
Tutorial 2:
Summarizing Data in SQL
Have you ever looked at a bunch of raw numbers in a spreadsheet and wondered how to make sense of the information? This is what we'll learn about here. I want to show you how SQL shapes the way we work with data, especially when we're dealing with large sets of information.
Here at Dataquest, we use SQL every day to keep track of how our courses are performing. With thousands of learners learning from our content, we need a way to quickly spot trends and patterns. SQL provides us with powerful tools, like aggregation functions that can add things up, find averages, or count items. When we use these tools with the GROUP BY clause, we can look at our data from different angles. For instance, we group our course data by topic to see which subjects learners find most interesting or challenging.
I still remember when I first started working with large amounts of data in a spreadsheet. It was like trying to navigate a dense forest without a map. But as I began writing SQL queries for working with real information, things started to click. I realized SQL could help me ask the right questions and find useful answers. This skill has been instrumental in making informed, data-driven decisions that keep our team on track.
One of the reports we often run at Dataquest looks at how many learners complete each course over time. This helps us identify which courses are successful and which ones might need improvement. We also analyze how many times learners attempt each part of a course, which helps us spot any tricky sections that might be causing confusion. With these insights, we can refine our courses to make the learning journey smoother and more enjoyable for our learners.
Now that we've covered the basics, let's explore the specifics of summarizing data in SQL. You'll learn about functions that work with groups of data, how to calculate summary statistics, and ways to group and filter information effectively. By the end, you'll have the skills to uncover meaningful insights from your data. It's like learning to read the story hidden in the numbers!
Let's start building our skills in data summarization. We'll begin with the building blocks of data summarization in SQL—the functions that work with groups of data. These are like the raw materials for a house—once you understand them, you'll be amazed at what you can build. And the best part? You can start making sense of large datasets with just a few lines of code.
Lesson 1 – Aggregate Functions with SQL

Remember when I mentioned that SQL helps us spot trends and patterns in our data? That's where SQL's aggregate functions come in. I still remember the thrill of discovering them—it felt like uncovering a powerful tool for data analysis.
In this tutorial we'll use the Chinook database. This database contains information about a fictional digital music shop—like an iTunes store. All the queries you'll see are from our Summarizing Data in SQL course.
Let's start with the SUM function. It's as straightforward as it sounds—it adds up all the values in a column. Here's how we use it:
SELECT SUM(total) AS overall_sale
FROM invoice;
And here are the results:
| overall_sale |
|---|
| 4709.43 |
This query calculates the total sales by adding up all the values in the 'total' column of our invoice table. At Dataquest, we use queries like this to track our total earnings. By doing so, we can gain a better understanding of our business's overall performance.
Next, let's explore the AVG function, which calculates the average of a column:
SELECT AVG(total) AS avg_sale
FROM invoice;
Here's the output:
| avg_sale |
|---|
| 7.67 |
This shows us the average sale amount across all invoices. It's super useful for understanding typical behavior. For instance, we use it to analyze how many courses our learners usually complete or how much time they typically spend.
We also have MIN and MAX for finding the smallest and largest values, and COUNT for adding up rows or non-null values. These functions provide a quick overview of your data, much like looking at a map before you start a journey.
I've got a story about these functions. A few years ago, when I was using them extensively at Dataquest, I noticed low engagement and completion rates for the first course in our newer Excel content. So, I brought this to the team and we decided to dig into the data using aggregate functions.
We used a query something like this to investigate:
SELECT category, AVG(completion_rate) AS avg_completion
FROM courses
GROUP BY category;
Guess what we found? The completion rates were much lower for the first Excel course than the remaining four courses in the sequence. After digging into the course content we identified the problem with the first course—it wasn't applied, or "hands-on" enough. With this new insight, we completely rewrote the first course to make it more engaging. And you know what? Our completion rates for the first course soon matched the high completion rates of the later courses.
This experience really demonstrated the power of aggregate functions. They help you see the big picture and spot patterns you might miss if you're just looking at one piece of data at a time.
As we continue, we'll explore how to combine these aggregate functions with other SQL techniques to dig even deeper into your data. By doing so, we can uncover more insights and make better data-driven decisions.
Lesson 2 – Summary Statistics with SQL

After getting comfortable with the basics of combining data in SQL, it's time to explore summary statistics. This is where SQL really shows its strength as a tool for data analysis, helping us find insights that might be hiding in large datasets.
We use summary statistics every day to get insights into our course data. For instance, we often want to know the total runtime of our video content, the average lesson duration, and the number of lessons we offer. You might think this would take a lot of work, but we can actually get all this information with just one SQL query:
SELECT SUM(milliseconds) AS total_runtime,
AVG(milliseconds) AS avg_runtime,
COUNT(*) AS num_row
FROM track;
This query gives us a result that looks like this:
| total_runtime | avg_runtime | num_row |
|---|---|---|
| 1378778040 | 393599.212104 | 3503 |
So, what does this tell us? Well, our total content runtime is 1,378,778,040 milliseconds, each track is about 393,599 milliseconds long on average, and we have 3,503 tracks in total. But let's be honest, most of us don't think in milliseconds, do we?
