Introduction to Python Programming
Python has become a cornerstone of data science and data analysis, opening doors to exciting career opportunities for those willing to learn. As someone who started as a Dataquest student and now oversees Python course development, I've seen firsthand how learning Python can transform your data career. In this tutorial, I'd like to show you how an introduction to Python programming can help you with that.
My learning journey began with an early version of Dataquest's introduction to Python programming course. And honestly, I was skeptical about learning yet another programming language on top of R and SQL. But what I didn't realize was how the decision to learn Python would shape my career path, eventually leading me to my current role. That experience taught me a valuable lesson that you can quote me on:
blockquote p { margin: 0; position: relative; z-index: 1; }
Python is accessible to anyone willing to learn, regardless of their background.
Now, you might be wondering, "Why should I learn Python when I already know SQL?" This is a great question and something I had to ask myself too. Although SQL is excellent for querying databases and handling large datasets, Python is capable of so much more. It's like having a multipurpose data tool at your fingertips for performing a wide array of data tasks efficiently. With Python, you can manipulate data, perform complex analyses, create stunning visualizations, automate repetitive tasks, and even create machine learning and AI tools. Don't get me wrong, knowing SQL is still an important skill, but having Python in your pocket means you can automate a lot of your workflows and solve problems that SQL can't.
Let me give you a practical example of this. To help our learners decide if they're ready to enroll in a particular course or not, we recently added a prerequisites section to each of our course pages. Rather doing this course by course, I wrote a Python script to automate the process. This simple script saved me and my team hours of manual work. And that's the great thing about Python—it's not just for working on big complex data science tasks—it's a practical tool that can make your daily work more efficient and enjoyable.
Now, if you're feeling a bit intimidated by the prospect of learning Python, don't worry. It's more approachable than you might think, especially when you're learning with structured learning resources like ours. In this tutorial, we'll start you off with the basics:
- An introduction to Python programming
- Working with Python variables
- Understanding Python data types
- Leveraging the power of Python lists
As you explore Python throughout this tutorial, remember that anyone can learn it, regardless of their background. Whether you're a complete beginner or coming from another programming language, Python's intuitive syntax and supportive community make it easy to learn. And the best part? Once you've got the basics down, you'll be well-positioned to venture into exciting fields like machine learning and AI, where Python truly dominates.
In the first lesson below, we'll explore Python programming, covering the fundamental concepts that will start you on your journey to becoming a proficient data analyst or data scientist. We'll look at how to write your first Python program, understand the structure of Python code, and start thinking like a programmer. Let's get started!
Lesson 1 – Python Programming
When I first started learning Python, I wasn't sure it was going to be worth it. But as I started applying it to real-world data problems, I was amazed at how quickly it transformed the way I approach data analysis. Now, with several years of experience, I can confidently say that Python has transformed the way I approach data analysis and has optimized many of my workflows.
But before we get into any actual code, let's define some terms so that we're all on the same page. When we write Python code, we program the computer to do something. For this reason, we also call the code we write a program. The code we write serves as input to the computer and we call the result of executing the code output.
