
Tutorial 1: Data Cleaning and Analysis in Python
Main Data Cleaning Guide Page
Tutorial 1: Data Cleaning and Analysis in Python - You are here
Tutorial 2: Advanced Data Cleaning in Python
Tutorial 3: Data Cleaning Project Walk-through
Pandas Cheat Sheet and PDF Download
RegEx Cheet Sheet and PDF Download
Have you ever felt that initial rush of excitement when starting a new data analysis project, only to have it disappear when you see how messy your data is? I experienced this firsthand a few years ago while working on a weather prediction project. I had gathered several weather datasets from different sources, confident that with such extensive information, my machine learning model would produce accurate predictions. But things didn't go as planned―a direct result of not including a data cleaning in Python step in my plan.
When I ran my first set of predictions, the results made no sense. After hours of banging on my keyboard, I realized the issue wasn't with my model―it was with my data. Some weather stations reported temperatures in Celsius, others in Fahrenheit. Wind speeds came in different units, and naming conventions looked like distant cousins across my datasets. Some values were missing, while others seemed questionable.
Through this experience, I learned that good analysis requires clean data. When I started over and properly cleaned the data, I encountered several common challenges that you'll likely face in your own work:
- Standardizing formats and units: I converted all temperatures to Celsius and wind speeds to meters per second
- Handling missing values: I addressed gaps in weather station recordings
- Removing duplicates: I dealt with stations reporting the same data multiple times
- Investigating outliers: I examined extreme temperature readings
- Correcting data types: I fixed numeric data that was stored as text
Python's pandas library makes handling these situations much simpler than trying to clean data manually. With pandas, you can efficiently standardize formats, handle missing values, remove duplicates, and prepare your data for analysis. You'll find these skills valuable in any data role―whether you're analyzing customer behavior, financial data, or scientific measurements.
Throughout this tutorial, we'll explore essential techniques for cleaning and preparing data using pandas. You'll learn how to combine datasets, transform data types, work with strings, and handle missing values. We'll apply these methods to real-world data challenges, similar to the ones I faced in my weather project. By the end, you'll be able to take messy, raw data and transform it into a clean, analysis-ready format.
Let's start by looking at how to aggregate data with pandas, which will help us understand our dataset's structure before cleaning it.
Lesson 1 – Data Aggregation
Before we start cleaning any dataset, we need to understand what we're working with. That's where data aggregation comes in―the process of summarizing data, whether by calculating simple statistics like means and medians or by grouping rows into meaningful categories. When I aggregated temperature readings in my weather prediction project, the high average values I got back revealed that some stations had recorded in Fahrenheit while others used Celsius. Finding these patterns helped me plan my cleaning strategy before getting into any kind of analysis.
To show you how to do this, let's work with some real data. We'll use the World Happiness Report dataset, which assigns happiness scores to countries based on poll results. This dataset is perfect for learning about aggregation because it includes various metrics like GDP per capita, family relationships, life expectancy, and freedom scores―all factors that contribute to overall happiness. While spreadsheet software can handle basic aggregations, you'll soon see why pandas provides more powerful and flexible tools for understanding your data's structure and potential issues.
Getting Started with Basic Aggregation
First, let's load the data and examine its structure:
import pandas as pd
happiness2015 = pd.read_csv('World_Happiness_2015.csv')
first_5 = happiness2015.head()
print(first_5)
happiness2015.info()Here's what the first five rows look like:
| Country | Region | Happiness Rank | Happiness Score | Standard Error | Economy (GDP per Capita) | Family | Health (Life Expectancy) | Freedom | Trust (Government Corruption) | Generosity | Dystopia Residual | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Switzerland | Western Europe | 1 | 7.587 | 0.03411 | 1.39651 | 1.34951 | 0.94143 | 0.66557 | 0.41978 | 0.29678 | 2.51738 |
| 1 | Iceland | Western Europe | 2 | 7.561 | 0.04884 | 1.30232 | 1.40223 | 0.94784 | 0.62877 | 0.14145 | 0.43630 | 2.70201 |
| 2 | Denmark | Western Europe | 3 | 7.527 | 0.03328 | 1.32548 | 1.36058 | 0.87464 | 0.64938 | 0.48357 | 0.34139 | 2.49204 |
| 3 | Norway | Western Europe | 4 | 7.522 | 0.03880 | 1.45900 | 1.33095 | 0.88521 | 0.66973 | 0.36503 | 0.34699 | 2.46531 |
| 4 | Canada | North America | 5 | 7.427 | 0.03553 | 1.32629 | 1.32261 | 0.90563 | 0.63297 | 0.32957 | 0.45811 | 2.45176 |
And here's what info() tells us about the dataset's structure:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 158 entries, 0 to 157
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Country 158 non-null object
1 Region 158 non-null object
2 Happiness Rank 158 non-null int64
3 Happiness Score 158 non-null float64
4 Standard Error 158 non-null float64
5 Economy (GDP per Capita) 158 non-null float64
6 Family 158 non-null float64
7 Health (Life Expectancy) 158 non-null float64
8 Freedom 158 non-null float64
9 Trust (Government Corruption) 158 non-null float64
10 Generosity 158 non-null float64
11 Dystopia Residual 158 non-null float64
dtypes: float64(9), int64(1), object(2)
memory usage: 14.9+ KBNow we can see the structure of our data clearly. The head() method shows us that we have countries and their happiness-related metrics, while info() reveals that we have 158 countries in total, with numerical columns like Happiness Score (stored as float64) and categorical ones like Region and Country (stored as object type).
Calculating Regional Happiness Scores
Looking at individual rows doesn't tell us much about overall patterns. Let's use aggregation to get a clearer picture by calculating summary statistics for different groups. For example, we might want to know the average happiness score for each region. Pandas makes this incredibly simple with its powerful groupby() DataFrame method. The diagram below shows a sample of what this method will do to our dataset:

grouped = happiness2015.groupby('Region')
happy_grouped = grouped['Happiness Score']
happy_mean = happy_grouped.mean()
print(happy_mean)This code produces the following output:
| Region | Happiness Score |
|---|---|
| Australia and New Zealand | 7.285000 |
| Central and Eastern Europe | 5.332931 |
| Eastern Asia | 5.626167 |
| Latin America and Caribbean | 6.144682 |
| Middle East and Northern Africa | 5.406900 |
| North America | 7.273000 |
| Southeastern Asia | 5.317444 |
| Southern Asia | 4.580857 |
| Sub-Saharan Africa | 4.202800 |
| Western Europe | 6.689619 |
Let's break down what this code does:
- First, we group our data by Region using
groupby() - Then, we select just the
'Happiness Score'column from our grouped data - Finally, we calculate the mean for each group using
mean()
Looking at the output, we can immediately spot some interesting patterns. Australia/New Zealand and North America show the highest average happiness scores (around 7.3), while Sub-Saharan Africa has the lowest (4.2). These kinds of patterns would be much harder to spot by looking at individual country data.
The beauty of pandas' groupby() method is how it simplifies complex aggregations into just a few lines of code. We can easily change the aggregation method (like using median() instead of
mean()) or group by different columns without writing lengthy loops.
