Introduction to NumPy and pandas for Data Analysis
When I first started working with large datasets in Python, I often found myself waiting for hours as my code processed the data. It was frustrating and inefficient. Then I discovered NumPy and pandas for data analysis, and everything changed. These powerful Python libraries streamlined my workflow and significantly improved my data processing speed, allowing me to perform complex operations with ease.
Let me give you a concrete example from one of my personal projects. I once worked on a machine learning project that involved processing thousands of satellite weather images like the one shown below. Using basic Python, this task took so long that I’d start it before bed, hoping it would be done by morning. On rare occasions, the task finished successfully, but more often than not, it was either still running in the morning or had crashed sometime during the night. I knew there had to be a better way. With NumPy’s vectorized operations and pandas’ ability to efficiently handle structured data, I learned how to complete the same task in less than an hour. It was over 20 times faster and far more reliable, never crashing like vanilla Python would.

In this tutorial, we’ll cover both of these powerful libraries, starting with NumPy. You’ll learn how its vectorized operations can improve your data processing and how Boolean indexing makes selecting and filtering data more efficient. Then, we’ll move on to pandas and see how it simplifies working with structured data. By the end, you’ll have a solid understanding of both NumPy and pandas, helping you streamline your Python workflow for efficient data science tasks.
Let’s begin by exploring the fundamentals of NumPy and how it can improve your data analysis capabilities.
Lesson 1 – Introduction to NumPy
NumPy, short for "Numerical Python," is a foundational library for scientific computing in Python. It's the backbone of many data science and machine learning tools, and once you start using it, you’ll see why it is so loved by the Python community. At the heart of NumPy is the ndarray, or n-dimensional array—a powerful list-like object designed for efficient numerical operations.
Creating Your First NumPy Array
Let’s start by creating a simple one-dimensional ndarray:
import numpy as np
data_ndarray = np.array([5, 10, 15, 20])This code imports NumPy (typically aliased as np) and creates an ndarray with four elements. While it looks similar to a regular Python list, an ndarray offers performance and flexibility advantages for numerical operations.
The Power of Vectorized Operations
One of the biggest advantages of using NumPy is its speed. NumPy’s vectorized operations make a significant difference when working with large datasets.
As mentioned earlier, when working on my satellite weather image project, switching to NumPy was a game changer. The key lies in NumPy’s vectorized operations. Unlike standard Python lists, where you’d typically use loops to process data element-wise, NumPy allows you to apply operations directly to entire arrays at once. This speeds up the process and reduces the chances of errors or crashes, making it far more reliable for large-scale data processing.
Let’s start by looking at a Python loop example that performs multiple calculations (squaring, cubing, and raising values to the fourth power) on a large dataset:
import time
# Create a large Python list
python_list = list(range(1000000))
# Start time
start_time = time.time()
# Perform multiple calculations using a Python loop
result = 0
for x in python_list:
result += (x**2 + x**3 + x**4)
# End time and print the time taken
end_time = time.time()
print(f"Python Loop Time Taken: {end_time - start_time:.6f} seconds")Python Loop Time Taken: 0.824237 secondsNow, let’s see how NumPy handles the same task using vectorized operations. Note that we’ll use np.float64 for the NumPy array to handle the large values generated by raising numbers to high powers:
import numpy as np
import time
# Create a large NumPy array with float data type
numpy_arr = np.arange(1000000, dtype=np.float64)
# Start time
start_time = time.time()
# Perform the same multiple calculations with vectorized operations
np_result = np.sum(numpy_arr**2 + numpy_arr**3 + numpy_arr**4)
# End time and print the time taken
end_time = time.time()
print(f"NumPy Time Taken: {end_time - start_time:.6f} seconds")NumPy Time Taken: 0.044395 secondsAlthough both methods produce the same result, the Python loop takes 0.824237 seconds, while NumPy completes the task in just 0.044395 seconds. That’s an efficiency boost of nearly 20x with NumPy! This comparison highlights how powerful NumPy’s vectorized operations are, especially when performing complex calculations on larger datasets.
Beyond Speed: NumPy's Versatility
But speed isn't the only benefit. NumPy also provides tools for complex mathematical operations, data reshaping, and statistical analyses. These capabilities make it an essential part of any data scientist's or analyst's toolkit.
As you continue to work with NumPy, you'll discover how it can handle tasks like:
- Performing mathematical operations on entire datasets at once
- Efficiently storing and accessing large amounts of data
- Generating random numbers and simulating data
- Applying linear algebra operations
In the next lesson, we'll explore some of these features in more depth. You'll see how NumPy can simplify filtering your data and make your workflow more intuitive. Whether you're analyzing financial data, processing scientific measurements, or working with machine learning models, NumPy will become an invaluable part of your data analysis toolkit.
Lesson 2 – Boolean Indexing with NumPy
One of the most powerful features of NumPy is its ability to help you select specific data points quickly and efficiently. With Boolean indexing, you can filter data with precision without the need for complex code. This technique allows you to select data based on conditions, making your analysis much more streamlined and intuitive.
In this lesson, we’ll be working with a dataset of about 90,000 yellow taxi trips to and from various NYC airports, covering January to June 2016. You can download the dataset here to follow along with the code. A full data dictionary is also available here, which describes key columns like pickup_year, pickup_month, pickup_day, pickup_time, trip_distance, fare_amount, and tip_amount. This data will give us a great opportunity to see Boolean indexing in action!
Let’s load the dataset and prepare our variables for analysis:
import numpy as np
# Load the dataset, skipping the header row
taxi = np.genfromtxt('nyc_taxis.csv', delimiter=',')[1:]
# Extract the pickup month column
pickup_month = taxi[:, 1]In this code, we use [1:] to skip the header row, and [:, 1] selects the second column, which contains the month of each trip. Now we’re ready to dive into Boolean indexing.

Understanding Boolean Indexing
Boolean indexing acts like a filter for your data, letting you select rows or columns based on conditions you define. It works by creating a Boolean array—an array of True and False values—that matches the shape of your data. Wherever the condition is met, you get a True, and wherever it isn't, you get a False. Then, you use this Boolean array to select only the data you need.