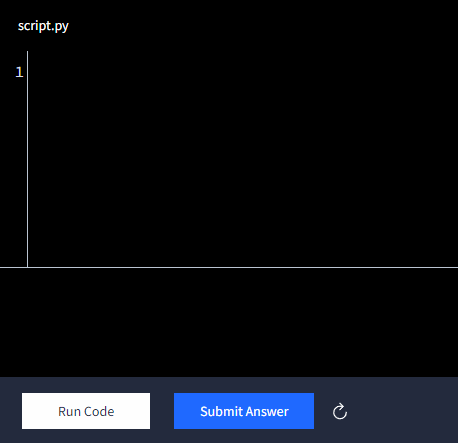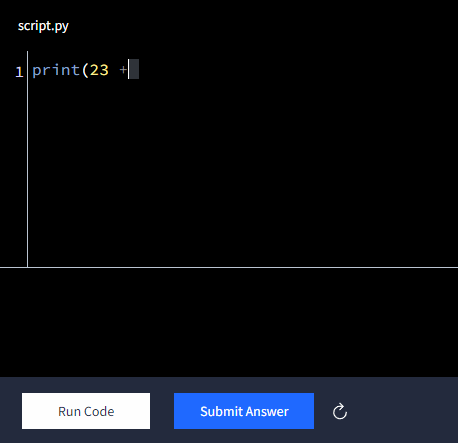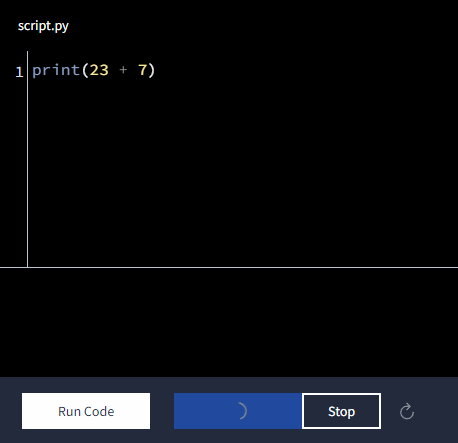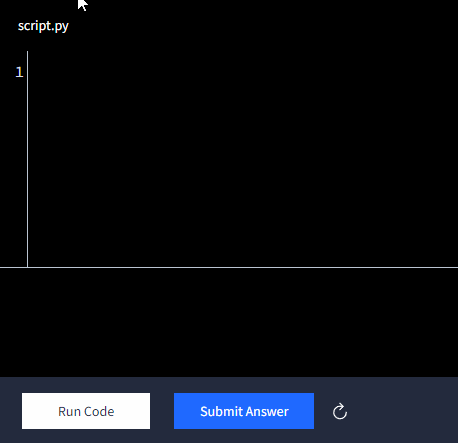
Let's start with some basic code. Python's syntax is designed to be readable and intuitive. If we give this as input:
print(23 + 7)As demonstrated in the animation above, when we execute (run) this code, we'll get this as output:
30You can almost read this code like a sentence: "Print the result of 23 plus 7." This readability is one of the reasons why Python is so popular for data analysis. When you're working with complex datasets or intricate algorithms, having code that's easy to understand and maintain is invaluable. In my daily work, I use similar syntax to analyze student progress data, calculate course completion rates, and identify areas for improvement in our curriculum.
Let's try another example:
print(0.00 + 6.99)
print(4.5 - 3.5)Running this code gives us:
6.99
1.0While these are basic arithmetic operations, they illustrate Python's clarity and simplicity. In real-world data analysis, you'll use similar principles to calculate averages, identify trends, or process large datasets. For instance, when I'm analyzing our course data, I might use Python to calculate the average time students spend on each lesson, or to find the correlation between practice exercises completed and overall course performance.
If you're just starting out with Python programming, here's my advice: start small, but be consistent. Begin by modifying the simple programs we've looked at here. Change the numbers, try different operations. Make it a goal to write a few lines of Python code every day. You'll be surprised how quickly you progress.
As you become more comfortable with Python, you'll discover its true power in data science. If you enroll in our Data Scientist in Python Certificate Program, you'll learn to use libraries like Pandas for data manipulation, Matplotlib for creating visualizations, and Scikit-learn for implementing machine learning algorithms. I've seen students go from writing simple print statements to building complex predictive models in a matter of months.
Learning Python is more than just adding a skill to your resume. It's about transforming the way you approach data problems. It allows you to automate repetitive tasks, uncover insights from complex datasets, and even predict future trends. Whether you're looking to enhance your current role or transition into a data-focused career, Python provides the foundation you need.
If you're just starting your data science journey, learning Python is one of the best investments you can make. Its gentle learning curve allows you to start writing useful code quickly, while its depth ensures that you'll always have more to learn and explore.
As we continue with this tutorial, we'll explore specific Python concepts that are particularly useful for data analysis. Next, we'll look at how to work with variables in Python, a fundamental skill that forms the backbone of any data analysis task.
Lesson 2 – Python Variables

Ok, now let's talk about one of the most fundamental concepts in Python programming: variables. In Python, variables are like labeled boxes that contain information. They're essential in data analysis because they help us store, manipulate, and analyze data efficiently without having to work with numbers directly, like the coding examples above did.
