
Tutorial 2: Advanced Data Cleaning in Python
Main Data Cleaning Guide Page
Tutorial 1: Data Cleaning and Analysis in Python
Tutorial 2: Advanced Data Cleaning in Python - You are here
Tutorial 3: Data Cleaning Project Walk-through
Pandas Cheat Sheet and PDF Download
RegEx Cheet Sheet and PDF Download
A few years ago, I started working on an ambitious project to build machine learning models for weather prediction. Despite having sophisticated algorithms and plenty of data, my results were consistently disappointing. After weeks of tweaking my models with no improvement, I finally realized the problem wasn't with my algorithms―it was with my data.
My datasets were a mess. Some weather stations reported temperatures in Celsius, others in Fahrenheit. Wind speeds came in different units, and naming conventions varied across stations. Even simple things like weather conditions were inconsistent―'partly cloudy' in one dataset might be 'p.cloudy' in another. This made it nearly impossible to analyze the data properly or make accurate predictions.

You've likely encountered similar challenges in your own work. Maybe you've struggled with customer data in different formats, survey responses with inconsistent categories, or JSON data from APIs that seems impossible to work with. These are common problems that every data analyst faces, regardless of industry or experience level.
Through teaching at Dataquest and working on numerous projects, I've developed practical techniques for handling these advanced data cleaning in Python challenges. I learned to use regular expressions to standardize text data, ensuring weather conditions like the one I described above were treated consistently. List comprehensions and lambda functions helped me efficiently transform large blocks of data, like converting temperature readings between units. When dealing with missing values, I applied thoughtful imputation techniques using data from nearby weather stations.
In this tutorial, I'll share these practical techniques for cleaning and preparing complex datasets. We'll start with regular expressions for standardizing text data, then move on to efficient data transformation methods using list comprehensions and lambda functions. Finally, we'll tackle the challenge of missing data using various imputation strategies. Throughout each section, I'll share real examples from my weather prediction project and other real-world scenarios I've encountered while teaching.
Let's begin with regular expressions, which provide powerful tools for cleaning and standardizing text data.
Lesson 1 - Regular Expression Basics
When I started working on my weather data project, I spent hours manually fixing text inconsistencies. I wrote long chains of if-statements to check for variations like 'partly cloudy', 'p.cloudy', and 'PARTLY CLOUDY'. Each new variation meant adding another if-statement to my code. I knew there had to be a better way.
That's when I realized regular expressions (regex) was that better way. Instead of writing separate checks for each variation, I could define a single pattern that described what I was looking for. Think about how you might search for a house: you have a list of requirements like three bedrooms, two bathrooms, and at least 1500 square feet. Any house matching those requirements is one you'll want to check out. Regular expressions work similarly on text data―you define a pattern of requirements, and regex finds all text matching that pattern.
For example, instead of writing multiple if-statements to check for 'partly cloudy', 'p.cloudy', and 'PARTLY CLOUDY', I could write a single regex pattern that says "find any text that contains 'partly' or 'p.' followed by 'cloudy' in any capitalization." This one pattern replaced dozens of lines of if-statements and made my code much easier to maintain.
Let's start with a simple example using Python's re (regular expression) module. We'll look for the pattern "and" within a piece of text:
import re
m = re.search('and', 'hand')
print(m)< _sre.SRE_Match object; span=(1, 4), match='and' >In this code, we're using the search function re.search() to look for the pattern 'and' within the text 'hand'. The function finds 'and' within 'hand' (at positions 1-4) and returns a match object with information about what it found. This is a simple example where we're looking for an exact sequence of characters, but regex becomes much more powerful when we start using special pattern characters.
Working with Basic Patterns
The object that re.search() returns contains information about where the match was found and what text matched. If no match is found, the function returns None, making it easy to check if text matches our patterns.
In my years of experience, I've seen how text data rarely comes in a perfectly consistent format. Let's work with a simple example that demonstrates this common challenge. Imagine we're analyzing customer feedback where people have mentioned their favorite colors:
# Sample customer feedback data
string_list = ['Julie's favorite color is Blue.',
'Keli's favorite color is Green.',
'Craig's favorite colors are blue and red.']
# Let's count mentions of 'blue' regardless of capitalization
pattern = '[Bb]lue' # Character set [Bb] matches either 'B' or 'b'
for s in string_list:
if re.search(pattern, s):
print('Match')
else:
print('No Match')Match
No Match
MatchIn this example, we create a list of three strings representing customer feedback. Our goal is to find mentions of the color 'blue' regardless of whether it's capitalized or not. Running our code, we can see that it successfully matches both 'Blue' in the first string and 'blue' in the last string, while correctly not matching the second string which mentions a different color.
Let's break down exactly what's happening in the example above. The character set [Bb] tells regex to match either an uppercase 'B' or lowercase 'b' in the first position, followed by the exact letters 'lue'. This single pattern replaces what would otherwise require multiple if-statements checking for different capitalizations. This table shows how you can also define ranges for character classes:

Building Your Regex Skills
When working with pandas, these patterns become even more powerful. The str.contains() method accepts regex patterns, making it easy to filter and clean large datasets based on text patterns. Personally, I used this feature to quickly identify all weather condition descriptions in my dataset that referred to cloudy conditions, regardless of how they were written.
Here are some key guidelines for picking up regex effectively:
- Start by understanding how patterns match text literally ― the pattern 'cat' simply matches the exact sequence of letters 'cat'
- Practice using character sets to match multiple possibilities in a single position ― like
[Cc]atto match both 'Cat' and 'cat' - Get comfortable with
re.search()before moving on to more complex regex functions - Keep the Python regex documentation handy ― even after years of working with regex, I still reference it regularly
For my project, once I understood these basics, I could write patterns to standardize all those different weather condition formats. Instead of spending hours manually cleaning data with complex if-statements, I had clean, consistent data in minutes. A single pattern like [Pp](artly)?[s.]?[Cc]loudy could match all the variations of 'partly cloudy' in my dataset.
In the pattern above, the ? quantifier makes the preceding character or group optional, meaning it will match zero or one occurrence of that previous element. The character in regex is an escape character that tells regex to treat the next character literally or as a special sequence. It’s used for special symbols (like . for a literal dot) and predefined classes (like s for any space).
