The Data Engineering Roadmap for Beginners (2026)
Wondering how to become a data engineer? This complete data engineering roadmap shows you exactly what to learn, in what order, and how long it realistically takes, whether you're starting from scratch or transitioning from software development, data analysis, or another field.
Data engineering is the backbone of every data-driven company. Data engineers build the systems that move, transform, and store data: the infrastructure behind flight status apps, pharmacy notifications, accurate delivery estimates, machine learning models, and executive dashboards. It's not the flashy front-end work, but it's what makes everything else possible.
If you've been curious about breaking into data engineering but feel overwhelmed by where to start, you're in the right place. This roadmap covers the essential skills (Python, SQL, cloud platforms, orchestration tools), realistic timelines (8-12 months to job-ready), and exactly how to build a portfolio that gets you hired.
At Dataquest, we've helped thousands of learners become job-ready data engineers through our Data Engineer Career Path, which follows this exact progression with hands-on projects from day one. Let's get into it.
Why Data Engineering?
Before we get into how to become a data engineer, let's establish why it's worth your investment.
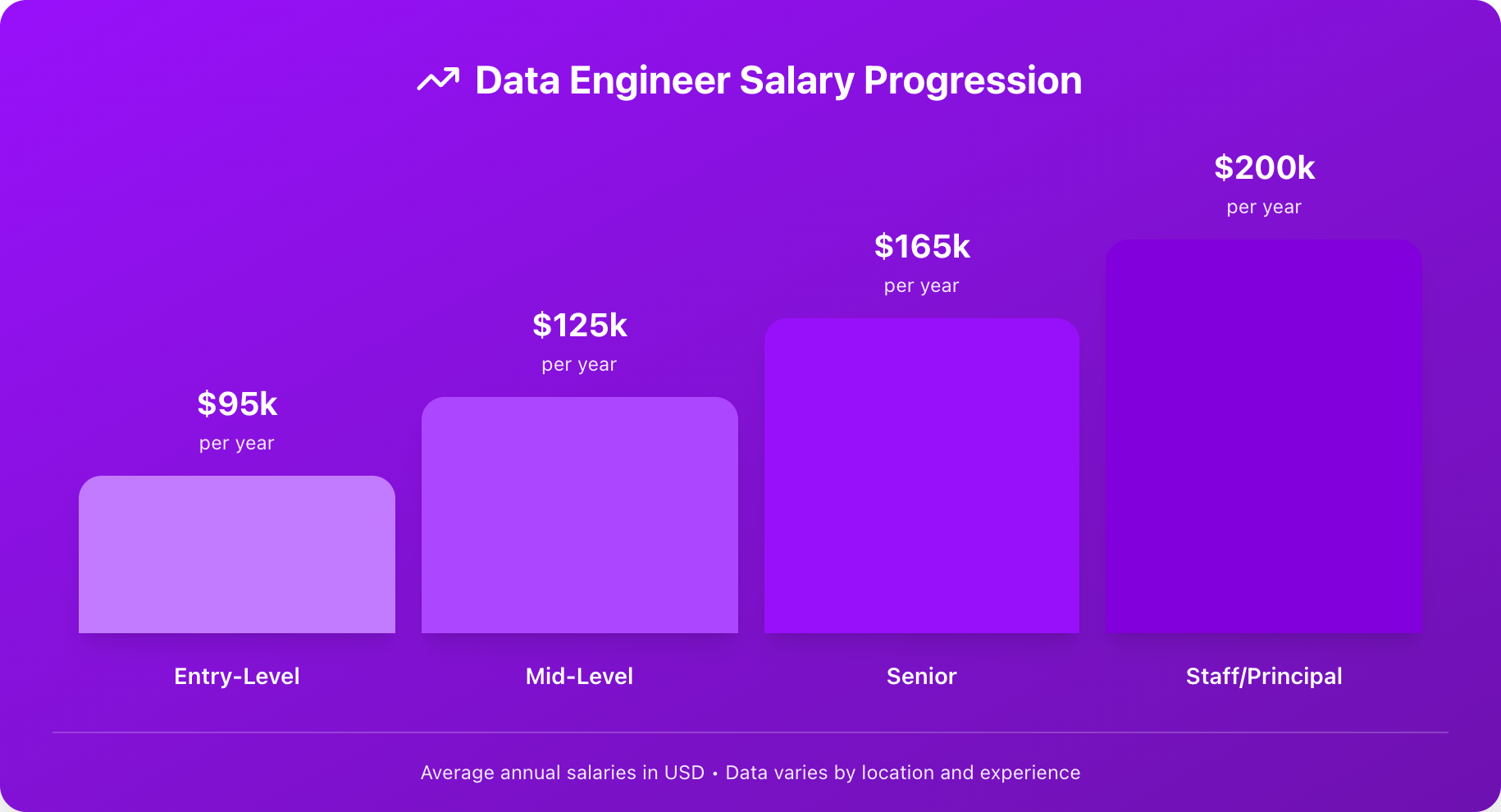
- The compensation is excellent. Data engineers in the United States earn a median total pay of around \$131,000 per year, according to Glassdoor data from January 2026. Entry-level positions typically start between \$90,000-\$110,000, while senior data engineers often exceed \$160,000. In high-cost-of-living areas like San Francisco or New York, compensation can be significantly higher. Data engineer salaries increase by roughly \$30K-40K at each career level, as shown in the chart below.
- Demand is outpacing supply. The StartUs Insights Data Engineering Market Report 2025 states that the data engineering industry experienced a growth rate of 22.89% in the last year, the global workforce exceeded 150,000 employees, and last year's growth added over 20,000 professionals. The World Economic Forum's 2025 Future of Jobs Report identified big data specialists as among the fastest-growing jobs in technology.

