Basic Operators and Data Structures in Python
When I first started learning Python for data analysis, I felt overwhelmed by the sheer volume of information and the complexity of the tasks ahead. But as I began to explore Python's basic operators and data structures, I discovered a world of possibilities that transformed my approach to data analysis. In this tutorial, I'll share my journey and the key insights I've gained, focusing on three fundamental Python concepts: for loops, conditional statements, and dictionaries.
These building blocks of Python programming have not only streamlined my data processing tasks but have also opened up new avenues for insightful analysis that I couldn't have imagined when I first started. Even if you're just beginning your Python journey, or you're looking to enhance your existing skills, this tutorial will provide you with practical examples and real-world applications that you can apply to your own data analysis projects. Here's what we'll cover:
We'll start by exploring Python
forloops, which are incredibly useful for handling repetitive tasks and help with keeping your code DRY (Don't Repeat Yourself). As an example, in a recent project at Dataquest, I used aforloop to process each course in our catalog in order to create a script that would automate the creation of course prerequisites. This experience reminded me of how Python can transform tedious tasks into efficient processes. Whenever you're dealing with lots of data or performing repetitive tasks,forloops can save you time and avoid headaches.After learning about loops, we'll examine conditional statements―the decision-making tools of your code. By using
if,else, andelifstatements, you'll be able to empower your program to make choices based on specific conditions before executing particular code snippets. These conditional tools are essential when you need your analysis to adapt to different scenarios or data characteristics.Next up, we'll explore dictionaries, one of Python's most versatile data structures. Think of them as organized containers for data, where each piece of information is easily accessible by name. In data analysis, dictionaries can help you structure complex datasets, making them easier to manipulate and understand.
Finally, by combining these concepts, you'll see how you can create scripts that automate tasks, clean datasets, and perform complex calculations. You'll discover how these tools can be applied across various areas of data science, from preprocessing data for machine learning models to extracting actionable insights from your data.
As we explore these essential Python building blocks, think about how you might apply them in your own work. What time-consuming tasks could you automate? How could you use these tools to dig deeper into your datasets and uncover hidden insights?
Let's begin by taking a close look at Python for loops and learn how we can leverage them to become more efficient programmers.
Lesson 1 – Python For Loops
When I started working with large datasets, I often found myself repeating the same operations over and over. That's when I really started to take advantage of using Python for loops. These powerful tools will forever change the way you handle repetitive tasks, allowing you to process large amounts of data with just a few lines of code. Here's a short animation showing a Python for loop in action:

In their most basic form, Python for loops allow you to iterate over a sequence (like a list or string) and perform an action for each item. Let's breakdown a simple example based on the animation above:

In this example, value is our iteration variable. However, we can use any iteration variable name we want here. So in real-world situations, it's a good idea to choose something that's a little more descriptive. While iterating over a_list, the iteration variable (value) takes on the value of each item in a_list (one at a time), allowing us to perform an action (in this case, printing) for each item in the list.
Although this was a simple example, for loops really shine when working with larger datasets. Imagine you have information about multiple apps, each represented as a list within a larger list. You can use a for loop to process this data efficiently:
app_data_set = [row_1, row_2, row_3, row_4, row_5]
rating_sum = 0
for row in app_data_set:
rating = row[-1]
rating_sum = rating_sum + rating
print(rating_sum)Let's break this code down:
- We start with
rating_sum = 0to initialize our sum. - The loop goes through each
rowinapp_data_set. - For each row, we extract the
rating(the last item in the list) withrow[-1]. - We add this
ratingto our running total inrating_sum. - After the loop finishes, we print the total sum of ratings.
I've noticed many learners struggle with knowing which lines of code are part of the loop and which aren't. Allow me to clarify this for you now. Notice that the two lines of code following the for loop are indented compared to the rest of the code. These two lines form the body of the loop and signals that only they are executed with each iteration of the loop. At the end of the day, this loop calculates the sum of ratings for all apps in the dataset and then prints the result. The result would represent the total of all ratings. From here, we could go on to calculate the average rating by dividing rating_sum by the number of apps.
At Dataquest, we use for loops daily to analyze course data. For example, we once needed to calculate the average completion time for each lesson in a course. By using a for loop to iterate through the lesson data, we were able to quickly identify which lessons were taking longer than expected. This insight helped us optimize our course content, improving the learning experience for our students.
Here are some tips for using for loops effectively in your data analysis:
- Start with basic loops and gradually increase complexity as you become more comfortable.
- Use descriptive variable names to make your code more readable and easier to understand.
- Pay attention to indentation, as Python uses it to define the body of the loop.
- Consider using
enumerate()if you need both the index and value of items in your loop. - Be mindful of performance, and consider using more advanced techniques like list comprehensions or vectorized operations for very large datasets.
Loops are a powerful tool that can help you automate repetitive tasks, handle large datasets efficiently, and uncover insights that might be missed with manual analysis. As you continue to work with Python, you'll find countless ways to apply for loops in your data science projects.
Remember, practice makes perfect. Don't be afraid to experiment with for loops in your own projects. Start by identifying repetitive tasks in your current workflows. Could a for loop make that task more efficient? Could it help you analyze your data in a new way? You might be surprised at how much they can improve your data analysis capabilities.