In my early days of learning to program, the concept of variables clicked for me when I realized how they line up with the way we think about data in the real world―they tend to be variable. Let me show you what I mean with a couple of simple examples:
result = 3.98
print(result)Output
3.98In this code, we're assigning the value 3.98 to a variable named result―kind of like labeling a box with result and putting 3.98 inside it. Then, when we tell Python to print(result), it looks for the box with the label result and shows us what's inside. But here's the real power of Python variables: whenever we need that value again, rather than having to remember it, we can just ask Python to look for the box labeled result and it takes care of the rest for us.
Another powerful aspect of using variables is their flexibility. We can update them as our data changes and as we perform calculations on them. Here's another example:
app_costs = 1.99
print(app_costs)
app_costs = 6.99
print(app_costs + 3)Output:
1.99
9.99As you can see, we first set app_costs to 1.99, but then updated it to 6.99 + 3 (hence the 9.99 output). This ability to change variable values is essential when you're analyzing data that evolves over time or when you're performing calculations with them.
At Dataquest, we use variables constantly in our work. As I mentioned in the introduction above, I recently created a Python script to automate the process of writing prerequisites for each of our courses. By using variables to store course information like difficulty level, topic, and required skills, I built a system that allows my team to work with descriptive names that make sense rather than (what appear to be) random numbers. Again, when it comes to Python programming, readability makes a big difference―especially when working with others.
If you're just starting out with Python variables, here are a few tips I can share with you:
-
Choose descriptive names for your variables. For example, use
total_salesinstead of justts. This makes your code more readable and easier to understand. -
Understand variable types. Python can store different kinds of data in variables―numbers, text, lists, and more―but at any given moment, a variable holds one specific type of data. We'll get into the specifics on Python data types in the next lesson.
-
Break down complex calculations using multiple variables to store intermediate results. This makes your code easier to debug and understand.
-
Experiment with updating variables and observe how it affects your code output. This will help you understand how data flows through your program, which is essential for working with data.
As you become more comfortable with variables, you'll see how they form the foundation for more advanced concepts. They're essential for everything from basic data cleaning and transformation to complex machine learning algorithms.
In the next lesson, we'll explore different data types in Python, which will help you understand what kind of information you can store in variables. This knowledge will be crucial as you move into more advanced techniques. But for now, I encourage you to experiment with variables in your own Python code. Try creating variables to store different types of data, update them, and use them in calculations. You might be surprised at how experimenting with variables can open up new possibilities in your learning journey!
Lesson 3 – Python Data Types

Time to explore the fundamental data types in Python: integers, floats, and strings. Understanding these data types is essential for working with variables and being able to work with your data.
First, let's take a look at numbers. Python has two main types:
- integers: any whole number, including 0 and negative numbers
- Examples: -42, 314, 0, -15, 1
- floats: any number that use a decimal point, including 0 and negative numbers
- Examples: 3.14, -2.5, 0.0, -7.7777, 149.00
Here's a simple example of how Python handles these when performing calculations:
print(6.99 * 1)
print(0.0 + 1.99)Output:
6.99
1.99Notice how Python maintains precision (decimal places) even when multiplying by a whole number. This level of precision is vital in data analysis, where small differences can lead to significant insights.
You might wonder how you can determine the data type of the number you're working with. We can use the type() function to find out:
print(type(0))
print(type(0.0))Output:
int
floatThis distinction is important because different data types can produce unexpected results in your calculations. For example, when I was working on a program that involved a series of calculations, I was expecting my result to be a float, but I kept getting an integer instead. I was scratching my head until I added a couple of well-placed type() commands. That’s when I realized I was passing an integer like 5 instead of a float like 5.000 in one part of my calculation. The type() command showed me exactly what was going wrong. Once I used 5.000, I got the float result I needed. It’s a mistake you only make once... well, maybe twice, but figuring it out gets easier each time!
Now, let's discuss strings. In Python, we use strings to represent text data. They're incredibly versatile and essential for tasks like processing survey responses or analyzing social media data. Here's how we create strings:
app_name = "Facebook"
currency = "USD"
print(app_name)
print(currency)Output:
Facebook
USDStrings can be manipulated in many ways, like joining them together or extracting parts of them. This flexibility makes them powerful tools for text analysis.