To make our results easier to understand, we can change the time to minutes and round the results. Here's how we do that:
SELECT AVG(milliseconds / 1000.0 / 60) AS avg_runtime_minutes,
ROUND(AVG(milliseconds / 1000.0 / 60), 2) AS avg_runtime_minutes_rounded
FROM track;
This query gives us:
| avg_runtime_minutes | avg_runtime_minutes_rounded |
|---|---|
| 6.559987 | 6.56 |
Now we can easily see that our average track is about 6.56 minutes long. Much better, right? This kind of insight is exactly what makes SQL so powerful for data analysis.
I remember when I first started using these techniques at Dataquest. We were in the middle of a big project to improve our course content, and these summary statistics were a real eye-opener. Our analysis showed us that some of our courses had much longer average lesson completion times, and lower completion rates, than others.
At first, I was surprised. I thought all of our lessons took about the same length of time to complete. I also assumed that the difficulty of our course content was consistent. But the data told a different story—some courses were too long, others were too difficult, or both. This was valuable information because it helped us figure out where we needed to break content into smaller pieces, or make it less challenging. We spent a few weeks reworking those poor performing lessons, splitting them up into bite-sized chunks. The result? Our learners reported better understanding and higher completion rates. It was a win-win situation, all thanks to a few simple SQL queries.
If you're working with data, I encourage you to try out these summary statistics. They can quickly show you things about your data that you might miss otherwise. Here's a simple way to start:
- Think about your data. What do you want to know about it?
- Write down some questions. For example, "What's the average value?" or "How many items do we have in total?"
- Turn those questions into SQL queries using functions like
AVG(),COUNT(), andSUM(). - Run your queries and see what you find out!