In the next lesson, we'll explore how to combine for loops with conditional statements, opening up even more possibilities for your data analysis toolkit. But for now, try writing a few for loops of your own. The more you practice, the more natural they'll become, and the more time you'll save in your data analysis tasks.
Lesson 2 – Making Decisions with Python: If, Else, and Elif Statements
As you continue to expand your Python skillset, you're going to need a tool that allows your code to make decisions: conditional statements. These statements are essential for creating flexible and responsive data analysis workflows, especially if, else, and elif.
At its core, an if statement allows your code to ask a question and take different actions based on the answer. Let's look at a simple example:
if True:
print(100)Running this code would output:
100In this case, the condition True is always met, so the code inside the if block (indented) will always run. But conditions aren't always True.
The real power comes when we use conditions that can change based on our data. So now let's look at some more examples of how if statements behave if they're always False:
if True:
print('First Output')
if False:
print('Second Output')
if True:
print('Third Output')Output:
First Output
Third OutputNotice how the second print() statement doesn't execute because its condition is False. This demonstrates how if statements allow your code to selectively run based on conditions you specify. To be clear, we rarely use True and False like this when creating conditional statements. Rather, we tend to use comparison operators like >, <, ==, and != which will evaluate to either True or False based on our data. For reference, here are some of the most used Python comparison operators:

And here's a coding example that shows how they work:

Let's take a look at one more example where we iterate over a list of apps and their prices in order to create a list of free apps based on the condition price == 0:
app_and_price = [['Facebook', 0],
['Instagram', 0],
['Plants vs. Zombies', 0.99],
['Minecraft: Pocket Edition', 6.99],
['Temple Run', 0],
['Plague Inc.', 0.99]
]
free_apps = []
for app in app_and_price:
name = app[0]
price = app[1]
if price == 0:
free_apps.append(name)
print(free_apps)This code produces this output:
['Facebook', 'Instagram', 'Temple Run']I recall when I first started using if statements in my data analysis work. We were analyzing student progress data, and I needed to flag courses where less than 50% of learners were finishing. Here's a simplified version of what I used:
if completion_rate < 0.5:
print('This course needs attention')This simple condition allowed us to quickly identify courses that needed improvement, streamlining our curriculum development process. By automating this check, we were able to focus our efforts on the courses that truly needed our attention, rather than manually reviewing each one. It made a significant difference for our team's efficiency.
In your data analysis work, you might use if statements to filter out outliers or irrelevant data points, categorize data into different groups based on certain criteria, or handle missing or incorrect data.
While if statements are powerful on their own, they become even more versatile when combined with else and elif (a combination of else and if) statements. These allow you to specify alternative actions when the initial condition isn't met. For example, you might use an else statement to handle all cases that don't meet your if condition, or use elif to check multiple conditions in sequence. We'll explore these in more depth in the next lesson.
When you're using if statements in your data analysis workflows, keep these tips in mind:
- Make your conditions clear and readable: Complex conditions can be hard to debug.
- Be careful with floating-point comparisons: Due to how computers represent decimals, it's often better to use ranges rather than exact equality.
- Don't nest
ifstatements withinelsestatements: Useelifwhen you have multiple mutually exclusive conditions to check. We'll look at these in the next lesson.
As you continue to work with Python, you'll find that becoming proficient in conditional statements opens up new possibilities for your data analysis. They help your code respond to the data, making your analysis more reliable and informative. By implementing these decision-making tools, you're taking a significant step towards more sophisticated and efficient data analysis workflows.
Now let's build on this foundation and explore how to use else and elif statements to create even more nuanced decision-making processes in your code. These tools will further enhance your ability to handle complex data scenarios and extract meaningful insights from your datasets.
Lesson 3 – Working with Multiple Conditions in Python

Learning how to use multiple conditions in if statements was a turning point in my data analysis journey. I could create nuanced categories and handle complex scenarios with ease.
Let me share an example from one of our Python lessons at Dataquest that uses the same dataset as the previous example above. In the lesson, you're given a dataset of mobile apps, and you need to categorize them based on their price. Here's how you'd do that:
apps_data = [['Facebook', 0.0],
['Notion', 14.99],
['Astropad Standard', 29.99],
['NAVIGON Europe', 74.99]
]
for app in apps_data:
price = app[1]
if price == 0.0:
app.append('free')
elif price > 0.0 and price < 20:
app.append('affordable')
elif price >= 20 and price < 50:
app.append('expensive')
elif price >= 50:
app.append('very expensive')
print(apps_data)This code sorts each app into a price category. When you run it, here's what you'd get:
[['Facebook', 0.0, 'free'],
['Notion', 14.99, 'affordable'],
['Astropad Standard', 29.99, 'expensive'],
['NAVIGON Europe', 74.99, 'very expensive']]But price isn't the only thing you might want to evaluate. Let's look at another example where you categorize apps based on their user ratings:
app_ratings = [['Facebook', 3.5],
['Notion', 4.0],
['Astropad Standard', 4.5],
['NAVIGON Europe', 3.5]
]
for app in app_ratings:
rating = app[1]
if rating < 3.0:
app.append('below average')
elif rating >= 3.0 and rating < 4.0:
app.append('roughly average')
elif rating >= 4.0:
app.append('better than average')
print(app_ratings)This script puts apps into categories based on their ratings. The output would look like this:
[['Facebook', 3.5, 'roughly average'],
['Notion', 4.0, 'better than average'],
['Astropad Standard', 4.5, 'better than average'],
['NAVIGON Europe', 3.5, 'roughly average']]We use similar approaches at Dataquest all the time. For instance, when we developed a new data science course, we used multiple conditions to analyze student performance across different topics. By looking at both practice problem scores and project completion rates, we could identify areas where students needed extra help.