To create a Boolean array, you use comparison operators. Here are some of the most common ones:
==: checks if two values are equal!=: checks if two values are not equal>: checks if a value is greater than another<: checks if a value is less than another>=: checks if a value is greater than or equal to another<=: checks if a value is less than or equal to another
Now, let’s see Boolean indexing in action. For example, if we want to find all the taxi rides that occurred in January:
january_bool = pickup_month == 1
january = pickup_month[january_bool]
january_rides = january.shape[0]
print(january_rides)Here, january_bool is a Boolean array where each element is True if the corresponding month is January (i.e., 1), and False otherwise. We then use this array to index the pickup_month array, selecting only the January rides. The number of rows in january is the total number of rides in January:
800Complex Filtering with Boolean Indexing
Boolean indexing can handle more than single comparisons like the one above. You can also combine multiple conditions to filter data based on complex criteria. For example, let’s find all taxi rides where the tip amount is greater than $20 and the total fare is under $50:
tip_amount = taxi[:, 12]
total_fare = taxi[:, 13]
high_tip_low_fare_bool = (tip_amount > 20) & (total_fare < 50)
big_tip_rides = taxi[high_tip_low_fare_bool]
print(big_tip_rides)[ 2016 3 4 5 1 4 3 8.55 832 23.5
0.8 0 25 49.3 1]Here’s what’s happening:
- We create two Boolean arrays: one for trips where the tip amount is greater than $20 and one for trips where the total fare is below $50.
- By combining these two conditions with the
&(and) operator, we create a single Boolean array (high_tip_low_fare_bool) that filters for trips meeting both criteria. Both conditions must beTruefor a row to be selected. - We then use this Boolean array to filter the dataset, returning all taxi rides that meet both criteria. In this case, only one ride fits the conditions.
This powerful technique allows you to narrow down your dataset based on multiple conditions, zeroing in on exactly the data you’re interested in. You can also use the | (or) operator to find rows where either condition is true, meaning the row will be selected if any condition is True.
Boolean Array Shape Requirements
It’s important to remember that Boolean arrays must have the same number of elements as the dimension they are filtering. For example, if you’re filtering rows of a 2D array, the Boolean array must match the number of rows in that array. This ensures that each element in the Boolean array corresponds to the correct data point in the dataset. If the shapes don’t match, NumPy will raise an error.
This requirement ensures your filtering logic is applied consistently across your data.
Real-World Application of Boolean Indexing
At Dataquest, Boolean indexing helps us analyze our course data and make improvements. For example, we can quickly identify the specific screens in lessons that are giving learners trouble by filtering our data based on low completion rates for screen exercises. This allows us to pinpoint and improve the exercises that are causing students to struggle and apply targeted lesson optimizations.
Tips for Getting Started with Boolean Indexing
If you’re new to Boolean indexing, here are a few tips to help you get started:
- Start with simple conditions, like equality or inequality checks, before moving to more complex filters.
- Use the
&(and) and|(or) operators to combine multiple conditions in a single Boolean array. - Boolean arrays must match the dimension of the data they are filtering, ensuring that each element corresponds to the correct data point.
- For more advanced use cases, consider using
numpy.where(), which allows you to apply conditions and select data in one step.
Boolean indexing not only simplifies your code but also makes it more efficient and readable. Instead of writing complex loops or numerous if statements, you can often accomplish your goal with just one line of code.
The more you use Boolean indexing, the more you’ll find it becomes an essential part of your data analysis toolkit. It’s flexible, efficient, and makes data selection much easier to manage.
In the next lesson, we’ll explore how to combine NumPy with another essential data science library: pandas. You’ll see how using these two tools together can further streamline your workflow and enhance your data manipulation capabilities.
Lesson 3 – Introduction to Pandas
After getting comfortable with NumPy, I quickly realized I needed something more powerful for handling large and complex datasets. That's when I turned to pandas. Whether I was working with missing data, needing better tools to analyze and reshape datasets, or simply wanted more flexibility in data manipulation, pandas made my life a lot easier. Building on NumPy’s foundation, pandas adds a rich set of tools designed specifically for data analysis and manipulation, which felt like the perfect solution to my challenges.
In case you're wondering―like I did when I first heard the name―the name pandas comes from "panel data," referring to multi-dimensional structured datasets, often used in econometrics. It also plays on the name of the black and white bear, making it catchy and easy to remember. The library was designed to work efficiently with structured data, hence the connection to tabular data structures.
Introducing the Dataset: Fortune 500 Companies
For the next few lessons, we’ll be working with a dataset of the top 500 companies in the world by revenue, commonly referred to as the Fortune 500. This dataset covers information such as company rankings, revenue, profits, CEO names, and the industries and sectors they operate in. You can download the dataset here to follow along with the examples.
Here are a few key columns to familiarize yourself with:
company: The name of the company.rank: The company’s rank on the Global 500 list.revenues: Total revenue for the fiscal year (in millions of USD).revenue_change: The percentage change in revenue from the previous year.profits: The company’s net income for the fiscal year (in millions of USD).ceo: The Chief Executive Officer of the company.country: The country where the company is headquartered.
Let’s load the data and begin exploring it:
import pandas as pd
f500 = pd.read_csv('f500.csv', index_col=0)
f500.index.name = NoneThis code reads the CSV file into a pandas DataFrame called f500. The index_col=0 parameter tells pandas to use the first column as the index, and f500.index.name = None removes the name of the index for cleaner output.
What is a DataFrame?
A DataFrame is the most commonly used data structure in pandas, often compared to an Excel spreadsheet or an SQL table. It is a two-dimensional, labeled data structure where each row represents an observation (like a company in our Fortune 500 dataset), and each column represents a variable (like revenues, profits, or CEO names).

Under the hood, however, a DataFrame is essentially a collection of Series objects. A Series is the other foundational data structure in pandas and is a one-dimensional array of data. Think of each column in a DataFrame as a Series. While people often say the DataFrame is the core pandas object, it’s really just a collection of Series objects that share the same index.
Let’s look at an example. If we select the revenues column from our DataFrame, we’re actually working with a Series:
revenues = f500['revenues']
print(type(revenues))
print(revenues.head())
<class 'pandas.core.series.Series'>
Walmart 485873
State Grid 315199
Sinopec Group 267518
China National Petroleum 262573
Toyota Motor 254694
Name: revenues, dtype: int64Here, we can see that revenues is a Series object. It’s one-dimensional, with each company as the index and its corresponding revenue as the value. You can think of this as a labeled array where each label (company) is associated with a value (revenue).