Remember, SQL isn't just good at getting data—it's also great at summarizing and analyzing that data in ways that make sense. As you practice these techniques, you'll be able to find valuable insights in even the biggest datasets.
Now that you've seen the power of summary statistics, let's see how we can group and analyze data.
Lesson 3 – Group Summary Statistics with SQL
When I first discovered grouping in SQL, things just clicked for me. It was like stumbling upon a hidden feature in a video game—suddenly, I could explore my data in ways I never thought possible. This skill has become a go-to tool in my work at Dataquest, where we use SQL grouping all the time to better understand our course data.
The GROUP BY clause is the key to this powerful feature. It's like a categorization tool for your data. You can organize your information into groups based on one or more columns, and then perform calculations on each group.
To help you understand GROUP BY, think of it like sorting items into boxes. Imagine you have a pile of invoices from different countries, and you want to organize them by country. GROUP BY does something similar with your data in SQL.
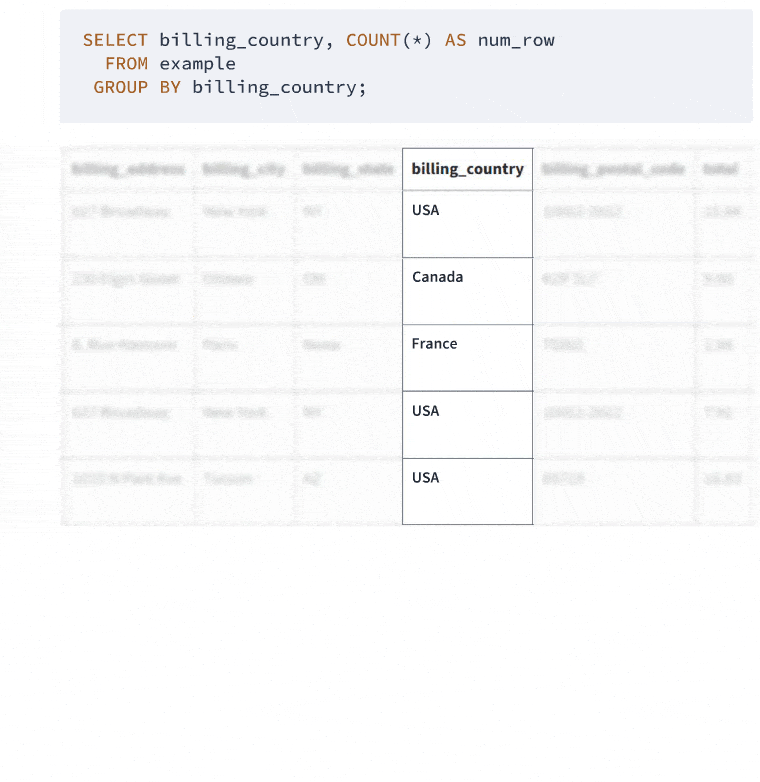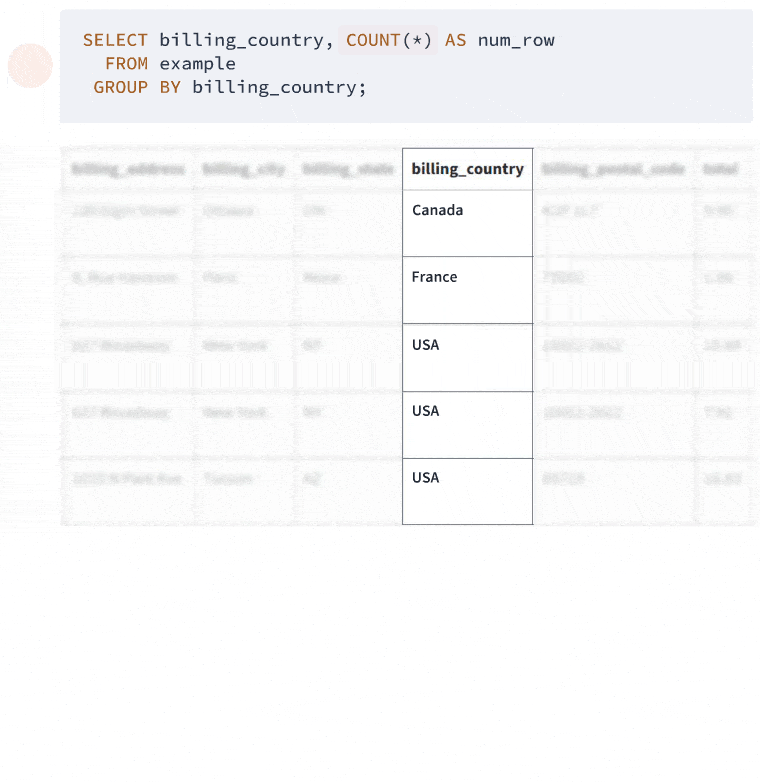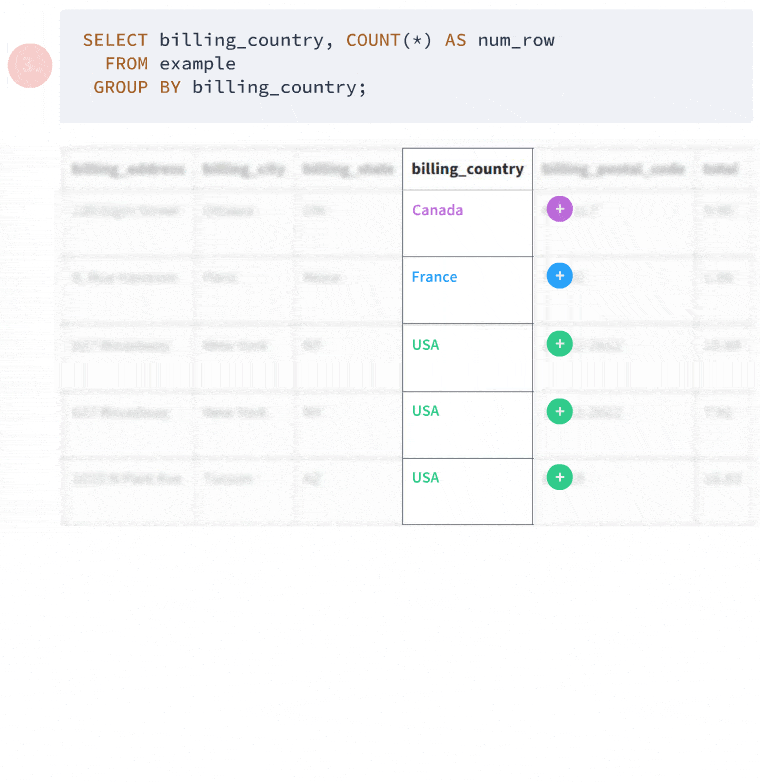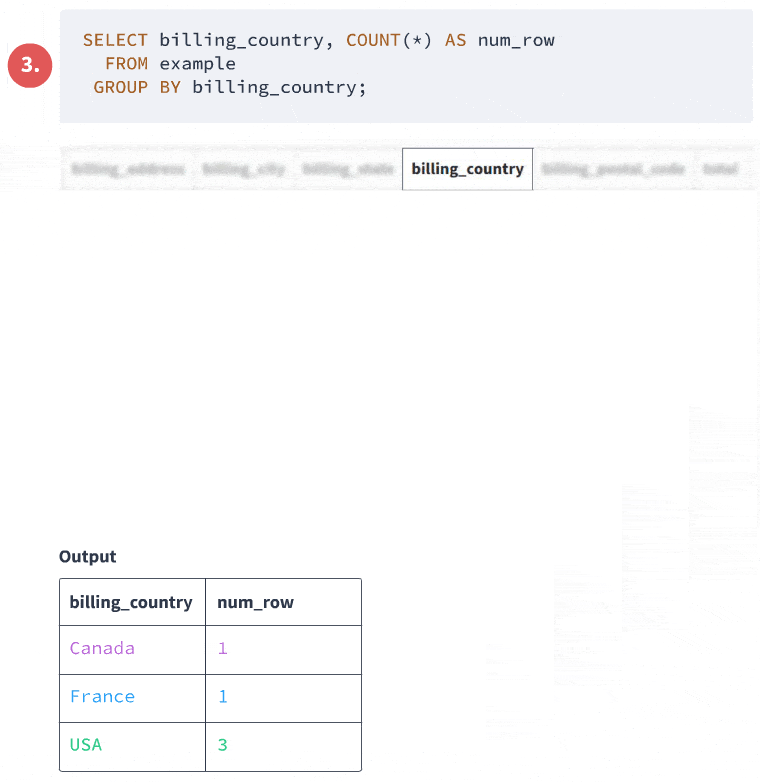
When you use GROUP BY, you're telling SQL to organize your data into groups based on one or more columns. It's like saying, "Put all the invoices from Argentina in one box, all the invoices from Australia in another, and so on." Then, for each group (or box), you can perform calculations or count items. Here's a simple example to get us started:
SELECT billing_country, COUNT(*) AS num_row
FROM invoice
GROUP BY billing_country;
This query is asking, "Hey database, can you tell me how many invoices we have for each country?" Here's what you might see:
| billing_country | num_row |
|---|---|
| Argentina | 5 |
| Australia | 10 |
| Austria | 9 |
| Belgium | 7 |
| Brazil | 61 |
| Canada | 76 |
| Chile | 13 |
| Czech Republic | 30 |
| Denmark | 10 |
| Finland | 11 |
See how GROUP BY sorted our data into country groups, and COUNT(*) counted up the invoices for each? It's a quick way to get a sense of your data.