Here are some tips to keep in mind when working with multiple conditions:
- Keep your conditions simple: Write them in a way that's easy to read and understand. You'll thank yourself later when you're debugging!
- Be careful with decimals: Computers can be tricky with decimal numbers. It's often safer to use ranges instead of exact comparisons.
- Use
eliffor options that can't overlap: If you're dealing with categories where an item can only be in one category,elifis your friend. - Test your logic: Always run your code with different inputs to make sure it's behaving the way you expect.
By becoming proficient at setting up multiple conditions, you're adding a powerful tool to your data analysis toolkit. You'll be able to ask more nuanced questions of your data and get more insightful answers.
As you continue working with Python, you'll find all sorts of ways to use these concepts in your data projects. In the next lesson, we'll explore how to store our data in one of Python's most convenient data structures: dictionaries.
Lesson 4 – Organizing Data with Python Dictionaries
Now that we've explored for loops and conditional statements, let's discuss a powerful tool that has revolutionized the way we work with data: Python dictionaries. If you've been following our Introduction to Python guide, you know how useful lists can be. But what if you need to organize information in a more structured way than lists allow?

Dictionaries are the perfect solution. They're flexible and incredibly useful for analyzing data. Unlike lists, which use numerical indices, dictionaries use keys to access values. This makes them ideal for storing and retrieving data that has a natural pairing, like words and their definitions in an actual dictionary, or in the example below, content ratings and their corresponding numbers.
Let's create a dictionary:
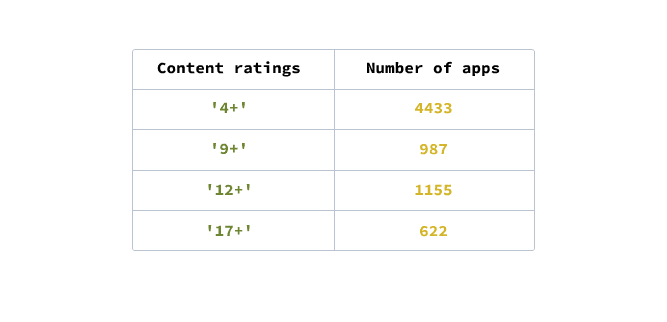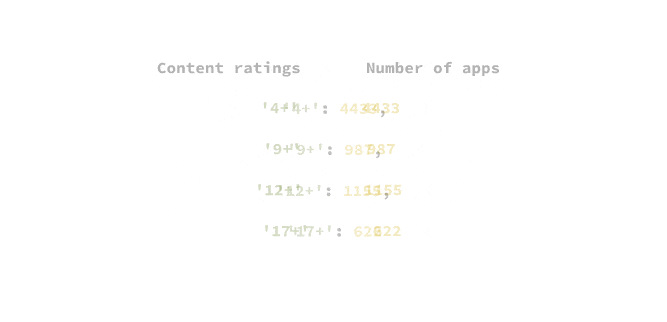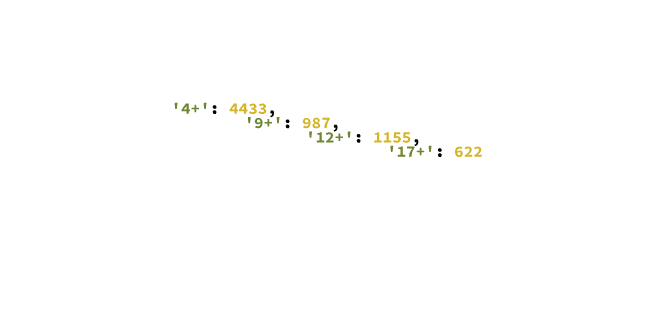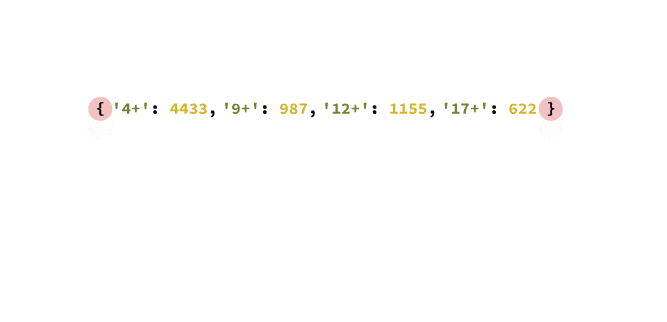
content_ratings = {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}
print(content_ratings)And here's the resulting dictionary output:
{'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}In this example, we're storing information about content ratings. The keys ('4+', '9+', etc.) represent different rating categories, and the values (4433, 987, etc.) represent the number of apps in each category. Here's a quick animation showing how we can take this data represented in a table, and convert it to a Python dictionary:
One of the things I appreciate most about dictionaries is how intuitive they are when retrieving data; referencing dictionary_name[key] will return its associated value. Need to know how many apps have a '12+' rating? Simply access the data using content_ratings['12+'] and you'll get 1155. It's that easy!