Here are some predefined classes that can help simplify regex syntax:

In the next lesson, we'll build on these fundamentals to learn more sophisticated pattern matching techniques.
Lesson 2 - Advanced Regular Expressions
After getting comfortable using basic regex patterns in my weather prediction project, I soon encountered even more complex challenges. I realized that I needed to extract specific parts of text data, like separating city names from weather conditions or pulling out temperature readings from longer strings. This is where capture groups and lookarounds became invaluable tools in my data cleaning workflow.
Understanding Capture Groups
Capture groups allow you to extract specific parts of a pattern by wrapping them in parentheses (()). Think of them like marking sections in a document with sticky notes―they help you identify and extract just the parts you need. Let's work with a practical example using weather station URLs.
In my project, I needed to collect data from various weather stations, each with their own URL format. Here's how I used capture groups to standardize the process of extracting information from these URLs:
import pandas as pd
# Create a pandas Series with weather station URLs
test_urls = pd.Series([
'http://weather.noaa.gov/stations/KNYC/daily',
'https://weathernet.com/stations/new-york/central-park',
'http://cityweather.org/nyc/manhattan/data',
'https://weatherarchive.net/historical/NYC-Central/2023'
])
# Define pattern with capture groups
pattern = r"(https?)://([w.-]+)/?(.*)"
# Extract URL components and add column names
test_url_parts = test_urls.str.extract(pattern, flags=re.I)
test_url_parts.columns = ['protocol', 'domain', 'path']This pattern has three capture groups:
(https?)matches the protocol (http or https)([w.-]+)captures the domain name(.*)gets the rest of the URL path
When we run this code, we get a clean pandas DataFrame with each URL component in its own column:
| protocol | domain | path |
|---|---|---|
| http | weather.noaa.gov | stations/KNYC/daily |
| https | weathernet.com | stations/new-york/central-park |
| http | cityweather.org | nyc/manhattan/data |
| https | weatherarchive.net | historical/NYC-Central/2023 |
By breaking down these URLs into their components, I could easily identify which weather stations I was collecting data from and standardize how I accessed their historical weather records. This was particularly helpful when I needed to automate data collection from multiple sources.
Heads up: the re.I flag tells the vectorized string function str.extract() to ignore case when making a match. This is a common option for many regex operations.
Working with Lookarounds
Lookarounds are special patterns that let you match text based on what comes before or after it, without including those surrounding parts in the match. They're like adding conditions to your pattern matching―"only match this if it has that before it" or "don't match this if it's followed by that."

In my weather project, I used lookarounds to clean up inconsistent temperature readings. Some values had units after them (like '20C' or '68F'), while others had spaces or different formatting (like '20 C', '68 °F', or '68F'.). Here's how I used lookarounds to standardize these readings:
Full disclosure: The pattern we're about to look at might seem complex at first. When I started learning regex, I would have found this intimidating! But don't worry. Just like I did, you'll start with simple patterns and gradually build up to more sophisticated ones. Through practice and the structured learning approach at Dataquest, you'll develop the skills to create and understand patterns like this:
# Sample temperature readings
temps = pd.Series([
'20C', '68F', '22 C', '75 °F', '24C.', '77°F',
'Celsius: 25', '80 degrees F', 'Temperature(C): 23'
])
# Pattern to extract temperature values and units
pattern = r"(d+)s*(?:°|degrees)?s*([CF])(?:.|b)|(?:Celsius|Temperature(C)):s*(d+)"
# Extract temperatures and handle both pattern formats
matches = temps.str.extract(pattern)
# Combine the matches into final temperature and unit columns
temperatures = matches[0].fillna(matches[2])
units = matches[1].fillna('C') # If unit is missing, it was Celsius from pattern
# Create final result
result = pd.DataFrame({
'temperature': temperatures,
'unit': units
})Let's break this pattern down into smaller, more digestible pieces. Each part serves a specific purpose:
(d+): Captures one or more digits representing the temperature value. The+quantifier matches one or more of the preceding element (digits, in this case), ensuring that there is at least one digit present.s*: Matches optional whitespace between the number and the temperature unit or symbol. The*quantifier matches zero or more of the preceding whitespace character, allowing flexibility in spacing.(?:°|degrees)?: An optional non-capturing group ((?: . . .)) that matches either a°symbol or the word degree, that is not stored for later use. The?quantifier at the end makes this group optional, matching zero or one occurrence to allow formats like "20°C" or "20 degrees C".s*: Matches additional optional whitespace between the temperature symbol or word and the unit.([CF]): Captures temperature unit as either "C" or "F", for Celsius or Fahrenheit for later use.(?:.|b): A non-capturing group that allows for either a period (.) or a word boundary (b), matching variations like "24C." or "24C".|: Specifies an alternative pattern, allowing the regex to match either the first temperature format or one of the following.(?:Celsius|Temperature(C)):s*(d+): Matches special formats like "Celsius: 25" or "Temperature(C): 23". The*aftersmatches any preceding whitespace, and+afterdensures one or more digits are captured for the temperature value.
When we run this code, we get these results:
| temperature | unit |
|---|---|
| 20 | C |
| 68 | F |
| 22 | C |
| 75 | F |
| 24 | C |
| 77 | F |
| 25 | C |
| 80 | F |
| 23 | C |
This pattern successfully handles all our temperature formats by:
- Matching standard temperature formats with optional spaces and symbols
- Capturing temperatures described with 'Celsius:' or 'Temperature(C):'
- Properly identifying units in all cases
- Converting the results into a clean, standardized format
Remember, I didn't write this pattern in one go―it evolved as I encountered different temperature formats in my data. That's typically how regex development works: you start simple and gradually add complexity as needed. Through the Dataquest curriculum, you'll learn these patterns step by step, building your confidence with each new concept.
Practical Tips from Teaching Experience
During my time at Dataquest, I've learned that these advanced techniques become much more approachable when you:
- Break down complex patterns into smaller pieces and test each piece separately
- Use the regex101.com testing tool to visualize your patterns
- Keep the Python regex documentation open for reference
- Start with simple patterns and gradually add complexity as needed
In our next lesson, we'll look at how to combine these regex patterns with list comprehensions and lambda functions to transform data even more efficiently. You'll learn how to apply these patterns across entire datasets with just a few lines of code.