Using Aggregation to Identify Data Issues
Looking at our regional happiness averages, you might notice something interesting: the data looks... surprisingly clean. All the values fall within reasonable ranges, and we don't see any obvious red flags. This is actually quite unusual! In my experience, real-world datasets rarely look this tidy on first inspection.
While we didn't find any glaring issues in our happiness data, aggregation often reveals problems that need cleaning. For example, you might spot:
- Outliers that skew group averages dramatically
- Inconsistent units between different data sources
- Missing values concentrated in specific groups
- Duplicate entries that inflate certain categories
Here are some practical tips for using aggregation to check your data quality:
- Try different grouping combinations to view your data from multiple angles
- Calculate various summary statistics (mean, median, min, max) for each group
- Use pandas' built-in methods instead of writing your own loops
- Document any patterns that seem unexpected or worth investigating
Now that we've confirmed our happiness data is relatively clean (lucky us!), let's move on to learning how to combine data from multiple sources. This is a common challenge when working with real-world datasets that come from different systems.
Lesson 2 – Combining Data Using Pandas
So far, we've explored the 2015 World Happiness Report data, but what if we want to analyze how happiness scores change over time? For that, we'll need data from multiple years. This is a common scenario in data analysis―the information you need often lives in different files or comes from different sources. As I mentioned earlier with my weather prediction project, I had to combine temperature, precipitation, and wind speed data from separate files to create a complete dataset.
Let's expand our analysis using data from three years of the World Happiness Report. You can download the datasets here:
First, let's load our data and add a year column to each dataset so we can track changes over time:
import pandas as pd
happiness2015 = pd.read_csv("World_Happiness_2015.csv")
happiness2016 = pd.read_csv('World_Happiness_2016.csv')
happiness2017 = pd.read_csv('World_Happiness_2017.csv')
happiness2015['Year'] = 2015
happiness2016['Year'] = 2016
happiness2017['Year'] = 2017Pandas offers two distinct methods for combining datasets: concat() and merge(). Each serves a different purpose, so let's explore when and how to use each one.
Combining Data with pd.concat()
The concat() function is perfect when you want to simply stack datasets together. It works in two directions: vertically (stacking one dataset below another) or horizontally (placing datasets side by side). Let's look at a simple example using just three countries from each year:
head_2015 = happiness2015[['Country','Happiness Score', 'Year']].head(3)
head_2016 = happiness2016[['Country','Happiness Score', 'Year']].head(3)
# Vertical stacking (like adding more rows)
concat_axis0 = pd.concat([head_2015, head_2016], axis=0)
print(concat_axis0)
# Horizontal stacking (like adding more columns)
concat_axis1 = pd.concat([head_2015, head_2016], axis=1)
print(concat_axis1)When we stack vertically (axis=0), we get:
| Country | Happiness Score | Year | |
|---|---|---|---|
| 0 | Switzerland | 7.587 | 2015 |
| 1 | Iceland | 7.561 | 2015 |
| 2 | Denmark | 7.527 | 2015 |
| 0 | Denmark | 7.526 | 2016 |
And when we stack horizontally (axis=1):
| Country | Happiness Score | Year | Country | Happiness Score | Year | |
|---|---|---|---|---|---|---|
| 0 | Switzerland | 7.587 | 2015 | Denmark | 7.526 | 2016 |
| 1 | Iceland | 7.561 | 2015 | Switzerland | 7.509 | 2016 |
| 2 | Denmark | 7.527 | 2015 | Iceland | 7.501 | 2016 |

Using pd.merge() for Matching Records
When we need to combine data based on matching values rather than position, pd.merge() is the better choice. Let's see how it works with a few countries:
three_2015 = happiness2015[['Country','Happiness Rank','Year']].iloc[2:5]
three_2016 = happiness2016[['Country','Happiness Rank','Year']].iloc[2:5]
merged = pd.merge(left=three_2015, right=three_2016, on='Country', suffixes=('_2015','_2016'))Our input data from 2015:
| Country | Happiness Rank | Year | |
|---|---|---|---|
| 2 | Denmark | 3 | 2015 |
| 3 | Norway | 4 | 2015 |
| 4 | Canada | 5 | 2015 |
And from 2016:
| Country | Happiness Rank | Year | |
|---|---|---|---|
| 2 | Iceland | 3 | 2016 |
| 3 | Norway | 4 | 2016 |
| 4 | Finland | 5 | 2016 |
After merging:
| Country | Happiness Rank_2015 | Year_2015 | Happiness Rank_2016 | Year_2016 | |
|---|---|---|---|---|---|
| 0 | Norway | 4 | 2015 | 4 | 2016 |

Notice how pd.merge() only kept Norway in the result―it was the only country present in both datasets. This behavior is similar to an inner join in SQL, keeping only the records that match in both datasets. This is exactly what we want when tracking changes over time for specific countries.
Choosing the Right Combination Method
After seeing both methods in action, let's summarize when to use each:
Use pd.concat() when:
- You want to add new rows (axis=0) or columns (axis=1) based on position
- Your datasets share the same structure (like combining happiness data from different years)
- You don't need to match records based on specific values
Use pd.merge() when:
- You need to combine data based on matching values (like country names)
- You want control over how unmatched records are handled
- Your datasets have different structures but share some common columns
Validating Combined Data
Before moving forward with analysis, always validate your combined data by checking:
- Row counts: Did you lose or gain the expected number of records?
- Column names: Are there duplicate columns or unexpected suffixes?
- Sample records: Do the combinations make sense for your analysis?
- Missing values: Did the combination create any unexpected gaps?
For example, in our merge result above, we went from six total records to just one. This dramatic reduction makes sense because we were looking for exact country matches between years, but it's the kind of change you'd want to verify is intentional for your analysis. I learned this lesson the hard way in my weather project―when merging data from different weather stations, I initially lost several readings because station names weren't formatted consistently (like "Station A" vs "Station-A"). A quick validation check helped me catch and fix these matching issues before they affected my analysis.
Now that we understand how to combine our happiness data across different years, let's look at how to transform it into consistent formats for analysis. In the next lesson, we'll explore pandas' powerful transformation methods that help standardize data from multiple sources.
Lesson 3 – Transforming Data with Pandas
Once you've gathered and combined your data, the next step is transforming it into a consistent, usable format. Transformations allow you to reshape, standardize, and enrich your dataset, ensuring everything lines up for analysis. When working on my weather prediction project, I had to align different metrics and units across multiple sources, which made the trends and patterns I observed trustworthy. Transforming data with pandas is an essential skill that will let you trust the insights you uncover hidden within messy, raw data.
Continuing with our 2015 World Happiness Report data, let's explore how to transform our data into more meaningful formats. Pandas provides several methods for this: Series.map(), Series.apply(), and DataFrame.map(). Each has its strengths, and knowing when to use each one will make your data transformations more efficient.