But what if you need to build your dictionary piece by piece? No problem. Here's another way to create that same content ratings dictionary:
content_ratings = {}
content_ratings['4+'] = 4433
content_ratings['9+'] = 987
content_ratings['12+'] = 1155
content_ratings['17+'] = 622
print(content_ratings)Since it's the same dictionary, this produces the same output as before:
{'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}This method can be particularly useful when you're working with a small dataset and you want your code to be highly readable. It's also a useful method for adding data to an existing dictionary.
When I started working on a new course on data cleaning at Dataquest, we needed a way to track different types of data issues and their frequencies. Dictionaries were the ideal solution. We could easily update the count for each issue type as we processed the data, giving us a clear overview of the most common problems. This not only streamlined our course development process but also provided valuable insights that we used to improve our curriculum.
If you're working with data you want to organize it, dictionaries can significantly improve your workflow. They allow you to create meaningful associations between data points, making your code more readable and your analysis more intuitive. For instance, you could use dictionaries to organize customer data, linking each customer ID to a set of attributes like name, age, and purchase history.
Here are a few tips I've picked up for using dictionaries effectively in data analysis:
- Use descriptive keys: Make your dictionaries self-documenting by using clear, meaningful keys.
- Be consistent: If you're using dictionaries to represent similar objects, keep the structure consistent.
- Combine with other data structures: Dictionaries can contain lists, or even other dictionaries, allowing for complex data representation. This applies to both dictionary keys and values.
As you continue to enhance your data analysis skills, you'll find that dictionaries become an essential part of your Python toolkit. They're not just for storing data―they're a powerful way to structure your thinking about data relationships. Whether you're cleaning datasets, building feature sets for machine learning, or creating complex data pipelines, dictionaries will help you organize and access your data efficiently.
In the next lesson, we'll explore how to use dictionaries to create frequency tables, a common task in data analysis. This will further demonstrate how Python's data structures can streamline your workflow and reveal deeper insights from complex datasets. For now, I encourage you to experiment with dictionaries in your own projects. You might be surprised at how they can simplify your code and improve the structure of your data.
Lesson 5 – Creating Frequency Tables with Python Dictionaries

Now that we've learned about Python dictionaries, let's explore how they can be used to create frequency tables. These tables are a powerful tool in data analysis, helping us understand how often each value appears in our data.
At Dataquest, we regularly use frequency tables to analyze our course data. For example, we might want to know how many students are enrolled in each course category or what percentage of users are completing different types of projects.
Here's how we can create a frequency table for the app data example using Python dictionaries:
content_ratings = {}
ratings = ['4+', '4+', '4+', '9+', '9+', '12+', '17+']
for c_rating in ratings:
if c_rating in content_ratings:
content_ratings[c_rating] += 1
else:
content_ratings[c_rating] = 1
print(content_ratings)This code gives us:
{'4+': 3, '9+': 2, '12+': 1, '17+': 1}We're looping through our data, checking each app's content rating. If we've seen that rating before, we increment its count. If it's new, we add it to our dictionary with a count of 1. The result is a summary of how many apps fall into each content rating category.
Dictionaries are great for frequency tables because they're efficient. They make it easy to access and update our counts as we process our data. This efficiency is especially important when working with larger datasets.
On top of the raw count, we often need to know the proportion or percentage of items in each category. Here's how we can transform our frequency table to proportions and percentages:
c_ratings_proportions = {}
c_ratings_percentages = {}
total_number_of_apps = 7
for key in content_ratings:
proportion = content_ratings[key] / total_number_of_apps
percentage = proportion * 100
c_ratings_proportions[key] = proportion
c_ratings_percentages[key] = percentage
print(c_ratings_proportions)
print(c_ratings_percentages)This creates two new dictionaries: one for proportions and one for percentages. We can easily switch between different types of measurements, which lets us analyze our data in different ways. Here's what that output would look like:
{'4+': 0.43, '9+': 0.29, '12+': 0.14, '17+': 0.14}
{'4+': 42.86, '9+': 28.57, '12+': 14.29, '17+': 14.29}I've used these exact techniques to analyze our course completion rates at Dataquest by creating a frequency table to see how many students were completing each course. When I converted the raw numbers to percentages, we discovered our SQL courses had a lower completion rate than our Python courses. This insight led us to revamp our SQL curriculum, making it more engaging and practical. Within a few months, we saw the SQL completion rates improve significantly.
If you're working with data, I encourage you to try using frequency tables with dictionaries. They're a simple yet powerful way to summarize and understand your data. Here are some tips to get you started:
- Identify what you want to count in your dataset.
- Create a dictionary to store your counts.
- Loop through your data, updating the dictionary as you go.
- Consider converting your frequencies to proportions or percentages for easier interpretation.
- Use separate dictionaries for different types of measurements (counts, proportions, percentages) to keep your data organized.
Remember, frequency tables are just one tool in your data analysis toolkit, but they're one I find incredibly useful in my day-to-day work. They can help you quickly identify patterns, outliers, and trends in your data, providing a solid foundation for deeper analysis.