Lesson 3 - List Comprehensions and Lambda Functions
While working on my weather prediction project, I spent hours writing loops to clean messy data. It was tedious―four lines of code just to standardize temperature readings, another five to fix station names, and so on. Then I discovered list comprehensions and lambda functions, two Python features that transformed my data cleaning workflow.
Understanding List Comprehensions

List comprehensions provide a clear, concise way to transform data. Instead of writing multiple lines with loops and temporary variables, you can often achieve the same result in a single line, as shown in the example above.
Here's a practical example from my project, where I needed to clean up weather station metadata:
# Sample weather station metadata
weather_stations = [
{'station_id': 'NYC001', 'name': 'Central Park', 'last_updated': '2023-12-01', 'status': 'active'},
{'station_id': 'NYC002', 'name': 'LaGuardia', 'last_updated': '2023-12-01', 'status': 'active'},
{'station_id': 'NYC003', 'name': 'JFK Airport', 'last_updated': '2023-12-01', 'status': 'maintenance'}
]
# Helper function to remove specified keys from a dictionary
def remove_field(d, field):
"""Remove a field from a dictionary (d) and return the modified copy."""
return {k: v for k, v in d.items() if k != field}
# Remove 'last_updated' field from all station records
clean_stations = [remove_field(d, 'last_updated') for d in weather_stations]This list comprehension replaces what would typically be a four-line loop:
# Traditional loop approach
clean_stations = []
for d in weather_stations:
new_d = remove_field(d, 'last_updated')
clean_stations.append(new_d)The list comprehension version isn't just shorter―it's also more readable. You can easily see that we're creating a new list by applying remove_field to each dictionary in our weather_stations dataset.
Working with Lambda Functions
Lambda functions are small, single-use functions that you can define right where you need them. For my project, I used them to handle data that needed different processing based on its format. Here's an example where I needed to process weather condition codes:
# Sample weather condition codes with descriptions
condition_codes = pd.Series([
['SKC', 'CLEAR', 'Sunny conditions'],
['BKN', 'BROKEN', 'Mostly cloudy'],
['OVC', 'OVERCAST', 'Complete cloud cover'],
['SCT', 'SCATTERED', 'Partly cloudy']
])
# Extract the plain-language description (last element) when available
cleaned_conditions = condition_codes.apply(lambda l: l[-1] if len(l) == 3 else None)This lambda function examines each list of condition codes and makes a decision: if the list has exactly 3 items (code, category, and description), keep the description; otherwise, return None. Without lambda functions, we'd need to write a separate function definition:
# Traditional function approach
def clean_condition(code_list):
if len(code_list) == 3:
return code_list[-1]
return None
cleaned_conditions = condition_codes.apply(clean_condition)Combining Techniques for Efficient Data Cleaning
Through my teaching experience at Dataquest, I've found these guidelines particularly helpful for learners:
- Use list comprehensions when you need to transform each item in a dataset the same way
- Choose lambda functions for quick, one-off transformations that need simple logic
- Combine both techniques with regex patterns for powerful text processing
- Keep readability in mind―if your list comprehension or lambda function becomes complex, break it into smaller pieces
Let's look at a real example that combines these techniques to clean weather station data. First, we'll create some sample data and define our helper function to convert to Celsius:
# Sample raw weather station data
raw_data = [
{
'station': 'CENTRAL PARK WEATHER STATION',
'temp': '75F',
'timestamp': '2023-12-01 12:00:00'
},
{
'station': 'La Guardia Airport Station',
'temp': '23C',
'timestamp': '2023-12-01 12:00:00'
},
{
'station': 'JFK Weather Monitor',
'temp': '68F',
}
]
def convert_to_celsius(temp_str):
"""Convert temperature string to Celsius float value."""
if not temp_str:
return None
# Extract numeric value and unit
value = float(''.join(c for c in temp_str if c.isdigit() or c == '.'))
unit = temp_str[-1].upper()
# Convert if needed
if unit == 'F':
return round((value - 32) * 5/9, 1)
return value # Already CelsiusNow we can combine list comprehensions, regex, and our conversion function to clean the data:
# Clean and standardize the data
clean_data = [
{
'station': re.sub(r's+', '_', d['station'].lower()), # Replace multiple spaces with underscore
'temp_c': convert_to_celsius(d.get('temp')), # Convert to Celsius if present
'timestamp': d.get('timestamp', None) # Handle missing timestamps
}
for d in raw_data
]
# View the results
for station in clean_data:
print(f"Station: {station['station']}")
print(f"Temperature (C): {station['temp_c']}")
print(f"Timestamp: {station['timestamp']}n")Station: central_park_weather_station
Temperature (C): 23.9
Timestamp: 2023-12-01 12:00:00
Station: la_guardia_airport_station
Temperature (C): 23.0
Timestamp: 2023-12-01 12:00:00
Station: jfk_weather_monitor
Temperature (C): 20.0
Timestamp: NoneThis code combines several cleaning operations in one efficient process:
- Uses regex (
re.sub()) to standardize station names by converting spaces to underscores and making them lowercase - Converts temperatures to Celsius, handling both Fahrenheit and Celsius inputs
- Manages missing timestamps using dictionary's
get()method with a default value
In my case, this approach helped me standardize data from multiple weather stations that each had their own formatting quirks. Instead of writing separate cleaning functions for each data source, I could process them all with a single list comprehension.
In our next lesson, we'll tackle another common challenge in data cleaning: working with missing data. We'll see how these same principles of clear, efficient code can help us deal with gaps in our data effectively.
Lesson 4 - Working with Missing Data
When I started analyzing my weather prediction project data, I noticed that some weather stations reported temperature readings but were missing wind speeds. Others had detailed precipitation data but lacked humidity measurements. My first instinct was to remove any rows with missing values, but this would have meant losing valuable information from stations that were otherwise providing good data.