GROUP BY is even more powerful when you combine it with other SQL tools. For example:
SELECT billing_state,
COUNT(*) AS num_row,
AVG(total) AS avg_sale
FROM invoice
WHERE billing_country = 'USA'
GROUP BY billing_state;
This query is asking, "For each state in the USA, how many invoices do we have, and what's the typical sale amount?" Here's a sneak peek at what you might get:
| billing_state | num_row | avg_sale |
|---|---|---|
| AZ | 9 | 9.350000000000001 |
| CA | 29 | 7.715172413793104 |
| FL | 12 | 7.672499999999999 |
| IL | 8 | 8.91 |
| MA | 10 | 6.633 |
| NV | 11 | 8.28 |
| NY | 8 | 9.9 |
| TX | 12 | 7.177499999999999 |
| UT | 10 | 7.226999999999999 |
| WA | 12 | 8.1675 |
As you've probably figured out, at Dataquest we use queries like this to better understand our learners. For instance, we might look at how well learners are doing in different types of courses. We could group courses by topic and check out the average completion rate. This helps us spot which subjects our learners love, and which ones might need a little extra attention.
An important thing to remember is that GROUP BY is different from filtering with WHERE. WHERE filters data before grouping, while GROUP BY organizes the data into categories for analysis. For example, if you wanted to only look at invoices from 2022, you might use WHERE to filter the data first, then use GROUP BY to organize the remaining invoices by country.
Here are some tips to keep in mind when working with GROUP BY:
- Think of
WHEREas a filter that checks your data beforeGROUP BYorganizes it. - Make sure to include all non-aggregated columns in your
GROUP BYclause. - Use
GROUP BYto summarize your data by categories or time periods. - Try pairing
GROUP BYwithORDER BYto sort your results.
As you play around with GROUP BY, you'll find it becoming your go-to tool in SQL. It helps answer questions like "What's flying off our shelves?" or "Who are our VIP customers?" These insights can shape business decisions.
In the next section, we'll explore more advanced techniques for working with grouped data, including grouping by multiple columns and using HAVING to filter your results. With these skills, you'll be able to dig even deeper into your data and uncover some real insights.
Lesson 4 – Multiple Group Summary Statistics

Imagine grouping your data by not just one, but multiple columns. This enables you to drill down into specific subsets of data and uncover hidden trends. For instance, let's say we want to analyze our invoice data by both country and state. We can use the following SQL query:
SELECT billing_country, billing_state,
COUNT(*) AS num_row,
AVG(total) AS avg_sale
FROM invoice
GROUP BY billing_country, billing_state;
This query gives us a breakdown of sales by both country and state:
| billing_country | billing_state | num_row | avg_sale |
|---|---|---|---|
| Argentina | None | 5 | 7.92 |
| Australia | NSW | 10 | 8.118 |
| Austria | None | 9 | 7.699999999999999 |
| Belgium | None | 7 | 8.627142857142857 |
| Brazil | DF | 15 | 7.128 |
| Brazil | RJ | 11 | 7.47 |
| Brazil | SP | 35 | 6.816857142857143 |
| Canada | AB | 10 | 2.9699999999999998 |
| Canada | BC | 9 | 7.37 |
| Canada | MB | 8 | 8.78625 |
But what if we want to zoom in even more? That's where the HAVING clause comes in. In SQL, both WHERE and HAVING clauses are used for filtering data, but they work at different stages of the query process. Think of WHERE as a filter that applies before grouping, and HAVING as a filter that applies after grouping.