Working with Series and DataFrames
Series and DataFrame objects share many similar methods and functions, which makes them easy to work with once you understand both. However, certain methods apply specifically to one or the other. In the next lesson, we’ll take a close look at a couple of methods, and see how DataFrame and Series objects differ in terms of functionality and usage.
Pandas and NumPy
While NumPy is great for numerical operations, pandas shines in data manipulation and analysis. The DataFrame object in pandas completely changed how I approach data cleaning. With pandas' specialized methods, I could easily handle missing values, convert data types, and perform complex aggregations, all with intuitive and readable code.
Pandas is also excellent at handling complex data types like dates and text. For a time-series analysis on weather data spanning several years, pandas made it easy to parse dates, resample the data to different time frequencies, and perform time-based operations.
The real power comes when you combine NumPy and pandas. For instance, in my weather analysis project, I used NumPy for heavy numerical computations and pandas for data manipulation and time-series operations. This combination allowed me to extract insights that would have been nearly impossible with basic Python alone.
Pandas and SQL
If you're comfortable with SQL, you'll find that NumPy and pandas complement your skills beautifully. While SQL is great for querying databases, NumPy and pandas excel at in-memory data manipulation and analysis. A typical workflow might involve using SQL to extract data from your database, then leveraging NumPy and pandas to perform complex calculations, reshape your data, and create visualizations.
In the next lesson, we'll explore some fundamental techniques for data exploration using pandas. You'll see how these tools can help you quickly understand your data and set the stage for deeper analysis.
Lesson 4 – Exploring Data with Pandas: Fundamentals
When I start working with a new dataset, I always begin by getting to know it better. In this section, we'll explore how pandas makes data exploration easy and efficient.
Getting to Know Your Data
Let’s walk through some fundamental methods together. Two essential techniques I use are info() and describe(). The info() method provides a concise summary of a DataFrame, while describe() offers useful statistics for numerical columns, both on DataFrame and Series objects.

Let’s start with info() to get a quick overview of our dataset.
This exclusive DataFrame method provides information about the number of rows and columns, column names, data types, and non-null counts. Here's what we get when we call it on our f500 dataset:
f500.info()<class 'pandas.core.frame.DataFrame'>
Index: 500 entries, Walmart to AutoNation
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 rank 500 non-null int64
1 revenues 500 non-null int64
2 revenue_change 500 non-null float64
3 profits 499 non-null float64
4 assets 500 non-null int64
5 profit_change 436 non-null float64
6 ceo 500 non-null object
7 industry 500 non-null object
8 sector 500 non-null object
9 previous_rank 500 non-null float64
10 country 500 non-null object
11 hq_location 500 non-null object
12 website 500 non-null object
13 years_on_global_500_list 500 non-null int64
14 employees 500 non-null int64
15 total_stockholder_equity 500 non-null int64
dtypes: float64(4), int64(6), object(6)
memory usage: 66.4+ KBThis summary is a quick way to check data types, spot missing values (like in the profits column), and see how much memory the dataset uses. It’s a great first step to get a feel for the dataset.
Statistical Overview with describe()
Next, let’s use the describe() method to get a summary of the dataset's numeric columns:
print(f500.describe())This gives us statistical insights, such as mean, standard deviation, and min/max values for each numerical column:
. rank revenues revenue_change profits assets profit_change previous_rank years_on_global_500_list employees total_stockholder_equity
count 500.000000 500.000000 498.000000 499.000000 500.000000 436.000000 500.000000 500.000000 500.000000 500.000000
mean 250.500000 55416.358000 4.538353 3055.203206 243632.300000 24.152752 222.134000 15.036000 133998.300000 30628.076000
std 144.481833 45725.478963 28.549067 5171.981071 485193.700000 437.509566 146.941961 7.932752 170087.800000 43642.576833
min 1.000000 21609.000000 -67.300000 -13038.000000 3717.000000 -793.700000 0.000000 1.000000 328.000000 -59909.000000
25% 125.750000 29003.000000 -5.900000 556.950000 36588.500000 -22.775000 92.750000 7.000000 42932.500000 7553.750000
50% 250.500000 40236.000000 0.550000 1761.600000 73261.500000 -0.350000 219.500000 17.000000 92910.500000 15809.500000
75% 375.250000 63926.750000 6.975000 3954.000000 180564.000000 17.700000 347.250000 23.000000 168917.250000 37828.500000
max 500.000000 485873.000000 442.300000 45687.000000 3473238.000000 8909.500000 500.000000 23.000000 2300000.000000 301893.000000This output provides valuable insights, such as the average company revenue being around 55.4 billion USD and the largest company having 485.9 billion USD in revenue. It also shows the wide variation in profits, with the most profitable company earning 45.7 billion USD, while the least profitable lost 13.0 billion USD. describe() helps us understand central tendencies and spread across multiple columns quickly.
We can also use describe() on individual Series objects. For example, let’s take a look at the profit_change column:
print(f500["profit_change"].describe())count 436.000000
mean 24.152752
std 437.509566
min -793.700000
25% -22.775000
50% -0.350000
75% 17.700000
max 8909.500000
Name: profit_change, dtype: float64Look familiar? It should! This is part of the full f500.describe() output we saw earlier. By calling describe() on a specific Series, we can drill down and get these summary statistics for just one column at a time—super useful when you want to analyze a single column of your dataset in more detail.
Efficient Data Operations with Pandas
Pandas allows us to perform operations on entire columns at once, which is faster and more memory-efficient than using loops. For example, let’s calculate the change in rank for each company:
rank_change = f500["previous_rank"] - f500["rank"]
print(rank_change.head())Walmart 0
State Grid 0
Sinopec Group 1
China National Petroleum -1
Toyota Motor 3
dtype: int64With a single line of code, we can subtract the current rank from the previous rank for every company in the dataset, showing how companies’ positions have shifted. With pandas, operations like this are efficient, even for large datasets.
Quick Statistical Insights
On top of what we've seen already, pandas provides handy methods like mean(), max(), and min() to quickly calculate key statistics. For example, we can find the average profits directly with:
print(f500["profits"].mean())3055.2032064128252And yes, you’ve seen this number before! It appeared in the full f500.describe() output we explored earlier. By using mean() directly on the profits column, we’re isolating just this one metric, which shows how pandas makes it easy to focus on specific details in your data.