Simple Transformations with Series.map()
Let's start by categorizing countries' economic impact on happiness as either 'High' or 'Low'. Here's what our 'Economy' data looks like initially:
| Country | Economy | |
|---|---|---|
| 0 | Switzerland | 1.39651 |
| 1 | Iceland | 1.30232 |
| 2 | Denmark | 1.32548 |
| 3 | Norway | 1.45900 |
| 4 | Canada | 1.32629 |
We can transform these numerical values into categories using Series.map():
def label(element):
if element > 1:
return 'High'
else:
return 'Low'
happiness2015['Economy Impact'] = happiness2015['Economy'].map(label)Here's our result:
| Country | Economy | Economy Impact | |
|---|---|---|---|
| 0 | Switzerland | 1.39651 | High |
| 1 | Iceland | 1.30232 | High |
| 2 | Denmark | 1.32548 | High |
| 3 | Norway | 1.45900 | High |
| 4 | Canada | 1.32629 | High |
Notice that we created a new column instead of modifying the original 'Economy' column. This is a good practice as it preserves our original data for reference.
Using Series.apply() for More Flexibility
While map() works well for simple transformations, it has limitations. Like, what if we want to make our threshold flexible?
def label(element, x):
if element > x:
return 'High'
else:
return 'Low'
# This will raise an error:
# happiness2015['Economy'].map(label, x=0.8)
# But this works:
happiness2015['Economy'].apply(label, x=0.8)Working with Multiple Columns
Let's say we want to apply our labeling function to several happiness factors. We could do it column by column:
happiness2015['Economy Impact'] = happiness2015['Economy'].apply(label, x=0.8)
happiness2015['Health Impact'] = happiness2015['Health'].apply(label, x=0.8)
happiness2015['Family Impact'] = happiness2015['Family'].apply(label, x=0.8)But pandas offers a more efficient approach using DataFrame.map(). Let's calculate how each factor contributes to the total happiness score as a percentage:
# Define the factors we want to analyze
factors = ['Economy', 'Family', 'Health', 'Freedom', 'Trust', 'Generosity']
def percentages(col):
div = col / happiness2015['Happiness Score']
return div * 100
factor_percentages = happiness2015[factors].apply(percentages)This produces:
| Economy | Family | Health | Freedom | Trust | Generosity | |
|---|---|---|---|---|---|---|
| 0 | 18.41 | 17.79 | 12.41 | 8.77 | 5.53 | 3.91 |
| 1 | 17.22 | 18.55 | 12.54 | 8.32 | 1.87 | 5.77 |
| 2 | 17.61 | 18.08 | 11.62 | 8.63 | 6.42 | 4.54 |
| 3 | 19.40 | 17.69 | 11.77 | 8.90 | 4.85 | 4.61 |
| 4 | 17.86 | 17.81 | 12.19 | 8.52 | 4.44 | 6.17 |
Choosing the Right Method
Here's when to use each transformation method:
Use Series.map() when:
- You need a simple transformation on a single column
- Your function doesn't require additional arguments
- You want the clearest, most straightforward code
Use Series.apply() when:
- Your function needs additional arguments
- You want to apply more complex logic to each element
- You need more flexibility in your transformation
Use DataFrame.map() when:
- You need to transform multiple columns at once
- You want to avoid repetitive code
- Your transformation logic is consistent across columns
A quick note: In older versions of pandas (prior to 2.1.0), you might see DataFrame.applymap() used for element-wise operations. This method has been deprecated in favor of DataFrame.map(), which we used above.
Just as these methods helped standardize our happiness data, they're equally valuable for other data cleaning tasks. As mentioned earlier with the temperature units in my weather project, having the right transformation method can make standardizing data much more efficient!
In the next lesson, we'll explore how to work with text data in pandas, which presents its own unique challenges and opportunities for cleaning and standardization.
Lesson 4 – Working with Strings in Pandas
Real-world data isn’t always neatly formatted; you’ll often encounter messy strings with inconsistent capitalization, unexpected characters, or even extra spaces. Cleaning and standardizing string data is necessary for analysis and is especially common when working with text-heavy datasets, like survey responses or social media data. In my weather project, I dealt with varying formats for city names and station codes, which I had to standardized before any analysis. Learning to manipulate strings in pandas is a powerful skill that will help you prepare data for accurate, meaningful insights.
For this lesson, we'll combine our 2015 World Happiness Report data with a dataset of economic information from the World Bank. First, let's prepare our data:
world_dev = pd.read_csv("World_dev.csv")
col_renaming = {'SourceOfMostRecentIncomeAndExpenditureData': 'IESurvey'}
# Merge datasets and rename the long column name
merged = pd.merge(left=happiness2015, right=world_dev, how='left',
left_on='Country', right_on='ShortName')
merged = merged.rename(col_renaming, axis=1)Working with text data often requires cleaning and standardization. Just as we needed to standardize country names to merge our datasets, we'll often find other text fields that need similar treatment. Let's explore pandas' string processing capabilities using the currency information from our merged dataset.
Let's look at how currencies are recorded in our dataset:
| Country | CurrencyUnit |
|---|---|
| Switzerland | Swiss franc |
| Iceland | Iceland krona |
| Denmark | Danish krone |
| Norway | Norwegian krone |
| Canada | Canadian dollar |
| Finland | Euro |
| Netherlands | Euro |
| Sweden | Swedish krona |
| New Zealand | New Zealand dollar |
| Australia | Australian dollar |
Comparing String Processing Methods
To analyze currency patterns, we first need to extract just the currency type (franc, krona, dollar, etc.) from the full currency unit. Pandas offers two approaches for this task. First, let's try using the apply() method:
def extract_last_word(element):
return str(element).split()[-1]
merged['Currency Apply'] = merged['CurrencyUnit'].apply(extract_last_word)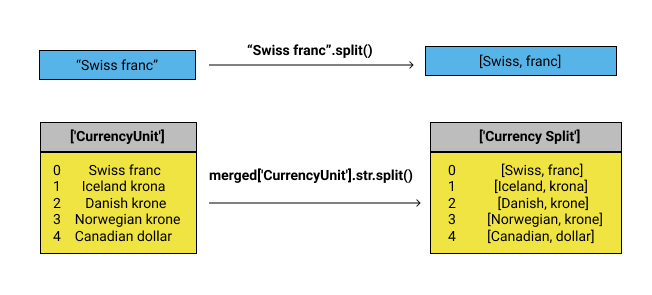
While this works, pandas provides a more elegant solution using vectorized string operations:
merged['Currency Vectorized'] = merged['CurrencyUnit'].str.split().str.get(-1)Both approaches produce the same result:
| Country | CurrencyUnit | Currency Apply | Currency Vectorized |
|---|---|---|---|
| Switzerland | Swiss franc | franc | franc |
| Iceland | Iceland krona | krona | krona |
| Denmark | Danish krone | krone | krone |
| Norway | Norwegian krone | krone | krone |
| Canada | Canadian dollar | dollar | dollar |
Leveraging Vectorized String Operations
The vectorized approach using pandas' .str accessor isn't just more concise—it's also faster because it operates on the entire Series at once rather than element by element. The .str accessor provides many useful operations:
.str.split(): Divides strings into lists (as we did above).str.get(): Retrieves elements from lists.str.replace(): Substitutes text patterns.str.contains(): Finds specific strings or patterns.str.extract(): Pulls out matching patterns
Looking at all unique currency types in our dataset reveals the complexity of real-world text data:
['franc' 'krona' 'krone' 'dollar' 'Euro' 'shekel' 'colon' 'peso' 'real'
'dirham' 'sterling' 'Omani' 'fuerte' 'balboa' 'riyal' 'koruna' 'baht' nan
'dinar' 'quetzal' 'sum' 'yen' 'Boliviano' 'leu' 'guarani' 'tenge'
'cordoba' 'sol' 'rubel' 'zloty' 'ringgit' 'kuna' 'ruble' 'manat' 'rupee'
'rupiah' 'dong' 'lira' 'naira' 'ngultrum' 'yuan' 'kwacha' 'denar'
'metical' 'lek' 'mark' 'loti' 'tugrik' 'lilangeni' 'pound' 'forint'
'lempira' 'somoni' 'taka' 'rial' 'hryvnia' 'rand' 'cedi' 'gourde' 'birr'
'leone' 'ouguiya' 'shilling' 'dram' 'pula' 'kyat' 'lari' 'lev' 'kwanza'
'riel' 'ariary' 'afghani']Best Practices for String Cleaning
When working with text data, follow these guidelines:
- Start with a small sample to test your approach (as we did with the first few currencies)
- Use vectorized methods for better performance and cleaner code
- Chain operations together for complex transformations
- Keep track of changes to ensure transformations work as expected
- Document your standardization decisions (especially important with currency names, which might have multiple valid forms)
In the next lesson, we'll explore how to handle missing and duplicate values—notice how our currency data included some 'nan' values, a common challenge when working with real-world datasets.