Let's look at a sample of weather station data and analyze its missing value patterns:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Create sample data - 24 hours of readings from 5 stations
dates = pd.date_range('2023-12-01', '2023-12-02', freq='H')[:-1] # 24 hours of data
stations = ['Central_Park', 'LaGuardia', 'JFK', 'Newark', 'White_Plains']
weather_data = pd.DataFrame({
'timestamp': np.repeat(dates, len(stations)),
'station': np.tile(stations, len(dates)),
'temperature': np.random.normal(70, 5, size=24*len(stations)),
'humidity': np.random.normal(65, 10, size=24*len(stations)),
'wind_speed': np.random.normal(10, 3, size=24*len(stations)),
'precipitation': np.random.normal(0.02, 0.01, size=24*len(stations))
})
# Introduce realistic missing patterns
# Simulate sensor failures and maintenance periods
weather_data.loc[weather_data['station'] == 'JFK', 'temperature'] = np.nan # Temperature sensor down
weather_data.loc[weather_data['timestamp'].dt.hour < 6, 'humidity'] = np.nan # Early morning humidity sensor issues
weather_data.loc[weather_data['station'].isin(['LaGuardia', 'Newark']), 'wind_speed'] = np.nan # Wind sensor maintenance
weather_data.loc[weather_data['precipitation'] < 0, 'precipitation'] = np.nan # Remove negative precipitation values
# Count null values in each column
null_counts = weather_data.isnull().sum()
null_counts_pct = (null_counts / len(weather_data) * 100).round(1)
# Create a summary DataFrame
null_summary = pd.DataFrame({
'null_counts': null_counts,
'null_percentage': null_counts_pct
})This code creates a sample dataset with some common missing data patterns we might see in real weather station data. Since we're using random numbers to generate our sample data, your exact results may vary slightly from what's shown below, particularly for precipitation values where we remove negative readings. However, the overall patterns will remain consistent.
Let's examine the missing data patterns:
| Column | Missing Values | Missing Percentage |
|---|---|---|
| timestamp | 0 | 0.0% |
| station | 0 | 0.0% |
| temperature | 24 | 20.0% |
| humidity | 30 | 25.0% |
| wind_speed | 48 | 40.0% |
| precipitation | varies | varies |
This summary reveals several patterns in our data:
- Temperature readings are missing for one station (JFK) ― exactly 24 readings (one full day)
- Humidity sensors have issues during early morning hours (first 6 hours for all 5 stations = 30 readings)
- Wind speed measurements are missing from two stations (LaGuardia and Newark = 48 readings)
- Precipitation readings may be missing where random values were negative (this number will vary with each run)
Understanding these patterns is crucial for deciding how to handle the missing values. For example, knowing that temperature readings are missing for an entire station suggests we might want to look at nearby stations for reasonable estimates. Similarly, the pattern of missing humidity readings during early morning hours might indicate a systematic issue with data collection that needs to be addressed.
Visualizing Missing Data Patterns
Sometimes patterns in missing data aren't obvious from summary statistics alone. Let's create a visual representation of our missing values to help identify any patterns that might not be apparent in the numerical summaries:
def plot_null_matrix(df):
"""
Create a visual representation of missing values in a dataframe.
Light squares represent missing values, dark squares represent present values.
"""
plt.figure()
# Sort the dataframe by station and timestamp for better visualization
df_sorted = df.sort_values(['station', 'timestamp'])
# Create a boolean dataframe based on whether values are null
df_null = df_sorted.isnull()
# Create a heatmap of the boolean dataframe
sns.heatmap(df_null, cbar=False, yticklabels=False)
plt.xticks(rotation=45, ha='right')
plt.title('Missing Value Patterns in Weather Station Data')
plt.tight_layout()
plt.show()When we visualize our missing data patterns, we can see clear structures that might not be obvious from just looking at the numbers:
# Reorder columns for better visualization
column_order = ['station', 'timestamp', 'temperature', 'humidity', 'wind_speed', 'precipitation']
plot_null_matrix(weather_data[column_order])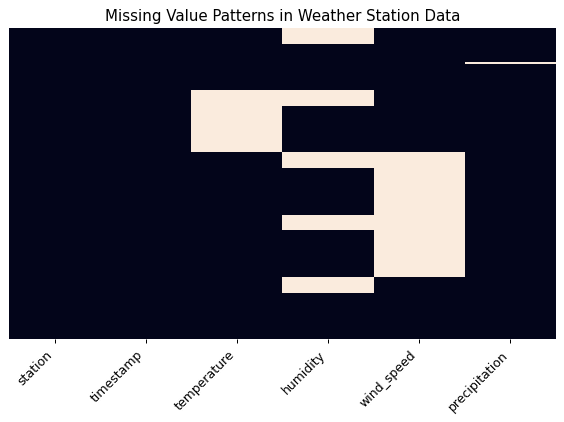
The resulting heatmap shows several interesting patterns:
- Vertical bands in the temperature column show complete missing data for the JFK station
- Regular patterns in the humidity column represent the missing early morning readings
- Clear blocks in the wind speed column show the two stations with missing measurements
- Scattered missing values in the precipitation column where negative values were removed
This visualization helps us make better decisions about how to handle missing values. For example:
# Create masks for different missing value scenarios
temp_missing = weather_data['temperature'].isnull()
nearby_stations = weather_data.groupby('timestamp')['temperature'].transform(
lambda x: x.fillna(x.mean())
)
# Fill missing temperatures with nearby station averages
weather_data.loc[temp_missing, 'temperature'] = nearby_stations[temp_missing]In this example, we're using the average temperature from other stations at the same timestamp to fill in missing values. This approach makes sense because we can see from our visualization that when one station is missing temperature data, other stations typically have readings available.
The heatmap also reveals that our missing data isn't random―it follows specific patterns related to station operations and sensor functionality. This insight helps us choose more appropriate strategies for handling missing values rather than using simple approaches like removing incomplete rows or filling with overall averages.