We can also pull out the highest and lowest profits, values we touched on earlier with describe():
print(f500["profits"].max())
print(f500["profits"].min())45687.0
-13038.0And there we have it! The top earner pulled in 45.7 billion USD, while the company with the largest loss dropped 13.0 billion USD. This gives us a clear sense of the extremes within the Fortune 500, and pandas lets us grab these insights effortlessly with just a few lines of code.
These fundamental exploration techniques give you the tools to quickly understand your data and make informed decisions. Whether you’re calculating statistics, comparing columns, or summarizing your dataset, pandas provides the flexibility to do it efficiently.
In the next lesson, we’ll build on these fundamentals and explore more advanced data manipulations and analysis methods that will further enhance your data science skills.
Lesson 5 – Exploring Data with Pandas: Intermediate
Now that you're comfortable with the basics of pandas, you're probably wondering what's next. Let's explore some techniques that have helped me tackle more complex data challenges and uncover deeper insights.
Advanced Data Selection with iloc
Selecting data using integer location, or iloc, is a powerful tool. This method allows you to access any part of your dataset by its position. Here's how it works:
fifth_row = f500.iloc[4]
company_value = f500.iloc[0, 0]In this example, fifth_row retrieves all the data from the fifth row of our dataset, while company_value gets the first piece of data in the top-left corner. I often rely on this technique when exploring new datasets. It's like being able to access any page in a book instantly.

Index Alignment: A Powerful Feature
Next, I want to highlight a feature that's incredibly useful: index alignment. Pandas can automatically line up data based on index labels. Here's a quick example:
previously_ranked = f500[f500["previous_rank"].notnull()]
revenue_change = previously_ranked["previous_rank"] - previously_ranked["rank"]
f500["rank_change"] = revenue_changeEven if revenue_change doesn't perfectly match our main dataset, pandas will align it correctly. This provides an enormous benefit when working with data from different sources that don't quite line up.
Complex Filtering with Boolean Conditions
When filtering data, pandas allows you to combine conditions to create complex queries. For instance:
big_rev_neg_profit = f500[(f500["revenues"] > 100000) & (f500["profits"] < 0)]This finds all companies with revenues over $100 billion (remember, our data is in millions) and negative profits. I used a similar technique recently to identify users who had completed multiple courses but hadn't logged in for a while, helping us reach out and re-engage them.
Sorting Data for Insights
Finally, let's talk about sorting. The sort_values() method is essential when you need to order your data. Here's a simple example:
sorted_companies = f500.sort_values("employees", ascending=False)This sorts companies by their number of employees, from highest to lowest. I often rely on this to rank our courses by popularity or to see which lessons are taking users the longest to complete.
Practical Tips for Intermediate Pandas Use
A helpful tip: when working with these techniques, start small. Try them out on a subset of your data first to ensure you're getting the results you expect. It's much easier to spot and fix issues when working with a smaller dataset.
As you practice these methods, you'll find they become second nature. They'll help you work with your data more efficiently and uncover insights you might have missed before. In the next lesson, we'll explore some advanced pandas features that will expand what you can do with your data.
Lesson 6 – Data Cleaning Basics
I’ll admit, when I first started working with large datasets, I was my own worst enemy. I’d dive into analysis without properly cleaning my data, only to end up with misleading insights and frustrating errors. But I quickly learned that data cleaning isn’t just a preliminary step—it’s the foundation of reliable analysis.
One particularly challenging project at Dataquest taught us this lesson. We were analyzing student progress across different courses, and some of our early results showed unusually high completion rates. After some digging, we realized the issue was due to inconsistencies in how course names were recorded and how completion was calculated. Those misleading results directly showed us just how essential data cleaning is for trustworthy analysis.
Working with the Laptops Dataset
In this lesson, we’ll explore the basics of data cleaning using a dataset of 1,300 laptops. This dataset contains information like brand names, screen sizes, processor types, and prices. You can download the dataset here if you’d like to follow along. Each cleaning step we demonstrate will help you develop a practical understanding of these concepts, using this dataset as a real-world example.
Cleaning Column Names
Consistent, readable column names are critical for intuitive and error-free coding. Inconsistent names can slow you down or cause confusion during analysis. Here’s how we can apply a column-naming convention to the laptops.csv dataset:
def clean_col(col):
col = col.strip()
col = col.replace("Operating System", "os")
col = col.replace(" ", "_")
col = col.replace("(", "")
col = col.replace(")", "")
col = col.lower()
return col
new_columns = [clean_col(c) for c in laptops.columns]
laptops.columns = new_columnsThis function makes sure that column names are consistent by removing extra spaces, replacing spaces with underscores, removing parentheses, and converting everything to lowercase. For example, "Operating System" becomes "os" to keep things concise. This consistency is essential because it makes your code easier to read and maintain, especially when working on larger datasets or collaborating with others.
Ensuring Correct Data Types
Having the correct data types ensures your operations behave as expected. If you assume a column contains numbers but it’s actually storing strings, you could run into frustrating bugs. Let’s apply this concept to the screen_size column in the laptops dataset:
laptops["screen_size"] = (
laptops["screen_size"].str.replace('"', '').astype(float)
)
laptops.rename({"screen_size": "screen_size_inches"}, axis=1, inplace=True)In this example, we’re cleaning the screen_size column by removing the inch symbol (") and converting the resulting values to floats. Renaming the column to screen_size_inches also clarifies the unit of measurement, making future analysis easier. Without this step, you might end up comparing strings instead of numbers—a common mistake that can lead to misleading results or incorrect calculations.
Handling Missing Values
Missing values are common in real-world datasets, and how you handle them can significantly impact your analysis. You have several options:
- remove rows with missing data
- fill in missing values with a specific value (like
0) - use statistical measures (like the mean or median) for imputation
Pandas makes these operations straightforward with methods like dropna() and fillna(). Here’s an example of filling missing values in the price column:
laptops["price"] = laptops["price"].fillna(laptops["price"].mean())In this example, we replace missing prices with the average price across all laptops. This strategy ensures that our analysis remains consistent without losing valuable data points. However, the right approach will depend on the context of your analysis—sometimes it makes more sense to remove missing data, especially if it represents a small percentage of your dataset.