Lesson 5 – Working With Missing and Duplicate Data
Real-world datasets are rarely perfect. They often contain missing values, duplicates, and inconsistencies that can significantly impact your analysis. I learned this the hard way in my weather prediction project when missing temperature readings led to incorrect forecasts. Let's explore how to identify and handle these issues effectively.
For this lesson, we'll work with modified versions of the World Happiness Report data:
Before we can combine these datasets, we need to standardize their column names. Let's look at our 2015 dataset's columns:
print(happiness2015.columns.tolist())['Country', 'Region', 'Happiness Rank', 'Happiness Score', 'Standard Error', 'Economy (GDP per Capita)', 'Family', 'Health (Life Expectancy)', 'Freedom', 'Trust (Government Corruption)', 'Generosity', 'Dystopia Residual', 'Year']Notice the inconsistent formatting: parentheses, spaces, and mixed capitalization. Let's clean these up:
happiness2015.columns = happiness2015.columns.str.replace('(', '').str.replace(')', '').str.strip().str.upper()
print(happiness2015.columns.tolist())['COUNTRY', 'REGION', 'HAPPINESS RANK', 'HAPPINESS SCORE', 'STANDARD ERROR', 'ECONOMY GDP PER CAPITA', 'FAMILY', 'HEALTH LIFE EXPECTANCY', 'FREEDOM', 'TRUST GOVERNMENT CORRUPTION', 'GENEROSITY', 'DYSTOPIA RESIDUAL', 'YEAR']After cleaning the column names for all three datasets, we can combine them:
# Clean column names across all datasets
happiness2015.columns = happiness2015.columns.str.replace('(', '').str.replace(')', '').str.strip().str.upper()
happiness2016.columns = happiness2016.columns.str.replace('(', '').str.replace(')', '').str.strip().str.upper()
happiness2017.columns = happiness2017.columns.str.replace('.', ' ').str.replace('s+', ' ', regex=True).str.strip().str.upper()
# Combine datasets
combined = pd.concat([happiness2015, happiness2016, happiness2017], ignore_index=True)Identifying Missing Values
Let's see how many missing values we have in each column:
print("Number of non-null values in each column:")
print(combined.notnull().sum().sort_values())Number of non-null values in each column:
WHISKER LOW 155
WHISKER HIGH 155
UPPER CONFIDENCE INTERVAL 157
LOWER CONFIDENCE INTERVAL 157
STANDARD ERROR 158
HAPPINESS RANK 470
HAPPINESS SCORE 470
ECONOMY GDP PER CAPITA 470
GENEROSITY 470
FREEDOM 470
FAMILY 470
HEALTH LIFE EXPECTANCY 470
TRUST GOVERNMENT CORRUPTION 470
DYSTOPIA RESIDUAL 470
COUNTRY 492
YEAR 492
REGION 492
dtype: int64We can visualize these patterns using a heatmap:
import seaborn as sns
combined_updated = combined.set_index('YEAR')
sns.heatmap(combined_updated.isnull(), cbar=False)
plt.show()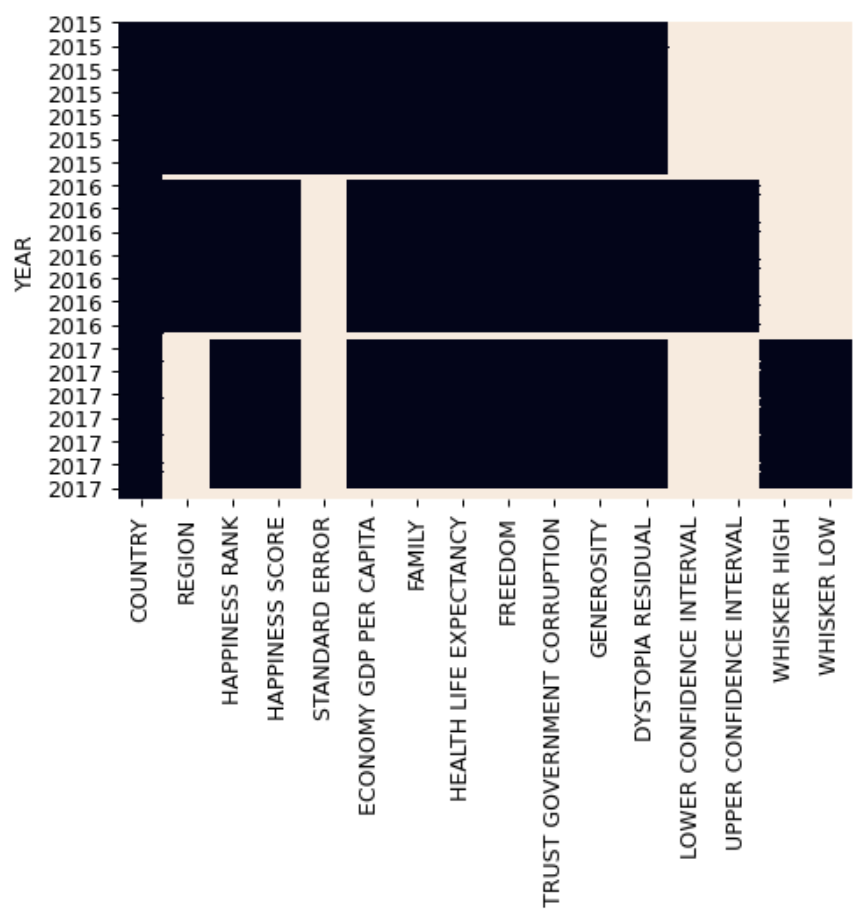
The heatmap reveals:
- some columns are completely missing for certain years (lighter regions)
- some rows (countries) are missing data across most columns
- only the
COUNTRYcolumn has complete data across all years (dark region)
Let's see what happens if we try to drop all rows with any missing values:
cleaned = combined.dropna()
print(f"Rows before: {len(combined)}")
print(f"Rows after: {len(cleaned)}")
print(f"Percentage of data lost: {((len(combined) - len(cleaned))/len(combined) * 100):.1f}%")Rows before: 492
Rows after: 0
Percentage of data lost: 100.0%Well that clearly won't work! Let's be more strategic. First, we should understand which columns are most important for our analysis. Looking at the non-null counts above, we can see that some columns like 'WHISKER LOW' and 'UPPER CONFIDENCE INTERVAL' have far more missing values than core columns like 'HAPPINESS SCORE'.