In the final lesson of this tutorial, we'll explore how to combine all the concepts we've learned so far to tackle more complex data analysis tasks. You'll see how loops, conditionals, and dictionaries work together to create powerful data processing pipelines.
Lesson 6 – Bringing It All Together
By combining loops, conditionals, and dictionaries, we can create sophisticated data analysis workflows that can handle complex, real-world datasets. Let me share a recent experience from my work at Dataquest that illustrates this perfectly.
We wanted to analyze student engagement across all our courses, looking at factors like course score, time spent on lessons, and the number of attempts made on practice problems. This task required us to use all the concepts we've discussed above.
Here's a simplified version of the code we used:
course_data = [
['Python Basics', [80, 85, 90, 75, 88]],
['SQL Fundamentals', [70, 65, 72, 68, 74]],
['Data Visualization', [85, 92, 88, 90, 95]]
]
course_stats = {}
for course in course_data:
course_name = course[0]
scores = course[1]
total_score = 0
num_students = len(scores)
for score in scores:
total_score += score
avg_score = total_score / num_students
if avg_score >= 85:
performance = 'Excellent'
elif avg_score >= 70:
performance = 'Good'
else:
performance = 'Needs Improvement'
course_stats[course_name] = {
'average_score': avg_score,
'performance': performance
}
print(course_stats)This code does several things:
- It loops through each course in our dataset.
- For each course, it calculates the average score using a nested loop.
- It uses conditional statements to categorize the course performance based on the average score.
- Finally, it stores all this information in a dictionary, with the course name as the key and another dictionary containing the statistics as the value.
When we run this code, we get output like this:
{'Python Basics': {'average_score': 83.6, 'performance': 'Good'},
'SQL Fundamentals': {'average_score': 69.8, 'performance': 'Needs Improvement'},
'Data Visualization': {'average_score': 90.0, 'performance': 'Excellent'}}This dictionary gave us a clear overview of how each course was performing. With it, we could quickly see which courses were doing well and which ones needed our attention. As mentioned earlier, we noticed that our SQL Fundamentals course needed some optimizations, which led us to revise the curriculum and add more interactive elements to boost student engagement.
By combining loops, conditionals, and dictionaries in this way, we were able to process a complex dataset and extract meaningful insights that directly impacted our course development strategy. This is the power of Python for data analysis―it allows you to take raw data and transform it into actionable information.
As you continue to develop your Python skills, you'll find more and more ways to combine these concepts to solve complex data problems. Here are some tips to keep in mind as you work on your own projects:
- Start simple: Begin with a basic version of your analysis and gradually add complexity.
- Break down your problem: Identify the different steps you need to take and tackle them one at a time.
- Use meaningful variable names: This will make your code easier to read and debug.
- Comment your code: Explain what each section does, especially for complex operations.
- Test as you go: Run your code frequently to catch and fix errors early.
Remember, becoming proficient in data analysis with Python is a journey. Each project you work on will teach you something new and help you refine your skills. Don't be afraid to experiment and try new approaches―that's how you'll grow as a data analyst.
Advice from a Python Expert
As we wrap up this tutorial, I hope you've gained a deeper understanding of how Python's basic operators and data structures can transform your approach to data analysis. We've explored for loops, conditional statements, and dictionaries, seeing how each can be used to efficiently process and analyze data. More importantly, we've seen how combining these tools can lead to powerful, flexible data analysis workflows.
Throughout this post, we've used real-world examples and learning material from the Dataquest platform to illustrate these concepts. From analyzing course completion rates to categorizing mobile apps, these examples show how Python can be applied to solve actual data challenges. The skills you've learned here are the same ones I use daily in my work, and they form the foundation of more advanced data science techniques.
Remember, the key to becoming proficient in Python for data analysis is practice. Start by applying these concepts to your own datasets. Can you use a for loop to automate a repetitive task? Could conditional statements help you categorize your data more effectively? Might a dictionary provide a more intuitive way to store and access your information?
As you continue to develop your skills, you'll find that these fundamental concepts open doors to more advanced topics in data science. They're the building blocks that will allow you to tackle machine learning, data visualization, and complex statistical analyses.
If you're excited to dive deeper into Python for data analysis, I encourage you to check out the Basic Operators and Data Structures in Python course at Dataquest. This course expands on the concepts we've covered here, providing hands-on practice with real-world datasets and expert guidance to help you take your skills to the next level.
Remember, every data scientist, from beginners to experienced professionals, is on a continuous learning path. The Dataquest Community is particularly supportive, so don't hesitate to seek help when you need it. With each line of code you write and each dataset you analyze, you're building a skillset that can uncover valuable insights and drive important decisions. So keep exploring, stay curious, and enjoy the adventure that Python and data science offer. Who knows what new discoveries await you?
Frequently Asked Questions
How can Python for loops enhance efficiency in data analysis tasks?
for loops enhance efficiency in data analysis tasks?Python for loops are a fundamental tool that can significantly boost efficiency in data analysis tasks. By automating repetitive operations, processing large datasets quickly, and performing complex calculations with ease, for loops make data analysis more efficient.