The Benefits of Data Cleaning
By cleaning your data, you create a reliable foundation for your analysis. This reduces the risk of errors and ensures your insights are accurate. Clean data also saves time in the long run, preventing headaches caused by bugs or inconsistencies that can derail your analysis mid-project.

Documenting Your Data Cleaning Steps
Finally, always document your data cleaning steps. This will help you remember what you did and allow others to reproduce or build upon your work. At Dataquest, we maintain data cleaning logs for each project, which have proven invaluable when we need to revisit analyses or onboard new team members.
With these data cleaning basics under your belt, you’re ready to approach any dataset with confidence. In the final section of this tutorial, we’ll take your cleaned data and use pandas’ powerful analysis functions to extract meaningful insights.
Guided Project: Exploring eBay Car Sales Data
Now that you've got a solid grasp of NumPy and pandas, it's time to put your skills to the test with a real-world dataset. Let's explore a project that will allow you to practive everything we've covered in this tutorial by analyzing used car listings from eBay Kleinanzeigen, a German classifieds website.
Loading and Exploring the Data
Let's start by loading our data:
autos = pd.read_csv('autos.csv', encoding='Latin-1')
autos.info()This command gives us a quick overview of our dataset, showing the number of rows, column names, and data types. It's an essential first step in understanding what we're working with.
Next, let's take a look at the first few rows:
autos.head()You might notice some issues with the data. The column names might not be descriptive, or some data types might seem off. This is where our data cleaning skills come in handy.
Cleaning the Data
One of the first things we should do is clean up the column names:
autos.columns = ['date_crawled', 'name', 'seller', 'offer_type', 'price',
'ab_test', 'vehicle_type', 'registration_year', 'gearbox',
'power_ps', 'model', 'odometer', 'registration_month',
'fuel_type', 'brand', 'unrepaired_damage', 'ad_created',
'num_photos', 'postal_code', 'last_seen']This step makes the data much easier to work with and understand.
Now, let's address some common data issues. The price and odometer columns are likely stored as strings with currency symbols or units. We need to clean these up and convert them to numeric types:
autos['price'] = autos['price'].str.replace('$', '').str.replace(',', '').astype(int)
autos['odometer'] = autos['odometer'].str.replace('km', '').str.replace(',', '').astype(int)
autos = autos.rename({'odometer': 'odometer_km'}, axis=1)This code removes the dollar signs and commas from the price column, and the 'km' and commas from the odometer column. We convert both to integers for easier calculations later. We also rename odometer to odometer_km for clarity.
Analyzing the Data
With our data cleaned up, we can start to analyze it. We might look at the average price of cars by brand, or the relationship between a car's age and its price. The possibilities are endless, and this is where data analysis gets exciting.
Let's start by looking at the average price for each brand:
brand_mean_price = autos.groupby('brand')['price'].mean(numeric_only=True).sort_values(ascending=False)
print(brand_mean_price.head())This code groups our data by brand, calculates the mean price for each brand, and then sorts the results in descending order. We're printing the top 5 most expensive brands on average:
brand
porsche 44537.979592
citroen 42657.463623
sonstige_autos 38300.840659
volvo 31689.908096
mercedes_benz 29511.955429
Name: price, dtype: float64Next, let's explore the relationship between a car's age and its price. We'll need to calculate the age of each car first:
import datetime
current_year = datetime.datetime.now().year
autos['car_age'] = current_year - autos['registration_year']
age_price_corr = autos['car_age'].corr(autos['price'], numeric_only=True)
print(f"Correlation between car age and price: {age_price_corr:.6f}")Correlation between car age and price: -0.000013This code calculates the age of each car and then computes the correlation between car age and price. A negative correlation indicates that older cars tend to be cheaper, which is what we might expect. But the correlation between a car's age and its price in this dataset is extremely close to zero, with a value of -0.000013. This suggests that there is no meaningful linear relationship between the age of the car and its price. In other words, the car's age does not appear to significantly affect its price based on the data provided. This is a little surprising and should make you question the validity of this calculation.
Visualizing the Data
Sometimes, the best way to validate your observations is to visualize it. Let's create a scatter plot of car age vs. price to see if it can explain our findings above:
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.scatter(autos['car_age'], autos['price'], alpha=0.5)
plt.title('Car Age vs. Price')
plt.xlabel('Car Age (years)')
plt.ylabel('Price (€)')
plt.show()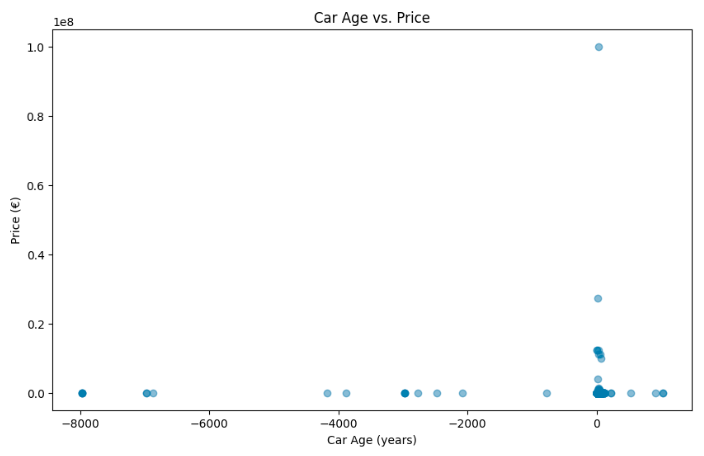
This plot immediately reveals some serious data quality issues—how can a car be -8,000 years old, or cost over 10 million Euros? These kinds of errors are clear signs that our dataset needs more cleaning. Before we can trust our correlation calculation, we need to carefully clean both the price and car_age columns to remove extreme outliers and correct any invalid entries. This example highlights why getting to know your data through exploration is so important: rushing into analysis without checking for these issues can lead to incorrect conclusions.
Data visualization, like the scatter plot we created, is a powerful tool not just for understanding trends but also for spotting these kinds of errors. It allows us to confirm our observations or catch problems that might not be obvious from summary statistics alone. In this case, the unexpected correlation value makes more sense once we visualize the data—our dataset needs some work before it can provide meaningful insights.
Drawing Insights
As you work through this project, try to think about what each piece of analysis tells you about the used car market in Germany. Are there certain brands that hold their value better than others? Is there a "sweet spot" in terms of car age where you get the best value for money?