Companies across every industry (finance, healthcare, retail, tech, and manufacturing) are hiring data engineers faster than the talent pipeline can fill.
- The skills are transferable and future-proof. AI isn't replacing data engineers; it's creating more work for them! Every AI model needs clean, well-structured data pipelines feeding it. The fundamentals you'll learn (SQL, Python, distributed systems, data modeling) remain relevant even as specific tools evolve.
- The work is meaningful. Data engineers don't just write code, they enable entire organizations to make better decisions. That sales dashboard the CEO uses? A data engineer built the pipeline behind it. That fraud detection model saving millions? It runs on an infrastructure designed by a data engineer.
What Does a Data Engineer Actually Do?
Data engineering job descriptions are packed with intimidating buzzwords such as ETL pipelines, distributed systems, and data orchestration. But what does the work actually feel like? What will you spend your hours doing? Let's cut through the jargon and look at the reality.
A Day in the Life of a Data Engineer
Let's walk through a realistic Tuesday for a mid-level data engineer at a mid-sized tech company. This isn't glamorized—it's the genuine mix of problem-solving, collaboration, and building that makes up the role.
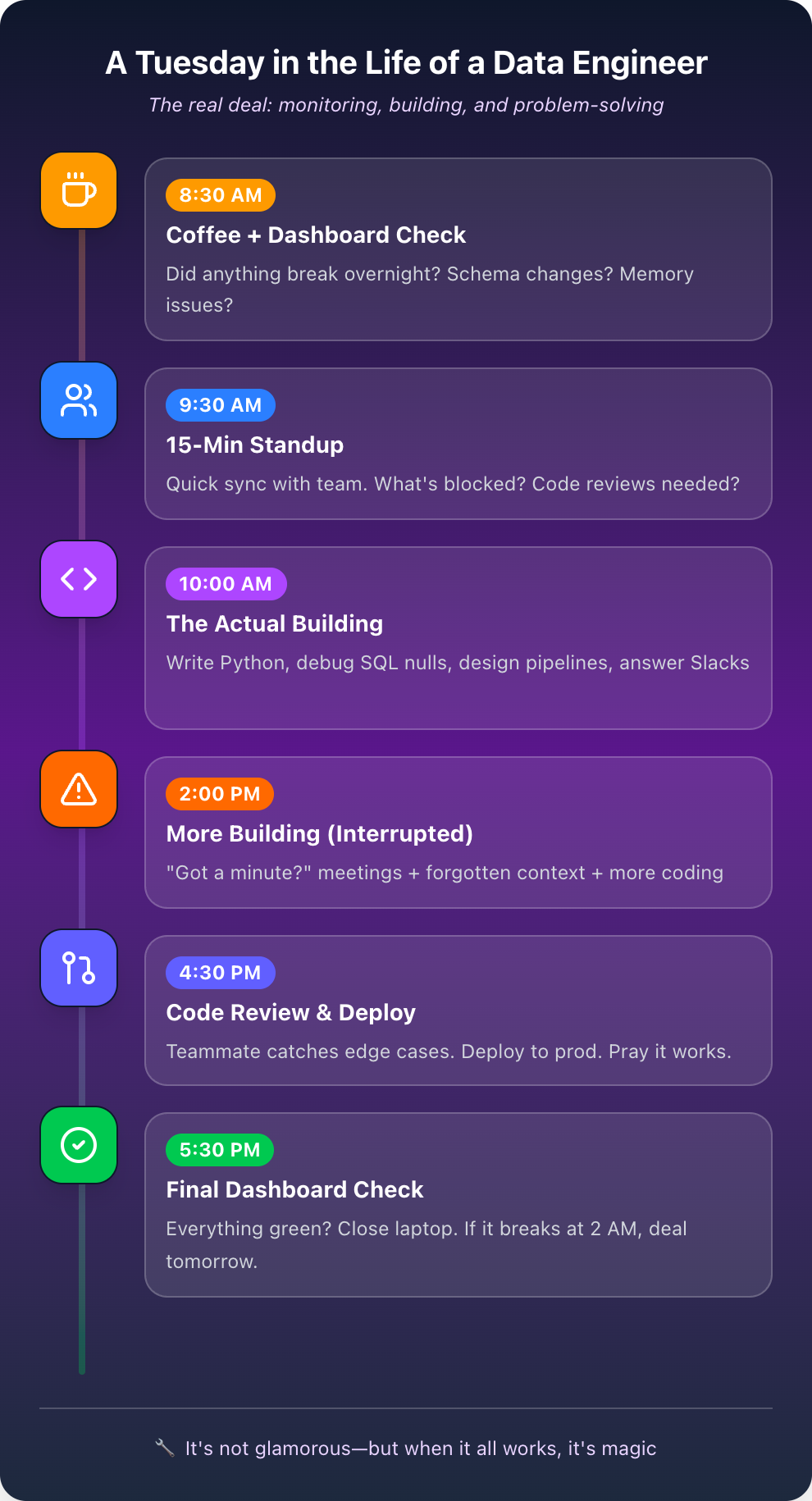
If you love solving puzzles, building systems, and enabling others to do their best work, data engineering might be perfect for you. Let's break down the specific responsibilities in more detail.
Core Responsibilities
The data engineer role involves designing systems, solving problems, collaborating with other teams, and keeping infrastructure running smoothly. These five responsibilities make up most of your work, though the balance shifts depending on your company's size and maturity.