Strategies for Handling Missing Data
Once we understand our missing data patterns, we can apply appropriate strategies to handle them. In my weather project, I discovered that using data from nearby stations often provided better estimates than overall averages. Let's look at how to implement this approach:
# Calculate average temperatures by timestamp, excluding missing values
timestamp_averages = weather_data.groupby('timestamp')['temperature'].transform(
lambda x: x.mean()
)
# Create a mask for missing temperatures
temp_missing = weather_data['temperature'].isnull()
# Fill missing temperatures with timestamp averages
weather_data['temperature'] = weather_data['temperature'].mask(
temp_missing,
timestamp_averages
)Let's verify our results by checking the temperature values before and after filling:
# View sample of data before and after filling
print("Sample of filled temperature values:")
sample_stations = weather_data[['station', 'timestamp', 'temperature']].head(10)
print(sample_stations)We can apply similar strategies to other measurements. For humidity readings, we might want to use values from similar times on other days:
# For humidity, calculate average by hour across all days
hourly_humidity = weather_data.groupby(weather_data['timestamp'].dt.hour)['humidity'].transform('mean')
# Create a mask for missing humidity values
humidity_missing = weather_data['humidity'].isnull()
# Fill missing humidity values with hourly averages
weather_data['humidity'] = weather_data['humidity'].mask(
humidity_missing,
hourly_humidity
)This approach makes sense because humidity often follows daily patterns―early morning humidity readings tend to be similar from one day to the next. By using hourly averages, we maintain these natural patterns in our data.
For wind speed measurements, where we're missing data from entire stations, we might want to be more conservative:
# For wind speed, only fill using nearby stations within the same hour
# that are within a certain threshold
def get_nearby_wind_speed(group):
"""Calculate average wind speed for nearby stations."""
if group['wind_speed'].isnull().all():
return group['wind_speed'] # If all stations are missing data, return as is
return group['wind_speed'].fillna(group['wind_speed'].mean())
# Group by timestamp and fill missing wind speeds
weather_data['wind_speed'] = weather_data.groupby('timestamp').apply(
lambda x: get_nearby_wind_speed(x)
)['wind_speed']This more conservative approach for wind speed acknowledges that wind conditions can vary significantly between stations, so we only want to use readings from the same time period.
Through my experience with weather data, I've found that different measurements often require different handling strategies. Temperature tends to be fairly consistent across nearby stations, humidity follows daily patterns, and wind speed can vary significantly by location. Understanding these characteristics helps us choose appropriate methods for handling missing values.
Best Practices for Missing Data
Through my experience teaching at Dataquest and working with real-world datasets, I've developed these guidelines for handling missing data:
- Always investigate why data is missing before deciding how to handle it
- Consider the context of your data when choosing an imputation strategy
- Document your decisions about handling missing data―future you will thank present you
- Test your imputation strategy on a small sample before applying it to your full dataset
- Validate your results to ensure your handling of missing data hasn't introduced bias
Now that we've covered these essential data cleaning techniques, let's look at how to put them all together in practice. In the final section, I'll share some advice about combining these methods effectively in your own data cleaning projects.
Advice from a Python Expert
From teaching at Dataquest and working with countless datasets, I've learned that proper data cleaning is often the defining factor between the success and failure of a data analysis project. Looking back on my weather prediction project, I can finally say that what began as a frustrating experience with messy data turned into an invaluable learning opportunity.
The real power of the techniques we've covered in this tutorial comes from using them together thoughtfully. Like when I used regular expressions to standardize weather condition descriptions, then applied list comprehensions to efficiently transform thousands of temperature readings. Then, when I encountered missing data, I used nearby weather station readings combined with pandas' powerful data manipulation methods to fill the gaps intelligently.
Lessons Learned
Through years of teaching and practical experience, I've found these principles particularly valuable:
- Start small and test thoroughly ― clean a sample of your data first to validate your approach
- Document your cleaning steps ― include comments explaining why you made specific choices
- Keep your original data intact ― always work with copies when cleaning
- Validate your results ― check that your cleaning hasn't introduced new problems or biases
- Consider the context ― what makes sense for one dataset might not work for another
Building Your Skills
If you're looking to develop your data cleaning skills further, I encourage you to:
- Practice with real datasets ― they often present challenges you won't find in tutorials
- Share your work in the Dataquest Community to get feedback from other learners
- Document your cleaning processes ― create a personal library of useful cleaning patterns
- Take our Advanced Data Cleaning in Python course for more in-depth practice
Final Thoughts
Remember that data cleaning isn't just about fixing errors―it's about understanding your data deeply enough to prepare it properly for analysis. When I finally got my weather prediction models working accurately, it wasn't because I found a better algorithm. It was because I took the time to understand and properly clean my data.
The techniques we've covered―regular expressions, list comprehensions, lambda functions, and missing data handling―are powerful tools that will serve you well in any data project. But they're most effective when used thoughtfully, with a clear understanding of your data and your analysis goals.
Keep practicing, stay curious about your data, and remember: good analysis always starts with clean data. With these skills, you’ll spend less time wrestling with messy datasets and more time wowing everyone with your insights!
Frequently Asked Questions
What are regular expressions and how do they improve text data cleaning in Python?
Regular expressions, or regex, are tools that help you tidy up messy text data in Python. Instead of writing multiple if-statements to handle different text variations, you can use a single regex pattern to match and standardize your data.
Using Python's re module, you can create powerful patterns to match text. For example:
import re
string_list = ['Julie's favorite color is Blue.',
'Keli's favorite color is Green.',
'Craig's favorite colors are blue and red.']
# Let's count mentions of 'blue' regardless of capitalization
pattern = '[Bb]lue' # Character set [Bb] matches either 'B' or 'b'
for s in string_list:
if re.search(pattern, s):
print('Match')
else:
print('No Match')Match
No Match
MatchThis pattern uses a character set [Bb] to match either uppercase or lowercase 'B', making it perfect for standardizing inconsistent capitalizations in your data.
Regex really shines when dealing with complex text formats. For example, you can use patterns with special characters to match variations in how data is written:
smatches any whitespace characterdmatches any digit?makes the previous element optional.matches any character except newline
Some key benefits of using regex for data cleaning include:
- Standardizing text data with consistent formatting
- Extracting specific information using capture groups
- Processing large text datasets efficiently
- Reducing complex cleaning code to simple patterns
To effectively use regex in your data cleaning:
- Start with simple literal patterns
- Practice using character sets for matching variations
- Get comfortable with basic functions like
re.search() - Keep the Python regex documentation handy for reference
- Test patterns on small samples before applying to full datasets
By incorporating regular expressions into your data cleaning workflow, you can handle text inconsistencies more efficiently and produce cleaner, more reliable datasets for analysis. Whether you're standardizing categorical variables, cleaning survey responses, or processing text fields, regex provides the tools to tackle these challenges effectively.