We need both because they serve different purposes. WHERE can't use aggregate functions (like AVG, SUM, COUNT) because it operates on individual rows before any grouping occurs. HAVING, however, can use these functions because it works after grouping. Here's an example that uses both:
SELECT billing_country, billing_state,
MIN(total) AS min_sale,
MAX(total) AS max_sale
FROM invoice
WHERE billing_state <> 'None'
GROUP BY billing_country, billing_state
HAVING AVG(total) < 10;
The WHERE clause first filters out rows where billing_state is 'None'. In other words, it's is saying, "Hey, give me all the rows where the billing state is not equal to 'None'." Then, after grouping by country and state, the HAVING clause only keeps groups where the average total is less than 10. This HAVING clause is saying, "From our grouped data, only show me the country-state combinations where the average sale is less than $10." It's a great way to focus on specific parts of your data that you're really interested in. Here's what we get:
| billing_country | billing_state | min_sale | max_sale |
|---|---|---|---|
| Australia | NSW | 1.98 | 17.82 |
| Brazil | DF | 0.99 | 14.85 |
| Brazil | RJ | 1.98 | 16.83 |
| Brazil | SP | 0.99 | 17.82 |
| Canada | AB | 0.99 | 8.91 |
| Canada | BC | 2.97 | 14.85 |
| Canada | MB | 1.98 | 19.8 |
| Canada | NS | 0.99 | 13.86 |
| Canada | NT | 0.99 | 11.88 |
| Canada | ON | 0.99 | 19.8 |
To summarize, use WHERE for conditions on individual rows before grouping (e.g., "only invoices from 2022", "only products in stock"). Use HAVING for conditions on groups after grouping (e.g., "only countries with more than 100 sales", "only product categories with an average price above $50").
I've used this technique to analyze course data at Dataquest, grouping courses by topic and programming language, then filtering for combinations where less than 50% of learners were finishing the course. In one case, this revealed that our intermediate SQL courses were giving people more trouble than we thought! We broke those courses into smaller, more manageable pieces, made the instructions clearer, and within a few months, more learners were completing the courses.
To give another example, recently I was puzzled by low completion rates for the Prompting Large Language Models in Python course I developed last year. I uncovered this by grouping our course data by lesson number and screen, then filtered for the low completion rates. This revealed the exact screen where the problem was! An issue with answer checking made it impossible to pass the screen. Thanks to the new SQL query I built, I was able to identify this trouble screen among the thousands we have on the Dataquest platform. We saved this query and re-run it regularly to monitor screen-level performance.
Here are a few tips I've picked up along the way:
-
Start small: Don't try to group everything at once. Start with one column, then add more as you get comfortable.
-
Order matters: Remember,
WHEREcomes beforeGROUP BY, andHAVINGcomes after. -
Keep it speedy: Grouping lots of columns can slow things down, especially with big datasets. If your query's taking forever, try grouping fewer columns or ask your database admin about optimizing indexes.
To wrap up, multiple group summary statistics is a powerful technique that can help you uncover hidden insights in your data. By following these tips and best practices, you can start analyzing your data in new and exciting ways.
Advice from a SQL Expert
We've covered a lot of ground in our exploration of SQL data summarization techniques. I hope you're as excited as I am about the possibilities they offer.
This article demonstrated the value of SQL in making sense of large datasets. Whether you're analyzing sales figures, understanding user behavior, or monitoring system performance, SQL helps you identify correlations and uncover insights that might otherwise remain hidden.
I still remember when I first started using these techniques at Dataquest. We were analyzing our course completion rates, and by using SQL to group and summarize our data, we uncovered some surprising patterns. This led to improvements in our course design that significantly boosted learner success rates. It was a powerful reminder of how SQL can drive real-world impact.
Now, I'm sure you're eager to put these new skills to use. Here's my advice: start with a simple SQL project, and gradually build up to more complex analyses. Pick a dataset that interests you—maybe something related to your work or a personal interest. Begin with basic queries, and gradually move on to more advanced techniques.
For those interested in expanding their skills further, our Summarizing Data in SQL course offers hands-on practice with real-world datasets. If you're looking to learn even more, our SQL Fundamentals path covers everything from the basics to advanced techniques.
As you practice, you'll become more comfortable asking questions of your data and uncovering insights. Don't be afraid to explore and learn more—there are plenty of resources available to help you along the way. Keep in mind that data analysis is as much an art as it is a science, and you're the artist.
Frequently Asked Questions
What is summarizing data in SQL?
Summarizing data in SQL is a powerful technique that helps you make sense of large datasets by condensing them into meaningful insights. This is achieved using aggregate functions like SUM, AVG, COUNT, MIN, and MAX, which work together with the GROUP BY clause.
At its core, summarizing data in SQL involves performing calculations on specific groups within your data. For example, you might want to know the average sale amount for each country:
SELECT billing_country,
AVG(total) AS avg_sale
FROM invoice
GROUP BY billing_country;
This query could return results like:
| billing_country | avg_sale |
|---|---|
| USA | 7.94 |
| Canada | 7.05 |
Summarizing data in SQL offers several benefits. You can quickly spot trends, create insightful reports, and make informed decisions. For instance, an e-commerce company could use these techniques to identify their best-selling products by category, which would help them optimize their inventory and marketing strategies.
