This comprehensive guide offers everything you need for an introduction to NumPy, pandas, and data visualization with tutorials that build foundational skills, practice problem exercises to reinforce learning, handy cheat sheets for quick reference, and projects that provide practice in real-world data science scenarios. The included FAQs address common challenges, making it an essential resource for anyone serious about learning Python for data science.
Tutorials
The three tutorials summarized below will help support you on your journey to learning NumPy, pandas, and data visualization for data science. Check out the associated full tutorials for more details. If you're just starting out and want to actively learn these concepts directly in your browser, enroll in Dataquest's Data Analyst in Python career path for free.
1. Introduction to NumPy and pandas for Data Analysis
Have you ever found yourself struggling with slow data processing or complex calculations when working with large datasets in Python? NumPy and pandas are powerful libraries that can help you overcome these challenges. By learning these tools, you can significantly speed up your data analysis tasks, handle large datasets with ease, and perform complex operations efficiently. Whether you're dealing with financial data, scientific measurements, or any other type of structured data, NumPy and pandas provide the capabilities you need to extract meaningful insights quickly and accurately.
If you're an aspiring data scientist, analyst, or anyone who works with data in Python, mastering NumPy and pandas is essential for taking your skills to the next level. These libraries form the foundation of many data science and machine learning workflows, enabling you to manipulate, analyze, and visualize data with greater ease and efficiency. By investing time in learning these tools, you'll be better equipped to handle real-world data challenges and make data-driven decisions in your projects or career.
Introduction to NumPy and pandas for Data Analysis — here's a breakdown of what this NumPy and pandas tutorial teaches:
Lesson 1 – Introduction to NumPy
- Create and manipulate
ndarrayobjects for efficient numerical operations - Utilize vectorized operations to perform calculations on entire arrays at once
- Understand the performance benefits of NumPy over standard Python lists
Lesson 2 – Boolean Indexing with NumPy
- Apply Boolean indexing to filter data based on specific conditions
- Combine multiple conditions for complex data selection
- Use Boolean arrays to perform element-wise operations on datasets
Lesson 3 – Introduction to pandas
- Create and manipulate
DataFrameandSeriesobjects for structured data analysis - Understand the relationship between pandas and NumPy data structures
- Load data from CSV files into pandas
DataFrameobjects
Lesson 4 – Exploring Data with pandas: Fundamentals
- Use
info()anddescribe()methods to gain quick insights into datasets - Perform basic statistical operations on
DataFramecolumns - Apply efficient data operations using pandas methods
Lesson 5 – Exploring Data with pandas: Intermediate
- Utilize
ilocfor advanced data selection based on integer positions - Apply index alignment for efficient data manipulation across different datasets
- Use complex filtering and sorting techniques to extract specific insights
Lesson 6 – Data Cleaning Basics
- Implement techniques for cleaning and standardizing column names
- Convert data types and handle missing values in datasets
- Apply string methods for data cleaning and transformation
Guided Project: Exploring eBay Car Sales Data
- Apply NumPy and pandas skills to analyze a real-world dataset of used car listings
- Clean and preprocess data to ensure accuracy in analysis
- Create visualizations to uncover insights and identify data quality issues
By learning NumPy and pandas for data analysis, you'll be equipped with powerful tools to handle large datasets efficiently, perform complex calculations quickly, and extract meaningful insights from your data. These skills will enable you to tackle real-world data challenges with confidence, whether you're analyzing financial trends, processing scientific data, or developing machine learning models. You'll be able to clean and preprocess data more effectively, create insightful visualizations, and make data-driven decisions in your projects or career. With these foundational skills in place, you'll be well-prepared to advance your data science capabilities and take on more sophisticated analysis tasks.
2. Introduction to Data Visualization in Python
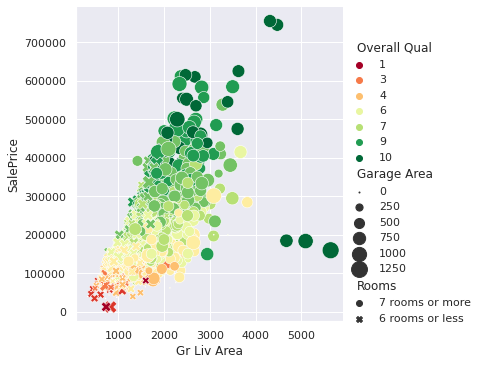
Raw numbers often conceal valuable insights within datasets. Data visualization transforms these numbers into compelling visual narratives, revealing patterns and trends that might otherwise remain hidden. By creating simple time series graphs, seasonal trends will emerge from the raw data. Data visualization can transform our understanding and improve the accuracy of our analyses.
Learning data visualization is essential for anyone working with data, from analysts and scientists to business professionals. As data continues to grow in volume and complexity, the ability to create clear, insightful visualizations has become a highly sought-after skill. Employers value candidates who can effectively communicate insights through visuals, not just crunch numbers. Whether you're looking to enhance your current role or transition into a data-focused career, mastering data visualization techniques will set you apart in the job market and enable you to make more informed decisions based on your data.
Introduction to Data Visualization in Python — here's a breakdown of what this data visualization tutorial teaches:
Lesson 1 – Line Graphs and Time Series
- Create line graphs using
matplotlib.pyplotto visualize trends over time - Customize plot elements such as titles, labels, and formatting
- Compare multiple time series on a single graph to identify patterns and relationships
Lesson 2 – Scatter Plots and Correlations
- Generate scatter plots to explore relationships between two variables
- Calculate and interpret Pearson's correlation coefficient
- Understand the distinction between correlation and causation in data analysis
Lesson 3 – Bar Plots, Histograms, and Distributions
- Create bar plots to compare values across different categories
- Use histograms to visualize the distribution of numerical data
- Identify and interpret common distribution patterns (e.g., normal, uniform, skewed)
Lesson 4 – pandas Visualizations and Grid Charts
- Utilize pandas' built-in plotting functions for quick data exploration
- Create grid charts (small multiples) to compare multiple related graphs
- Apply data cleaning techniques to prepare datasets for visualization
Lesson 5 – Relational Plots and Multiple Variables
- Use seaborn's
relplot()function to create multi-variable visualizations - Represent additional variables using color, size, and shape in scatter plots
- Interpret complex relationships between multiple variables in a single plot
By learning these data visualization techniques, you'll be able to create compelling visual narratives that reveal hidden patterns and insights in your data. You'll gain proficiency in using popular Python libraries like matplotlib, seaborn, and pandas to create a wide range of visualizations, from simple line graphs to complex multi-variable plots. These skills will enable you to effectively communicate your findings to both technical and non-technical audiences, making you a valuable asset in any data-driven organization. Whether you're analyzing financial trends, exploring scientific data, or optimizing business processes, the ability to create insightful visualizations will enhance your decision-making capabilities and open up new opportunities in the field of data science.