How do you implement advanced data cleaning in Python using regular expressions?
Regular expressions (regex) in Python can help you transform messy text data into clean, standardized formats. Instead of writing multiple if-statements to handle different text variations, you can use a single regex pattern to match and clean your data efficiently.
For example, let's say you have temperature data that appears in various formats like '20C', '68F', '22 C', '75 °F', '58 degrees F', or 'Temperature(C): 23'. You can use a regex pattern to clean this data. Here's an example pattern:
pattern = r"(d+)s*(?:°|degrees)?s*([CF])(?:.|b)|(?:Celsius|Temperature(C)):s*(d+)"
This pattern has several components that work together to match and clean the data. Let's break it down:
(d+)captures one or more digits for the temperature value.s*handles optional whitespace between elements.(?:°|degrees)?matches optional degree symbols or text.([CF])captures the temperature unit (Celsius or Fahrenheit).- The pattern also handles special formats like "Temperature(C): 23".
To use regex effectively for data cleaning, follow these steps:
- Start with simple patterns and gradually increase complexity.
- Test your patterns on small data samples first.
- Use the regex101.com testing tool to visualize and debug patterns.
- Keep the Python regex documentation open for reference.
- Document your patterns with clear comments explaining each component.
When working with complex data formats, it's helpful to break down your cleaning process into steps:
- Identify common patterns in your messy data.
- Create and test regex patterns for each variation.
- Apply patterns systematically to standardize your data.
- Validate results to ensure accurate cleaning.
Common challenges when working with regex include handling unexpected data formats and maintaining readable patterns. To overcome these challenges, try the following:
- Test patterns against diverse data samples.
- Break complex patterns into smaller, manageable pieces.
- Use clear variable names and comments.
- Validate cleaned data against expected formats.
Remember, effective regex implementation comes from understanding both the pattern syntax and your data's structure. Take time to analyze your data's patterns before writing complex expressions, and always validate your results to ensure accurate cleaning.
Which pattern matching symbols are most useful for cleaning text data?
When working with text data, you'll often encounter inconsistencies that need to be cleaned up. Certain pattern matching symbols can be especially helpful in this process. Based on my experience working with various datasets, I've found the following symbols to be particularly useful:
Basic Matches
[]for character sets (e.g.,[Bb]matches 'B' or 'b')()for capture groups|for alternatives
Predefined Classes
dmatches any digitsmatches any whitespace characterwmatches word characters
Quantifiers
?makes the previous element optional*matches zero or more occurrences+matches one or more occurrences
For example, a pattern like [Pp](artly)?[s.]?[Cc]loudy can match variations like 'partly cloudy', 'p.cloudy', and 'Partly Cloudy'. The [] handles case variations, ? makes elements optional, and s matches spaces while . matches a literal dot.
When working with temperature data, I've used patterns like (d+)s*(?:°|degrees)?s*([CF]) to match various formats like '20C', '68F', '22 C', '75 °F', and '16 degrees C'. This flexibility is essential when dealing with real-world data that often comes in inconsistent formats.
To get the most out of pattern matching, it's helpful to keep a few tips in mind:
- Start with simple patterns and gradually add complexity
- Test patterns on small samples first
- Keep the regex documentation handy for reference
- Consider readability when combining multiple symbols
By using these pattern matching symbols and following these tips, you can transform messy text data into clean, consistent formats ready for analysis.
How do capture groups help extract specific information from text data?
Capture groups in regular expressions are a powerful tool for extracting specific parts of text. By wrapping patterns in parentheses, you can identify and extract just the parts you need. Think of them like labels that help you organize and make sense of complex text data.
For example, when working with URLs like 'http://weather.noaa.gov/stations/KNYC/daily', you can use capture groups to break down the URL into its components:
pattern = r"(https?)://([w.-]+)/?(.*)"
This pattern has three capture groups:
(https?)matches the protocol (http or https)([w.-]+)captures the domain name(.*)gets the rest of the URL path
When applied to weather station URLs, this pattern cleanly separates each component into its own column, making the data easier to analyze and process. This technique is particularly useful for advanced data cleaning in Python when dealing with semi-structured text data like log files, URLs, or inconsistently formatted fields.
Besides capture groups, there are also non-capture groups, defined with the syntax (?: ... ). Non-capture groups let you group elements without saving the match, which is helpful for organizing complex patterns without storing unneeded matches.
So, what are the benefits of using capture groups? They allow you to extract information from complex text with precision, organize extracted data into structured formats, and standardize inconsistent data formats. Additionally, capture groups make it easier to automate the processing of large text datasets and support data validation and quality checks.
When working with capture groups in your data cleaning workflow, here are some best practices to keep in mind:
- Break down complex patterns into smaller, manageable pieces
- Test your patterns on small samples first
- Use clear and descriptive names for extracted components
- Document your patterns for future reference
- Consider combining capture groups with other regex features for more powerful matching
By incorporating capture groups into your text processing toolkit, you can efficiently transform messy, unstructured text data into clean, organized formats ready for analysis. Whether you're processing URLs, cleaning log files, or standardizing inconsistent data formats, capture groups provide the precision and flexibility needed for effective data cleaning.
What are the differences between positive and negative lookarounds in regex?
Lookarounds are special patterns in regex that help you match text based on what comes before or after it, without including those surrounding parts in the match. The main difference between positive and negative lookarounds lies in their assertions. Positive lookarounds require certain patterns to exist, while negative lookarounds require patterns to not exist.
Let's break it down further. Positive lookarounds use (?=) for lookahead and (?<=) for lookbehind. These are useful when you need to validate specific formats in your data. For example, when working with temperature readings, you can use a positive lookahead to ensure you're capturing numbers that are actually temperatures by checking for unit markers like 'C' or 'F'.