When working with extensive datasets, for loops prove particularly useful. For instance, you can use a for loop to process information about multiple apps, each represented as a list within a larger list:
app_data_set = [row_1, row_2, row_3, row_4, row_5]
rating_sum = 0
for row in app_data_set:
rating = row[-1]
rating_sum = rating_sum + rating
print(rating_sum)This loop efficiently calculates the sum of ratings for all apps in the dataset, demonstrating how for loops can handle large amounts of data with just a few lines of code. This is especially helpful when working with large datasets, as it saves time and effort.
The benefits of using for loops in data analysis are numerous. They:
- Automate repetitive tasks, freeing up time and effort for more complex analysis.
- Enable efficient processing of large datasets, making it easier to work with extensive data.
- Allow complex calculations across multiple data points, providing deeper insights into the data.
- Reduce the risk of manual errors in your analysis, ensuring more accurate results.
In my experience analyzing course data, I've used for loops to calculate average completion times for each lesson in a course. This helped us identify which lessons were taking longer than expected, allowing us to optimize our course content and improve the learning experience for our students.
When using for loops, keep the following tips in mind:
- Start with basic loops and gradually increase complexity as you become more comfortable with the syntax.
- Use descriptive variable names to make your code more readable and easier to understand.
- Pay attention to indentation, as Python uses it to define the body of the loop.
- Consider using
enumerate()if you need both the index and value of items in your loop.
Although for loops are incredibly useful, they may become less efficient with very large datasets. In such cases, you might need to consider more advanced techniques like list comprehensions or vectorized operations.
By combining for loops with other Python concepts like conditional statements and dictionaries, you can create powerful data analysis workflows, process data more efficiently, and uncover insights that might be missed with manual analysis.
In what ways do conditional statements contribute to decision-making in Python programs?
Conditional statements are a fundamental part of Python programming, allowing programs to make decisions based on specific conditions. As a data analyst, I've found that using if, else, and elif statements is essential for creating flexible and responsive workflows.
In my experience, these statements significantly contribute to decision-making in Python programs by enabling code to execute different blocks based on whether certain conditions are met. This capability is particularly useful when categorizing data, filtering out irrelevant information, or handling various scenarios in analysis.
When working on data analysis projects, I often use conditional statements to segment data into meaningful categories. For example, I might categorize course performance based on how learners rated it or average completion rates. This approach allows me to gain more nuanced insights from our data.
The benefits of using conditional statements in data analysis are numerous. They provide the flexibility to adapt analyses based on different data characteristics, improve efficiency by focusing on relevant subsets, and enhance data categorization capabilities. I've found that these features are particularly useful when dealing with complex datasets that require sophisticated filtering or when creating dynamic reports that adjust based on specific criteria.
To get the most out of conditional statements, it's essential to understand how to use them effectively. By incorporating these tools into your analytical toolkit, you'll be well-equipped to tackle a wide range of data challenges and extract meaningful insights from your datasets.
How do Python dictionaries differ from lists when it comes to organizing and accessing data?
Python dictionaries and lists are both powerful data structures, but they serve different purposes. When working with data in Python, it's essential to understand the strengths of each.
Lists are ordered collections of items that you can access by their position, or index. They're ideal for storing sequences of data where the order matters. For example, you might use a list to store a series of app ratings:
ratings = [3.5, 4.0, 4.5, 3.5]On the other hand, dictionaries store data as key-value pairs. They're unordered, and you access them by their keys, which can be more meaningful than numerical indices. Dictionaries are perfect for organizing data with natural pairings. For instance, you could use a dictionary to store content ratings and their frequencies:
content_ratings = {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}When accessing data, lists use numerical indices, while dictionaries use keys. This makes dictionaries more intuitive for certain types of data and often more efficient for lookup operations.
In data analysis, lists are often used for storing raw data or sequences of related items. They're particularly useful when you need to maintain a specific order or when you're dealing with homogeneous data. Meanwhile, dictionaries excel at creating frequency tables, organizing complex datasets, and storing data that needs to be accessed by meaningful identifiers.
For example, when analyzing course data, you might use a list to store individual student scores for a particular course. However, a dictionary would be more suitable for organizing overall course statistics:
course_stats = {
'Python Basics': {'average_score': 83.6, 'performance': 'Good'},
'SQL Fundamentals': {'average_score': 69.8, 'performance': 'Needs Improvement'}
}This structure allows for quick and intuitive access to specific course data.
In more complex data analysis tasks, you might combine both structures. For instance, you could use a dictionary to store multiple lists, where each list represents a different attribute of your data.
While dictionaries offer more flexible data organization and faster lookup times for large datasets, they don't maintain order like lists do. Lists also allow for easy iteration over elements in a specific sequence, which can be important in certain analytical processes.
To choose the right data structure for your needs, consider the following: if order matters and you need to access elements by position, use a list. If you need to organize data with meaningful keys and want fast, intuitive access to values, use a dictionary. Both are essential tools in Python for data analysis, and understanding their strengths will help you make the right choice for your specific analytical needs.
How can conditional statements be applied to categorize data stored in lists or dictionaries?
Conditional statements are a powerful tool in Python that let you make decisions in your code based on specific criteria. When working with data structures like lists or dictionaries, these statements become especially useful for categorizing information.
For instance, you can use conditional statements to group mobile apps based on their user ratings. By setting up a series of conditions (like "if rating is less than 3.0" or "if rating is between 3.0 and 4.0"), you can automatically sort apps into categories such as "below average," "average," or "above average."