Data Engineer vs. Related Roles
Data engineering overlaps with several other data roles, which causes confusion when you're trying to figure out your career path. You'll work alongside data scientists, analysts, and DevOps engineers, where sometimes your responsibilities blur together. But each role has a distinct focus. Here's how the data engineer role compares to the roles you'll hear about most often.
| Role | Primary Focus | Example Deliverable | Key Difference |
|---|---|---|---|
| Data Engineer | Building data infrastructure | Automated ETL pipeline processing 1M records/hour | You build the systems others use |
| Data Scientist | Extracting insights with ML | Customer churn prediction model | You analyze data that engineers prepared |
| Data Analyst | Business intelligence and reporting | Quarterly sales trends dashboard | You interpret data for stakeholders |
| DevOps Engineer | Application reliability | CI/CD pipeline for software releases | You focus on apps; data engineers focus on data systems |
The line between these roles gets fuzzy sometimes, but think of it this way: data engineers build the roads and bridges that move data reliably from place to place. DevOps engineers build and maintain the cities, traffic systems, and power grids that keep those roads running smoothly at scale. Data analysts and data scientists are the people who drive on those roads, analysts to understand what’s happening and report on it, and scientists to explore, experiment, and get somewhere interesting.
Is Data Engineering Right for You?
Data engineering isn't for everyone, and that's okay. Before investing months of your time learning these skills, it's worth asking whether the day-to-day reality matches what you're looking for in a career.
Let’s see if you’d enjoy the day-to-day work of a data engineer, and whether it fits your working style.
How Long Will This Take?
Your path to becoming a data engineer depends on where you're starting from and how much time you can dedicate to learning. Someone with programming experience will move faster than a complete beginner—and that's okay. Here's a realistic breakdown based on your background and available study time.
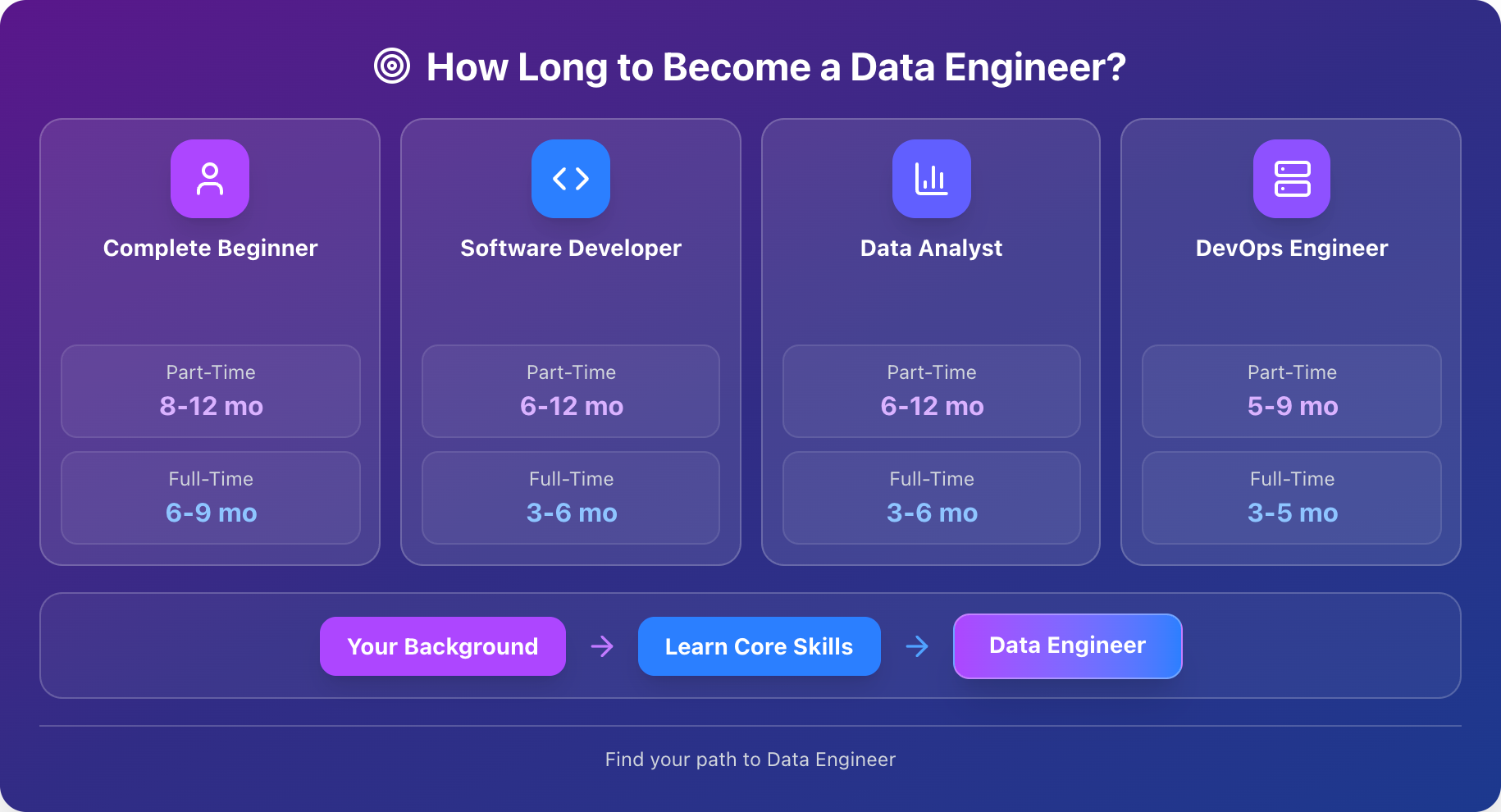
Starting From Scratch (No Programming Experience)
Your timeline:
- 5 hrs/week → 8-12 months
- 10-15 hrs/week → 4-6 months
- 20+ hrs/week → 3-4 months
This is the longest path, but it's absolutely achievable. You'll need to build everything from the ground up: programming fundamentals, SQL, command line comfort, and then the data engineering-specific skills. The good news? You're learning with fresh eyes and won't have to unlearn bad habits.
