YOUR Expert Opinion! EASY money. Click >HERE<"
expected_answer = "win money we need your expert opinion easy money click here"
print(clean_message(test_message) == expected_answer) # Should print True
Practice solving this data cleaning exercise using our interactive coding environment designed for Python practice online with real-time feedback.
Cheat Sheets
Data Cleaning Cheat Sheet
Check out our comprehensive Pandas Cheat Sheet that provides a quick reference for essential data cleaning commands. You can also download the Pandas Cheat Sheet as a PDF.
Regular Expressions Cheat Sheet
Check out our comprehensive Regular Expressions Cheat Sheet that provides a quick reference for essential pattern matching. You can also download the Regular Expressions Cheat Sheet as a PDF.
Data Cleaning Practice
The best way to get data cleaning practice is to work on a real world challenge in the form of projects. Use these Dataquest guided projects to test your skills and show off your knowledge to potential employeers by including them in your portfolio.
1. Clean and Analyze Employee Exit Surveys
Difficulty Level: Beginner
Overview
In this beginner-level data science project, you'll analyze employee exit surveys from the Department of Education, Training and Employment (DETE) and the Technical and Further Education (TAFE) institute in Queensland, Australia. Using Python and pandas, you'll clean messy data, combine datasets, and uncover insights into resignation patterns. You'll investigate factors such as years of service, age groups, and job dissatisfaction to understand why employees leave. This project offers hands-on experience in data cleaning and exploratory analysis, essential skills for aspiring data analysts.
Tools and Technologies
- Python
- Jupyter Notebook
- pandas
Prerequisites
To successfully complete this project, you should be familiar with data cleaning techniques in Python and have experience with:
- Basic pandas operations for data manipulation
- Handling missing data and data type conversions
- Merging and concatenating DataFrames
- Using string methods in pandas for text data cleaning
- Basic data analysis and aggregation techniques
Step-by-Step Instructions
- Load and explore the DETE and TAFE exit survey datasets
- Clean column names and handle missing values in both datasets
- Standardize and combine the "resignation reasons" columns
- Merge the DETE and TAFE datasets for unified analysis
- Analyze resignation reasons and their correlation with employee characteristics
Expected Outcomes
Upon completing this project, you'll have gained valuable skills and experience, including:
- Applying data cleaning techniques to prepare messy, real-world datasets
- Combining data from multiple sources using pandas merge and concatenate functions
- Creating new categories from existing data to facilitate analysis
- Conducting exploratory data analysis to uncover trends in employee resignations
Relevant Links and Resources
2. Analyzing NYC High School Data
Difficulty Level: Beginner
Overview
In this hands-on project, you'll take on the role of a data scientist analyzing relationships between student demographics and SAT scores at New York City public schools. Using Python, pandas, and Matplotlib, you'll clean and combine multiple datasets, create informative plots, and draw meaningful conclusions to determine if the SAT is a fair assessment. This project provides valuable experience in data analysis and visualization, allowing you to apply your skills to a real-world dataset and uncover insights into SAT score demographic trends.
Tools and Technologies
- Python
- Pandas
- Matplotlib
- Jupyter Notebook
Prerequisites
Before diving into this project, you should be comfortable with the following:
- Cleaning and preparing data using the pandas library
- Combining datasets using joins in pandas
- Computing summary statistics and correlations to analyze data
- Visualizing data using matplotlib to generate plots
Step-by-Step Instructions
- Explore the datasets to understand their structure and contents
- Clean and prepare the data by handling missing values and inconsistencies
- Combine datasets using joins to integrate demographic and SAT score data
- Compute summary statistics and correlations to analyze relationships
- Visualize the data using scatter plots, bar charts, and box plots
- Draw conclusions about the fairness of the SAT based on demographic factors
Expected Outcomes
Upon completing this project, you'll have gained practical experience and valuable skills, including:
- Applying data cleaning and preparation techniques to real-world datasets
- Analyzing relationships between variables using summary statistics and correlations
- Creating informative visualizations to communicate insights
- Interpreting analysis results to draw meaningful conclusions
- Evaluating the fairness of standardized tests using data analysis
Relevant Links and Resources
3. Star Wars Survey
Difficulty Level: Beginner
Overview
In this project designed for beginners, you'll become a data analyst exploring FiveThirtyEight's Star Wars survey data. Using Python and pandas, you'll clean messy data, map values, compute statistics, and analyze the data to uncover fan film preferences. By comparing results between demographic segments, you'll gain insights into how Star Wars fans differ in their opinions. This project provides hands-on practice with key data cleaning and analysis techniques essential for data analyst roles across industries.