However, summarizing data can also come with challenges. Large datasets can slow query performance, and summary statistics might mask important details or outliers. To overcome this, it's essential to balance your high-level view with detailed analysis when needed.
By using SQL to summarize your data, you can turn raw numbers into actionable insights. Whether you're analyzing sales figures, user behavior, or system performance, these techniques empower you to extract valuable information from your data, driving smarter decision-making across various industries.
What are the most effective methods to learn SQL data summarization techniques?
Developing skills in summarizing data in SQL is a valuable skill for anyone working with large datasets. Here are some effective methods to help you become proficient in this area:
- Build a strong foundation: Start by understanding the core aggregate functions like
SUM,AVG,COUNT,MIN, andMAX. Practice using these functions individually before combining them in more complex queries. - Use real-world datasets: Apply your skills to actual data. Many open-source datasets are available online, or you can create your own. Try answering practical questions like "What's the average sale amount per country?" or "Which product category has the highest total revenue?"
- Gradually increase complexity: Begin with simple queries and gradually introduce more advanced concepts. For example, start with a basic
GROUP BYclause, then progress to grouping by multiple columns or using subqueries. - Learn the difference between
WHEREandHAVINGclauses:WHEREfilters individual rows before grouping, whileHAVINGfilters grouped data. Practice using both in your queries to refine your results effectively. - Explore multiple group summary statistics: Challenge yourself to group data by two or more columns. This can reveal hidden patterns and correlations in your data.
- Leverage online learning platforms: Many websites offer interactive SQL environments where you can practice writing and running queries. These platforms often provide immediate feedback, helping you learn from your mistakes quickly.
- Apply your skills to real-world problems: Use your skills to analyze actual data challenges in your work or personal projects. For instance, you could analyze your personal finance data to track spending patterns across different categories and time periods.
Remember, becoming proficient in summarizing data in SQL takes time and practice. Start with simple queries, practice regularly, and gradually increase the complexity of your analyses. With persistence and hands-on experience, you'll soon be able to extract valuable insights from even the most complex datasets. Keep exploring and challenging yourself—every query you write is a step towards proficiency!
How can aggregate functions in SQL help in analyzing large datasets?
When working with large datasets, it can be overwhelming to make sense of the vast amounts of information. That's where aggregate functions come in—they help you summarize and extract valuable insights from your data. In this answer, we'll explore how aggregate functions can help you analyze large datasets and provide examples of how to use them.
Aggregate functions, such as SUM, AVG, COUNT, MIN, and MAX, are powerful tools that help you quickly summarize data by performing calculations on groups of rows. When analyzing large datasets, these functions offer several advantages:
- They provide a quick overview of your data, helping you spot trends and patterns.
- They're efficient, processing entire groups of data at once rather than row by row.
- They're versatile and can be combined with other SQL features for deeper analysis.
For example, at Dataquest, we use aggregate functions to analyze our course data. We might use a query like this to understand our video content:
SELECT SUM(milliseconds) AS total_runtime,
AVG(milliseconds) AS avg_runtime,
COUNT(*) AS num_row
FROM track;
This single query gives us a clear picture of our video content, including the total runtime, average lesson duration, and the total number of lessons we offer.
Aggregate functions become even more powerful when combined with GROUP BY. This allows you to summarize data in SQL for specific subsets of your information. For instance, you could analyze sales data by both country and state:
SELECT billing_country, billing_state,
COUNT(*) AS num_row,
AVG(total) AS avg_sale
FROM invoice
GROUP BY billing_country, billing_state;
This query breaks down the number of sales and average sale amount for each country-state combination, providing a detailed view of your data.
While aggregate functions are incredibly useful, it's worth noting that complex queries with multiple groupings can sometimes slow down performance. In such cases, you might need to optimize your database or consider specialized data warehousing solutions.
In summary, aggregate functions are a key part of summarizing data in SQL effectively. By using these functions, you can extract valuable insights from your data and make informed decisions across various fields. Whether you're analyzing sales figures, user behavior, or course performance, aggregate functions can help you uncover the stories hidden in your data.
What practical benefits does the GROUP BY clause offer when summarizing data in SQL?
GROUP BY clause offer when summarizing data in SQL?The GROUP BY clause in SQL is a valuable feature that helps you summarize data and gain insights into specific subsets of your data.
One key advantage of using GROUP BY is that it allows you to quickly identify patterns and trends within your data. For example, you can use it to analyze sales performance by country or product category. This feature also enables you to efficiently calculate aggregate statistics, such as averages, counts, or sums, for each group. This is particularly useful when working with large datasets. Additionally, GROUP BY makes it easy to compare different groups, which can help you spot outliers or anomalies.
To illustrate this, let's consider an example from the tutorial that demonstrates how to use GROUP BY to analyze invoice data by country and state:
SELECT billing_country, billing_state,
COUNT(*) AS num_row,
AVG(total) AS avg_sale
FROM invoice
GROUP BY billing_country, billing_state;
This query provides a breakdown of the number of sales and average sale amount for each country-state combination, giving you valuable insights at a glance. By combining GROUP BY with other SQL features, such as HAVING or ORDER BY, you can further filter and sort your grouped data, uncovering even more insights.