This approach offers several benefits for data analysis:
- Flexibility: You can easily adjust categories or thresholds to suit your analysis needs.
- Clarity: The categorization logic is straightforward and easy to understand.
- Efficiency: You can process large datasets quickly and consistently.
- Customization: You can create as many categories as needed for your specific analysis.
When using conditional statements for data categorization, keep these tips in mind:
- Use clear and meaningful category names to make your analysis more intuitive.
- Ensure your conditions cover all possible values to avoid uncategorized data.
- Consider using ranges instead of exact comparisons for numerical data to account for potential variations.
By becoming proficient in using conditional statements, along with other basic operators and data structures in Python, you can create more sophisticated data analysis workflows. This skill allows you to extract meaningful insights from your datasets, segment data effectively, and make informed decisions in various fields, from market analysis to user behavior studies.
What advantages do dictionaries offer when creating frequency tables for data analysis?
When working with Python, dictionaries can be a powerful tool for creating frequency tables in data analysis. Their key-value pair structure makes them well-suited for counting and categorizing data efficiently.
One significant benefit of using dictionaries is the speed at which you can look up and update values. This is particularly useful when building a frequency table, as you can quickly check if an item exists and update its count. This approach is much faster than searching through a list, especially when dealing with large datasets.
For example, consider creating a simple frequency table for content ratings. You can use the following code:
ratings = ['4+', '4+', '4+', '9+', '9+', '12+', '17+']
content_ratings = {}
for c_rating in ratings:
if c_rating in content_ratings:
content_ratings[c_rating] += 1
else:
content_ratings[c_rating] = 1This code efficiently counts each rating's occurrences, resulting in a clear frequency table.
In a real-world application, I used this technique to analyze course completion rates at Dataquest. By creating a frequency table of completion statuses, we were able to identify which courses needed improvement. This led to revisions in the curriculum that significantly increased completion rates.
Dictionaries also make it easy to convert raw counts to proportions or percentages, providing different perspectives on your data. However, it's worth noting that dictionaries don't maintain order, which may be important for some analyses.
Overall, dictionaries provide an efficient and intuitive way to create frequency tables in Python, making them a valuable tool for data analysts working with large datasets and complex categorization tasks. Their flexibility and speed make them a reliable choice for many data processing and analysis tasks.
How does combining for loops, conditionals, and dictionaries lead to more powerful data analysis workflows?
Combining for loops, conditionals, and dictionaries in Python enables more efficient and flexible data analysis. This approach allows you to process large datasets, make decisions based on specific criteria, and organize results in a structured manner.
To illustrate this, let's consider an example. Suppose you want to analyze a dataset of mobile apps. You can use a for loop to iterate through the dataset, apply conditional statements to categorize the apps based on price or rating, and store the results in a dictionary for easy access and further analysis.
Here's how this might work:
- A
forloop processes each app in the dataset. - Conditional statements categorize the app based on its price or rating.
- The results are stored in a dictionary, with the app name as the key and its category as the value.
By combining these concepts, you can create sophisticated data processing pipelines that can handle complex, real-world datasets. The benefits of this approach include:
- Efficient processing of large amounts of data
- Flexibility in applying various criteria to your analysis
- Improved organization of results
- Ability to handle complex data structures
In real-world applications, this technique can be used to analyze student performance across multiple courses, categorize products based on various attributes, or process and summarize large datasets from scientific experiments.
While this approach is powerful, it's essential to consider potential challenges, such as maintaining code readability and optimizing performance for very large datasets. As you work with basic operators and data structures in Python, practice combining these concepts to create more sophisticated analysis workflows.
By mastering the combination of for loops, conditionals, and dictionaries, you'll be able to tackle more complex data analysis tasks and extract meaningful insights from your data more effectively, setting a strong foundation for advanced data science techniques.
Can Python dictionary values be both mutable and immutable?
When working with Python dictionaries, it's essential to understand that the values they store can be either mutable or immutable. This flexibility makes dictionaries a powerful tool in data analysis.
Immutable values, such as strings and numbers, are commonly used in dictionaries. For example, consider a dictionary used to analyze app content ratings:
content_ratings = {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}In this case, both the keys (strings) and values (integers) are immutable, meaning their contents cannot be changed after creation.
On the other hand, dictionary values can also be mutable objects, such as lists or other dictionaries. For instance, in a course analysis, you might use a dictionary with mutable values:
course_stats[course_name] = {
'average_score': avg_score,
'performance': performance
}Here, the value is another dictionary, which can be modified.
The choice between mutable and immutable values depends on your specific needs. Immutable values are useful when you want to ensure data integrity and store fixed information, such as the number of apps in each content rating category.
In contrast, mutable values allow for more dynamic data structures. They're beneficial when you need to update or expand information associated with a key. For example, using a nested dictionary in the course analysis enables you to store and update both the average score and performance rating for each course.
However, when working with mutable values, be cautious: changes to the value will affect all references to that object. This can lead to unexpected behavior if not managed carefully.
By understanding the properties of dictionary values, you can create more efficient and effective data analysis workflows. For instance, you can use immutable values for static data like frequency counts and mutable values for more complex, updateable data structures like course statistics.
By leveraging this flexibility, you can tailor your data structures to the specific requirements of your analysis tasks and achieve better results.