Tools and Technologies
- Python
- Pandas
- Jupyter Notebook
Prerequisites
Before starting this project, you should be familiar with the following:
- Exploring and cleaning data using pandas
- Combining datasets and performing joins in pandas
- Applying functions over columns in pandas DataFrames
- Analyzing survey data using pandas
Step-by-Step Instructions
- Map Yes/No columns to Boolean values to standardize the data
- Convert checkbox columns to lists and get them into a consistent format
- Clean and rename the ranking columns to make them easier to analyze
- Identify the highest-ranked and most-viewed Star Wars films
- Analyze the data by key demographic segments like gender, age, and location
- Summarize your findings on fan preferences and differences between groups
Expected Outcomes
After completing this project, you will have gained:
- Experience cleaning and analyzing a real-world, messy dataset
- Hands-on practice with pandas data manipulation techniques
- Insights into the preferences and opinions of Star Wars fans
- An understanding of how to analyze survey data for business insights
Relevant Links and Resources
Python Frequently Asked Questions
What specific steps are included in data cleaning with Python?
When working with data in Python, it's essential to clean and prepare your datasets before analysis. Here's a step-by-step approach using pandas and other Python tools to help you get started:
- Initial Data Assessment: Start by loading your data using pandas and examining its structure with
info()andhead(). Check for missing values usingisnull()andsum(), and review data types to identify necessary conversions. Use basic statistics to spot potential outliers. - Standardize and Format: Clean up your column names using string methods, and convert data types with
astype()andto_datetime(). Standardize text data using string operations, and apply consistent formatting across similar fields. - Handle Missing Data: Analyze patterns using visualization techniques, and remove or fill gaps with
fillna()anddropna(). Use appropriate methods like mean, median, or mode imputation, and document your approach to missing value treatment. - Clean Text and Categories: Remove special characters and standardize case, fixing spelling variations and merging similar categories. Use regular expressions for pattern matching, and create consistent categorical variables.
- Combine Data Sources: Merge datasets using
concat()andmerge(), aligning data from different sources. Validate row counts after combining, and create calculated fields as needed. - Validate Results: Check summary statistics with
describe(), and create visualizations to verify cleaning steps. Ensure data consistency across all variables, and document your cleaning process.
Remember, data cleaning is an iterative process. You'll likely discover new issues as you work with your data, so keep your cleaning steps organized and documented to ensure reproducibility and maintain data quality throughout your analysis.
How do pandas functions streamline the data cleaning process?
Pandas functions make data cleaning more efficient and systematic by providing powerful tools to handle common cleaning tasks. With pandas, you can easily handle missing values, standardize formats, and combine datasets.
When working with real datasets, I've found that pandas functions save a significant amount of time compared to writing custom code. For example, I can quickly standardize column names, handle missing values, and merge datasets from different sources. This is particularly useful when cleaning survey data or combining information from multiple files.
Some key pandas functions that streamline data cleaning include fillna() and dropna() for handling missing values, astype() and to_datetime() for converting data types, merge() and concat() for combining datasets, map() and apply() for transforming data consistently, and string methods for cleaning and standardizing text data.
The benefits of using pandas functions for data cleaning are numerous. They provide consistent and reliable results across large datasets, optimize performance for handling big data, and include built-in data validation and error handling. This reduces the chance of errors compared to manual cleaning and results in clear, readable code that's easy to maintain.
By using pandas functions effectively, you can create more efficient and reliable data cleaning workflows. This allows you to spend less time on data preparation and more time on the analytical work that drives decision-making.
What are the most effective ways to handle missing values in pandas DataFrames?
When working with real-world datasets in Python, you'll often encounter missing values. These gaps in your data can be a challenge to address during the data cleaning process. To overcome this hurdle, it's essential to understand the scope of the problem and choose the right approach.