Instead of dropping rows, let's try dropping columns that have too many missing values:
# Drop columns with more than 330 missing values (keeping columns present in at least 2 years of data)
print(f"Columns before: {len(combined.columns)}")
combined = combined.dropna(thresh=159, axis=1)
print(f"Columns after: {len(combined.columns)}")
print("nRemaining columns:")
print(combined.columns.tolist())Columns before: 17
Columns after: 12
Remaining columns:
['COUNTRY', 'HAPPINESS RANK', 'HAPPINESS SCORE', 'ECONOMY GDP PER CAPITA', 'FAMILY', 'HEALTH LIFE EXPECTANCY', 'FREEDOM', 'TRUST GOVERNMENT CORRUPTION', 'GENEROSITY', 'DYSTOPIA RESIDUAL', 'YEAR', 'REGION']Why did we choose 159 as our threshold? Looking at our table of non-null values above, we can see that the five statistical columns ('WHISKER HIGH', 'WHISKER LOW', 'UPPER CONFIDENCE INTERVAL', 'LOWER CONFIDENCE INTERVAL', and 'STANDARD ERROR') have the fewest non-null values, maxing out at 158 rows. By choosing 159 as our threshold, dropna will remove these five columns which won't help with our analysis anyway.
Now we can try dropping rows with missing values again:
# Now drop rows with missing values
rows_before = len(combined)
combined = combined.dropna()
print(f"Rows before: {rows_before}")
print(f"Rows after: {len(combined)}")
print(f"Percentage of data lost: {((rows_before - len(combined))/rows_before * 100):.1f}%")Rows before: 492
Rows after: 470
Percentage of data lost: 4.5%This is much more reasonable! We've kept the core happiness metrics while removing rows and columns that would make year-over-year comparison difficult.
Managing Duplicates
After handling missing values, we should check for duplicate entries. In our dataset, duplicates might occur when a country appears multiple times in the same year. We can identify duplicates using the duplicated() method:
dups = combined.duplicated(['COUNTRY', 'YEAR'])
print(f"Number of duplicates: {dups.sum()}")
print(combined[dups][['COUNTRY', 'REGION', 'HAPPINESS RANK', 'HAPPINESS SCORE', 'YEAR']])Number of duplicates: 3| COUNTRY | REGION | HAPPINESS RANK | HAPPINESS SCORE | YEAR | |
|---|---|---|---|---|---|
| 162 | SOMALILAND REGION | Sub-Saharan Africa | NaN | NaN | 2015 |
| 326 | SOMALILAND REGION | Sub-Saharan Africa | NaN | NaN | 2016 |
| 489 | SOMALILAND REGION | Sub-Saharan Africa | NaN | NaN | 2017 |
The duplicated() method identifies rows that have matching values in specified columns. In this case, we're checking for countries that appear multiple times in the same year. To remove these duplicates, we can use the drop_duplicates() method:
combined = combined.drop_duplicates(['COUNTRY', 'YEAR'])Best Practices for Handling Missing and Duplicate Data
Through my experience with both the happiness data and my weather prediction project, I've developed these guidelines for handling data quality issues:
- Always examine your data before cleaning:
- Check for missing values in each column
- Look for duplicate entries
- Visualize patterns (like we did with the heatmap)
- Be strategic about handling missing values:
- Consider why the data might be missing
- Decide whether to drop or fill based on your analysis needs
- Document your rationale for each decision
- When removing data:
- Keep your original dataset intact
- Create copies for cleaning
- Track how much data you're removing and why
- Validate your cleaning steps:
- Check summary statistics before and after cleaning
- Look for unexpected changes in your data
- Verify that relationships between variables remain sensible
In the final section of this tutorial, we'll put all these techniques into practice with a guided project analyzing employee exit surveys. You'll see how these methods help prepare real HR data for analysis, from standardizing response formats to handling missing answers in survey responses.
Guided Project: Clean and Analyze Employee Exit Surveys
Let's put our data cleaning skills to work by analyzing exit surveys from employees of the Department of Education, Training and Employment (DETE) and the Technical and Further Education (TAFE) institute in Queensland, Australia.
Loading and Exploring the Data
First, let's load our datasets:
dete_survey = pd.read_csv('dete_survey.csv')
tafe_survey = pd.read_csv('tafe_survey.csv')
print("DETE Survey shape:", dete_survey.shape)
print("nTAFE Survey shape:", tafe_survey.shape)Just like our happiness data earlier, these datasets have different column names for similar information. For example, both track how long employees worked at the institutes, but use different column names and formats for this information.
Cleaning the Data
Let's standardize how we record employee dissatisfaction across both datasets:
def update_vals(val):
if pd.isnull(val):
return np.nan
elif val == '-':
return False
else:
return True
# Apply our standardization function
combined_updated['dissatisfied'] = combined_updated['dissatisfied'].map(update_vals)This transformation gives us consistent True/False values, making it easier to analyze patterns in employee satisfaction.
Analyzing the Data
Let's examine the relationship between years of service and employee dissatisfaction:
# Check the distribution of dissatisfaction
combined_updated['dissatisfied'].value_counts(dropna=False)
# Replace missing values with the most common response (False)
combined_updated['dissatisfied'] = combined_updated['dissatisfied'].fillna(False)
# Calculate dissatisfaction percentage by service category
dis_pct = combined_updated.pivot_table(index='service_cat',
values='dissatisfied')The results show some interesting patterns:
- 403 employees (62%) left for reasons unrelated to dissatisfaction
- 240 employees (37%) indicated dissatisfaction as a factor
- 8 responses had missing values
Visualizing the Results
To better understand these patterns, we can create a bar plot showing dissatisfaction rates by years of service. This visualization reveals that mid-career employees (3-6 years of service) tend to report higher dissatisfaction rates than both newer and more senior employees.
Drawing Insights
This analysis raises important questions for HR professionals:
- Why do mid-career employees show higher dissatisfaction rates?
- Are there specific departments or roles with higher turnover?
- How might the institute better support employee development during critical career stages?