In a project at Dataquest, we analyzed user feedback on our courses using Python. We processed thousands of comments, using string operations to clean the data and integer counts to quantify their overall sentiment. The ability to seamlessly work with both text and numerical data made Python the perfect tool for the job.
Here are a few tips that might help you when working with these data types:
- Always check the type of data you're working with. Use
type()if you're unsure. It's saved me from many headaches! - When dealing with financial data, be cautious with floats due to potential rounding errors. The
decimalmodule is useful for high-precision calculations. - Remember that strings are immutable in Python. This means you can't change them in-place, but you can create new strings based on operations on existing ones.
Understanding these basic data types is just the start. As you continue your data science journey, you'll see how these fundamentals play into more complex operations. A solid grasp of these concepts makes tasks like data cleaning, statistical analysis, and even machine learning algorithms much more manageable.
In the next lesson, we'll explore how to organize and structure these data types using Python lists. This will open up even more possibilities for data manipulation and analysis.
Lesson 4 – Python Lists

Now that we've covered variables and how they hold specific types of data, let's take a closer look at one of Python's most versatile data structures: lists. Unlike variables, which store a single value at a time, lists can hold multiple items of different types all at once. This makes them incredibly useful when you're working with complex datasets, like a row in a table or a collection of values. For many learners, understanding lists marks a significant milestone—it’s often the moment when Python transforms from abstract code to a practical tool they can use to solve real-world problems.
For the reasons mentioned above, lists in Python are incredibly flexible. Let's consider an example:
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
print(row_1)
print(type(row_1))This code creates a list called row_1 that contains information about the Facebook app. When we run it, we get:
['Facebook', 0.0, 'USD', 2974676, 3.5]
<class 'list'>Our list contains a mix of strings, integers, and floats. This flexibility is what makes lists so useful in data science. We can use them to represent rows in a dataset, where each element might be a different type of information.
Now that we've seen lists in action, let's talk about accessing and manipulating the data within them. In Python, we use indexing to retrieve specific elements from a list:
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
print(row_1[0])
print(row_1[4])Running this code gives us:
Facebook
3.5Here, we're accessing the first element (the app name) and the last element (the user rating) of our list. Notice that Python uses what's called zero-based indexing, so the first element is at located at index 0, not 1.
I recall a project at Dataquest where I truly appreciated the power of list indexing. We were analyzing course completion rates across hundreds of courses. Each course had a list of data similar to our Facebook app example above. By using indexing, I could efficiently extract specific pieces of information (like the course name or the completion rate) for each course. This allowed us to quickly identify trends and areas for improvement in our curriculum.
If you're new to lists, here are some tips you might find helpful:
- Use descriptive names for your lists: Instead of using
row_1, consider usingfacebook_app_datainstead. - Remember that list indexing starts at 0: This is a common source of confusion for beginners.
- Use negative indexing to access elements from the end of the list: For example,
row_1[-1]gives you the last element, 3.5. - Experiment with nested lists (lists within lists) to represent more complex data structures: For example, you could have a list of courses, where each course in the list is itself a list that stores attributes specific to that course.
As you become more comfortable with lists, you'll find they're essential for many Python data analysis tasks. They're the foundation for more complex data structures and are used extensively in popular data science libraries like pandas. Lists are also particularly useful in preparing data for machine learning models, where you often need to organize and manipulate large datasets efficiently.
For now, I encourage you to experiment with creating and indexing your own lists. Try representing different types of data and see how you can use indexing to extract the information you need. The more you practice, the more natural and powerful this fundamental Python skill will become.
Take a moment to review what you’ve practiced so far, and remember that every small step brings you closer to mastering Python. Next, we’ll explore advice on how to keep building on these skills and take your Python proficiency to the next level.
Advice from a Python Expert
Throughout this tutorial, we've explored the essential building blocks of Python programming: variables, data types, and lists. While these concepts may seem straightforward, they form the foundation for complex data analysis, machine learning models, and AI applications. By mastering these basics, you'll be able to create efficient, scalable solutions for real-world data challenges.