Remember, the goal of data analysis isn't just to crunch numbers – it's to tell a story with those numbers. What story does this data tell about the used car market? How might these insights be useful to someone looking to buy or sell a used car?
This project is your chance to apply everything you've learned about NumPy and pandas in a real-world context. Embrace the challenges, learn from the process, and enjoy the insights you uncover. Happy analyzing!
Advice from a Python Expert
When I first encountered large datasets, I felt overwhelmed by the sheer volume of information. But as I learned NumPy and pandas, I discovered how these libraries could transform my workflow. Tasks that once took hours became possible in minutes, and I found myself able to extract insights I never thought possible.
That project where we analyzed student progress across different courses is a great example of this. Initially, we struggled with inconsistencies in how course names were recorded and how completion was calculated. By using pandas, we quickly cleaned and standardized the data. Then, with NumPy's powerful array operations, we performed complex calculations on completion rates and time spent per lesson. What might have taken a day with basic Python was completed in a single hour.
Based on my experience, I've found that the key to mastering NumPy and pandas is to start small and practice regularly. With each new skill, you'll find that you're able to tackle more complex data challenges.
If you're just starting with NumPy and pandas, here's some practical advice:
- Start with a small, real-world dataset. Perhaps analyze your personal finances or explore a public dataset on a topic you're passionate about.
- Practice regularly, even if it's just for 15 minutes a day. Consistency is key in building your skills.
- Don't hesitate to use the documentation. Both NumPy and pandas have excellent resources that can help you solve specific problems.
- Join our Dataquest Community where you can ask questions and share your progress.
If you're looking to deepen your understanding of pandas, I highly recommend checking out the Dataquest pandas fundamentals course. It's designed to help you build a strong foundation in these libraries, with practical exercises and real-world examples that will boost your confidence in tackling complex data challenges.
Remember, every data analyst started as a beginner. What matters is your willingness to learn and persevere through challenges. Each problem you solve builds your skills and confidence.
So, take that first step today. Open up your Python environment, import NumPy and pandas, and start exploring. With patience and practice, you'll be amazed at the insights you can uncover and the data challenges you can solve.
Frequently Asked Questions
What are the key benefits of learning NumPy and pandas for data analysis?
When it comes to data analysis, learning NumPy and pandas can greatly enhance your skills. One of the main advantages of using these libraries is that they significantly improve performance and efficiency when working with large datasets. This means that tasks that would normally take hours can be completed in just minutes.
NumPy and pandas also provide powerful data manipulation capabilities, making it easy to clean, transform, and reshape data. This is particularly useful when performing complex mathematical operations. With these libraries, you can handle a wide range of data challenges, from creating frequency tables to calculating correlations.
Another benefit of using NumPy and pandas is that they simplify complex operations that would be difficult or impossible to perform with basic Python alone. For example, if you're working on time series analysis, financial modeling, or machine learning projects, these libraries provide the tools you need to extract meaningful insights efficiently. Additionally, they complement SQL skills beautifully, allowing you to perform in-memory data manipulation and analysis after extracting data from databases.
By learning NumPy and pandas, you'll be well-equipped to tackle advanced data analysis tasks and uncover valuable insights from your data.
How do vectorized operations in NumPy speed up data processing compared to regular Python loops?
Vectorized operations in NumPy are a powerful feature that allow you to perform calculations on entire arrays simultaneously, rather than iterating through elements one by one. This approach significantly speeds up data processing compared to regular Python loops, making NumPy an essential tool for efficient data analysis.
To illustrate the difference, let's consider an example from our tutorial. We'll compare the performance of a Python loop and a NumPy vectorized operation.
start_time = time.time()
result = 0
for x in python_list:
result += (x**2 + x**3 + x**4)
end_time = time.time()
print(f"Python Loop Time: {end_time - start_time:.6f} seconds")Output: Python Loop Time: 0.824237 seconds
Now, let's see how NumPy performs:
start_time = time.time()
np_result = np.sum(numpy_arr**2 + numpy_arr**3 + numpy_arr**4)
end_time = time.time()
print(f"NumPy Time: {end_time - start_time:.6f} seconds")Output: NumPy Time: 0.044395 seconds
As you can see, the NumPy vectorized operation is nearly 20 times faster than the equivalent Python loop. This is because NumPy's underlying implementation in C can leverage specialized CPU instructions to process data in parallel.
When working with large datasets, this performance improvement becomes especially noticeable. Tasks that might take hours with regular Python loops can be completed in minutes or even seconds using NumPy's vectorized operations. This efficiency allows data analysts to work with larger datasets, perform more complex analyses, and iterate on their work more quickly.
Moreover, vectorized operations in NumPy lead to cleaner, more readable code. Instead of writing nested loops to perform calculations, you can express complex operations in a more concise and intuitive manner. This not only makes your code easier to understand and maintain but also reduces the likelihood of errors that can occur in loop-based implementations.
In real-world data analysis tasks, such as processing large volumes of financial data or analyzing scientific measurements, the speed and efficiency of NumPy's vectorized operations can be a significant advantage. Whether you're calculating statistics across millions of data points or applying complex mathematical transformations to entire datasets, NumPy's vectorized approach allows you to focus on the analysis itself rather than worrying about computational efficiency.
By using NumPy and its vectorized operations, you'll be well-equipped to handle large-scale data processing tasks efficiently, opening up new possibilities for in-depth analysis and insights in your data science projects.
What is Boolean indexing in NumPy, and how does it make data filtering easier?
Boolean indexing in NumPy is a powerful technique that simplifies data filtering. It uses arrays of True and False values to select specific data points. This method is especially useful in data analysis, as it allows you to filter large datasets based on complex conditions efficiently.
When working with NumPy and pandas for data analysis, Boolean indexing offers several benefits. For one, it simplifies your code with clear and concise syntax. It also enables fast data selection, even in large datasets. Additionally, you can combine multiple conditions using logical operators, giving you more flexibility.
Let's consider a practical example. Suppose you have a dataset of taxi rides and you want to identify rides with high tips and low fares. You can use Boolean indexing to do this quickly and efficiently:
high_tip_low_fare = (tip_amount > 20) & (total_fare < 50)
selected_rides = rides[high_tip_low_fare]This code creates a Boolean array that's True only for rides meeting both conditions, then uses it to filter the dataset.