Here are some strategies to help you handle missing values:
- Identify Missing Values: Use the
isnull()andsum()functions to see how many missing values are in your DataFrame:df.isnull().sum()This will give you a clear picture of the problem and help you decide on the best course of action.
- Fill Missing Values: You have several options for filling missing values:
- Use
fillna()with a specific value - Apply mean, median, or mode imputation
- Employ forward or backward fill with
ffill()orbfill() - Implement more sophisticated imputation techniques
- Use
- Remove Missing Values: The
dropna()function removes rows or columns containing missing values. However, use this approach with caution, as it may result in losing valuable information.
To handle missing values effectively, follow these best practices:
- Examine the pattern of missing values before choosing a strategy
- Document your approach to missing value treatment
- Validate your results after handling missing values
- Consider the impact on your analysis
When choosing a missing value strategy, consider your specific context and data requirements. For example, when analyzing survey responses, you might use mean imputation for numerical fields but create a separate category for missing categorical responses. By selecting the right approach, you can preserve data integrity while maintaining analytical validity.
How can I use regular expressions to standardize text data in Python?
When working with text data in Python, regular expressions (regex) are an essential tool for cleaning and formatting text. By using regex patterns, you can systematically identify and replace inconsistent text formats, making your data more consistent and easier to analyze.
The Python re module provides several functions that make text standardization straightforward. For example, re.search() allows you to find patterns in text, while re.sub() enables you to replace matched patterns. Additionally, you can use str.extract() with regex patterns to process text in pandas.
Character classes are particularly useful for matching text variations. For instance, when cleaning survey responses or user feedback, you can use character classes to standardize inconsistent formats. Here's an example of a function that removes punctuation and standardizes case:
def clean_message(text):
for char in string.punctuation:
text = text.replace(char, '')
return text.lower()
This function takes a string as input, removes all punctuation, and converts the text to lowercase, making it more consistent for analysis.
When using regex for data cleaning in Python, here are some practical tips to keep in mind:
- Start with simple patterns and test them on small samples to ensure they work as expected.
- Use character classes to match flexible patterns and make your regex more efficient.
- Document your regex patterns so you can easily reuse them in the future.
- Validate your results after applying transformations to ensure the changes are correct.
By incorporating regex into your data cleaning workflow, you can efficiently transform inconsistent text data into standardized formats, making it easier to analyze and gain insights from your data.
What methods help identify and remove duplicate entries in datasets?
When working with real-world datasets, duplicate entries can lead to inaccurate conclusions. To maintain data quality, it's essential to learn how to identify and remove duplicates.
Let's start by examining your dataset's structure using pandas' info() and head() functions. This initial assessment will help you identify where duplicates might exist and how they could impact your analysis. You can use the duplicated() function to identify duplicate rows and value_counts() to reveal duplicate values in specific columns.
To remove duplicates effectively, follow these steps:
- Use
drop_duplicates()to eliminate duplicate rows. - Specify which columns determine uniqueness.
- Choose whether to keep first or last occurrences.
- Document your cleaning process.
- Validate your results using
describe()and summary statistics.
When handling duplicates, keep the following factors in mind:
Some duplicates might be legitimate data points, so be cautious when removing them. Additionally, removing duplicates can affect your dataset's size and statistics. Different columns may require different duplicate handling strategies, so it's essential to validate your results after removing duplicates.
By carefully examining your data before and after removing duplicates, you can ensure data integrity while effectively cleaning your dataset. Keep track of how many duplicates you remove and verify that the remaining data accurately represents your population of interest.
How do I combine multiple datasets while maintaining data integrity?
When you're working with multiple datasets in Python, it's essential to ensure that the data remains accurate and consistent. Based on my experience with complex datasets, I've developed a step-by-step approach to merging data and preserving its quality.
Step 1: Assess Your Data
Before combining datasets, it's essential to examine the structure and content of each dataset. You can use pandas' info() and head() functions to get a better understanding of the data. Check for missing values using isnull() and sum(), and review the data types to identify any necessary conversions. Document the number of rows in each dataset to ensure that everything adds up correctly.
Step 2: Standardize Your Data
To ensure that your datasets are consistent, you'll need to standardize the column names, data types, and formatting. Use string methods to clean up column names, and convert data types using astype() and to_datetime(). Standardize text data using string operations, and apply consistent formatting across similar fields.