Your focus: Start with Phase 1 and don't rush it. Python and SQL fundamentals are your foundation since everything else builds on them.
Transitioning From Software Engineering
What you already have: Strong programming skills, system design and architecture understanding, comfort with Git, command line, and debugging.
What to focus on: SQL proficiency (if you've been doing mostly application development, your SQL might be weaker than you think), data-specific tools like ETL patterns, Airflow, and data warehouses, plus data modeling and schema design for analytics workloads.
The biggest shift is mindset: you're building infrastructure for data, not applications for users. The reliability and performance concerns are similar, but the patterns are different.
Your timeline:
- 5 hrs/week → 4-6 months
- 10+ hrs/week → 2-4 months
Transitioning From Data Analysis
What you already have: SQL expertise (probably your biggest advantage), business understanding and stakeholder communication skills, experience working with data, and understanding what questions matter.
What to focus on: Python programming for building automated pipelines (versus one-off ad-hoc queries), cloud platforms and infrastructure concepts, workflow orchestration for scheduling and monitoring pipelines.
The shift is from answering questions with data to building systems that enable others to answer questions.
Your timeline:
- 5 hrs/week → 5-8 months
- 10+ hrs/week → 3-5 months
Transitioning From DevOps Engineering
What you already have: Cloud platform expertise, CI/CD experience and infrastructure-as-code skills, system monitoring and troubleshooting abilities.
What to focus on: SQL and data manipulation (this might be your biggest gap), ETL patterns and data-specific tools, data modeling concepts.
Many of your infrastructure skills transfer directly. The shift is from application infrastructure to data infrastructure.
Your timeline:
- 5 hrs/week → 4-6 months
- 10+ hrs/week → 2-4 months
Note: These are guidelines, not guarantees. Your actual timeline depends on how quickly concepts click, whether you hit any major roadblocks, and how consistent you are with practice. The key insight: even 5 hours a week adds up faster than you'd think—and consistency beats intensity every time.
The Complete Data Engineering Roadmap
Now that you understand the role and confirmed this career fits you, let's map out your learning journey.
This roadmap is designed for someone starting from scratch. If you're transitioning from software engineering, data analysis, or a related field, you'll move through some sections faster and we'll cover specific transition paths later.
Realistic timeline: With consistent, focused study, you can become job-ready in 8-12 months. Dataquest's Data Engineering Career Path is designed to get you there in about 8 months at just 5 hours per week—that's less than an hour a day. If you can dedicate more time (10-15 hours per week), you could compress that timeline to 6 months.
If 8-12 months feels long to you, just remember that you're learning skills that command a median salary of \$131,000 per year. Investing a few months to build a career that will serve you for decades is one of the best decisions you can make, and 5-10 hours a week is genuinely manageable alongside a full-time job or other commitments.
Your Learning Plan at a Glance
Here's the full roadmap in one view. Each phase builds on the previous one, taking you from foundational skills to job-ready data engineer.
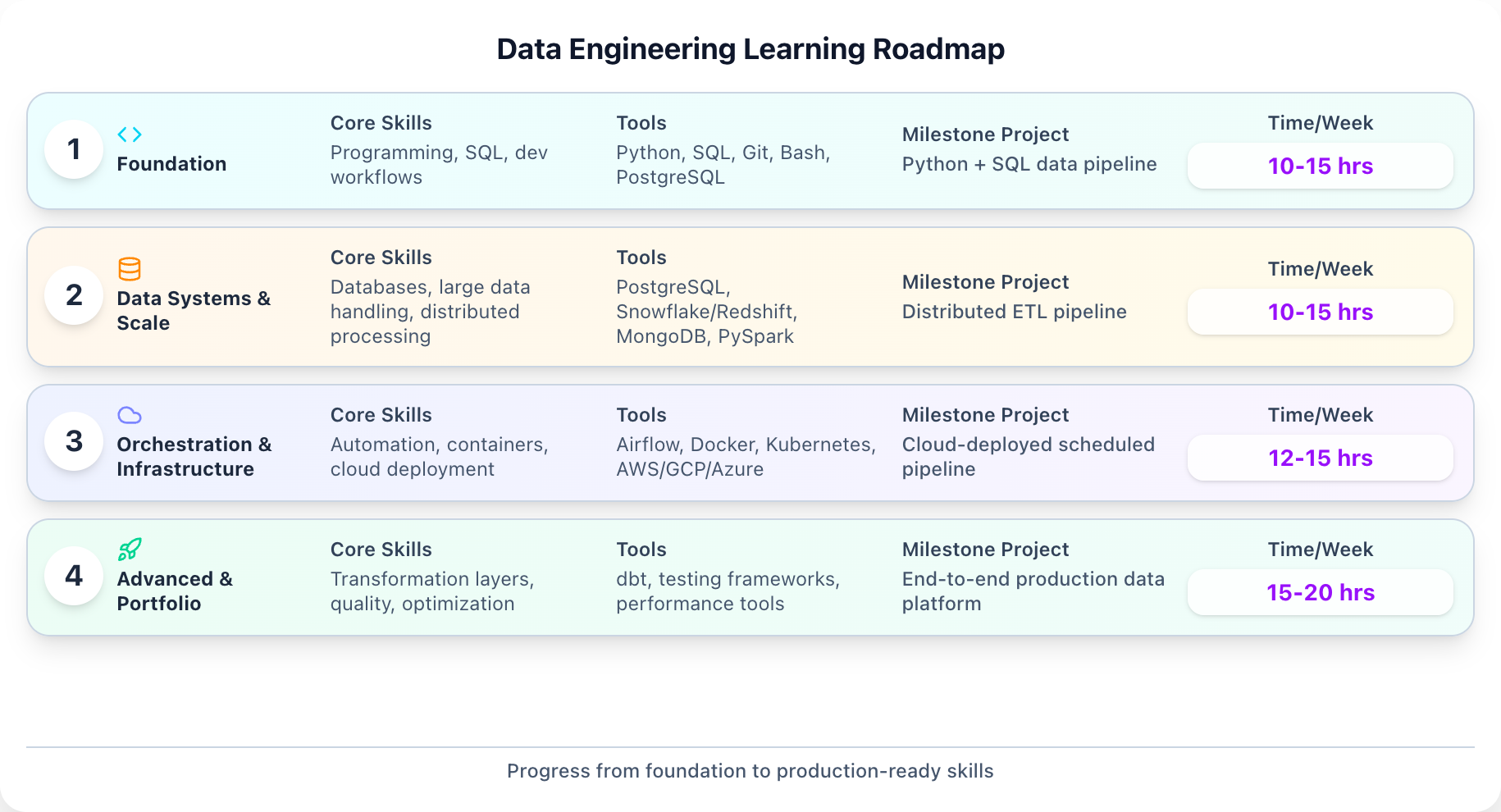
Note: This is a guideline, not a rigid prescription. Life happens—jobs get demanding, family needs attention, and motivation ebbs and flows. What matters is consistent forward movement, even if some weeks are slower than others.