3. Telling Stories Using Data Visualization and Information Design
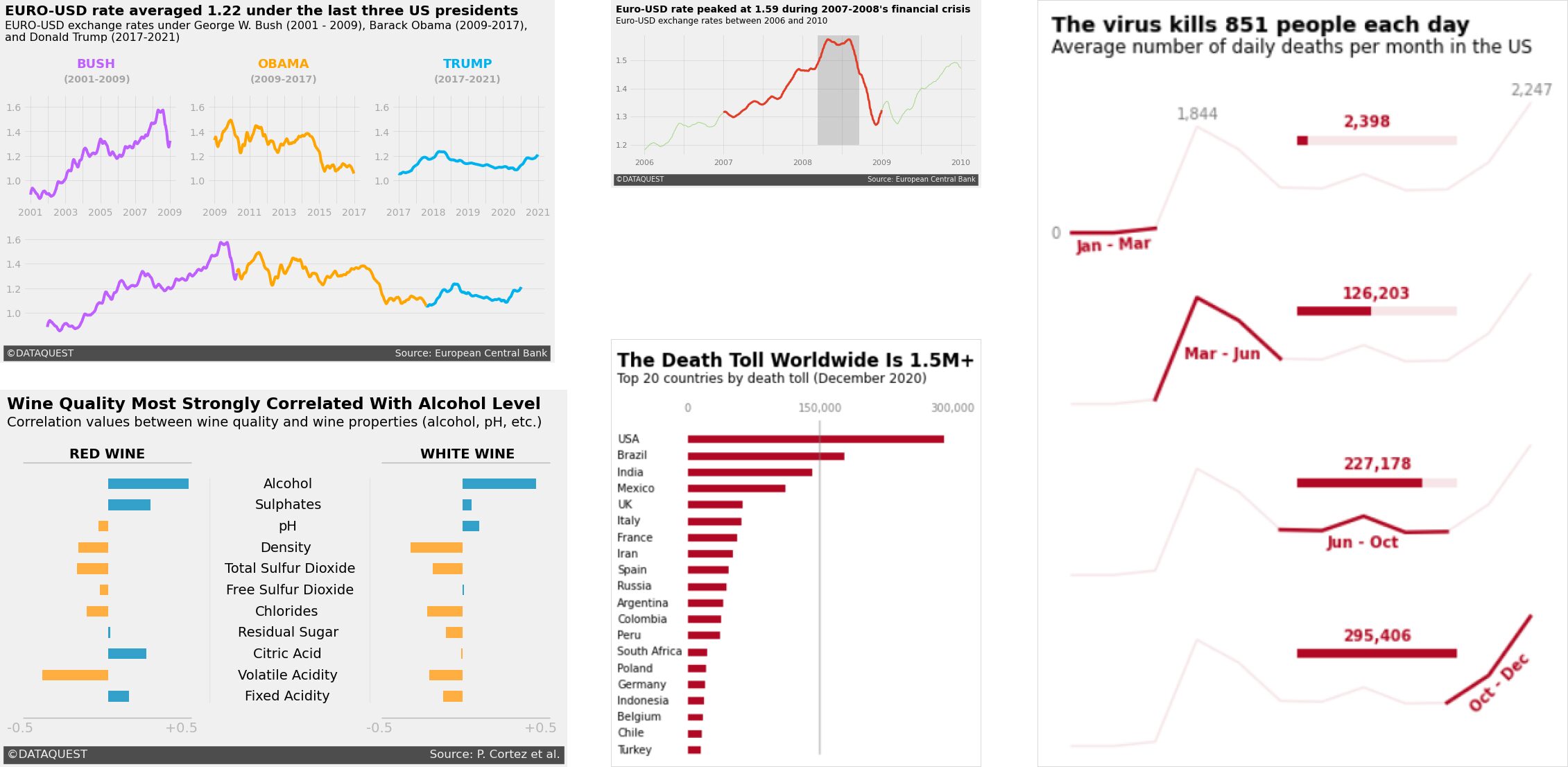
Standing in front of a room, watching eyes glaze over as you click through slide after slide of charts, can be an embarrassing experience for any data analyst. You know your numbers make sense, but they're just not connecting with your audience. This is where the art of data storytelling comes in. By focusing on visual design and weaving in a clear narrative, you can transform raw data into an engaging story that your audience will understand, turning complex insights into memorable takeaways.
Learning to tell compelling data stories is an essential skill for anyone working with data. Whether you're a data scientist presenting findings to stakeholders, a business analyst explaining trends to executives, or a researcher sharing results with the public, the ability to create clear, engaging visualizations can significantly impact how your insights are received and acted upon. This tutorial will equip you with the techniques to create professional-looking, narrative-driven visualizations using Python, helping you communicate your data more effectively and persuasively.
Telling Stories Using Data Visualization and Information Design — here's a breakdown of what this data storytelling tutorial teaches:
Lesson 1 – Design for an Audience
- Tailor visualizations to specific audience needs and knowledge levels
- Use Matplotlib's object-oriented interface for greater control over plot elements
- Apply design principles to maximize the data-ink ratio and enhance clarity
Lesson 2 – Storytelling Data Visualization
- Create multi-panel visualizations to show data progression over time
- Add context through annotations, labels, and narrative elements
- Guide viewers through data insights using visual cues and formatting
Lesson 3 – Gestalt Principles and Pre-Attentive Attributes
- Apply Gestalt principles (proximity, similarity, enclosure, connection) to organize visual information
- Utilize pre-attentive attributes like color and size to guide attention effectively
- Understand and implement visual hierarchy in data visualizations
Lesson 4 – Matplotlib Styles: A FiveThirtyEight Case Study
- Implement the FiveThirtyEight style using Matplotlib's style sheets
- Customize plots to achieve a clean, professional look
- Create visually consistent and impactful data stories across multiple visualizations
Guided Project: Storytelling Data Visualization on Exchange Rates
- Clean and prepare real-world financial data for visualization
- Apply rolling means to smooth out short-term fluctuations in time series data
- Create a compelling visual narrative using exchange rate data and economic events
By completing this tutorial, you'll be able to create professional-quality data visualizations that effectively communicate complex insights. You'll learn to design charts and graphs tailored to your audience, incorporate storytelling elements to make your data more engaging, and apply psychological principles to enhance visual comprehension. These skills will enable you to present data in a way that not only informs but also inspires action, whether you're analyzing market trends, presenting research findings, or explaining complex phenomena to a general audience.
Practice Problems
Test your knowledge with the NumPy, pandas, and data visualization exercises below. For additional practice problems and real-time feedback, try our interactive coding environment, great for Python practice online.
NumPy Practice Problems
1. Creating a Ndarray of Ones
In this NumPy practice problem, you'll create a 2-dimensional array in which every entry is equal to one.
NumPy provides the np.ones() function that we can use to do this. It takes as input a shape and produces a ndarray with the given shape in which each entry is equal to one.