On the other hand, negative lookarounds use (?!) for lookahead and (?<!) for lookbehind. These help you exclude unwanted matches, making them valuable for filtering out data that might technically match your pattern but isn't what you want. For example, when cleaning numerical data, you might use a negative lookbehind to avoid matching numbers that are part of dates or other irrelevant measurements.
A practical pattern that combines both types might look like this:
(d+)s*(?:°|degrees)?s*([CF])(?:.|b)
This pattern uses positive lookarounds to ensure proper temperature formatting while avoiding unwanted matches. The s* allows for optional whitespace, and (?:°|degrees)? uses a non-capturing group to match optional temperature symbols.
When working with lookarounds in your data cleaning workflows, keep the following tips in mind:
- Use positive lookarounds to validate specific formats in your data.
- Apply negative lookarounds to exclude unwanted matches.
- Combine both types for precise pattern matching.
- Always test your patterns thoroughly with sample data before applying them to larger datasets.
By understanding the differences between positive and negative lookarounds, you can create more precise and efficient pattern matching solutions for your data cleaning needs.
How can list comprehensions speed up data cleaning operations?
List comprehensions are a powerful tool in Python for cleaning data more efficiently. By allowing you to transform data in a single line of code, they eliminate the need for multiple lines of code with loops and temporary variables. This makes advanced data cleaning in Python more streamlined and efficient.
For example, when working with weather station metadata, you can use a list comprehension to remove unwanted fields from multiple records at once using a helper function called remove_field. Here's an example:
clean_stations = [remove_field(d, 'last_updated') for d in weather_stations]
This concise line of code replaces what would typically require a four-line loop:
clean_stations = []
for d in weather_stations:
new_d = remove_field(d, 'last_updated')
clean_stations.append(new_d)
So, how do list comprehensions speed up data cleaning operations? There are several reasons:
- They eliminate the overhead of repeated append operations.
- They reduce memory usage by creating the output list just once.
- They process data more efficiently through optimized bytecode.
- They minimize the risk of errors from complex loop structures.
When working with large datasets, these performance benefits become particularly significant. In my experience, cleaning operations that previously took minutes with traditional loops can complete in seconds using list comprehensions. However, it's worth noting that very complex operations might be better split into traditional loops for clarity and maintainability.
To get the most out of list comprehensions in data cleaning, follow these best practices:
- Keep operations simple and focused on a single transformation.
- Use descriptive variable names to maintain readability.
- Test with small data samples before processing large datasets.
- Consider breaking down complex operations into multiple steps.
- Balance code conciseness with maintainability.
By incorporating list comprehensions into your data cleaning workflow, you can significantly reduce processing time and create more elegant and maintainable code. This efficiency gain allows you to focus more on analysis and less on data preparation.
When should you choose lambda functions over traditional functions in data cleaning?
Lambda functions are best suited for simple, one-off transformations in your data cleaning workflows. They're especially useful when working with pandas operations that require quick, single-purpose functions, and the logic is straightforward.
For example, when cleaning weather condition codes, a lambda function works perfectly for extracting specific elements:
cleaned_conditions = condition_codes.apply(lambda l: l[-1] if len(l) == 3 else None)
In contrast, the same operation written as a traditional function would be more verbose:
def clean_condition(code_list):
if len(code_list) == 3:
return code_list[-1]
return None
cleaned_conditions = condition_codes.apply(clean_condition)
Through my experience with data cleaning, I've learned that lambda functions are ideal when:
- Your operation is simple and can be expressed in a single expression
- The function will only be used once in your code
- You're working with pandas operations like
apply()ortransform() - The logic doesn't require complex error handling
On the other hand, I prefer traditional functions when:
- The transformation requires multiple steps
- The logic needs complex error handling
- The function will be reused throughout the code
- Debugging capabilities are important
- The operation needs detailed documentation
The key is to prioritize readability. If a lambda function becomes too complex to understand at a glance, it's better to use a traditional function definition. This ensures that your code remains clear and maintainable in your data cleaning pipeline.
What are effective ways to visualize missing data patterns?
Visualizing missing data patterns is a powerful technique for understanding gaps in your dataset. By creating visual representations of missing values, you can identify patterns that might not be immediately apparent from summary statistics alone.
One effective approach is to use heatmaps, where light squares represent missing values and dark squares show present values. Here's a Python function I used to create these visualizations for my weather prediction project:
def plot_null_matrix(df):
plt.figure()
df_sorted = df.sort_values(['station', 'timestamp'])
df_null = df_sorted.isnull()
sns.heatmap(df_null, cbar=False, yticklabels=False)
plt.xticks(rotation=45, ha='right')
plt.title('Missing Value Patterns in Weather Station Data')
plt.tight_layout()
plt.show()
When analyzing my weather station data, this visualization helped me identify several important patterns:
- Vertical bands showing complete missing data for specific stations
- Regular patterns in humidity readings during early morning hours
- Clear blocks of missing wind speed measurements from certain stations
- Scattered missing precipitation values
Understanding these patterns is essential for choosing the right handling strategies. In my case, when I noticed that temperature readings were missing for an entire station, I realized I could use readings from nearby stations as reasonable estimates. Similarly, seeing regular patterns in missing humidity readings during early morning hours indicated a systematic data collection issue that needed to be addressed.
To effectively use missing data visualizations in your own work:
- Sort your data in a meaningful way before visualization (e.g., by time and location)
- Look for patterns across different variables
- Consider the context of your data when interpreting patterns
- Use visualizations to inform your missing data handling strategy
- Document any systematic patterns you discover
By incorporating these visualizations into your data cleaning workflow, you can make more informed decisions about handling missing values and ensure your final analysis is based on a thorough understanding of your data's quality and completeness.
How do you select the right strategy for handling missing values?
Selecting the right strategy for handling missing values starts with understanding the patterns in your data. To do this, try visualizing missing data through heatmaps. This can reveal important structures, such as whether values are missing randomly or follow specific patterns like time-of-day or sensor maintenance schedules.
When choosing a strategy, consider the following key steps:
- Analyze patterns through visualization and summary statistics to get a sense of what's going on with your data.
- Understand the context of why data might be missing. Is it due to equipment failure or human error?