Remember, the goal isn't just to clean and analyze data—it's to uncover insights that can help organizations improve employee satisfaction and retention. What story does this data tell about employee experience? How might these insights inform HR policies and practices?
Advice from a Python Expert
When I think back to my early data cleaning projects, like that weather prediction challenge I mentioned, I remember feeling lost in my messy data. But each challenge taught me something valuable. Those temperature unit inconsistencies? They taught me to always check my assumptions. The varying text formats? They showed me the importance of standardization before analysis.
Throughout this tutorial, we've worked with real-world data that reflects the kinds of challenges you'll face in your own projects. From standardizing happiness scores across different years to handling missing employee survey responses, we've seen how pandas can transform messy data into valuable insights.
Here's what I've learned about effective data cleaning:
- Start with exploration, not cleaning. Understanding your data's quirks first will help you make better cleaning decisions later.
- Document everything. Write down your cleaning steps and rationale—you'll thank yourself later when you need to explain or repeat your process.
- Keep your original data intact. Create copies for cleaning so you can always start fresh if needed.
- Test your assumptions. As we saw with the employee survey data, what looks like a duplicate or missing value might tell an important story.
If you're feeling uncertain about how to deal with data cleaning, remember that every analyst starts somewhere. Begin with small datasets where you can easily verify your results. Practice regularly with different types of data—each challenge will build your confidence and skills.
Ready to tackle more data cleaning challenges? The Data Cleaning and Analysis in Python course offers hands-on practice with real-world datasets. And don't forget to join the Dataquest Community, where you can share your work and learn from others facing similar challenges.
Remember, clean data is the foundation of good analysis. Take your time, be systematic, and don't be afraid to try different approaches. With practice and patience, you'll develop an intuition for handling even the messiest datasets.
Frequently Asked Questions
What are the five main steps in data cleaning in Python using pandas?
When working with data in Python using pandas, it's essential to follow a systematic approach to transform messy datasets into analysis-ready information. Based on my experience with various datasets, including international survey data, I've found that breaking down the process into manageable steps is particularly effective.
Here are the five main steps for cleaning data in Python:
- Standardize your data structure: Start by ensuring consistency in your data format. This includes cleaning up column names by removing special characters and standardizing case. For example:
df.columns = df.columns.str.replace('(', '').str.replace(')', '').str.strip().str.upper() - Combine multiple data sources: Use pandas'
concat()function for stacking similar datasets ormerge()for joining on common columns. Chooseconcat()when working with datasets that share the same structure, andmerge()when you need to combine data based on matching values in specific columns. - Handle missing values: First, assess patterns in missing data using
df.notnull().sum(). Then decide whether to drop or fill missing values based on your analysis requirements. Sometimes dropping columns with too many missing values (usingdropna(thresh=threshold)) is more effective than removing rows. - Remove duplicate entries: Use
drop_duplicates()to eliminate redundant data, especially when combining datasets from different sources. Always specify the columns to check for duplicates:df = df.drop_duplicates(['COUNTRY', 'YEAR']) - Transform data types and formats: Use pandas' string methods and
apply()functions to standardize data formats and create consistent categories across your dataset. This ensures your data is ready for analysis and helps prevent errors in calculations.
By following these steps, you'll be able to create a robust foundation for analysis. I recommend validating your results after each step and keeping the original data intact while cleaning. This methodical approach has helped me handle everything from weather data with inconsistent temperature units to survey responses with varying text formats.
How do you use pandas' groupby() method for data aggregation?
groupby() method for data aggregation?The pandas groupby() method is a useful way to organize and analyze data by categories. It splits your data into groups, allows you to perform calculations on each group, and then combines the results. This makes it a helpful tool for identifying patterns and potential issues during data cleaning.
For example, let's say you want to analyze regional patterns in a dataset. You can use groupby() to group your data by region, and then calculate the mean happiness score for each region.
grouped = happiness2015.groupby('Region')
happy_grouped = grouped['Happiness Score']
happy_mean = happy_grouped.mean()
This code reveals clear patterns in the data, showing significant variations across regions (from 7.285 in Australia/New Zealand to 4.202 in Sub-Saharan Africa). These patterns can help you identify potential data quality issues or outliers that need investigation during the cleaning process.
To get the most out of groupby() for data cleaning, follow these steps:
- When selecting columns to group by, choose ones that could reveal data inconsistencies. For instance, you might group financial data by department or customer data by region.
- Once you've grouped your data, apply multiple aggregations (such as mean, count, min, and max) to spot outliers. This can help you identify potential data entry errors or inconsistent units between groups.
- Comparing group statistics can also help you identify unexpected patterns. For example, you might notice that one region has a significantly higher or lower mean happiness score than others.
groupby() in this way, you can more effectively identify and address data quality issues while gaining valuable insights into your dataset's structure and patterns.
What is the difference between pandas concat() and merge() functions?
concat() and merge() functions?When working with pandas, you'll often need to combine datasets. While both concat() and merge() functions serve this purpose, they work in distinct ways.
The concat() function is ideal for stacking similar datasets together, either vertically (adding rows) or horizontally (adding columns). This works best when your datasets share the same structure, such as combining multiple years of survey data. For example:
concat_axis0 = pd.concat([head_2015, head_2016], axis=0) # Vertical stacking
concat_axis1 = pd.concat([happiness_2015, happiness_2016], axis=1) # Horizontal stacking
On the other hand, the merge() function combines datasets based on matching values in specific columns, similar to SQL joins. This is useful when you need to combine data that shares common identifiers, such as customer IDs or country names:
merged = pd.merge(
left=three_2015,
right=three_2016,
on='Country',
suffixes=('_2015','_2016')
)
So, when should you use each function? Choose concat() when:
- You're adding new rows or columns based on position.
- Your datasets share the same structure.
- You're combining time-series data from different periods.
Use merge() when:
- You're combining data based on matching values (like IDs or names).
- You need control over how unmatched records are handled.
- Your datasets have different structures but share common columns.
In data cleaning, these functions help you combine information from multiple sources while maintaining data integrity. For instance, use
concat() to combine yearly survey responses, or merge() to add demographic information to customer data based on shared identifiers.
How do you handle missing values in pandas DataFrames?
When working with pandas DataFrames, you'll often encounter missing values. These can be a challenge in data cleaning, but there are ways to identify and handle them effectively.
To start, you can use the notnull() method combined with sum() to identify columns with missing values:
df.notnull().sum().sort_values()
This will show you the count of non-null values in each column, helping you pinpoint where missing data occurs.