Example:
```python x = np.ones((7,)) print(x) ``` ``` [1. 1. 1. 1. 1. 1. 1.] ```Instructions
- Create a 2-dimensional ndarray with seven rows and five columns in which each entry is equal to one. Assign it to a variable
x.
Hint
- Use the
np.ones()function.
Answer
```python import numpy as np # Create a 2D array with seven rows and five columns filled with ones x = np.ones((7, 5)) print(x) ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
2. Extracting All Even Values
In this NumPy practice problem, we want you to extract all even values from a 2-dimensional array. The result should be a 1-dimensional array that contains all even values of the provided 2-dimensional array.
Recall that the even numbers are 0, 2, 4, 6, and so on.
For example, if the 2-dimensional array was:
``` [[1 2 4] [3 4 6]] ```The result would be:
``` [2 4 4 6] ```Instructions
Create a 1-dimensional array named
```python x = np.array([ [6, 8, 9, 4, 4], [8, 1, 5, 3, 10], [2, 6, 7, 6, 6], [7, 8, 3, 6, 7], [10, 7, 7, 5, 2] ]) ```even_valuesthat contains all even values from the provided 2-dimensional arrayx.
Hint
- Use a boolean mask on
x. - Make use of the
%modulus operator used to calculate the remainder of a division between two numbers.
Answer
```python import numpy as np x = np.array([ [6, 8, 9, 4, 4], [8, 1, 5, 3, 10], [2, 6, 7, 6, 6], [7, 8, 3, 6, 7], [10, 7, 7, 5, 2] ]) # Extract all even values even_values = x[x % 2 == 0] ```Practice solving this exercise using our interactive coding environment designed for NumPy practice online with real-time feedback.
3. Stacking Vertically 1
In this NumPy practice problem, you'll be given a list with 1-dimensional arrays. Your goal is to create a 2-dimensional array whose rows are the 1-dimensional arrays in that list.
For example, if the list was:
```python lst = [ np.array([1, 2, 3, 4]), np.array([5, 6, 7, 8]), np.array([9, 10, 11, 12]), np.array([13, 14, 15, 16]) ] ```We want to transform it into the following 2-dimensional array:
```python [[ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12] [13 14 15 16]] ```You might want to take a look at the numpy.vstack() function.
Instructions
- Use the provided list of ndarrays
lstto create a 2-dimensional ndarray whose rows are the ndarrays inlst. Assign it to variablex.
Hint
- Use the
numpy.vstack()function.
Answer
```python import numpy as np lst = [ np.array([1, 6, 1, 7, 6, 3, 7, 2]), np.array([7, 4, 6, 5, 5, 5, 6, 8]), np.array([1, 1, 4, 5, 5, 3, 8, 2]), np.array([3, 9, 5, 3, 9, 1, 5, 4]) ] # Stack the arrays vertically x = np.vstack(lst) ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
4. Calculating the Maximum
In this NumPy practice problem, you'll calculate the maximum value of a given 2-dimensional ndarray.
Instructions
- Calculate the maximum value of the provided ndarray
x. Assign the answer to variablemaximum. ```python x = np.array([ [56, 75, 82, 18, 47, 27, 53], [85, 97, 48, 21, 57, 44, 20], [24, 40, 15, 57, 17, 93, 55], [68, 61, 24, 77, 90, 73, 34], [22, 14, 31, 34, 68, 19, 55], [37, 75, 64, 42, 14, 16, 98] ]) ```
Hint
- Use the
ndarray.max()method.
Answer
```python import numpy as np x = np.array([ [56, 75, 82, 18, 47, 27, 53], [85, 97, 48, 21, 57, 44, 20], [24, 40, 15, 57, 17, 93, 55], [68, 61, 24, 77, 90, 73, 34], [22, 14, 31, 34, 68, 19, 55], [37, 75, 64, 42, 14, 16, 98] ]) # Calculate the maximum value maximum = x.max() ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
Pandas Practice Problems
1. DataFrame from Dictionaries
In this pandas practice problem, you'll practice creating a DataFrame from two dictionaries having the same set of keys.
We provide you with two dictionaries. These dictionaries contain data on the life expectancy of the top 10 countries with the highest life expectancies.
The women dictionary contains the women's life expectancy. The men dictionary contains the men's life expectancy. The data was gathered from here.
Instructions
- Create a DataFrame named
life_exp_top10with two columnsWomenandMen(in that order). The values in these columns should be the ones in respective dictionaries.
Hint
- Use the
pandas.DataFrame()constructor. Provide to it a dictionary with keys'Women'and'Men'. The values should be the provided dictionaries. - Alternatively, you can use the
DataFrame.from_dict()method. The documentation shows a few examples on how to do it.
Answer
```python import pandas as pd # Data women = { 'Hong Kong': 87.6, 'Japan': 87.5, 'Switzerland': 85.5, 'Singapore': 85.7, 'Italy': 85.4, 'Spain': 86.1, 'Australia': 85.3, 'Iceland': 84.4, 'Israel': 84.4, 'South Korea': 85.8 } men = { 'Hong Kong': 81.8, 'Japan': 81.3, 'Switzerland': 81.7, 'Singapore': 81.4, 'Italy': 81.1, 'Spain': 80.7, 'Australia': 81.3, 'Iceland': 81.3, 'Israel': 81.1, 'South Korea': 79.7 } # Answer life_exp_top10 = pd.DataFrame({ 'Women': women, 'Men': men }) # Alternative answer life_exp_top10 = pd.DataFrame.from_dict({ 'Women': women, 'Men': men }) ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
2. Selecting the Age Column
In this pandas practice problem, you'll practice selecting a column from a DataFrame.
Instructions
- Select the
Agecolumn from thepeopleDataFrame and assign it to a variable calledages.
Hint
- Use the
pandas.locproperty.
Answer
```python import pandas as pd # Load the DataFrame people = pd.read_csv('people.csv') # Answer ages = people['Age'] ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
3. List to Series Object
In this pandas practice problem, we give you a list and your goal is to create a Series object with the same values as that list.
Remember that you can create a Series object using the pandas.Series() constructor.
Instructions
- Create a Series object whose values are the same as the
valueslist. Assign it to a variable namedseries.
Hint
- Use the
pandas.Series()constructor.
Answer
```python import pandas as pd # List of values values = [6, 2, 9, 1, 4, 8, 3, 5, 7] # Convert the list to a Series series = pd.Series(values) ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
4. Birthrate VS Deathrate
In this pandas practice problem, you'll practice selecting data using boolean indexing.
Instructions
- Select all countries from the
countriesDataFrame such that:- The
Birthrateis smaller than theDeathrate.
- The
- Assign the result to a variable named
birth_vs_death.
Hint
- Use the
<operator to create a boolean mask.