If you're coming from a SQL background, you'll find that Python amplifies your data manipulation capabilities. It's not about replacing your current skills, but expanding your toolkit to tackle more complex problems.
Python is a powerful tool that can transform the way you approach data problems. Whether you're looking to enhance your current role or transition into a data-focused career, Python provides the foundation you need.
For those just starting with Python, my advice is to set achievable goals and build momentum. Commit to writing a few lines of code every day, and you'll be surprised by how quickly you'll be automating tasks, creating insightful visualizations, and uncovering patterns in complex datasets. The field of data science is constantly evolving, and Python skills will help you stay at the forefront of these exciting developments.
At Dataquest, I use Python daily to analyze student data and optimize our curriculum. This constant application to real-world problems continues to deepen my appreciation for its power and versatility. I encourage you to find similar opportunities in your own work or personal projects.
You're probably just beginning your Python journey, and so the possibilities are endless. Whether you're automating a simple task or building a complex AI tool, remember that every expert was once a beginner. If you're ready to take the next step, consider exploring structured learning resources like our Introduction to Python Programming course at Dataquest.
Remember, everyone's journey with Python is unique. You might face challenges, but each obstacle you overcome is a step towards becoming a more proficient data analyst or scientist. The Dataquest Community is particularly supportive, so don't hesitate to seek help when you need it.
Frequently Asked Questions
What are the key concepts covered in an introduction to Python programming course?
If you're new to Python, you might wonder what to expect from an introductory course. As someone who's learned Python and now helps develop courses, I can share some insights on what you'll typically cover. Here are the key concepts you'll encounter:
-
Python Syntax: You'll start by learning how to write your first Python program, understanding how to structure code and use basic operations like printing output. For example, you might start with simple commands like
print(23 + 7)to get a feel for how Python processes instructions. -
Variables: Variables are essential in Python, as they store information that you can use and manipulate in your code. You'll learn how to create, name, and work with variables, which is important for handling data efficiently in analysis tasks.
-
Data Types: Python uses several basic data types, including integers, floats, and strings. Understanding these data types is essential for working with different kinds of data, from numerical analysis to text processing.
-
Lists: Lists are versatile structures that can store multiple items of different types. You'll learn how to create and manipulate lists, which are useful for representing complex data sets in your analyses.
-
Basic Operations: You'll use Python for calculations and learn how to perform various operations on your data.
These concepts form the foundation for more advanced Python applications in data science. For instance, I recently applied these basics to automate our course prerequisite writing process, saving hours of manual work. As you progress, you'll find yourself using these skills to clean data, perform statistical analyses, and even build machine learning models.
Keep in mind that everyone starts with these basics, regardless of their background. With consistent practice and application to real-world problems, you'll be surprised at how quickly you can advance from printing "Hello, World!" to extracting valuable insights from complex datasets. The journey of learning Python for data analysis is exciting and full of possibilities.
How do Python variables function, and why are they essential in data analysis?
Python variables are like labeled boxes that store information, forming the foundation of data analysis in Python programming. Having seen how variables help transform raw data into meaningful insights, I can attest to their importance.
In Python, creating a variable is straightforward:
result = 3.98
print(result)Output:
3.98This code assigns the value 3.98 to a variable named result. When we print it, Python retrieves the stored value.
So, why are variables essential in data analysis? For one, they allow us to store and manipulate data efficiently. Additionally, using descriptive variable names makes our code more readable and maintainable. We can also update variable values as our data changes or as we perform calculations.
For example, when I automated our course prerequisite writing process, I used variables to store course information like difficulty level and required skills. This allowed me to work with meaningful names rather than abstract numbers, making the code more intuitive and easier to debug.
Variables in Python can hold different types of data, from numbers to text, which is incredibly useful when working with diverse datasets. Whether you're calculating average course completion rates or analyzing user feedback, variables provide the flexibility to handle various data types seamlessly.
As you progress in your Python programming journey, you'll see how these simple "boxes" form the building blocks for more complex data structures and analysis techniques. This foundation will pave the way for advanced concepts like machine learning and AI applications in data science.
Can you provide an example of how Python variables are used in real-world data tasks?