Step3: Combine Your Datasets
To combine your datasets, follow these steps:
- Use the appropriate pandas functions (
concat()for appending,merge()for joining on common columns). - Validate the row counts after combining the datasets.
- Check for unexpected null values.
- Verify that the data types remain correct.
- Review summary statistics using
describe().
Testing your combinations on small subsets first can help identify potential issues early on. Additionally, keeping detailed documentation of your cleaning and combining steps ensures reproducibility and makes it easier to troubleshoot if problems arise.
By following these steps and maintaining rigorous validation throughout the process, you can successfully combine datasets while preserving their integrity and ensuring accurate analysis results.
What techniques help validate the accuracy of cleaned data?
When it comes to validating the accuracy of cleaned data, a systematic approach is key. This involves combining automated checks with manual verification to ensure your data is reliable.
First, calculate summary statistics to verify that your data is within expected bounds. Check that value ranges are correct, aggregated totals match control figures, distributions follow anticipated patterns, and key relationships between variables remain intact.
Next, perform targeted sample checks. Manually verify a random selection of records, focusing on critical data fields. Check edge cases and unusual values, and compare cleaned results to source data.
You can also use quantitative validation methods to verify your data. Compare record counts before and after cleaning, verify the percentage of missing values, and check the proportion of records in different categories. Additionally, validate calculated fields to ensure they match expected formulas.
It's essential to document your validation process. Record all validation steps performed, note any assumptions or special cases, and track issues found and how they were resolved. This will help you create reproducible validation procedures.
Keep in mind that validation is an iterative process. You may need to go through multiple validation-cleaning cycles until you're confident in your data quality. However, this investment pays off by preventing analysis errors and ensuring reliable results.
Best practices include validating early and often during the cleaning process, using multiple validation techniques, and maintaining detailed documentation of your validation findings and decisions.
How can I efficiently clean large datasets in Python?
When working with large datasets in Python, it's essential to be mindful of processing time and memory usage. Here's a step-by-step guide to help you clean large datasets effectively:
- Optimize Memory Usage First: To start, check your dataset's memory consumption using
df.info(memory_usage='deep'). This will help you identify areas where you can optimize memory usage. Next, convert columns to the most suitable data types usingastype(). For text columns with repeated values, consider using categorical data types. Finally, drop any unnecessary columns early on to save memory. - Process Data in Chunks: Large files can be processed in chunks using
pd.read_csv('file.csv', chunksize=10000). This approach allows you to clean each chunk independently and write the cleaned data to disk progressively. When combining the results, do so efficiently to avoid memory issues. - Use Efficient Functions: When cleaning your dataset, use vectorized operations instead of loops whenever possible. Pandas has built-in functions like
fillna(),dropna(), andreplace()that can speed up your cleaning process. Useapply()only when necessary, as it can be slower than vectorized operations. When possible, process specific columns rather than entire DataFrames to conserve memory. - Handle Missing Values Strategically: To handle missing values effectively, start by analyzing their patterns using
isnull().sum(). Then, fill missing values using the most suitable method, considering the memory impact of your approach. Document your method for treating missing values to ensure transparency and reproducibility. - Validate Throughout: As you clean your dataset, validate your results regularly. Check summary statistics after each major transformation, verify data types and unique values, and monitor memory usage during processing. Keep track of row counts to ensure data integrity. For optimal performance, focus on using pandas' built-in functions and avoid operations that create unnecessary copies of your data. Regular validation checks will help you maintain data quality while managing memory efficiently.
Remember to document your cleaning steps and decisions to make your process reproducible and maintainable. By following these steps, you'll be able to handle large datasets effectively while maintaining data quality throughout the cleaning process.
What are practical ways to handle inconsistent date formats in Python?
When working with real-world datasets, inconsistent date formats can be a common obstacle. To overcome this challenge, I rely on pandas' to_datetime() function as my primary tool. This function is highly flexible and can automatically parse many date formats without explicit formatting instructions. For example, when dealing with dates in specific formats, I specify the format parameter - such as '%m/%d/%Y' for MM/DD/YYYY dates or '%d-%m-%y' for DD-MM-YY formats.