Answer
```python import pandas as pd # Load the countries data countries = pd.read_csv('countries.csv', index_col=0) # Select countries where Birthrate is smaller than Deathrate birth_vs_death = countries[countries['Birthrate'] < countries['Deathrate']] ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
Data Visualization Practice Problems
1. Types of Line Graphs
In this data visualization practice problem, you'll plot a line graph for Argentina using time series data from the COVID-19 pandemic. The dataset you're working with contains daily reported cases and deaths for various countries, recorded in columns like Date_reported, Country, Cumulative_cases, New_cases, and more.
To handle the time series data properly, you'll need to convert the Date_reported column to datetime format before plotting the graph. This will ensure the x-axis of the plot accurately reflects the date progression.
Instructions
- Load the dataset from the provided link and assign it to a variable named
who_time_series. - Convert the
Date_reportedcolumn to datetime format usingpd.to_datetime(). - Isolate the data for Argentina in a variable named
argentina. - Plot a line graph of Argentina's
Cumulative_cases. - Include the title
"Argentina: Cumulative Reported Cases", an x-axis label"Date", and a y-axis label"Number of Cases".
Hint
- Use
pd.read_csv()to load the CSV file from the dataset link. - Use
pd.to_datetime()to properly format theDate_reportedcolumn. - Use
plt.plot()to plot the graph, and remember to include axis labels and a title usingplt.xlabel(),plt.ylabel(), andplt.title().
Answer
```python import pandas as pd import matplotlib.pyplot as plt # Load and prepare the data who_time_series = pd.read_csv('WHO_time_series.csv') who_time_series['Date_reported'] = pd.to_datetime(who_time_series['Date_reported']) # Isolate Argentina data argentina = who_time_series[who_time_series['Country'] == 'Argentina'] # Plot the cumulative cases for Argentina plt.plot(argentina['Date_reported'], argentina['Cumulative_cases']) plt.title('Argentina: Cumulative Reported Cases') plt.xlabel('Date') plt.ylabel('Number Of Cases') plt.show() ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
2. Scatter Plots
In this data visualization practice problem, you'll plot a scatter plot to visualize the relationship between wind speed and the number of bikes rented. The dataset you're working with contains daily data for a bike-sharing system, with columns like dteday (the date), temp (air temperature), cnt (number of bikes rented), and windspeed (wind speed).
Scatter plots are great for visualizing the relationship between two numerical variables. In this exercise, you'll create a scatter plot to see how wind speed impacts the number of bikes rented. Before plotting, ensure the dteday column is converted to datetime for proper handling of date-related tasks, though we won't use it in the plot.
Instructions
- Load the dataset from the provided link and assign it to a variable named
bike_sharing. - Convert the
dtedaycolumn to datetime format usingpd.to_datetime(). - Create a scatter plot with the
windspeedcolumn on the x-axis and thecntcolumn on the y-axis. - Label the x-axis as
'Wind Speed'and the y-axis as'Bikes Rented'. - Display the plot using
plt.show().
Hint
- Use
pd.read_csv()to load the dataset andpd.to_datetime()to convert thedtedaycolumn. - Use
plt.scatter()to create the scatter plot, passingwindspeedandcntas arguments. - Remember to add axis labels using
plt.xlabel()andplt.ylabel()to make the plot easier to interpret.
Answer
```python import pandas as pd import matplotlib.pyplot as plt # Load and prepare the data bike_sharing = pd.read_csv('day.csv') bike_sharing['dteday'] = pd.to_datetime(bike_sharing['dteday']) # Generate the scatter plot plt.scatter(bike_sharing['windspeed'], bike_sharing['cnt']) plt.ylabel('Bikes Rented') plt.xlabel('Wind Speed') plt.show() ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
3. Histograms
In this data visualization practice problem, you'll generate histograms to explore the distribution of the casual and cnt columns from a bike-sharing dataset. The dataset you're working with contains daily data for a bike-sharing system, with columns like dteday (the date), cnt (total number of bikes rented), and casual (number of casual users, i.e., non-subscribers).
Histograms are useful for visualizing the distribution of numerical data by grouping values into intervals (or bins). In this exercise, you'll create histograms to observe how the number of casual bike rentals compares to the total number of rentals.
Instructions
- Load the dataset from the provided link and assign it to a variable named
bike_sharing. - Convert the
dtedaycolumn to datetime format usingpd.to_datetime(). - Generate a histogram for the
casualcolumn usingplt.hist(). - Display the plot using
plt.show(). - Generate another histogram for the
cntcolumn. - Compare the shape of the
casualhistogram with thecnthistogram. What differences do you notice?
Hint
- Use
pd.to_datetime()to convert thedtedaycolumn into datetime format. - Pass the
bike_sharing['casual']column toplt.hist()for the first histogram, andbike_sharing['cnt']for the second histogram.
Answer
```python import pandas as pd import matplotlib.pyplot as plt # Load the bike sharing data bike_sharing = pd.read_csv('day.csv') bike_sharing['dteday'] = pd.to_datetime(bike_sharing['dteday']) # Generate the histogram for the casual column plt.hist(bike_sharing['casual']) plt.title('Histogram of Casual Users') plt.show() # Generate the histogram for the cnt column plt.hist(bike_sharing['cnt']) plt.title('Histogram of Total Rentals (cnt)') plt.show() ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
4. Pandas Visualization Methods
In this data visualization practice problem, you'll generate a histogram to visualize traffic slowness data using Pandas' built-in plotting capabilities. The dataset you're working with contains traffic data for São Paulo, including a column Slowness in traffic (%) that measures the percentage of slowness in traffic at different times.
Before you can create the histogram, you need to clean the data by adjusting the format of the Slowness in traffic (%) column. After that, you’ll generate the histogram and add customizations such as a title and an x-axis label.
Instructions
- Load the dataset and examine the
Slowness in traffic (%)column to identify formatting issues that need to be cleaned up. - Clean the
Slowness in traffic (%)column so that it can be used for numerical analysis. - Create a histogram for the
Slowness in traffic (%)column. - Add a title that describes the distribution of the data and label the x-axis appropriately.
- Display the plot.
Hint
- Use
Series.str.replace(',', '.')to replace commas with dots in theSlowness in traffic (%)column, and then use theastype(float)method to convert it to a numeric format. Remember to assign the results back to the column to save your changes. - Use
Series.plot.hist()to generate the histogram for theSlowness in traffic (%)column. - Use
plt.title()to add a title andplt.xlabel()to label the x-axis.
Answer
```python import matplotlib.pyplot as plt import pandas as pd # Load and clean the data traffic = pd.read_csv('traffic_sao_paulo.csv', sep=';') traffic['Slowness in traffic (%)'] = traffic['Slowness in traffic (%)'].str.replace(',', '.') traffic['Slowness in traffic (%)'] = traffic['Slowness in traffic (%)'].astype(float) # Generate the histogram traffic['Slowness in traffic (%)'].plot.hist() plt.title('Distribution of Slowness in traffic (%)') plt.xlabel('Slowness in traffic (%)') plt.show() ```Practice solving this exercise using our interactive coding environment designed for Python practice online with real-time feedback.
