Why You Should Learn Data Engineering
Exciting news: we have a Data Engineering path that offers from-scratch training for anyone who wants to become a data engineer or learn some data engineering skills.
Looks cool, right? But it begs the question:
Why Learn Data Engineering?
Typically, data science teams are comprised of data analysts, data scientists, and data engineers. We’ve talked about the differences between these data roles, but here let’s go deeper into some of the advantages of being a data engineer.
Data engineers are the people who connect all the pieces of the data ecosystem within a company or institution. They accomplish this by doing things like:
- Accessing, collecting, auditing, and cleaning data from applications and systems into a usable state
- Creating and maintaining efficient databases
- Building data pipelines
- Monitoring and managing all the data systems (scalability, security, etc)
- Implementing data scientists’ output in a scalable manner
Data Engineer vs. Data Scientist
Doing everything listed above primarily requires one particular skill: programming. Data engineers are software engineers who specialize in data and data technologies.
That makes them quite different from data scientists, who certainly have programming skills, but who typically aren’t engineers. It’s not uncommon for data scientists to hand over their work (e.g., a recommendation system) to data engineers for actual implementation.
And while it’s data analysts and data scientists who are doing the analysis, it’s typically data engineers who are building the data pipelines and other systems necessary to make sure that everyone has easy access to the data they need (and that no one has access to the data who shouldn’t).
A strong foundation in software engineering and programming equips data engineers to build the tools data teams and their companies need to succeed. Or, as Jeff Magnusson put it:
I like to think of it in terms of Lego blocks. Engineers design new Lego blocks that data scientists assemble in creative ways to create new data science.
This brings us to the first reason why you might want to learn data engineering:
1. It’s the Backbone of Data Science
Data engineers are on the front lines of data strategy so that others don’t need to be. They are the first people to tackle the influx of structured and unstructured data that enters a company’s systems. They are the foundation of any data strategy. Without Lego blocks, after all, you can’t build a Lego castle.
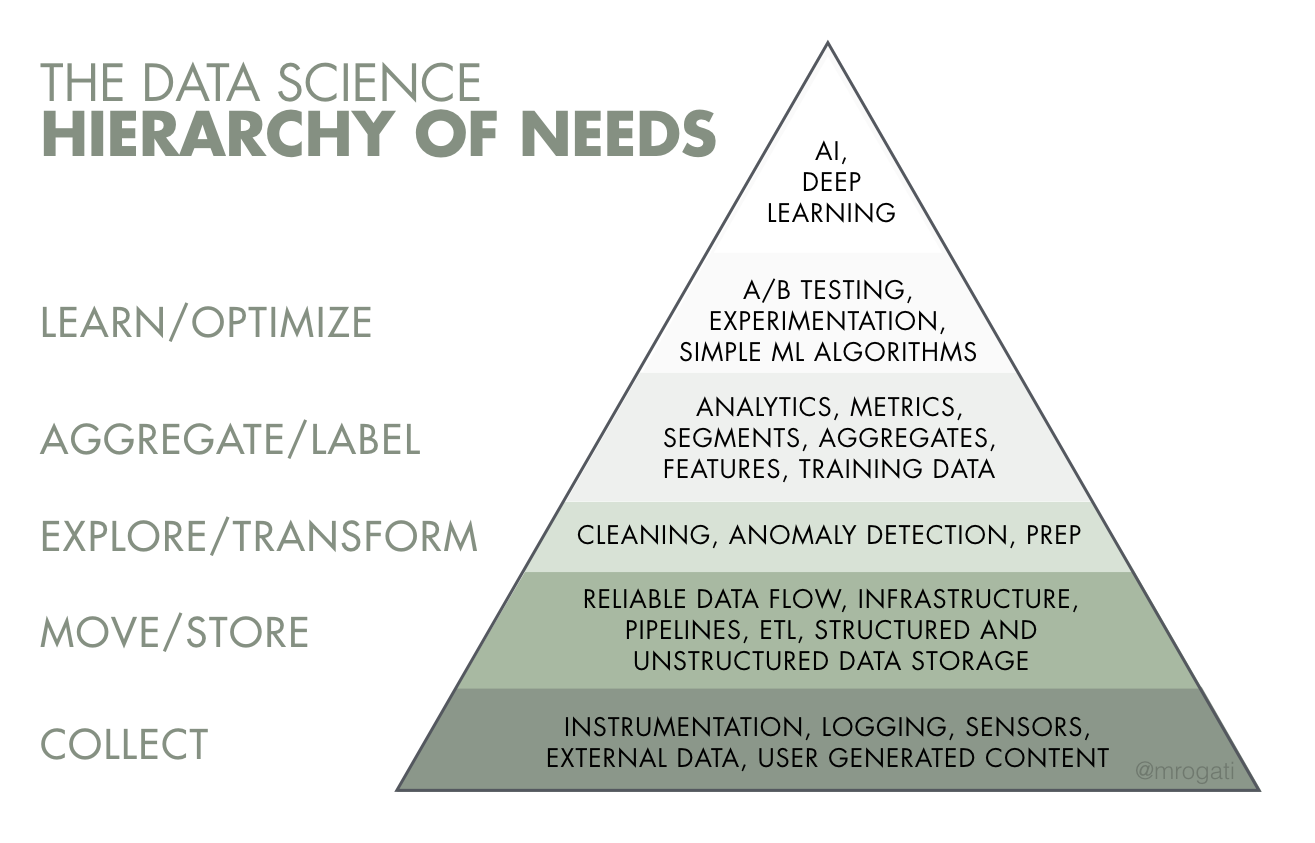
In the above Data Science Hierarchy of Needs (proposed by Monica Rogati), data engineers are completely responsible for the two bottom rows, and share responsibility with data analysts and data scientists for the third row from the bottom.