The Data Engineering Tech Stack: What You'll Learn
Here's a visual overview of the tools and technologies you'll explore on this roadmap. Don't worry if these names are unfamiliar because that's exactly what this guide is for.
Phase 1: Build Your Foundation
Timeline: 2-3 months
Every data engineer relies on these fundamentals daily. This phase focuses on learning how to write code, work with data, and operate like an engineer. Don't rush through it as these skills are the foundation everything else builds on.
Skill: Python Programming
Why it matters
Python is the primary language for data pipelines and automation. You'll need to learn Python to connect to APIs, transform data, orchestrate workflows, and interact with cloud services. You don't need to become a software engineer, but you need solid Python fundamentals.
What to learn
Start with core syntax: variables, loops, conditionals, and functions. These are the building blocks of every program you'll write. Move on to data structures—lists, dictionaries, and sets are everywhere in data engineering. You'll also need to get comfortable with file I/O (reading and writing CSV, JSON, and other formats) and basic error handling so your scripts don't crash when something unexpected happens.
Don't worry about advanced topics like decorators or metaclasses yet. Focus on writing clean, readable code that does what you need it to do. If you're just starting out, our guide on Why Learn Data Engineering explains how programming fits into the bigger picture.
How to practice
Try Project Euler—a collection of mathematical and programming problems designed to stretch your thinking. The problems range from approachable to genuinely difficult, and solving them builds both your Python fluency and algorithmic problem-solving skills.
For structured practice with immediate feedback, work through the exercises in our Python for Data Engineering Fundamentals course and Intermediate Python for Data Engineering.
Timeline: 1 month
Skill: Command Line and Version Control
Why it matters
Most data engineering work happens in terminals, not graphical interfaces. You'll ssh into servers, run scripts, manage files, and interact with cloud services through the command line. And learning Git isn't optional because it's how teams collaborate on code, track changes, and avoid disasters.
What to learn
Start with navigating the filesystem: changing directories, listing files, creating and removing folders. Learn to use pipes and redirects to chain commands together. Basic Bash scripting will save you hours once you can automate repetitive tasks.
For Git, focus on the fundamentals: initializing repositories, staging and committing changes, creating branches, and merging. Understand how to resolve merge conflicts (you will encounter them). Learn to work with GitHub or GitLab for remote collaboration.
How to practice
Try Oh My Git!, a free game that turns version control into an interactive puzzle. You'll visualize how Git actually works under the hood while practicing commits, branches, merges, and more. It's a surprisingly fun way to build Git fluency.
Timeline: 2-3 weeks
Skill: SQL – Working with Relational Data
Why it matters
SQL is arguably the single most important skill for data engineers. It's the primary interface to production data you'll use it for extraction, transformation, validation, and analysis. Job postings for data engineers almost universally list SQL skills as a requirement.
What to learn
Start with the fundamentals of SQL : SELECT statements, filtering with WHERE, and sorting with ORDER BY. Move to joins (inner, left, right, full) and aggregations (GROUP BY with COUNT, SUM, AVG). These cover probably 70% of the SQL you'll write daily.
Then level up with subqueries and common table expressions (CTEs), which let you write complex queries in readable chunks. Window functions are essential for calculations across rows—rankings, running totals, and moving averages. Don't skip these; they come up constantly.
How to practice
Find a dataset you're interested in (sports statistics, movie ratings, public health data) and ask questions about it. Which players had the highest scoring improvement year-over-year? What movies have the biggest gap between critic and audience ratings? Real questions make practice more engaging than arbitrary exercises.
Timeline: 2-3 weeks
Milestone Project
This project proves you can write Python code, work with SQL databases, use the command line, and manage code with version control. It's also your first portfolio piece.
Build a simple data pipeline that reads raw CSV data with Python, cleans and transforms it (handle missing values, standardize formats, derive new columns), loads the results into a PostgreSQL database, and documents the whole project in a Git repository with a clear README.
Need a starting point? Our guided projects Analyzing CIA Factbook Data and Answering Business Questions with SQL walk you through similar workflows with real data.
Phase 2: Data Systems and Scale
Timeline: 4-5 months
With the basics in place, this phase focuses on how data engineering systems actually work at scale—production databases, handling large datasets, and distributed processing.