So, how do you handle missing values? Here are a few strategies:
- Drop columns with too many missing values: If a column has too many missing values, it may not be useful for your analysis. You can drop these columns using the
dropna()method:df = df.dropna(thresh=threshold, axis=1) - Drop rows with missing values: If a row has missing values, you can drop it entirely. However, be cautious when doing so, as you may lose valuable data:
df = df.dropna() - Fill missing values with replacements: You can also fill missing values with suitable replacements, such as means or medians. For instance, to fill missing values in a numerical column with the column's mean:
df['column_name'] = df['column_name'].fillna(df['column_name'].mean())
When deciding how to handle missing values, consider the following factors:
- The proportion of missing data in each column
- The importance of affected columns for your analysis
- Whether missing values follow any patterns
- The potential impact on your analysis results
Before making any changes, it's essential to validate your approach. Check how much data you'll lose by dropping rows or columns:
rows_before = len(df)
df_cleaned = df.dropna()
percent_lost = ((rows_before - len(df_cleaned)) / rows_before * 100)
Ultimately, the key is to strike a balance between maintaining data integrity and maximizing useful information for your analysis. If a column is missing more than 50% of its values, it may be best to drop it. However, if only a few rows have missing values in critical columns, removing those specific rows might be a better approach. By being strategic, you can ensure that your data is clean and reliable.
What are the best methods for standardizing text data in pandas?
When working with text data in pandas, standardization is an important part of data cleaning. It helps ensure consistency across your dataset, making it easier to analyze and work with. Pandas provides powerful string methods through the .str accessor, making text standardization efficient and systematic.
To standardize text data, you can use pandas' vectorized string operations like .str.replace(), .str.strip(), and
.str.upper(). For example, to clean messy column names containing special characters and inconsistent formatting:
df.columns = df.columns.str.replace('(', '').str.replace(')', '').str.strip().str.upper()
This approach is more efficient than processing each string individually because it operates on the entire Series at once. This makes it ideal for cleaning large datasets. The .str accessor provides several essential operations for text standardization:
.str.split()- Divides strings into lists.str.get()- Retrieves elements from lists.str.replace()- Substitutes text patterns.str.contains()- Finds specific strings or patterns.str.extract()- Pulls out matching patterns
So, how can you standardize text data effectively? Here are some best practices to keep in mind:
- Start small - Test your approach on a small data sample before applying it to your entire dataset.
- Use vectorized methods - They're faster and more efficient than processing each string individually.
- Chain operations together - This makes it easier to perform complex transformations.
- Keep track of changes - This ensures that your transformations work as expected.
- Document your decisions - This helps you and others understand your standardization process.
By following these best practices and using pandas string methods effectively, you can transform messy text data into clean, consistent formats. This is especially useful when dealing with real-world data challenges like inconsistent survey responses or mismatched country names. With clean data, you can perform accurate analysis and gain reliable insights.
How can you identify and remove duplicate entries using pandas?
When working with data in Python, it's common to encounter duplicate entries. Fortunately, pandas provides straightforward methods to handle these duplicates effectively.
To identify duplicates, you can use the duplicated() method, specifying the columns that determine uniqueness. For example:
df.duplicated(['COUNTRY', 'YEAR']).sum()
This code tells you exactly how many duplicate entries exist based on your specified criteria.
To remove duplicates, you can use the drop_duplicates() method:
df = df.drop_duplicates(['COUNTRY', 'YEAR'])
When handling duplicates, it's essential to follow a few key steps:
- Examine your data to understand what constitutes a duplicate.
- Before removing duplicates, verify that they don't contain valuable information.
- Keep track of how many records you're removing.
- Document your cleaning decisions.
- Maintain a copy of your original dataset.
It's also important to note that what appears to be a duplicate might not always be unnecessary data. For instance, in survey responses, duplicate entries might represent follow-up interviews or updated information. After removing duplicates, always validate your data to ensure you haven't lost important insights.
By following these steps and maintaining careful documentation, you can ensure that your data cleaning process effectively handles duplicates while preserving the integrity of your dataset.
What visualization techniques help identify data quality issues?
Visualizing data quality issues can help you spot patterns and problems that might be hard to see in raw numbers. One technique that I've found particularly helpful is using heatmaps to identify missing values and potential data quality concerns.
When working with large datasets, I often start by creating a simple heatmap visualization:
import seaborn as sns
sns.heatmap(df.isnull(), cbar=False)
plt.show()
This type of visualization can immediately show you:
- Which columns are missing data for specific time periods
- Whether missing values follow systematic patterns
- The overall completeness of your dataset
- Potential issues with data collection or recording
To get a more complete picture of data quality, it's a good idea to use multiple visualization techniques. For example:
- Bar charts can help you quantify missing values across different categories
- Line plots can reveal temporal patterns in data completeness
- Scatter plots can expose outliers and unusual relationships
- Box plots can help you identify potential data entry errors or inconsistent units
When cleaning data in Python, I recommend creating these visualizations at each major step. This can help you validate your cleaning decisions and ensure that you haven't introduced new issues. For instance, after removing rows with missing values, a quick visualization can confirm whether you've maintained representative data across all categories.
The key is to use visualizations strategically throughout your data cleaning process. By doing so, you can not only identify problems but also guide your cleaning decisions and verify your results. I've often discovered subtle data quality issues through visualization that I missed when looking at numerical summaries alone.
How do you use pandas .str accessor for text data cleaning?
.str accessor for text data cleaning?When working with text data in Python, cleaning and standardizing the data is an essential step in preparing it for analysis. One powerful tool for this task is the pandas .str accessor. This feature provides vectorized string operations that can efficiently clean and transform entire columns of text data at once.
So, what can you do with the .str accessor? Here are some key string operations available:
.str.split()- Divide strings into lists.str.get()- Retrieve elements from lists.str.replace()- Substitute text patterns.str.contains()- Find specific strings or patterns.str.extract()- Pull out matching patterns
For example, let's say you have a dataset with messy column names that need standardization. You can chain multiple string operations together to clean up the names:
df.columns = df.columns.str.replace('(', '').str.replace(')', '').str.strip().str.upper()
This code transforms the messy column names into clean, standardized formats―a common requirement when preparing data for analysis.
One of the benefits of using the .str accessor is its efficiency. By operating on the entire Series at once, it can handle large datasets with thousands of text entries much faster than processing strings individually.
To get the most out of the .str accessor, follow these best practices:
- Test your string operations on a small sample first to verify the results
- Use vectorized methods instead of loops for better performance
- Chain related operations together to keep code clean and readable
- Document your text standardization rules for consistency
- Maintain a record of transformations applied to your text data
By using the .str accessor effectively, you can tackle common text cleaning challenges like standardizing categories, removing special characters, or extracting specific patterns from strings. With a little practice, you'll be able to handle even the messiest text data with ease.
What are effective ways to validate data cleaning results?
When validating data cleaning results, it's essential to follow a systematic approach to ensure your transformations worked as intended. A well-planned validation process helps you catch issues early and ensures your cleaned data provides a reliable foundation for analysis.
Here are effective validation methods to consider:
- Compare Dataset Properties:
- Use pandas'
info()method to check column types and non-null counts. - Compare value distributions before and after cleaning to verify that your transformations didn't introduce any unexpected changes.
- Verify that unique values make sense for each variable.
- Use pandas'
- Visualize Data Quality:
- Create heatmaps to identify patterns in missing values and detect any unexpected changes.
- Plot distributions to catch changes in your data that might affect your analysis.
- Use correlation matrices to verify relationships between variables.
- Track Data Loss:
- Calculate the percentage of rows and columns removed to understand the impact of your cleaning process.
- Document why specific data was eliminated to ensure transparency and reproducibility.