How Critical Is Data Engineering?
To answer this, imagine the pyramid pictured above is used as a funnel and flipped upside down. Data is poured into the top of that funnel, and the first people to touch it are data engineers. The more efficient they are at filtering, cleaning, and directing that data, the more efficient everything else can be as the data flows further down the funnel and towards other team members.
Conversely, if the data engineers are not efficient, they can serve as a block in the funnel that harms the work of everyone downstream. If, for example, a poorly-built data pipeline ends up feeding the data science team incomplete data, any analysis they perform on that data may be useless.
In this way, data engineers act as multipliers of the outcomes of a data strategy. They are the giants on whose shoulders data analysts and data scientists stand.
This is evidenced in the way companies with good data strategies structure their teams. According to Jesse Anderson, a data engineer and managing director of the Big Data Institute:
A common starting point is 2-3 data engineers for every data scientist. For some organizations with more complex data engineering requirements, this can be 4-5 data engineers per data scientist.
2. It’s Technically Challenging
One of the Python functions data analysts and scientists use the most is read_csv — from the pandas library. This function reads tabular data stored in a text file into Python, so that it can be explored and manipulated.
If you’ve worked with data in Python before, you’re probably very used to typing something like this:
import pandas as pd
df = pd.read_csv("a_text_file.csv")Easy and convenient, right? The read_csv function is a great example of the essence of software engineering: creating abstract, broad, efficient, and scalable solutions.
What does that mean and how does it relate to learning data engineering? Let’s take a deeper look.
- Abstract: When reading a file in a computer, a very complex process occurs under the hood. However, our use of the function is very simple because what goes on in the background is abstracted away from the usage. You don’t need to understand what
read_csvis doing “under the hood” to use it effectively. - Broad: This function also allows us to explicitly choose what delimiter is being used in the text’s file tabular data (e.g. commas, semicolons, tabs, and so on). This makes it easy to use with a variety of CSV styles, and that’s music to data scientists’ ears. And there are many other options that allow data practitioners to focus on their goals instead of having to worry about programming details.
- Efficient:
read_csvworks quickly and efficiently, and it’s also efficient to read in code. - Scalable: Another option included with this function allows us to read files by chunks, so that if a file is too large to read into the computer’s RAM, it can be read chunk by chunk, allowing users to process files as large as they come.
Robert A. Heinlein is famous for having said that:
One man’s magic is another man’s engineering.
It is data engineers who work that magic, building tools like the read_csv function that are abstract, broad, efficient, and scalable so that the rest of the team can focus on the data itself and their analysis rather than having to struggle with programming puzzles.
At the same time, data engineering probably requires less math than data science, so if you prefer programming over mathematics, data engineering could be an ideal option for you!
3. It’s Rewarding
Making data scientists’ lives easier isn’t the only thing that motivates data engineers. There’s no denying that data engineers are making a significant and growing impact on the world at large.
According to recent statistics, we create more than 402 billion gigabytes of data every single day. If that wasn't enough, it's believed that 90% of the world's data was created in just the last two years. This immensity of data has made data engineers more valuable than ever. IoT Analytics estimated more than 18.8 billion IoT devices at the end of 2024, up from about 16.6 billion in 2023, and 14.4 billion in 2022. With all this growth comes a lot more data from a lot more sources, and thus a lot more need for data engineers who can effectively process and channel it.