Python variables are a fundamental part of data analysis tasks. They serve as containers for storing and manipulating various types of information. When you're just starting to learn Python programming, understanding variables is essential for working efficiently with data.
Here's a simple example of how variables are used in Python:
result = 3.98
print(result)Output:
3.98This code assigns the value 3.98 to a variable named result. When you run this program, Python retrieves and displays the stored value, making it easy to work with throughout your analysis.
In real-world data tasks, variables offer several benefits. For one, they allow you to store and update values as your data changes. You can also perform calculations using meaningful names instead of abstract numbers. This makes complex datasets more manageable when organized into variables.
Let's consider an example. Imagine you're analyzing some app data. You might create variables like this:
app_name = "Facebook"
app_price = 0.0
currency = "USD"
num_ratings = 2974676
avg_rating = 3.5Using descriptive names like these makes it easier to work with your data. Instead of trying to remember what each number or string represents, you can focus on the insights you want to gain from your analysis. You can then easily use these variables in calculations or comparisons, such as finding apps with ratings above the average or comparing prices across different currencies.
As you continue to learn Python programming, you'll see how variables work together with other concepts like data types and lists to form the foundation of data analysis. Understanding variables is a key step in developing your Python skills and tackling more complex data challenges efficiently.
What are the main differences between integers, floats, and strings in Python?
In Python programming, understanding the three fundamental data types―integers, floats, and strings―is essential for effective data analysis. These building blocks form the foundation of more complex operations in Python.
Let's start with integers. Integers are whole numbers, including 0 and negative numbers. For example, -42, 314, and 0 are all integers. On the other hand, floats are numbers that use a decimal point, such as 3.14, -2.5, and 0.0. When performing calculations, Python maintains precision with floats:
print(6.99 * 1) # Output: 6.99
print(0.0 + 1.99) # Output: 1.99Strings represent text data in Python. They're incredibly versatile and essential for tasks like processing survey responses or analyzing social media data. We create strings by enclosing text in quotation marks:
app_name = "Facebook"
currency = "USD"Understanding these data types is important when working with variables in Python. For instance, when analyzing app data, we might use a combination of these types:
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]Here, we have two strings (app name and currency), floats (price and rating), and an integer (number of ratings) all in one list.
A helpful tip is to always check the type of data you're working with using the type() function. This can prevent errors and ensure your code behaves as expected when manipulating different data types, especially when dealing with complex datasets in real-world data analysis projects.
By understanding these basic data types, you'll be well-prepared to tackle more advanced concepts in Python programming, from data cleaning and transformation to complex machine learning algorithms.
Why is understanding data types important when working with data in Python?
Understanding data types is essential when working with data in Python. It directly impacts how we manipulate and analyze information. When I teach Python programming, I always emphasize three basic data types: integers (whole numbers), floats (decimal numbers), and strings (text data).
These data types are fundamental because they determine how Python processes and stores information. For example, when performing calculations, using integers instead of floats can lead to unexpected results due to integer division. I once spent hours debugging a data processing script because I was using integer division instead of float division!
To illustrate this, consider the following simple code:
print(6.99 * 1)
print(0.0 + 1.99)The output maintains precision:
6.99
1.99This level of precision is vital in data analysis, where small differences can lead to significant insights. Moreover, understanding data types helps us choose the right operations for our data. We can't perform mathematical operations on strings, for instance. By using the type() function, we can quickly check the data type we're working with and avoid errors in our analysis.
In real-world data analysis, being aware of data types is essential for tasks like data cleaning, statistical analysis, and even machine learning. For example, at Dataquest, we analyzed user feedback on our courses using Python, processing thousands of comments. We used string operations to clean the text data and integer counts to quantify sentiment.
A useful tip: when working with financial data, be cautious with floats due to potential rounding errors. The decimal module is useful for high-precision calculations in such cases.
Understanding these basic data types lays the groundwork for more complex operations in data science. As you progress in your Python journey, you'll see how this fundamental knowledge plays into advanced concepts like data structures, algorithms, and machine learning models, making your data analysis more efficient and accurate.
How can Python lists be utilized to organize and structure data effectively?
Python lists are powerful tools for organizing and structuring data. They can store multiple items of different types, making them ideal for storing mixed data.