Cheat Sheets
NumPy Cheat Sheet
Check out our comprehensive NumPy Cheat Sheet that provides a quick reference for essential data manipulation commands. You can also download the NumPy Cheat Sheet as a PDF.
Pandas Cheat Sheet
Check out our comprehensive Pandas Cheat Sheet that provides a quick reference for essential data manipulation commands. You can also download the Pandas Cheat Sheet as a PDF.
Matplotlib Cheat Sheet
Check out our comprehensive Matplotlib Cheat Sheet that provides a quick reference for essential essential plotting functions in matplotlib. You can also download the Matplotlib Cheat Sheet as a PDF.
Practice
The best way to get NumPy, pandas, and data visualiztion practice is to work on a real world challenge in the form of projects. Use these Dataquest guided projects to test your skills and show off your knowledge to potential employeers by including them in your portfolio.
1. Exploring eBay Car Sales Data
Difficulty Level: Beginner
Overview
In this beginner-level guided project, you'll analyze a dataset of used car listings from eBay Kleinanzeigen, a classifieds section of the German eBay website. Using Python and pandas, you'll clean the data, explore the included listings, and uncover insights about used car prices, popular brands, and the relationships between various car attributes. This project will strengthen your data cleaning and exploratory data analysis skills, providing valuable experience in working with real-world, messy datasets.
Tools and Technologies
- Python
- Jupyter Notebook
- NumPy
- pandas
Prerequisites
To successfully complete this project, you should be comfortable with pandas fundamentals and have experience with:
- Loading and inspecting data using pandas
- Cleaning column names and handling missing data
- Using pandas to filter, sort, and aggregate data
- Creating basic visualizations with pandas
- Handling data type conversions in pandas
Step-by-Step Instructions
- Load the dataset and perform initial data exploration
- Clean column names and convert data types as necessary
- Analyze the distribution of car prices and registration years
- Explore relationships between brand, price, and vehicle type
- Investigate the impact of car age on pricing
Expected Outcomes
Upon completing this project, you'll have gained valuable skills and experience, including:
- Cleaning and preparing a real-world dataset using pandas
- Performing exploratory data analysis on a large dataset
- Creating data visualizations to communicate findings effectively
- Deriving actionable insights from used car market data
Relevant Links and Resources
2. Finding Heavy Traffic Indicators on I-94
Difficulty Level: Beginner
Overview
In this beginner-level guided project, you'll analyze a dataset of westbound traffic on the I-94 Interstate highway between Minneapolis and St. Paul, Minnesota. Using Python and popular data visualization libraries, you'll explore traffic volume patterns to identify indicators of heavy traffic. You'll investigate how factors such as time of day, day of the week, weather conditions, and holidays impact traffic volume. This project will enhance your skills in exploratory data analysis and data visualization, providing valuable experience in deriving actionable insights from real-world time series data.
Tools and Technologies
- Python
- Jupyter Notebook
- pandas
- Matplotlib
- seaborn
Prerequisites
To successfully complete this project, you should be comfortable with data visualization in Python techniques and have experience with:
- Data manipulation and analysis using pandas
- Creating various plot types (line, bar, scatter) with Matplotlib
- Enhancing visualizations using seaborn
- Interpreting time series data and identifying patterns
- Basic statistical concepts like correlation and distribution
Step-by-Step Instructions
- Load and perform initial exploration of the I-94 traffic dataset
- Visualize traffic volume patterns over time using line plots
- Analyze traffic volume distribution by day of the week and time of day
- Investigate the relationship between weather conditions and traffic volume
- Identify and visualize other factors correlated with heavy traffic
Expected Outcomes
Upon completing this project, you'll have gained valuable skills and experience, including:
- Creating and interpreting complex data visualizations using Matplotlib and seaborn
- Analyzing time series data to uncover temporal patterns and trends
- Using visual exploration techniques to identify correlations in multivariate data
- Communicating data insights effectively through clear, informative plots
Relevant Links and Resources
3. Storytelling Data Visualization on Exchange Rates
Difficulty Level: Beginner
Overview
In this beginner-level guided project, you'll create a storytelling data visualization about Euro exchange rates against the US Dollar. Using Python and Matplotlib, you'll analyze historical exchange rate data from 1999 to 2021, identifying key trends and events that have shaped the Euro-Dollar relationship. You'll apply data visualization principles to clean data, develop a narrative around exchange rate fluctuations, and create an engaging and informative visual story. This project will strengthen your ability to communicate complex financial data insights effectively through visual storytelling.
Tools and Technologies
- Python
- Jupyter Notebook
- pandas
- Matplotlib
Prerequisites
To successfully complete this project, you should be familiar with storytelling through data visualization techniques and have experience with:
- Data manipulation and analysis using pandas
- Creating and customizing plots with Matplotlib
- Applying design principles to enhance data visualizations
- Working with time series data in Python
- Basic understanding of exchange rates and economic indicators
Step-by-Step Instructions
- Load and explore the Euro-Dollar exchange rate dataset
- Clean the data and calculate rolling averages to smooth out fluctuations
- Identify significant trends and events in the exchange rate history
- Develop a narrative that explains key patterns in the data
- Create a polished line plot that tells your exchange rate story
Expected Outcomes
Upon completing this project, you'll have gained valuable skills and experience, including:
- Crafting a compelling narrative around complex financial data
- Designing clear, informative visualizations that support your story
- Using Matplotlib to create publication-quality line plots with annotations
- Applying color theory and typography to enhance visual communication
Relevant Links and Resources
Frequently Asked Questions
What is NumPy?
NumPy (Numerical Python) is a fundamental library for scientific computing and data analysis in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
The main functions and capabilities of NumPy include:
-
Creating and manipulating arrays: With NumPy, you can easily create and work with multi-dimensional arrays. Functions like
np.array(),np.zeros(), andnp.ones()help you initialize arrays quickly. -
Mathematical operations: NumPy offers a wide range of mathematical functions that can be applied to entire arrays at once. For example,
np.sum(),np.mean(), andnp.std()calculate sum, average, and standard deviation respectively. -
Broadcasting: NumPy can perform operations on arrays of different shapes and sizes, automatically aligning them for calculations.
-
Linear algebra operations: It includes functions for matrix operations, eigenvalues, and more, making it powerful for complex mathematical computations.
Think of NumPy as a powerful tool that can perform operations on entire columns or even multi-dimensional data structures simultaneously, rather than working cell-by-cell. This efficiency dramatically speeds up calculations, especially when working with large datasets.