This means that data engineers have a huge variety of ways they can pursue their interests and deepen their skill sets. To give you an idea of how vast this world is, here’s a list of popular data tools and technologies:
- Amazon Redshift
- Amazon S3
- Apache Cassandra
- Apache HBase
- Apache Kafka
- Apache Spark
- Apache Zookeeper
- Azure
- ElephantDB
- Hadoop Distributed File System
- IBM DB2
- MapReduce
- Memcached
- Microsoft SQL Server
- Mongo DB
- Oracle Database
- PostgreSQL
- Redis
- SQLite
- Storm
- SAP IQ
- Teradata
- Vertica
Of course, a data engineer doesn’t have to know all of these, but this list illustrates just how much there is to do in the world of data engineering. Once you’ve got the skills to get jobs, you’ve got a lot of freedom to choose what you’re working on and what tools you’re working with.
Since data engineers have both data and software engineering skills, they’re also capable of building a variety of products. Want to contribute to an early-stage startup, or become an entrepreneur and found your own someday? Data engineering skills give you the tools you’ll need to both build great products and analyze how those products are performing. You’ll be able to implement and measure the success of pretty much anything you can think of.
Want to work remotely? According to The U.S. Bureau of Labor and Statistics:
The share of employed people who spent time working at home on days they worked was about the same as in 2022 (34 percent) but higher than in 2019 (24 percent), before the COVID-19 pandemic.
So if working outside of the office is something that suits you, data engineering could help you achieve that goal. Because there’s a high demand for data engineers, and because most of the work can be done remotely, it’s definitely possible to find remote data engineering jobs, or work for yourself as a freelance contractor on shorter-term data engineering projects.
Finally, data engineers also have plenty of opportunities to give back to the community. According to 2024’s Stack Overflow Developer’s Survey:
93% of respondents visit Stack Overflow at least multiple times per month if not multiple times per day.
And since you’ll have data and engineering skills, you’ll be able to make a real difference developing cool new tools for the data science community.
4. It Pays Well
You should never take a job based only on the salary, but there’s no denying that salary is important!
According to Glassdoor, a machine learning engineer gets paid an average of $168,000. Advertised data scientist positions pay an average of $164,000. And data engineering positions pay an average of $202,000.”
It’s no surprise as to why. Data engineering skills like Python, SQL, and the shell regularly rank among the highest-paying skills in StackOverflow’s developer surveys. And at the time of this writing, there are around 140,000 results for the search term Data Scientist on LinkedIn, and around 251,000 results for the search term Data Engineer.
A majority of companies report difficulty finding qualified data engineers. In a recent survey, 87% of tech leaders said they struggle to secure skilled tech talent in the current market. This persistent talent shortage shows that even though more people are entering the field, demand is still outpacing supply. Looking ahead, the job market for data engineers appears resilient. The tech industry’s recent “reset” (with some layoffs in 2022–23) has largely been a correction of over-hiring, and experts anticipate data roles will remain in demand through 2025.
And that’s not all! According to Statista:
The global big data market is forecasted to grow to 103 billion U.S. dollars by 2027
5. It’s Valuable Even If You Don’t Want to Be a Data Engineer
Even if you don’t want to pursue a career as a data engineer, if you want to work in data science, it can be very useful to have some knowledge of data engineering. The benefits are multifold:
- As a data practitioner, there’s a good chance you’ll periodically be asked to complete tasks that have some overlap with other job roles, including data engineering.
- Learning a different way of looking at things can be beneficial to your understanding, and it gives you an opportunity to brush up on skills you might not have used in a while.
- Having engineering skills will make you more self-sufficient. This can help your career tremendously as you need not be blocked anymore, waiting for someone to do something for you.
- Learning data engineering skills will allow you to empathize with data engineers and better communicate with them. This will also help your team, as you can become the bridge that connects yours to the data engineering team.
Wrapping Up and Next Steps
We’ve looked at five good reasons why data engineering is such an exciting and rewarding field: it’s the backbone of data science, it’s technically challenging, it’s deeply impactful, it pays well, and it’s valuable even if you never formally become a data engineer. When it comes right down to it, data engineering is all about designing systems that make data accessible, reliable, and ready for analysis. It’s where the Legos that build our data-fueled future are snapped together to create new data science.
If you’re ready to take the next step toward becoming a data engineer—or just want to add some invaluable engineering skills to your data toolkit—consider enrolling in our Data Engineering career path. We’ve designed it from scratch to give you the hands-on experience and foundational knowledge you need.
Best of luck to you and happy coding!