Skill: Production Databases and Data Warehousing
Why it matters
Data engineers design and operate data storage systems. You'll need to understand not just how to query databases, but how to design them: choosing the right database type for different workloads, structuring schemas for performance, and understanding the trade-offs between different approaches. Learning PostgreSQL is a great starting point.
What to learn
Deepen your knowledge of relational databases (PostgreSQL and MySQL are good choices). Learn about indexing, normalization vs. denormalization, and query execution plans.
Then expand to cloud data warehouses—Snowflake, Amazon Redshift, and Google BigQuery are the big players. These are optimized for analytical queries across massive datasets, and they work differently from traditional databases. Understand columnar storage, partitioning, and how pricing works (this matters more than you'd think).
Finally, learn the basics of NoSQL databases like MongoDB. Not every data problem fits neatly into rows and columns, and you should understand when and why to use document stores or key-value databases.
How to practice
Try SQL Murder Mystery, a free interactive game where you solve a murder case using SQL queries. You'll practice SELECT statements, JOINs, filtering, and aggregations while piecing together clues from a realistic database. It's a surprisingly addictive way to build SQL fluency.
Our PostgreSQL for Data Engineers course walks you through building production-ready database schemas with hands-on exercises.
Timeline: 1-2 months
Skill: Python for Large Datasets
Why it matters
Real-world datasets don't fit in memory. A single day's worth of transaction data might be gigabytes. Before reaching for distributed processing frameworks, you need to know how to handle larger-than-memory data with Python itself. Building strong NumPy and pandas skills is essential for this work.
What to learn
Get comfortable with NumPy fundamentals—vectorized operations are orders of magnitude faster than Python loops. Learn to process data in chunks rather than loading everything at once. Understand memory profiling so you can identify and fix bottlenecks.
Pandas is widely used but has memory limitations. Learn its tricks for reducing memory usage (downcasting dtypes, processing in chunks) and understand when you've outgrown it.
How to practice
Work through our Practice Optimizing DataFrames and Processing in Chunks guided project, which walks you through real optimization techniques on large datasets.
Practice these techniques systematically with our Pandas and NumPy Fundamentals course and Data Cleaning course, which include progressively larger datasets.
Timeline: 1-2 months
Skill: Distributed Data Processing
Why it matters
When datasets grow to tens of gigabytes or terabytes, single-machine processing isn't enough. Distributed processing frameworks let you spread work across clusters of machines. Learning Spark and PySpark is core to modern data engineering.
What to learn
Start with the concepts: how distributed computing works, what problems it solves, and what trade-offs it introduces (hint: distributed systems are harder to debug). Then focus on Apache Spark, specifically PySpark. Learn DataFrames, transformations, and actions. Understand lazy evaluation and why it matters for performance.
Write ETL pipelines that read from various sources, transform data using Spark operations, and write to destinations. Learn about partitioning and how to tune jobs for better performance.
How to practice
You can run Spark locally for learning purposes—you don't need a cluster to get started. Process increasingly large datasets and observe how performance changes. Try Databricks' free community edition for a managed environment.
Our Spark and Map-Reduce course provides a local Spark environment and guided exercises with real datasets.
Timeline: 2-3 weeks
Milestone Project
Build a distributed ETL pipeline that processes a large dataset (at least several gigabytes) using PySpark, performs meaningful transformations (aggregations, joins, data cleaning), loads results into a data warehouse or production database, and handles errors gracefully.
This demonstrates you can work with data at scale which is a key differentiator from analysts who work only with smaller datasets.
For hands-on practice with this workflow, check out our Building a Data Pipeline course, which demonstrates ETL at scale.

Phase: Orchestration and Infrastructure
Timeline: 3-4 months
At this stage, the focus shifts from "can it run?" to "can it run reliably, repeatedly, and in production?" These skills separate people who can write scripts from people who can build production systems.
Skill: Containerization and Cloud Deployment
Why it matters
Production systems run in containers and cloud environments, not on your laptop. Understanding Docker, Kubernetes (at least conceptually), and cloud platforms is essential for deploying and maintaining real data pipelines. Learning Docker is where most engineers start.
What to learn
Start with Docker: containerizing applications, writing Dockerfiles, managing images and containers. Understand why containers matter (reproducibility, isolation, deployment consistency).
Learn multi-container setups with Docker Compose. Then get an overview of Kubernetes concepts—pods, services, deployments—even if you won't be managing clusters yourself.
Finally, pick a cloud platform (AWS is most common, but Azure and GCP are also widely used) and learn its core data services: object storage (S3), compute (EC2/Lambda), and managed data services. Don't try to learn everything—focus on the services relevant to data engineering.
Timeline: 3-4 weeks
Skill: Workflow Orchestration
Why it matters
Real data pipelines don't run once—they run daily, hourly, or continuously. They have dependencies (pipeline B can't start until pipeline A finishes). They fail sometimes and need to retry. They need monitoring so you know when something goes wrong. Learning Apache Airflow is essential for handling all of this.
What to learn
Apache Airflow is the most widely used orchestration tool, and it's what you should learn first. Understand DAGs (directed acyclic graphs) and how they represent pipeline dependencies. Learn to schedule tasks, handle retries and failures, pass data between tasks, and set up alerting.
Beyond Airflow, be aware that alternatives exist (Prefect, Dagster, Luigi) and newer tools are gaining adoption. The concepts transfer across tools.
How to practice
Take one of your earlier projects and orchestrate it with Airflow. Instead of running your pipeline manually, schedule it to run automatically. Add error handling, retries, and notifications. Break the pipeline into logical tasks with clear dependencies.