In data science workflows, NumPy often works in tandem with pandas for data manipulation and various libraries for data visualization. For example, you might use NumPy to perform complex calculations on your data, pandas to structure and clean it, and then create visualizations to present your findings. This combination of NumPy, pandas, and data visualization tools forms a powerful ecosystem for analyzing and interpreting complex datasets, enabling data scientists to extract meaningful insights efficiently.
How do I round each number in a NumPy array?
When working with NumPy arrays, you may need to round numbers to make your data more presentable or easier to work with. Luckily, NumPy provides a simple way to round each number in an array using the round() function.
To round your entire array, you can use np.round() and specify the number of decimal places you want to keep. This function works element-wise, meaning it applies the rounding operation to each number in the array individually. This approach is especially useful when working with large datasets, as it allows you to round an entire array in one step, significantly speeding up your data processing.
Let's take a look at an example that demonstrates how to round each number in a NumPy array:
```python import numpy as np # Create a simple NumPy array arr = np.array([1.234, 2.345, 3.456, 4.567]) # Round each element in the array to 2 decimal places rounded_arr = np.round(arr, 2) print(rounded_arr) ```Output:
``` [1.23 2.35 3.46 4.57] ```In this example:
np.round(arr, 2)rounds each element in the arrayarrto 2 decimal places.
It's worth noting that rounding can result in some loss of precision in your data. If you need to maintain exact values, you may want to consider rounding only at the final stage of your analysis or when presenting results.
In data visualization, rounding can help make your plots more readable by reducing clutter from excessive decimal places. However, be cautious not to round too aggressively, as this could potentially obscure important patterns or trends in your data.
By using NumPy's array rounding feature effectively, you can improve the way you clean and present data, leading to more effective data analysis and visualization outcomes.
What does as mean in import numpy as np?
as mean in import numpy as np?The as keyword in import numpy as np is used to create a shortcut or alias for the imported module. This allows you to use a shorter name, np, instead of typing numpy every time you want to use a function from the library.
Using aliases like this has several advantages. For one, it saves you time and effort, especially when you're using library functions frequently. It also makes your code more readable by using consistent, shorter names. This convention is widely recognized and used in the data science community.
For example, in a data analysis workflow, you might see imports like this:
```python import numpy as np import pandas as pd import matplotlib.pyplot as plt # Create a NumPy array data = np.array([1, 2, 3, 4, 5]) # Use pandas to create a DataFrame df = pd.DataFrame(data, columns=['Values']) # Create a simple plot plt.plot(df['Values']) plt.show() ```This convention helps you write cleaner, more concise code when working with these libraries. It's especially useful in data science workflows where you're often switching between different libraries for numerical operations, data manipulation, and visualization.
By using these import conventions, you can make your code more efficient and easier to read. This, in turn, makes collaboration and code sharing easier, as you'll be following standard practices in the field.
How can I check if each number is even in NumPy?
When you're working with numbers in NumPy, you might need to identify even numbers for analysis or visualization. Fortunately, NumPy makes this process pretty straightforward.
To check if numbers are even in a NumPy array, you can follow these steps:
- Use the modulo operator (
%) with2on your array - Compare the result to
0
This creates a boolean array where True indicates an even number and False indicates an odd number. For example:
The resulting is_even array would be:
This boolean array is useful for various tasks―you can use it to filter your original array, count even numbers, or create masks for data visualization. For example, in a pandas DataFrame, you could use this to highlight even values in a heatmap or filter data for further analysis.
One of the benefits of this method is that it's efficient for large datasets. NumPy performs the operation element-wise, which means it doesn't require explicit loops. This makes it a valuable technique to learn when working with numerical data.
It's worth noting that while this operation is fast, it's essential to consider memory usage when working with very large arrays. In such cases, you might need to process your data in smaller chunks.
By learning how to perform this operation in NumPy, you'll become more proficient in handling numerical data in your pandas and data visualization workflows.
How do I create a NumPy random number generator?
Creating a NumPy random number generator is a valuable skill for data analysis and visualization tasks. Here's a step-by-step guide to help you set one up:
- First, import NumPy (typically as
np). - Next, create a generator object using
np.random.default_rng(). - Then, use methods like
random(),integers(), ornormal()to generate different types of random numbers.
For example, let's generate some random data for a hypothetical sales analysis:
```python rng = np.random.default_rng(seed=42) # Set seed for reproducibility daily_sales = rng.integers(100, 1000, size=30) # Generate 30 days of sales data ```This creates an array of 30 random integers between 100 and 999, simulating daily sales figures. You can then use pandas to organize this data into a DataFrame and create visualizations to analyze patterns or distributions.
Random number generation plays a key role in various data science tasks, including simulating datasets for testing algorithms, bootstrapping for statistical inference, and creating random samples for machine learning model validation.
When working with random data, keep in mind that results can vary between runs unless you set a specific seed. Additionally, be cautious about using random data to make real-world predictions without proper validation.
By following these steps, you'll be able to create diverse datasets to enhance your data analysis and visualization projects.
What is pandas and how does it complement NumPy?
Pandas is a powerful Python library that works alongside NumPy to provide a more comprehensive data analysis toolkit. While NumPy excels at numerical operations on arrays, pandas introduces the DataFrame - a two-dimensional labeled data structure that's perfect for working with structured data like spreadsheets or SQL tables.
So, how does pandas enhance your data analysis workflow? Here are a few key ways:
-
Easy data loading and saving: Pandas makes it easy to read and write data in various formats (CSV, Excel, SQL databases) with just a few lines of code.
-
Effortless data cleaning and transformation: With pandas, you can easily handle missing values, reshape data, and perform complex operations across rows and columns.
-
Intuitive data selection and filtering: Pandas provides flexible ways to select and filter your data, building on NumPy's indexing capabilities. For example, you can use pandas to select specific rows and columns, or filter your data based on conditions.
In practice, you might use NumPy to perform fast numerical computations on your data, while using pandas to handle tasks like merging datasets, grouping data, or computing summary statistics. This combination is particularly useful when preparing data for visualization, as pandas can easily transform your data into the format needed for plotting libraries.
By combining NumPy, pandas, and data visualization libraries, you create a robust workflow for data analysis in Python. You get the speed of NumPy's numerical operations, the flexibility of pandas for data manipulation, and the ability to create insightful visualizations - all working together to help you extract meaningful insights from your data.
What is a pandas DataFrame?
A pandas DataFrame is a powerful tool in Python that helps you work with structured data efficiently. Imagine you have a spreadsheet with rows and columns, where each column can contain different types of data, such as numbers, text, or dates. That's basically what a DataFrame is.
For example, let's say you're analyzing data on coffee shops in a city. Your DataFrame might have columns for the shop's name, location, and average rating. This flexibility makes DataFrames ideal for real-world data analysis tasks.