- Examine relationships between variables to see if there are any patterns or correlations that can help you fill in missing values.
- Test different approaches on a small sample to see what works best for your data.
- Validate your results to ensure you haven't introduced any bias.
Different scenarios call for different strategies. For example, if you're working with time-series data, using values from similar time periods can be effective. If you have spatial relationships, nearby values might provide good estimates.
Some effective approaches include:
- Using averages from similar time periods for cyclical data, like hourly averages to fill in missing readings.
- Leveraging readings from nearby locations for spatial data, like temperature readings from nearby locations.
- Applying more conservative approaches when dealing with highly variable measurements.
- Considering relationships between different variables for informed estimations.
Before implementing any strategy, make sure to:
- Test your approach on a small sample to ensure it works as expected.
- Verify that filled values maintain reasonable relationships with other variables.
- Document your decisions and rationale, so you can refer back to them later.
- Check that your strategy hasn't introduced systematic bias, which can affect your subsequent analysis.
- Consider the impact on your subsequent analysis, and make adjustments as needed.
- Use a copy of your original data to keep the source intact.
Remember, the goal is to maintain the integrity of your data while making it more complete and useful for analysis. The best strategy often combines understanding of both the technical aspects of your data and its real-world context.
What methods help identify and fix inconsistent data formats?
When working with data, it's common to come across inconsistencies in formatting. To address this issue, you'll need a systematic approach that combines visual inspection, pattern analysis, and automated cleaning techniques. In my experience, I've found several effective methods for handling these challenges.
To identify format inconsistencies, you can try the following:
- Create frequency tables of unique values to spot variations. This can help you identify patterns in your data that might be causing inconsistencies.
- Use visualization tools to highlight patterns in your data. This can make it easier to see where inconsistencies are occurring.
- Apply data analysis techniques to understand format distributions. This can help you identify the root cause of the inconsistencies.
- Check for mixed units or different decimal representations. This is especially important when working with numerical data.
- Look for variations in text formatting, spacing, or special characters. These small differences can add up and cause big problems.
For fixing inconsistent formats, I've found the following approaches to be particularly effective:
Regular expressions can be a powerful tool for standardizing text data. For example, a pattern like [Pp](artly)?[s.]?[Cc]loudy can standardize variations like 'partly cloudy', 'p.cloudy', and 'Partly Cloudy'. This approach works well for text data with predictable patterns.
When working with numerical data, you can use mathematical functions to standardize units and formats. For example, when working with temperature data, you can use functions to convert between units and standardize decimal places. These functions can be combined with list comprehensions for efficient processing across large datasets.
Here are some best practices to keep in mind:
- Start small and validate your cleaning approach before applying it to your entire dataset.
- Document your standardization rules and decisions so you can refer back to them later.
- Create reusable cleaning functions to ensure consistent processing.
- Keep your original data intact while cleaning, just in case you need to go back to the original version.
- Validate your results to ensure accuracy and test edge cases to catch potential issues.
Remember, the key to successfully identifying and fixing inconsistent data formats is to take the time to understand your data's patterns and choose the right approach for the job. What works for one type of data might not work for another, so be sure to consider the context of your data before implementing cleaning solutions.
How do you document data cleaning steps for reproducibility?
Documenting your data cleaning steps is essential for ensuring that your work is transparent and can be easily replicated by others. Below is a step-by-step approach to documentation that can help you with this.
To start, create a clear record of your initial data assessment. This should include:
- A description of any quality issues you find, such as inconsistent formats or missing values
- Notes on any patterns or systematic issues in the data
- Your initial cleaning strategy and the assumptions that underlie it
For each cleaning step, be sure to document the following key elements:
- The specific changes you made and why you made them
- The methods and functions you used, including any parameters
- How you validated the results
- Any challenges or edge cases you encountered
To keep your code organized and easy to understand, follow these best practices:
- Use descriptive names for variables and functions
- Add clear comments explaining complex operations
- Break down complicated processes into smaller, focused steps
- Include sample data showing the before and after states
Some practical tips I've learned through my experience include:
- Always work with copies of your original data
- Use version control for your cleaning scripts
- Create a separate documentation file or notebook
- Include examples of both typical and edge cases
- Note any external data sources or reference materials you used
By following these steps and documenting your results at each stage, you'll create a clear trail showing how your data was transformed and why specific decisions were made. This will make your work both reproducible and trustworthy.
What are the best ways to validate data cleaning results?
Validating data cleaning results is essential for ensuring the quality and reliability of your analysis. Having worked with a variety of datasets, I've identified several effective validation strategies that can help you achieve this goal.
One effective way to validate your data is by using visualizations. By creating heatmaps of your cleaned data, you can quickly identify any remaining patterns or anomalies that might indicate cleaning issues. For example, a heatmap can reveal unusual patterns or outliers that need your attention. Looking for vertical or horizontal bands in the visualization can help you identify systematic issues that might have been introduced during cleaning.
Here are some key validation strategies I recommend you use:
- Test your cleaning process on a small sample first and verify results manually to ensure everything is working as expected.
- Compare summary statistics before and after cleaning, such as means, medians, and standard deviations, to see if there are any significant changes.
- Create visualizations to compare data distributions pre- and post-cleaning to identify any differences.
- Cross-validate with known good data when possible to ensure your cleaning process is accurate.
- Check for logical consistency in your results, such as temperature ranges and time patterns, to ensure everything makes sense.
When filling in missing values, make sure the filled data maintains its relationships with other variables. For example, if you've used averages from similar time periods to fill gaps, verify that the filled values follow expected patterns and maintain reasonable relationships with related measurements.
Some practical tips for effective validation include:
- Keeping detailed documentation of all validation steps to track your progress and identify any issues.
- Using multiple validation methods to cross-check results and ensure accuracy.
- Paying special attention to edge cases and outliers to catch any potential problems.
- Verifying that cleaning hasn't introduced new biases to ensure your data remains reliable.
- Considering the context and domain knowledge when validating results to ensure everything makes sense.
- Testing your cleaning process with different subsets of your data to ensure it works consistently.
Validation is meant to help you catch errors, but it also ensures your cleaned data is reliable and ready for meaningful analysis.