Before converting dates, I always clean the data by removing extra whitespace, standardizing separators (like replacing various separators with a consistent one), handling missing values appropriately, and checking for obvious errors like dates far in the future or past.
When working with dates, it's essential to anticipate and manage potential errors. I typically use errors='coerce' in to_datetime() to convert invalid dates to NaT (Not a Time), which helps me identify problematic entries. This approach allows me to focus my cleaning efforts on the specific areas that need attention.
After conversion, I validate my results by checking for NaT values to identify any failed conversions, verifying that date ranges make logical sense, and confirming that the resulting dates match my expected format.
One helpful tip I've learned is to document my date standardization process and assumptions thoroughly. This makes my work reproducible and helps others understand my cleaning decisions.
How do I document my data cleaning process for reproducibility?
Documenting your data cleaning process is essential for reproducibility and collaboration. By keeping clear records, you can track changes, validate results, and share your work effectively with others. Here's how I approach documentation:
- Keep a Detailed Cleaning Log: When I start working with a new dataset, I create a log to document my progress. This log includes:
- My initial assessment of the data
- All transformations and changes I make
- The reasoning behind each cleaning decision
- Any assumptions or special cases I encounter
- Row counts before and after each major change
- Document Your Code: I add clear comments to my code to explain each cleaning step. This includes:
- Function docstrings that describe inputs and outputs
- Notes on dependencies and package versions
- Parameters or thresholds used
- External data sources
By documenting my code, I can ensure that others can understand my process and reproduce my results.
- Track Data Quality Metrics: I also track metrics that help me understand the quality of my data. This includes:
- Patterns of missing values
- How I identify and handle outliers
- Data type conversions
- Validation checks and results
- Any unexpected values or anomalies
By tracking these metrics, I can identify potential issues and address them early on.
- Use Jupyter Notebooks Effectively: I use Jupyter Notebooks to combine my code, documentation, and outputs. This helps me to:
- Explain my methodology in markdown cells
- Add visualizations to validate cleaning steps
- Keep intermediate results for verification
- Structure my notebooks in a logical, step-by-step flow
- Implement Version Control: Finally, I use version control to track changes to my cleaning scripts. This includes:
- Documenting different versions of cleaned datasets
- Noting when and why changes were made
- Keeping a changelog of major updates
- Storing backup copies of raw data
By implementing version control, I can ensure that my data cleaning process is reproducible and transparent.
By following these documentation practices, you can create reliable, reproducible data cleaning workflows that can be shared with colleagues and verified by others. This approach has helped me maintain consistency and catch potential issues early in the cleaning process.
What visualization techniques help identify data quality issues?
When working with data, it's easy to overlook errors or inconsistencies. Visual inspection can be a valuable tool in identifying these issues. By creating targeted visualizations, you can quickly spot patterns, outliers, and inconsistencies that might be missed when looking at raw numbers alone.
Here are some effective visualization techniques for identifying data quality issues:
- Missing Value Heatmaps
- These heatmaps reveal patterns of missing data across your dataset.
- They help you determine if values are missing randomly or systematically.
- They also show potential relationships between missing values in different columns.
- Distribution Plots (Histograms and Box Plots)
- These plots help you identify outliers and impossible values.
- They reveal unexpected patterns, such as negative ages or unrealistic measurements.
- They also show data entry errors through unusual spikes or gaps.
- Correlation Matrices
- These matrices highlight unexpected relationships between variables.
- They help you identify redundant or inconsistent data.
- They also reveal potential data entry or processing errors.
- Time Series Plots
- These plots show gaps in temporal data.
- They help you identify sudden value jumps that may indicate errors.
- They also reveal seasonal patterns that should (or shouldn't) exist.
When using these visualizations, look for:
- Unexpected patterns or symmetries that might indicate errors
- Outliers that fall outside reasonable bounds
- Inconsistent distributions across similar groups
- Sudden changes or discontinuities in time series
To get the most out of visualization in your data quality assessment:
- Start with broad overview plots to identify major issues
- Zoom in on suspicious patterns with more detailed visualizations
- Cross-validate findings using multiple visualization types
- Document patterns that indicate potential quality issues
Remember that visualization is just one tool in your data quality toolkit. Always validate visual findings with domain knowledge and statistical tests to ensure an accurate assessment of your data's quality.