By using Boolean indexing in your NumPy and pandas workflows, you can streamline your data analysis process. This technique will help you focus on extracting meaningful insights from your data, making it an essential tool for any data analyst working with large datasets.
How do pandas DataFrames make working with structured data more efficient than using Python lists or dictionaries?
Pandas DataFrames are powerful tools for working with structured data. When you learn to use them, you'll discover how they can make your work more efficient. Here are a few reasons why:
-
DataFrames store data in columns, which allows for faster operations on specific variables compared to row-based structures like lists of dictionaries. This makes it easier to work with large datasets.
-
DataFrames enable you to perform calculations on entire columns simultaneously, which eliminates the need for explicit loops. This significantly speeds up data processing, especially for large datasets.
-
DataFrames align data based on labels, which reduces the risk of errors when working with multiple datasets. This feature is particularly useful when dealing with complex data.
-
Pandas provides a wide range of functions for cleaning, transforming, and analyzing data. These functions are often more efficient than writing custom functions with lists or dictionaries.
-
DataFrames can handle large datasets more effectively than basic Python data structures, thanks to optimized internal representations. This means you can work with larger datasets without running out of memory.
For example, consider the following operation from the Fortune 500 dataset analysis:
rank_change = f500["previous_rank"] - f500["rank"]This single line calculates the change in rank for all companies in the dataset simultaneously, demonstrating the power of vectorized operations. With basic Python lists, you'd need to write a loop to perform the same calculation, which would be slower and more prone to errors.
In real-world applications, such as analyzing financial data or processing large datasets, DataFrames can significantly reduce processing time and simplify code. For instance, when analyzing course completion rates or user feedback, DataFrames allow for quick aggregations, filtering, and calculations that would be cumbersome with basic Python structures.
Moreover, pandas complements SQL skills beautifully. You can use SQL to extract data from databases, then leverage pandas for in-memory data manipulation and analysis, combining the strengths of both tools.
By using pandas DataFrames, you'll be able to handle complex data structures more efficiently, perform sophisticated analyses with less code, and ultimately extract more meaningful insights from your data.
What are some essential data cleaning techniques you can perform using pandas?
When it comes to data analysis, a solid foundation is key. Cleaning your data is a vital step that sets the stage for accurate insights and reliable results. Using pandas, you can perform several data cleaning techniques that make your analysis smoother and more efficient.
First, let's talk about cleaning column names. Inconsistent column names can cause headaches down the line. To avoid this, create a function to standardize them by removing extra spaces, replacing spaces with underscores, and converting everything to lowercase. For example, in our laptops dataset, we transformed "Operating System" into "os" for consistency and ease of use.
Next, ensure you have the correct data types. This is essential for avoiding unexpected behavior in your calculations. For instance, in our laptops data, we cleaned up the screen size column by removing the inch symbol and converting it to a float:
laptops["screen_size"] = laptops["screen_size"].str.replace('"', '').astype(float)
laptops.rename({"screen_size": "screen_size_inches"}, axis=1, inplace=True)Handling missing values is another important technique. Pandas gives you flexible options here—you can remove rows with missing data, fill in gaps with specific values, or use statistical measures. In our laptops example, we filled missing prices with the mean price:
laptops["price"] = laptops["price"].fillna(laptops["price"].mean())The approach you choose depends on your specific dataset and analysis goals. It's also a good idea to document your data cleaning steps, so you can remember what you did and allow others to reproduce your work.
By applying these pandas techniques, you'll be well on your way to accurate insights and reliable results. Clean data means fewer errors, more accurate insights, and less time spent troubleshooting down the line. This attention to detail will pay off in the long run, saving you time and headaches in your data analysis journey.
How can combining NumPy and pandas enhance your data analysis capabilities?
When working with complex datasets, combining NumPy and pandas can significantly boost your data analysis capabilities. These two libraries complement each other beautifully, each bringing unique strengths to the table.
NumPy excels at numerical operations, allowing you to perform calculations on large arrays of data quickly. Meanwhile, pandas is ideal for data manipulation and analysis, offering intuitive ways to organize, clean, and explore your data. By using them together, you can tackle more sophisticated data challenges.
For instance, you might use NumPy to perform rapid calculations across an entire dataset, and then use pandas to organize and analyze the results. This synergy is particularly valuable when working with large financial datasets or time series data.
Consider this example of how NumPy and pandas work together:
-
Use NumPy to calculate the change in rankings for companies:
rank_change = previous_rank - current_rank -
Incorporate this NumPy calculation into a pandas DataFrame:
df['rank_change'] = rank_change -
Use pandas to analyze the results, perhaps grouping by industry or calculating average rank changes.
This combination allows for efficient computation and easy data manipulation, all within a single workflow.
In real-world applications, data scientists often use NumPy and pandas together for tasks like portfolio analysis in finance. They might need to perform complex calculations on stock prices (using NumPy) and then analyze the results across different market sectors (using pandas).
By learning to use both NumPy and pandas for data analysis, you'll be well-equipped to handle a wide range of data challenges more efficiently and effectively. This powerful duo will enable you to extract deeper insights from your data, ultimately leading to more informed decision-making in your data science projects.
What's the difference between NumPy arrays and pandas Series, and when would you use each?
NumPy arrays and pandas Series are two fundamental data structures used in data analysis. While they share some similarities, they serve different purposes and have distinct characteristics.
NumPy arrays are designed for efficient numerical computations and are memory-efficient. This makes them ideal for large-scale mathematical operations. For instance, in our tutorial, we used NumPy arrays to perform vectorized operations on a dataset of 1,000,000 elements. This approach was significantly faster than using Python loops.
In contrast, pandas Series can handle mixed-type data and come with built-in labels for each element. This makes them perfect for working with labeled or mixed-type data. In our Fortune 500 analysis, we used a pandas Series to examine company revenues. The labels allowed us to easily access and analyze data by company name.
So, what are the key differences between NumPy arrays and pandas Series?
- Data types: NumPy arrays can only store data of the same type, while pandas Series can store mixed-type data.
- Labels: Pandas Series have an index label for each element, while NumPy arrays use integer indices.
- Functionality: Pandas Series offer a wide range of data manipulation and analysis methods, while NumPy arrays focus on numerical operations.
When to use NumPy arrays:
- You need to perform complex mathematical operations on large datasets.
- You're working with numerical data that's all of the same type.