How do WHERE and HAVING clauses differ when filtering summarized data in SQL?
WHERE and HAVING clauses differ when filtering summarized data in SQL?When working with summarized data in SQL, it's essential to understand the role of WHERE and HAVING clauses. Both help refine your results, but they operate at different stages of the query process.
Think of the WHERE clause as a filter that checks each row individually before grouping. It excludes data before any summarizing happens. For example, you might use WHERE to focus on rows where the billing state is known:
WHERE billing_state <> 'None'
This clause excludes rows where the billing state is 'None' before grouping occurs.
In contrast, the HAVING clause filters data after it's been summarized. It's like a checkpoint after grouping, ensuring that only relevant data remains. HAVING can use aggregate functions because it works on already grouped data. For instance:
HAVING AVG(total) < 10
This keeps only groups where the average total is less than 10.
Let's consider a real-world scenario: analyzing sales data. You might use WHERE to focus on this year's sales, group by product category, and then use HAVING to identify categories with over 1000 units sold.
One common mistake is using HAVING when WHERE would be more efficient. While HAVING can filter on individual columns, it's generally better to use WHERE for non-aggregate conditions to optimize query performance.
In summary, when summarizing data in SQL, use WHERE to filter individual rows before grouping and HAVING to filter groups after summarizing. By mastering these clauses, you'll be able to extract valuable insights from large datasets.
What are some common challenges when summarizing data in SQL, and how can they be addressed?
When working with SQL, you may encounter several challenges when summarizing data. Let's take a closer look at some common issues and how to overcome them.
Dealing with NULL values
NULL values can be tricky to work with, especially when using functions like AVG or SUM. For example, if you're calculating the average sale amount, NULL values might be ignored, which could inflate your average. To address this, you can use the COALESCE function to replace NULLs with a default value, or use IS NOT NULL in your WHERE clause to exclude them.
Grouping by multiple columns
As your analysis becomes more complex, you may need to group by multiple columns. This can make queries harder to write and understand. Start by keeping it simple and gradually increase complexity. For example:
SELECT billing_country, billing_state,
COUNT(*) AS num_row,
AVG(total) AS avg_sale
FROM invoice
GROUP BY billing_country, billing_state;
This query groups invoices by both country and state, providing a more detailed view of your data.
Choosing between WHERE and HAVING
WHERE filters individual rows before grouping, while HAVING filters grouped data. Use WHERE for conditions on individual rows and HAVING for conditions on groups. For instance:
SELECT billing_country, billing_state,
MIN(total) AS min_sale,
MAX(total) AS max_sale
FROM invoice
WHERE billing_state <> 'None'
GROUP BY billing_country, billing_state
HAVING AVG(total) < 10;
This query first excludes rows where billing_state is 'None', then groups by country and state, and finally filters for groups with an average total less than 10.
Performance issues with large datasets
Complex queries on large datasets can be slow. To optimize performance, consider creating indexes on frequently used columns or breaking complex queries into smaller parts.
In real-world applications, these challenges often intersect. For example, a data analyst once noticed unusually low completion rates for a course. By drilling down into the data using SQL summarization techniques, they discovered a single problematic screen causing the issue. This highlights the importance of being able to address these challenges effectively.
Remember, becoming proficient in summarizing data in SQL takes practice. Start with simple queries and gradually increase complexity as you become more comfortable. With time and practice, you'll be able to extract valuable insights from even the most complex datasets, turning raw numbers into actionable information for better decision-making.
What are some common pitfalls to avoid when working with summary statistics in SQL?
When summarizing data in SQL, you're working with a powerful tool that can reveal valuable information about your datasets. However, there are several common pitfalls that can trip up even experienced data analysts. Here are some key issues to watch out for:
- Misusing
WHEREandHAVINGclauses: These clauses serve different purposes in your SQL queries.WHEREfilters individual rows before any grouping occurs, whileHAVINGfilters grouped data after theGROUP BYclause. For example, if you're analyzing invoice data and want to focus on a specific country, useWHERE(e.g.,WHERE billing_country = 'USA'). On the other hand, if you want to filter for groups with an average sale above $10, useHAVING(e.g.,HAVING AVG(total) > 10). - Forgetting to include non-aggregated columns in
GROUP BY: When usingGROUP BY, all non-aggregated columns in yourSELECTstatement must be included in theGROUP BYclause. For instance, if you're grouping invoices by country and state, both columns should be in yourGROUP BY:SELECT billing_country, billing_state, AVG(total) AS avg_sale FROM invoice GROUP BY billing_country, billing_state; - Misinterpreting NULL values in calculations: NULL values can skew your results, especially when using functions like
AVGorSUM. For example, if you're calculating the average sale amount, NULL values might be ignored, potentially inflating your average. Always consider how your database handles NULLs and whether you need to exclude or handle them separately. - Overlooking data quality: Summary statistics can hide data quality issues. At Dataquest, we once noticed unusually low completion rates for a course. By drilling down into our data, we discovered a single problematic screen causing the issue. Always inspect your raw data and use functions like
MINandMAXto check for outliers or unexpected values.