What is an effective way to iterate through a list stored as a value in a Python dictionary?
When working with complex data structures in Python, you may need to iterate through a list stored as a value in a dictionary. One way to do this is by combining dictionary key access with a for loop.
Let's consider an example from a course performance analysis. Suppose we have a list of courses with scores, and we want to process each score. Here's how you can do it:
course_data = [
['Python Basics', [80, 85, 90, 75, 88]],
['SQL Fundamentals', [70, 65, 72, 68, 74]],
['Data Visualization', [85, 92, 88, 90, 95]]
]
for course in course_data:
course_name = course[0]
scores = course[1]
for score in scores:
# Process each scoreThis code demonstrates how to access a list within a larger data structure and iterate through its elements. The outer loop goes through each course, while the inner loop processes individual scores.
When working with lists stored in dictionaries, it's essential to consider the nested nature of the data. Before attempting to iterate through the list, make sure you're accessing the correct key in the dictionary.
By using this approach, data analysts can efficiently process complex, nested data structures in Python programs. This skill is fundamental for tasks such as calculating averages, identifying patterns, or applying transformations to datasets stored in multi-level data structures.
What tips can you share for using dictionaries effectively in data analysis projects?
Dictionaries are valuable tools for organizing and analyzing data in Python, offering flexibility and efficiency in handling complex datasets. Here are some tips for using them effectively in your data analysis projects:
-
Use descriptive keys: Create self-documenting dictionaries by using clear, meaningful keys. This improves readability and makes your code easier to understand.
-
Maintain consistency: When representing similar objects with dictionaries, keep the structure consistent. This facilitates working with multiple dictionaries and performing comparisons.
-
Combine with other data structures: Dictionaries can contain lists or even other dictionaries, allowing for complex data representation. This flexibility enables you to create sophisticated data structures tailored to your analysis needs.
-
Use dictionaries for frequency tables: Dictionaries are well-suited for creating and manipulating frequency tables. For example:
ratings = ['4+', '4+', '4+', '9+', '9+', '12+', '17+']
content_ratings = {}
for c_rating in ratings:
if c_rating in content_ratings:
content_ratings[c_rating] += 1
else:
content_ratings[c_rating] = 1This code efficiently counts the occurrences of each rating. You can then easily convert these counts to proportions or percentages:
total_apps = len(ratings)
for rating in content_ratings:
content_ratings[rating] = content_ratings[rating] / total_appsUse dictionaries to store complex data: In real-world applications, dictionaries can store multi-dimensional data. For instance, when analyzing course performance, I would typically use nested dictionaries like this:
course_stats[course_name_1] = {
'average_score': avg_score_course_1,
'performance': performance_course_1
course_stats[course_name_2] = {
'average_score': avg_score_course_2,
'performance': performance_course_2
course_stats[course_name_3] = {
'average_score': avg_score_course_3,
'performance': performance_course_3
}This structure allows you to store and access multiple attributes for each course easily.
I've used these techniques to analyze course completion rates, creating a frequency table to see how many students were completing each course. By converting raw numbers to percentages, we discovered that SQL courses had a lower completion rate than Python courses, leading to curriculum improvements.
While dictionaries are powerful, it's essential to be aware of their limitations. They can consume more memory than simpler data structures, and their lack of order might be inconvenient for certain analyses. Additionally, when working with large datasets, consider using specialized libraries like pandas for more efficient data manipulation.
By implementing these tips and being mindful of potential limitations, you can make the most of dictionaries in your data analysis workflows. They provide a flexible and intuitive way to organize, access, and analyze complex datasets, making them a valuable tool for any data analyst working with Python.
How can frequency tables created with dictionaries help identify patterns and trends in datasets?
Frequency tables created with dictionaries are a great way to summarize your data and identify patterns and trends. By counting the occurrences of different values, they provide a clear picture of your data's distribution, making it easier to spot common themes or unusual outliers.
To create a frequency table using a dictionary in Python, you start with an empty dictionary and iterate through your dataset. For each value, you either increment its count if it's already in the dictionary or add it with an initial count of 1 if it's not. This process efficiently tallies the frequency of each unique value:
ratings = ['4+', '4+', '4+', '9+', '9+', '12+', '17+']
content_ratings = {}
for c_rating in ratings:
if c_rating in content_ratings:
content_ratings[c_rating] += 1
else:
content_ratings[c_rating] = 1This frequency table helps identify patterns by showing the distribution of content ratings. You can quickly see which ratings are most common and which are rare. For example, you might notice that a particular rating is more prevalent than others, indicating a trend in the data.
To gain a deeper understanding of these trends, you can convert these raw counts to proportions or percentages. This transformation allows you to compare distributions across different-sized datasets or track changes over time. For instance, you might find that 42% of apps have a '4+' rating, revealing a trend towards family-friendly content.
I've used this technique to analyze course completion rates, creating a frequency table to see how many students were completing each course. By converting raw numbers to percentages, we discovered that SQL courses had a lower completion rate than Python courses. This insight led to curriculum improvements and ultimately increased completion rates.
Dictionaries are particularly effective for creating frequency tables because they allow for fast lookups and updates. This makes them a valuable tool for working with large datasets. By combining dictionaries with Python's basic operators and data structures, you can quickly summarize your data, identify key patterns, and make informed decisions in your analysis work.