Work through our Apache Airflow course, which includes setting up Airflow locally and building progressively complex DAGs.
Timeline: 1-2 months
Milestone Project
Containerize one of your data pipelines with Docker, orchestrate it with Airflow, deploy the whole setup to a cloud environment, and schedule it to run automatically with monitoring and alerting.
This project proves you can build production-grade data systems—exactly what employers are looking for.
You'll build exactly this kind of system in our Data Engineering Path's Cloud Computing course, which ties together everything from this phase.

Phase 4: Advanced Skills and Portfolio
Timeline: 2-3 months
This phase focuses on depth, reliability, and polish—the skills that separate junior engineers from job-ready candidates who can contribute immediately.
Skill: Transformation Layers and Analytics Engineering
Why it matters
Raw data is messy and hard to use. Clean, well-modeled data layers power analytics and decision-making. Modern data teams separate raw ingestion from business logic using tools like dbt (data build tool).
What to learn
Understand transformation patterns: staging layers, intermediate models, and final business-ready tables. Learn dbt for managing transformations as code—version-controlled, tested, documented. Understand dimensional modeling concepts for building analytics-friendly data structures.
How to practice
Take a raw dataset and build a complete transformation layer. Create staging models that clean the data, intermediate models that apply business logic, and final models that analysts would actually use. Document everything and write tests to validate your assumptions.
Timeline: 1-2 months
Skill: Data Quality and Optimization
Why it matters
Data engineers own data reliability. When dashboards show wrong numbers, you're the one who has to figure out why. And as data volumes grow, performance and cost optimization become increasingly important.
What to learn
Data validation and testing: checking for null values, validating data types, ensuring referential integrity, detecting anomalies. Query and pipeline optimization: reading execution plans, identifying bottlenecks, optimizing joins and aggregations. Monitoring and alerting patterns: what to track, how to set up alerts, how to respond when things break.
How to practice
Review your earlier projects with fresh eyes. Add comprehensive testing. Profile query performance and optimize slow spots. Set up monitoring that would catch real problems. Treat this as hardening your work for production.
Timeline: 1-2 months (and ongoing throughout your career)
Building Your Portfolio
Your portfolio is how employers see what you can actually do. Course certificates are nice, but projects prove skills.
What to include
Aim for 3-5 projects that show range. Each should live in its own GitHub repository with clear documentation: what problem it solves, how to run it, architecture decisions you made and why.
Include architecture diagrams for complex projects. Write about trade-offs you considered and challenges you overcame. If you're not sure where to start, our guide on building a data science portfolio project walks through the process step by step.
Every project from this roadmap contributes to your portfolio. The Phase 3 milestone—a containerized, orchestrated, cloud-deployed pipeline—is exactly what employers want to see.
One thing that sets the Dataquest Data Engineering Career Path apart: every course includes guided projects designed to build your portfolio as you learn. By the time you finish, you'll have 5+ substantial projects demonstrating real skills, not just certificates. Each project builds on the previous one, so your portfolio tells a coherent story of your growth as a data engineer.
Phase 4 Complete: Job-Ready
By the end of this phase, you'll have:
✅ Foundational skills: Python, SQL, Git, command line
✅ Data systems knowledge: databases, warehousing, distributed processing
✅ Production skills: orchestration, containers, cloud deployment
✅ Advanced capabilities: transformations, quality, optimization
✅ A portfolio of real projects demonstrating all of the above

Common Mistakes to Avoid
Learning data engineering is challenging. Here are the traps that slow people down—and how to sidestep them.
Mistake 1: Trying to Learn Everything at Once
What happens:
You see a job posting requiring Spark, Airflow, Kafka, dbt, Snowflake, Kubernetes, and three cloud platforms. You try to learn all of them simultaneously. You feel overwhelmed and make no real progress on anything.
The fix:
Master one skill before adding another. Follow this roadmap's phases sequentially. You don't need to know everything for your first job—you need to know the fundamentals really well and have the ability to learn new tools quickly. Employers understand that.
Mistake 2: Tutorial Hell
What happens:
You watch course after course, read tutorial after tutorial. You feel like you're learning because the content makes sense when you follow along. But when you try to build something yourself, you're lost.
The fix:
After every tutorial, close it and rebuild the project from scratch. Not from memory—from understanding. If you can't do it without the tutorial open, you haven't actually learned it yet. Dataquest's approach addresses this directly: you write code from day one with instant feedback, building muscle memory through practice rather than passive watching.
Mistake 3: Skipping Fundamentals
What happens:
You rush to the "exciting" tools—Spark, Airflow, cloud platforms—without solid Python and SQL foundations. You can follow tutorials for these advanced tools, but you hit walls constantly because you're missing basics.
The fix:
Spend three solid months on SQL and Python. It feels slow. It's not glamorous. But every data engineer uses these skills daily, and weak fundamentals will haunt you forever. Trust the process.
Mistake 4: Not Building Portfolio Projects
What happens:
You complete courses and learn skills, but you don't build projects you can show. Your resume says "Completed Coursera certificate" but there's no evidence of what you can actually do. Employers can't evaluate you.
The fix:
Build projects throughout your learning, not just at the end. Push everything to GitHub. Write documentation like you're explaining to a future employer. Treat every project like a job interview sample.
Mistake 5: Learning in Isolation
What happens:
You study alone. When you get stuck, you have no one to ask. Frustration builds, and you're more likely to quit when things get hard.
The fix:
Join communities. Reddit's r/dataengineering is active and helpful. The Dataquest community connects you with other learners. Ask questions when you're stuck. Share your progress. Learning alongside others makes the journey easier and more sustainable.