To avoid these pitfalls, start with simple queries and gradually add complexity. This approach helps you catch errors early and ensures your summary statistics accurately represent your data. Effective data summarization in SQL is not just about writing queries; it's about asking the right questions and interpreting the results meaningfully.
How does multiple group summary statistics enhance data analysis in SQL?
Multiple group summary statistics is a powerful technique for summarizing data in SQL that allows you to analyze information across multiple dimensions simultaneously. This approach helps you uncover deeper insights and patterns that might be missed when looking at single-dimension summaries.
For example, let's say you want to analyze sales data by both country and state. You can use a query like this:
SELECT billing_country, billing_state,
COUNT(*) AS num_row,
AVG(total) AS avg_sale
FROM invoice
GROUP BY billing_country, billing_state;
This query provides a breakdown of the number of sales and average sale amount for each country-state combination, giving you a more detailed view of your data. You can further refine your analysis by using the HAVING clause to filter grouped data based on specific conditions.
The benefits of using multiple group summary statistics include gaining a better understanding of your data across multiple dimensions, making more precise decisions, and increasing efficiency by analyzing multiple aspects of your data in a single query.
To illustrate this, consider a real-world application of this technique. At Dataquest, we analyzed course data to identify areas where learners were struggling. By grouping courses by topic and programming language, and then filtering for combinations where less than 50% of learners were finishing the course, we discovered that intermediate SQL courses were more challenging than expected. This insight led to course improvements and increased completion rates.
While this technique is powerful, it's essential to be mindful of potential challenges, such as increased query complexity and longer execution times for large datasets. To mitigate these, start with smaller groupings and gradually increase complexity as needed.
In summary, using multiple group summary statistics effectively can help you extract more value from your data, uncover hidden patterns, and make more informed decisions based on a comprehensive view of your information.
How can advanced SQL data summarization techniques improve business decision-making?
Advanced SQL data summarization techniques can greatly enhance business decision-making by providing a clearer picture of operations, customer behavior, and overall performance. These techniques enable companies to extract meaningful insights from large datasets, which can lead to more informed decisions.
One key technique is the GROUP BY clause, which allows businesses to organize data into categories. For example, a company could group sales data by country and state to gain a detailed view of regional performance. This granular analysis can reveal patterns that might be missed when looking at aggregate data alone.
The HAVING clause complements GROUP BY by filtering grouped data based on specific conditions. For instance, a business could use HAVING to identify product categories with average sales below a certain threshold, quickly spotting underperforming segments that require attention.
By combining these techniques, businesses can examine data across multiple dimensions simultaneously. For example, a query could analyze invoice data by both country and state, then filter for groups where the average sale is below a certain amount. This multi-dimensional analysis can uncover nuanced insights that drive more informed decision-making.
Real-world applications of these techniques are numerous. For example, an online learning platform used SQL to analyze course completion rates by grouping data by lesson number and screen. This analysis revealed a specific screen causing issues for learners, allowing the company to make targeted improvements and boost overall course completion rates.
While these techniques are powerful, they can present challenges, particularly when dealing with large datasets that may slow query performance. To address this, businesses can start with simpler queries and gradually increase complexity, or consult with database administrators about optimizing indexes for frequently used queries.
By leveraging these advanced SQL data summarization techniques, businesses can make more informed decisions, optimize their operations, and ultimately drive growth. Whether it's identifying trends in sales data, pinpointing areas for product improvement, or understanding customer behavior, these SQL tools provide the insights needed to stay competitive.
What are some real-world examples of using SQL data summarization in data analysis projects?
Let's take a look at how SQL data summarization can help solve real-world business challenges.
1. Improving Course Completion Rates
An online learning platform (that you know) used SQL data summarization to identify low completion rates in their intermediate SQL courses. By grouping course data by topic and programming language, they found that certain combinations had less than 50% completion rates. This led them to break down the courses into smaller, more manageable segments and improve instructions, resulting in better learner outcomes.
2. Identifying Problematic Content
SQL queries helped an online course provider pinpoint a specific issue causing low completion rates in a course about large language models. By grouping data by lesson number and screen, they isolated the exact screen causing problems. This precise identification allowed them to quickly resolve the issue.
3. Analyzing Regional Sales Performance
SQL data summarization can provide valuable insights into sales patterns across different geographical areas. By grouping invoice data by country and state, businesses can analyze the number of sales and average sale amounts for each region. This information helps them understand market performance, identify high-performing areas, and recognize regions that may need additional support or marketing efforts.
These examples illustrate the benefits of summarizing data in SQL:
- You can identify specific issues within large datasets.
- You can analyze multiple categories simultaneously, revealing patterns and trends.
- You can make informed decisions based on clear, actionable insights.
- You can monitor and improve performance across different aspects of your business or product.
By applying these SQL data summarization techniques to your own projects, you can uncover hidden trends, address complex problems, and drive meaningful improvements. Whether you're analyzing user behavior, product performance, or business metrics, these skills will help you extract valuable insights from your data and make informed decisions.