For example, you can create a list like this:
['Facebook', 0.0, 'USD', 2974676, 3.5]This list contains various pieces of information about an app: its name, price, currency, number of ratings, and average rating. By using lists, you keep related data together, simplifying manipulation and analysis tasks.
One of the key benefits of lists is their flexibility. They can store different data types in one structure, making them useful for a wide range of applications. Additionally, lists provide easy access to individual elements using indexing, and they can represent rows in a dataset. This simplifies data manipulation tasks and makes it easier to work with mixed data types.
In real-world data analysis, lists are useful for:
- Storing and processing survey responses
- Organizing time series data for trend analysis
- Preparing datasets for machine learning models
- Representing hierarchical data structures
To get the most out of lists, follow these best practices:
- Choose descriptive names for your lists (e.g.,
facebook_app_datainstead ofrow_1) - Remember that indexing starts at 0
- Experiment with nested lists for more complex data structures
As you work with lists in Python, you'll find that they form the foundation for more advanced data structures and are extensively used in popular data science libraries. By effectively using lists, you can handle complex datasets more efficiently and extract meaningful insights from your data.
What are some practical applications of Python lists in data science projects?
Python lists are incredibly versatile tools in your data analysis toolkit. They're one of the first things you'll learn in an introduction to Python programming, and for good reason. Lists can hold multiple items of different types, making them perfect for storing mixed data.
For instance, in one of my projects, I used a list like this:
['Facebook', 0.0, 'USD', 2974676, 3.5]This single list contained various pieces of information about an app: its name, price, currency, number of ratings, and average rating. By using lists, I could keep related data together, which made manipulation and analysis much more straightforward.
In my data science projects, I've found lists to be invaluable for various tasks, including:
- Storing and processing survey responses
- Organizing time series data for trend analysis
- Preparing datasets for machine learning models
- Representing hierarchical data structures
One of the benefits of lists is how easy they make it to access individual elements using indexing. When I was analyzing course completion rates across hundreds of courses at Dataquest, I used list indexing to efficiently extract specific pieces of information for each course. This allowed us to quickly identify trends and areas for improvement in our curriculum.
To get the most out of lists in your own projects, consider the following tips:
- Choose descriptive names for your lists (e.g.,
facebook_app_datainstead ofrow_1) - Remember that indexing starts at 0 (it's a common source of confusion for beginners)
- Experiment with nested lists for more complex data structures
As you progress in your Python journey, you'll find that lists form the foundation for more advanced data structures and are extensively used in popular data science libraries. Lists are a fundamental tool that you'll use throughout your career in data analysis and machine learning. They're not just a basic concept―they're a powerful tool that can help you work more efficiently and effectively.
How does Python complement SQL for data manipulation and workflow automation?
As someone who has worked with both SQL and Python, I've discovered that these two languages complement each other beautifully in data analysis. While SQL excels at querying databases, Python offers a wide range of possibilities for processing and analyzing data.
When I first started learning Python, I was impressed by its ability to handle complex data tasks. For example, I created a Python script to automate our course prerequisite writing process. This simple automation saved my team hours of manual work each week, which would have been challenging to achieve with SQL alone.
Python's strengths lie in its ability to clean, transform, and analyze data in ways that go beyond SQL's capabilities. With libraries like pandas, you can easily process data and perform tasks such as text cleaning and numerical analysis. For instance, when I analyzed user feedback on our courses, I used Python to process thousands of comments and quantify sentiment.
Python also excels at automating repetitive tasks. By creating scripts that can handle these tasks, you can free up your time for more complex analyses. This is particularly useful when dealing with data that requires multiple processing steps or when you need to repeat analyses regularly.
By combining SQL and Python skills, you'll have a powerful toolkit for data analysis. Use SQL to efficiently extract data from databases, and then leverage Python for advanced processing, visualization, and automation. This combination has transformed the way I approach data problems, making me more efficient and enabling me to tackle more complex challenges.
If you're just starting your Python journey, remember that it's accessible to anyone willing to learn, regardless of their background. With consistent practice and application to real-world problems, you'll soon see how Python can enhance your data analysis capabilities and open up new career opportunities in the field of data science.