- Memory efficiency is important.
Choose pandas Series when:
- You need labeled data for easy access and readability.
- You're working with mixed-type data.
- You need to perform data analysis tasks like handling missing values, filtering, or grouping.
In practice, NumPy and pandas often work together in data analysis workflows. You might use NumPy for initial data processing and numerical computations, then convert to a pandas Series or DataFrame for further analysis and visualization.
By understanding the strengths of both NumPy arrays and pandas Series, you can choose the right tool for each stage of your data analysis project, making your workflow more efficient and effective.
How does pandas help you handle missing data in your datasets?
Missing data can greatly affect the accuracy of your analysis, leading to skewed results or incorrect conclusions. Pandas, a popular library for data analysis in Python, provides effective tools to handle this common issue.
Here's how pandas helps you manage missing values in your datasets:
-
Identification: Pandas makes it easy to spot missing data. The info() method gives you a quick overview of your dataset, including the number of non-null values in each column. For a more detailed view, you can use the isnull() function to create a Boolean mask of missing values.
-
Removal: When necessary, pandas allows you to easily remove rows or columns containing missing data. The dropna() method can be used to eliminate rows with any missing values, or you can specify conditions for removal, such as dropping rows only if they have a certain number of missing values.
-
Imputation: Pandas offers flexible options for filling in missing values. The fillna() method allows you to replace missing data with a specific value, the mean, median, or even a calculated value based on other data. For example:
laptops["price"] = laptops["price"].fillna(laptops["price"].mean())
This code replaces any missing prices with the average price across all laptops, ensuring you don't lose valuable data points while maintaining the overall distribution of prices.
In real-world scenarios, you often encounter missing values in your data. For instance, when analyzing customer purchase history, you might come across missing values for certain transactions. Using pandas, you can quickly identify these gaps, decide whether to remove incomplete records or fill them with estimated values, and proceed with your analysis confident in the integrity of your data.
By simplifying the process of handling missing data, pandas allows you to focus on extracting meaningful insights from your datasets. When used in conjunction with other libraries like NumPy, pandas becomes a valuable tool for thorough data analysis, enabling you to tackle complex data challenges with ease and efficiency.
What steps should you take when exploring a new dataset using pandas?
When you start working with a new dataset in pandas, it's essential to take some initial steps to set yourself up for effective data analysis. Here are the key steps to follow:
-
Load and inspect the data: Use
pd.read_csv()or similar functions to load your data, then use.info()to get an overview of columns, data types, and non-null counts. -
Take a closer look at the first few rows: Use
.head()to view the first few entries and get a sense of the data's structure and content. -
Check for missing values: Look for null values using
.isnull().sum()to identify columns that may need cleaning or imputation. -
Examine the basic statistics: Use
.describe()to get summary statistics for numerical columns, helping you understand the data's distribution and range. -
Visualize key features: Create simple plots or histograms to visually inspect data distributions and relationships between variables. This can help you spot patterns or anomalies that might not be immediately apparent.
-
Clean and preprocess: Based on your findings, clean column names, convert data types if needed, and handle missing values appropriately.
For instance, when analyzing a dataset of car sales, you might discover through .describe() and visualization that some cars have impossibly high ages (e.g., 8,000 years old) or prices (e.g., over 10 million euros). This immediately signals the need for data cleaning before proceeding with further analysis.
By following these steps, you'll create a solid foundation for deeper analysis using NumPy and pandas. This initial exploration helps you avoid pitfalls, identify data quality issues early, and gain insights that guide your subsequent analytical approach. Understanding your data thoroughly at the outset can save hours of troubleshooting and prevent misleading conclusions down the line.
How can NumPy and pandas complement your SQL skills in data analysis projects?
When combining NumPy and pandas with SQL skills for data analysis, you'll find that these Python libraries bring unique strengths to the table. Think of SQL as your go-to tool for querying databases and extracting data. Once you have that data, NumPy steps in with its efficient numerical operations. For example, in one project, I used NumPy's vectorized operations to process millions of data points in seconds – a task that would have taken hours with basic Python loops.
Pandas then takes center stage for data manipulation and analysis. Its DataFrame structure makes it easy to clean, transform, and analyze your data. I often use pandas to handle tasks that would be cumbersome in SQL, such as dealing with time series data or performing complex aggregations.
Here's a typical workflow I use:
- Extract data from a database using SQL
- Load the data into a pandas DataFrame for cleaning and preprocessing
- Use NumPy for any heavy numerical computations
- Analyze and visualize the results using pandas and other Python libraries
For instance, when analyzing the Fortune 500 dataset, I used pandas to quickly calculate statistics like average revenues:
print(f500["revenues"].mean())This simple line of code computes the mean revenue across all companies, showcasing how pandas simplifies complex calculations.
By combining SQL, NumPy, and pandas, you'll have a powerful toolkit for data analysis. You'll be able to handle larger datasets, perform more complex analyses, and uncover insights that might be missed when using these tools in isolation.
The key is to use these tools together effectively. Each has its strengths, and learning to leverage them in combination will make you a more versatile and efficient data analyst.
What practical advice does the NumPy and pandas for data analysis tutorial offer for beginners?
When starting to learn NumPy and pandas for data analysis, having practical strategies can make a big difference in your progress. Here are some tips that I've found particularly helpful:
-
Start with a small, real-world project. Choose a dataset that interests you, such as your personal finances or a public dataset related to your favorite hobby. This will make learning more engaging and relevant.
-
Make practice a regular habit. Even 15 minutes of practice each day can be beneficial. I've seen students make significant progress with consistent, bite-sized practice sessions.
-
Take advantage of the excellent resources available for NumPy and pandas. Don't hesitate to consult the documentation when you're stuck – it's a valuable source of information.
-
Connect with others who share your interests. Online forums or local meetups can provide support, motivation, and fresh perspectives on data analysis challenges.
NumPy and pandas work well together, and understanding how they complement each other can be incredibly powerful. For example, I used pandas to clean and standardize course data, and then applied NumPy's array operations to perform complex calculations on completion rates. This combination turned what would have been a time-consuming task into a quick and efficient process.
Remember, every expert starts somewhere. By following tutorials and applying these tips, you'll build a strong foundation in NumPy and pandas. With time and practice, you'll become proficient in using these libraries to uncover insights from complex datasets.