Mistake 6: Giving Up Too Soon
What happens:
You hit a concept that doesn't click, or you get rejected from jobs you applied to, or progress feels slower than you expected. You think "maybe I'm not cut out for this" and quit—often when you're closer to a breakthrough than you realize.
The fix:
Expect challenges. They're normal, not signs you're failing. Every working data engineer struggled through the learning phase. Job rejections are part of the process, not personal verdicts. Progress isn't linear—plateaus happen, and then things click.
The only difference between successful data engineers and people who gave up? The successful ones kept going.
Resources to Accelerate Your Learning
The roadmap tells you what to learn. These resources help you learn effectively.
For SQL practice:
- SQLZoo (interactive tutorials from basics to advanced)
- SQL Murder Mystery (solve a crime using queries)
- Window Functions Practice (dedicated practice for window functions)
- HackerRank SQL (challenges ranked by difficulty)
- PostgreSQL Exercises (real database problems to solve)
- Dataquest SQL Cheat Sheet (quick reference for common queries)
For Python:
- Project Euler (mathematical programming challenges)
- Advent of Code (annual coding puzzles, great for problem-solving)
- Exercism Python Track (practice with mentorship)
- Real Python (practical tutorials on specific topics)
- Dataquest Python Cheat Sheet (syntax and functions at a glance)
For project data:
- Kaggle Datasets (thousands of datasets across every domain)
- Dataquest's Guide to Free Datasets (curated list with project ideas)
- Google Dataset Search (searches datasets across the entire web)
- AWS Open Data Registry (large-scale datasets on S3)
- Data.gov (U.S. government data, well-documented and clean)
For community:
- Dataquest Community (get help from other learners and share your projects)
- r/dataengineering (active community, great for career questions)
- DataTalks.Club (free courses, active Slack, weekly events)
- Data Engineering Discord (real-time help and networking)
Your Next Steps
You now have the complete roadmap, here’s what you can do now:
In the next 24 hours:
- Bookmark this roadmap (you'll want to reference it)
- Create a GitHub account if you don't have one
- Start Dataquest's free Data Engineering lessons
- Write your first line of code today
This week:
Complete 3-5 Python lessons. Practice writing and running code daily—even 30 minutes counts. Push something to GitHub.
This month:
Make substantial progress on Phase 1 foundations. Build your first portfolio project.
Conclusion
Data engineering is a rewarding, high-demand career with excellent compensation and genuine intellectual challenge. The 12-18 month journey from beginner to job-ready is substantial, but the path is clear: foundations first, then scale, then production skills, then portfolio polish.
Remember these key principles: start with Python and SQL (everything else builds on them), avoid common traps like tutorial hell and skipping fundamentals, build projects throughout your learning (not just at the end), and join a community (you don't have to do this alone).
Every data engineer working today started exactly where you are, with curiosity and determination. A year from now, you could be building production pipelines at a company you admire. The only way to guarantee failure is not starting.
The choice is yours.
Frequently Asked Questions
How long does it really take to become a data engineer from scratch?
The timeline depends mainly on how much time you can dedicate each week.
Part-time (5–10 hours/week): 12–18 months to job-ready
Full-time (30–40 hours/week): 6–9 months
These ranges vary based on your background. If you already know some programming, you’ll likely move faster. Consistency matters more than speed, and learning continues well after your first job—no one ever knows everything.
Do I need a computer science degree?
No. Many working data engineers are self-taught or came through bootcamps.
What matters most is demonstrable skill: solid projects, problem-solving ability, and an understanding of real-world data systems. Employers care far more about what you can build than where you learned it.
A degree can help, especially at larger companies, but it’s not a strict requirement for entering the field.
What programming languages should I learn first?
SQL comes first. It’s non-negotiable and arguably the most important skill in data engineering.
Python comes second. It’s the most widely used language for pipelines, automation, and data processing.
Later, you may add Java or Scala if you work heavily with Spark at scale. Start with SQL and Python—everything else can wait.
Can I learn data engineering while working a full-time job?
Absolutely. Most people do.
Plan for 10–15 hours per week spread across early mornings, evenings, or weekends. It takes longer than full-time study, but it’s completely achievable.
The key is consistency. Regular, focused practice matters far more than occasional bursts of intensity.
Which cloud platform should I learn first?
Pick one: AWS, Azure, or GCP.
AWS appears most often in job postings, but all three platforms are widely used. The underlying concepts transfer between them.
It’s better to learn one platform deeply than three superficially. Checking job listings in your target location can help guide your choice.
How do I build a portfolio with no work experience?
Use public datasets from Kaggle, government open data portals, or public APIs. Build projects that solve real problems, even if the scenarios are self-created.
Examples that impress employers include:
- An ETL pipeline processing public health data
- A pipeline that tracks and analyzes stock prices daily
- A data quality monitoring dashboard for any dataset
Push everything to GitHub with clear documentation. Quality beats quantity—three excellent projects are better than ten mediocre ones.
What does data engineering salary look like by experience level?
Based on January 2026 data, here’s what you can expect at different career stages:
- Entry-Level (0–2 years): \$90,000 – \$115,000
- Mid-Level (3–5 years): \$115,000 – \$145,000
- Senior (5–8 years): \$145,000 – \$180,000
- Staff / Principal (8+ years): \$180,000 – \$220,000+
Salaries vary by location, company size, and industry. Tech companies and financial services typically pay at the higher end.
Is data engineering being automated away by AI?
AI is changing data engineering, but it isn’t eliminating it.
AI tools can automate routine tasks like generating basic SQL or suggesting code, but they can’t replace architectural judgment, system design decisions, or business context.
If anything, AI is increasing demand by generating more data that needs to be engineered. The most effective data engineers are learning to use AI tools to become more productive, not replace themselves.