How can I automate common data cleaning tasks in Python?
When working with data in Python, you'll often find yourself performing the same cleaning tasks over and over. Fortunately, Python provides several powerful tools that can help you automate these tasks and make your workflow more efficient.
By using pandas functions and built-in methods, you can create a systematic approach to handling common cleaning challenges. For example, you can use the fillna() and dropna() methods to handle missing values consistently. You can also use astype() and to_datetime() to standardize data types, and leverage string methods to clean text data. Additionally, you can use merge() and concat() to combine datasets efficiently, and implement map() and apply() for consistent data transformations.
To get the most out of your automation, it's a good idea to keep your functions focused on specific tasks, such as standardizing column names or handling missing values. This will make it easier to test and debug your code. You should also validate your results after each transformation using info() and describe(), and document your cleaning steps and assumptions thoroughly. By testing your automation on small data samples before scaling, you can ensure that it works as expected. Finally, be sure to include error handling for unexpected data patterns.
Once you've automated your cleaning tasks, it's essential to validate your cleaned data to ensure that it's accurate and consistent. You can do this by checking summary statistics, creating visualizations, and verifying data consistency across variables. By following these steps, you can create reliable and reproducible data cleaning workflows that will save you time and effort in the long run.
By implementing these automation techniques and following good documentation practices, you can create efficient and effective data cleaning workflows that will serve you well in your data analysis projects.
What strategies help maintain data consistency during cleaning?
When working with data, it's essential to maintain consistency to ensure reliable analysis results. To achieve this, I've developed several strategies that help keep data consistent throughout the cleaning process.
- Standardize from the start: Begin by standardizing column names, data types, and formats. For example, when analyzing course completion data, I ensure all percentage values are stored as floats and dates follow a consistent format. I use pandas functions like
astype()for data type conversion andto_datetime()for dates. - Create reusable functions: Developing custom functions for common cleaning tasks helps ensure consistent treatment across similar data. This approach not only saves time but also reduces errors. For instance, a function that standardizes text data should handle capitalization, special characters, and formatting in the same way every time.
- Validate results systematically: After each transformation, I validate results using pandas'
describe()function and visualization techniques. This helps catch unexpected changes early. I also compare row counts before and after cleaning steps to ensure no data is accidentally lost. - Handle missing values consistently: When working with gaps in data, it's essential to document your approach and apply it systematically. If you decide to fill missing values with means for numerical data, maintain this strategy throughout similar variables in the dataset.
- Monitor data types: Regularly check data types using
info()to ensure they haven't changed unexpectedly during cleaning. This is particularly important when working with dates, numerical values, and categorical data.
By following these strategies and validating results throughout the process, you can maintain data consistency while cleaning. This systematic approach helps ensure your analysis is built on reliable, well-prepared data.
How do I handle outliers during the data cleaning process?
When cleaning data in Python, handling outliers effectively requires a combination of technical skills and a deep understanding of your data. Here's my approach:
First, I use summary statistics and visualizations to identify potential outliers. The pandas describe() function provides key metrics like mean, standard deviation, and quartiles that help spot unusual values. For example, I might create a histogram or box plot to visualize the distribution of my data and get a sense of where the outliers might be hiding.
To systematically detect outliers, I typically use one of the following methods:
- I calculate z-scores to identify values that are more than 3 standard deviations from the mean.
- I use the Interquartile Range (IQR) method to flag values that are beyond 1.5 times the IQR.
- I apply domain-specific thresholds based on business rules or expert knowledge.
When it comes to treating outliers, I consider several options. I might remove clear errors while documenting what was removed and why. Alternatively, I might cap extreme values at reasonable thresholds, a process known as winsorization. In some cases, I might create separate categories for legitimate but unusual values. Finally, I might transform the data to handle skewed distributions.
Before making any changes, I always take a step back to validate my approach. I compare summary statistics before and after outlier treatment to ensure that my changes make sense within the business context. I also verify that my decisions are well-reasoned and document my thought process for handling each type of outlier. This helps me avoid removing valuable information that might be hidden in the outliers. By taking a thoughtful and systematic approach to handling outliers, I can ensure that my data is accurate and reliable.