Let's create a simple DataFrame to demonstrate:
```python import pandas as pd # Create a DataFrame with data on coffee shops data = {'Name': ['Central Perk', 'Blue Bottle', 'Cafe Grumpy'], 'Location': ['NYC', 'SF', 'Brooklyn'], 'Rating': [4.5, 4.0, 4.2]} df = pd.DataFrame(data) # Display the DataFrame print(df) ```Output:
``` Name Location Rating 0 Central Perk NYC 4.5 1 Blue Bottle SF 4.0 2 Cafe Grumpy Brooklyn 4.2 ```In this example:
- The DataFrame has three columns:
'Name','Location', and'Rating'. - Each row represents data for a specific coffee shop, and the index (on the left) labels each row.
One key feature of DataFrames is the index, which labels each row. This index allows you to access and align data easily, especially when working with multiple datasets. Columns also have labels, making it simple to refer to specific data points.
DataFrames are particularly useful when working with large datasets and complex analyses. They work seamlessly with NumPy for numerical operations and various data visualization libraries, making it easy to create insightful visualizations from your data. For instance, you can use a DataFrame to create a bar chart showing the average rating of coffee shops in different neighborhoods.
By using pandas DataFrames in conjunction with NumPy and data visualization tools, you can streamline your data analysis workflow. From data cleaning and transformation to statistical analysis and creating compelling visualizations, DataFrames provide a solid foundation for exploring and understanding your data.
What is a pandas Series and how does it relate to a DataFrame?
A pandas Series is a one-dimensional labeled array that plays a central role in data analysis with Python. It's a versatile data structure that can hold various types of data, from numbers to strings to complex objects. Think of a Series as a single column in a spreadsheet or a single variable in a dataset.
A Series is closely related to a DataFrame, which is essentially a collection of Series objects aligned along a common index. Each column in a DataFrame is a Series, and you can easily access and manipulate these individual columns as Series objects.
While both Series and DataFrames are tabular data structures, they have some key differences:
- Dimensionality: A Series is one-dimensional, like a list or a single column, while a DataFrame is two-dimensional, like a table with rows and columns.
- Data storage: A Series holds a single column of data, whereas a DataFrame can hold multiple columns, each potentially containing different types of data.
- Indexing: Both use labels for indexing, but DataFrames have both row and column labels, allowing for more complex data access and manipulation.
Here's a simple example to illustrate how Series and DataFrames work together:
```python import pandas as pd # Create a Series s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']) # Create a DataFrame using the Series df = pd.DataFrame({ 'column1': s, 'column2': [5, 6, 7, 8] }) # Access a column (Series) from the DataFrame column1_series = df['column1'] ```In this example, we create a Series s, use it as one column in a DataFrame df, and then show how to access that column as a Series again.
Understanding how Series work is essential for efficient data manipulation and analysis with pandas. By working with individual columns of data, you can perform a wide range of operations and build a strong foundation for more complex tasks. In typical data science workflows, you'll often find yourself switching between Series and DataFrame operations as you clean, transform, and analyze your data.
By grasping the relationship between Series and DataFrames, you'll be well-equipped to handle a variety of data analysis tasks using pandas, setting the stage for more advanced techniques in data visualization and machine learning.
How can I get the column names in a pandas DataFrame?
When working with pandas, you often need to access the column names in your DataFrame. Column names represent the labels for each feature or variable in your dataset.
To get the column names, you can use the .columns attribute of your DataFrame. This returns an Index object containing all the column labels. If you need the column names as a list, you can easily convert the Index object to a Python list.
Let's take a look at an example that creates a simple DataFrame and retrieves the column names in both formats:
```python import pandas as pd # Create a simple DataFrame data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'City': ['New York', 'Los Angeles', 'Chicago']} df = pd.DataFrame(data) # Get the column names column_names = df.columns print(column_names) # If you need the column names as a list column_names_list = df.columns.tolist() print(column_names_list) ```Output:
``` Index(['Name', 'Age', 'City'], dtype='object') ['Name', 'Age', 'City'] ```In this example:
df.columnsreturns an Index object containing the column names:['Name', 'Age', 'City'].df.columns.tolist()converts this Index object into a regular Python list.
Accessing column names is essential for several reasons. Firstly, it helps you quickly understand the structure of your dataset. For example, you can use column names to identify specific columns for analysis or visualization. Additionally, column names help in identifying mislabeled or duplicate columns, which is important for data cleaning. Many pandas operations also require you to specify column names.
As you work with pandas, you'll find that efficiently working with column names is vital for tasks ranging from basic data cleaning to advanced statistical analysis and creating insightful visualizations. By understanding how to access column names, you'll be able to work more effectively with your data and gain valuable insights.
What is data visualization and why is it important in data analysis?
Data visualization is the process of turning raw numbers and statistics into visual formats, such as charts, graphs, and maps. This transformation makes complex information more accessible and easier to analyze.
Data visualization plays a significant role in data analysis for several reasons:
-
It helps reveal patterns, trends, and outliers quickly. For example, a scatter plot of customer demographics against purchasing behavior can instantly highlight market segments that might take hours to identify in a spreadsheet.
-
It simplifies complex datasets, making them understandable to both technical and non-technical audiences. A well-designed infographic can convey the key findings of a lengthy report in a single, compelling image.
-
It enables data-informed decision-making by presenting insights clearly and persuasively. A dashboard showing real-time sales metrics can help managers make quick, informed decisions about inventory and staffing.
Tools like NumPy and pandas are essential in preparing and manipulating data for visualization. When combined with Python libraries such as Matplotlib or Seaborn, they provide a powerful toolkit for creating sophisticated, interactive visualizations. For instance, you can use pandas to clean and aggregate sales data, then use Matplotlib to create a multi-line chart showing sales trends across different product categories.
Developing strong data visualization skills is increasingly valuable in today's data-rich environment. By transforming raw data into compelling visual narratives, analysts can influence strategy, drive action, and ultimately lead to better business outcomes. Whether you're analyzing financial trends, exploring scientific data, or optimizing marketing campaigns, strong visualization skills will set you apart as a data professional.
What are common data visualization tools in Python?
Data visualization is a powerful way to uncover insights and communicate findings in data analysis. When working with NumPy and pandas in Python, several visualization tools can help bring your data to life.
-
Matplotlib: This versatile library is the foundation for many Python visualization tools. It offers extensive customization options, allowing you to create a wide range of chart types. For example, you can create simple line plots or more complex figures with multiple panels. Matplotlib works seamlessly with NumPy arrays and pandas DataFrames, making it easy to visualize your processed data.
-
Seaborn: Built on top of Matplotlib, Seaborn provides a higher-level interface for creating attractive statistical graphics. It's particularly useful for visualizing relationships between variables and works well with pandas DataFrames. Seaborn excels at creating heatmaps, violin plots, and other advanced visualizations that can reveal patterns in your data.
-
Pandas built-in plotting: Pandas includes convenient plotting methods that leverage Matplotlib under the hood. These methods allow you to create quick visualizations directly from your DataFrames, which is especially useful during exploratory data analysis.