- Verify that remaining data is representative of your population.
- Validate Transformations:
- Check that standardized formats are consistent to ensure accuracy.
- Verify that merged datasets combined correctly to avoid any errors.
- Ensure categorical variables contain expected values to maintain data integrity.
For example, when cleaning survey data, you might track that removing rows with missing values reduced your dataset by 10%, then verify this reduction doesn't disproportionately affect certain groups. Similarly, after standardizing text responses, you'd confirm all variations were properly captured in your final categories.
Common validation challenges include detecting subtle changes in relationships between variables, identifying unintended consequences of cleaning steps, and balancing data quality with data preservation.
To ensure robust validation:
- Keep detailed logs of all cleaning steps to maintain transparency and reproducibility.
- Maintain copies of intermediate cleaning stages to track changes and identify potential issues.
- Use multiple validation methods for critical transformations to ensure accuracy.
- Document your validation process to facilitate collaboration and reproducibility.
By following these steps and methods, you can ensure that your data cleaning process is thorough and reliable, providing a solid foundation for your analysis.
How do you automate repetitive data cleaning tasks in Python?
Automating repetitive data cleaning tasks in Python can save you a significant amount of time and reduce errors in your data preparation process. To achieve effective automation, it's essential to identify common patterns in your cleaning needs and create systematic approaches to handle them.
One strategy I use is to standardize text data using vectorized operations instead of loops. This approach is not only faster but also more consistent when handling large datasets. For example, you can use pandas' built-in methods for bulk operations, such as
map() for straightforward transformations, apply() for more complex logic, and DataFrame.map() for operations across multiple columns.
Another approach is to create reusable cleaning functions for common transformations. For instance, you can write functions to standardize formats, handle missing values, or categorize data that you can apply across different datasets. This way, you can avoid duplicating effort and make your code more efficient.
When implementing automation, it's essential to follow best practices. First, start small and validate thoroughly. Test your automation on a sample of data first, verify results at each step, and document your transformation rules. This will help you catch any errors and ensure that your automation is working as expected.
It's also beneficial to build in flexibility. Design functions that can handle variations in your data, include error handling for unexpected cases, and make parameters adjustable for different scenarios. This will make your automation more robust and able to handle different situations.
Finally, maintain data integrity by keeping original data separate from cleaned versions, tracking all transformations applied, and including validation checks in your automation. This will ensure that your data remains accurate and reliable.
By following these strategies and best practices, you can create automated cleaning processes that ensure consistency across your datasets, reduce human error, and create reproducible workflows that can be shared with team members. Effective automation doesn't mean you have to clean everything all at once―it's involves identifying repetitive patterns and creating reliable solutions for handling them systematically.
What strategies help maintain data integrity during cleaning?
When cleaning data, you should try to maintain integrity by being systematic and detailed in your approach. Here are some effective strategies to help you do so:
- Preserve original data: Keep your raw data files untouched and create copies for cleaning steps. This way, you can maintain versions of intermediate stages and track any changes you make.
- Document thoroughly: Record every transformation you apply, including the rationale behind your cleaning decisions and any assumptions you make. This will help you keep track of your process and ensure transparency.
- Validate continuously: Use multiple methods to validate your data, such as checking column types and non-null counts, creating heatmaps to visualize patterns in missing values, and comparing value distributions before and after cleaning. This will help you catch any errors or inconsistencies.
- Handle missing and duplicate data strategically: Analyze patterns in missing values before deciding how to handle them. Consider dropping columns with excessive missing values instead of rows, and verify that duplicate removal doesn't eliminate valuable information. Document all removal decisions and their impact.
- Test transformations: Start with a small sample to verify your approach, and use methods that perform well for better results. Chain operations together for complex transformations, and validate results at each step.
For example, when cleaning survey data, calculate the percentage of rows removed and verify that the reduction doesn't disproportionately affect certain groups. After standardizing text responses, confirm that all variations were properly captured in your final categories.
Common challenges when cleaning data include detecting subtle changes in relationships between variables, identifying unintended consequences of cleaning steps, and balancing data quality with data preservation. To address these challenges:
- Keep detailed logs of all cleaning steps
- Maintain copies of intermediate stages
- Use multiple validation methods for critical transformations
- Document your validation process
Remember, the goal of cleaning data is not to create perfect data, but to ensure that your cleaning process maintains the integrity of your insights while documenting any limitations or assumptions.
How do you handle outliers in numerical data using pandas?
When cleaning data in Python, dealing with outliers is an important step that can significantly impact your analysis results. By taking a systematic approach to outlier detection and treatment, you can create more reliable datasets for your analysis while maintaining data integrity.
To detect outliers in numerical data using pandas, start by looking at basic summary statistics and visualizations. Means, medians, and standard deviations can quickly highlight potential issues. Visualization tools like box plots can help identify extreme values that warrant further investigation. These initial checks often reveal patterns that might indicate data quality issues or interesting phenomena worth exploring.
Once you've identified outliers, you have several options for handling them:
- Remove them if they're clearly errors
- Cap them at a certain threshold (winsorization)
- Transform the data to reduce their impact
- Keep them if they represent valid but rare events
The choice of how to handle outliers depends on the context of your analysis. For example, when analyzing employee survey data, you might keep some extreme values because they represent genuine but unusual responses. On the other hand, when working with sensor data, you might remove extreme outliers that indicate equipment malfunctions.
To ensure you're handling outliers effectively, follow these best practices:
- Document all outlier handling decisions
- Validate changes with domain experts when possible
- Keep your original data intact while cleaning
- Consider how your treatment choice might affect your analysis goals
Keep in mind, the goal isn't to eliminate all unusual values―it's to ensure your data accurately represents the phenomenon you're studying. By being thoughtful and systematic in your approach to outlier detection and treatment, you can create more reliable datasets for your analysis.
What are the best practices for documenting data cleaning steps?
When working with data, it's worth keeping a record of the steps you take to clean and prepare it for analysis. This helps you reproduce your results and makes it easier to collaborate with others. Here are some best practices to follow:
- Keep a structured cleaning log:
- An initial assessment of the data, including any missing values, duplicates, or inconsistencies
- A description of each transformation you apply and why you made that decision
- The impact of each cleaning decision, such as the number of rows removed or the effect on the data distribution
- The results of any validation checks you run to ensure the data is accurate and consistent
- Document key decisions:
- How you handled missing values (e.g., by dropping them, filling them with a specific value, or ignoring them)
- How you handled outliers and duplicates
- How you standardized column names and data types
- Any data type conversions you made
- Use version control:
- Keep your original data separate from your cleaned data
- Save intermediate stages of your cleaning process
- Track the sequence and impact of each transformation
- Note any unexpected patterns or issues you discover during the cleaning process
To implement these practices, create a dedicated section in your Python scripts or notebooks for documentation. Include summary statistics before and after each major transformation, and validate that relationships between variables remain sensible after cleaning.
Remember, the goal of documenting your data cleaning steps is to make it easy to reproduce your results and understand the decisions you made. By following these best practices, you'll be able to refine your approach and build trust in your analysis.