A typical workflow might involve using pandas to load and clean your data, NumPy for numerical computations, and then Matplotlib or Seaborn to create insightful visualizations. For instance, you could use pandas to load a CSV file of time series data, use NumPy to calculate moving averages, and then use Matplotlib to create a line plot showing trends over time.
While these tools are powerful, they can take time to learn. Matplotlib, in particular, can be complex for beginners due to its flexibility. However, the combination of NumPy, pandas, and these visualization libraries provides a robust toolkit for data analysis and presentation.
One challenge when using multiple tools is ensuring consistency in your visualizations. However, this can also be an advantage, as you can leverage the strengths of each tool for different aspects of your analysis. For example, you might use pandas for quick data exploration, Seaborn for statistical visualizations, and Matplotlib for finely-tuned publication-quality figures.
By learning to use these visualization tools alongside NumPy and pandas, you'll be well-equipped to perform comprehensive data analysis and create compelling visual stories from your data.
What is data storytelling and how does it improve data presentations?
Data storytelling is a way to turn raw numbers into compelling visual narratives that make complex insights more accessible and memorable. When I use data storytelling in my presentations, I notice a significant improvement in audience engagement and understanding. For instance, instead of just displaying a bar chart of sales figures, I create a multi-panel visualization that guides viewers through our company's journey, highlighting key events and market trends that influenced our performance.
By applying visual design principles and focusing on narrative, data storytelling helps me emphasize the most important insights and provide context that raw data alone can't convey. This approach not only makes my presentations more engaging but also leads to better decision-making, as stakeholders can more easily grasp the implications of the data. For example, I use Python tools like NumPy, pandas, and Matplotlib to create effective data stories. These tools allow me to efficiently clean and process large datasets, and create polished, customized visualizations that support my narrative.
One challenge I often face with data storytelling is avoiding oversimplification of complex information. While it's essential to make data accessible, I need to ensure that I'm not misrepresenting the nuances or uncertainties in the data. To address this, I strive to find a balance between simplicity and accuracy. I use techniques like error bars or provide additional context in annotations to achieve this balance.
Developing strong data storytelling skills has greatly benefited my work as a data professional. It's not just about creating visually appealing charts; it's about using data to tell a compelling story that influences decisions and drives action. By developing these skills, I've become more effective at communicating insights and making a real impact with my analyses.
What are Gestalt principles in data visualization?
Gestalt principles are laws of visual perception that describe how we naturally group and organize visual elements. These principles can help you create more intuitive and easier-to-understand charts, graphs, and other visual representations of data.
The key Gestalt principles most relevant to data visualization are:
- Proximity: Elements close together are perceived as related
- Similarity: Objects with similar attributes (color, shape, size) are seen as part of the same group
- Enclosure: Our minds tend to perceive elements enclosed within a boundary as belonging to a group
- Connection: Our eyes follow lines or other linking elements to show relationships
When applying these principles, consider how they can help your audience quickly understand your data. For example, when creating a scatter plot using Python libraries like Matplotlib, you can use consistent colors to represent different categories, making it easier for viewers to identify and compare data points.
Another example is using proximity in a bar chart to group related categories closer together. This can help highlight relationships or contrasts between different data segments, making patterns more apparent.
However, it's essential to use Gestalt principles thoughtfully. Overusing them or applying them inconsistently can lead to confusing or misleading visualizations. Always consider your specific dataset, audience, and the story you're trying to tell when deciding how to apply these principles.
By understanding and applying Gestalt principles, you can create more intuitive and easily interpretable visualizations that effectively communicate your data insights. This will help you communicate your findings more clearly and make a stronger impact with your analysis.
What are pre-attentive attributes in data visualizations?
Pre-attentive attributes are visual properties that our brains process quickly and automatically, without much conscious effort. These attributes are useful tools in data visualization, as they help guide viewers' attention and enhance understanding of complex information.
Some common pre-attentive attributes include:
- Color
- Size
- Shape
- Orientation
- Motion
- Position
When creating visualizations using tools like Matplotlib or Seaborn in Python, we can use these attributes to make our charts more effective. For example, in a scatter plot comparing multiple variables, we might use color to distinguish between categories, size to represent a quantitative value, and position (through x and y coordinates) to show relationships between variables.
The key benefit of pre-attentive attributes is their ability to communicate information quickly. Our brains can process these visual cues in less than 250 milliseconds, making them useful for highlighting key points in our data stories. When working with large datasets using NumPy and pandas, thoughtful use of pre-attentive attributes can help us draw attention to important trends or outliers that might otherwise be overlooked.
However, it's essential to use these attributes thoughtfully. Overusing or misusing pre-attentive cues can lead to confusing or misleading visualizations. To avoid this, follow these best practices:
- Use attributes purposefully and consistently
- Limit the number of pre-attentive cues in a single visualization
- Consider accessibility, such as using colorblind-friendly palettes
- Ensure that the chosen attributes align with the nature of your data and the story you're telling
By understanding and effectively using pre-attentive attributes, we can create more impactful and intuitive visualizations. This makes our data easier to interpret and enhances our ability to tell compelling data-driven stories, a valuable skill in fields ranging from data science to business analytics.
How can I improve my skills in NumPy, pandas, and data visualization?
Improving your skills in NumPy, pandas, and data visualization is essential for becoming proficient in data analysis and science. Here are some effective strategies to help you enhance your abilities:
- Start with hands-on practice using tutorials that cover essential concepts. For example, learn to create and manipulate NumPy arrays, clean and analyze data with pandas, and generate various plot types using Matplotlib. These exercises will help you build a strong foundation in data manipulation and visualization techniques.
As you practice, you'll become more comfortable working with these libraries. To take your skills to the next level, try applying them to real-world projects. For instance, you could explore used car listings data to uncover pricing trends, or analyze traffic patterns to identify indicators of heavy congestion. These projects will challenge you to use NumPy, pandas, and visualization tools in practical scenarios, helping you develop problem-solving skills and gain experience with messy, real-world data.
-
Having quick reference materials handy can also be helpful. Keep cheat sheets nearby when working on projects, as they can significantly speed up your workflow and reinforce your knowledge of these libraries.
-
Using interactive coding environments can also accelerate your learning process. These platforms provide immediate feedback as you practice, allowing you to experiment with code snippets and see results instantly.
-
Consistent practice is key to improving your skills. Set aside regular time to work on projects and exercises, starting with simpler tasks and gradually increasing complexity as you become more comfortable. For example, begin by creating basic line plots of time series data, then progress to more advanced visualizations like multi-panel plots that tell a comprehensive data story.
Remember, becoming proficient in these tools takes time and dedication. Focus on applying what you learn to practical problems, and don't hesitate to revisit fundamental concepts as you tackle more complex challenges. With persistent effort, you'll soon be able to efficiently manipulate large datasets and create insightful visualizations that effectively communicate your findings.