
Tutorial 4:
SQL Subqueries
Have you ever needed to ask a follow-up question to get a complete answer? That's similar to what we do with data using SQL subqueries. I've had the opportunity to work with subqueries extensively, and I've seen how they can greatly simplify complex data analysis tasks. In this post, let's explore the world of subqueries, looking at various types, from simple scalar subqueries to more complex correlated subqueries. We'll also discuss Common Table Expressions (CTEs) and views, powerful SQL techniques that will equip you with the tools to tackle complex data analysis tasks with ease.
Subqueries in SQL are incredibly versatile tools. They're like having a skilled assistant who quickly looks up information for you while you're in the middle of a bigger task. At Dataquest, we use them daily to keep our content in top shape.
I remember when we first started using Common Table Expressions (CTEs), a type of subquery, to tackle our bug-tracking process. It was an eye-opening experience. Suddenly, we could break down our complex problem into smaller, manageable steps. We could gather all the bugs, identify the ones that were taking too long to fix, and group them by status—all within a single query.
One aspect of subqueries that I find particularly useful is how they help us analyze trends over time. For instance, we can now easily track how many bugs we encounter each week, month, or year. This gives us valuable insights into our cWhat are subqueries in SQontent development process and helps us make informed decisions.
You might be wondering how subqueries could be useful in your own work. Well, if you've ever needed to compare data to a summary (like finding all sales above the average), or if you've wanted to filter based on a condition from another table, subqueries are the way to go. They're also great for those "find the top N" type questions that often come up in data analysis.
In tutorial, we're exploring subqueries. Whether you're new to SQL or you're already on this learning journey with us, understanding subqueries will significantly enhance your data analysis skills.
In this tutorial, we'll walk through different types of subqueries, starting with scalar subqueries. These are the simplest form, returning a single value that can be used in the main query. Think of them as the building blocks that will pave the way for more advanced SQL techniques.
So, let's begin our exploration of subqueries by looking at scalar subqueries. They're straightforward but powerful, and they'll set the stage for the more complex subquery types we'll cover later.
Lesson 1 – Scalar Subqueries in SQL

Imagine being able to perform calculations that automatically adapt to changes in your database, eliminating the need to update your calculations manually. This is the magic of the scalar subquery.
A scalar subquery is like a mini-query within a larger query, designed to return a single value that can be used directly in the outer query for comparisons, calculations, or filtering. It performs a quick, on-the-fly calculation and seamlessly integrates the result into your main query, making your code more dynamic and efficient.
Let's look at a real-world example using our Chinook database. Check out this scalar subquery:
SELECT COUNT(*)
FROM invoice;
This subquery calculates the total number of invoices in the invoice table. While it might seem straightforward, it's a perfect illustration of how scalar subqueries can make your queries more dynamic. Instead of hardcoding a value like 614—which represents the current total number of invoices—using a subquery ensures your calculations automatically update as your data changes. Let's see how you can use this approach to keep your queries adaptable.
Now, suppose you want to calculate the percentage of sales for each country. You could do this in two steps, but with a scalar subquery, you can do it all in one go:
SELECT billing_country,
ROUND(COUNT(*)*100.0/
(SELECT COUNT(*)
FROM invoice), 2) AS sales_prop
FROM invoice
GROUP BY billing_country
ORDER BY sales_prop DESC
LIMIT 5;
This query gives you:
| billing_country | sales_prop |
|---|---|
| USA | 21.34 |
| Canada | 12.38 |
| Brazil | 9.93 |
| France | 8.14 |
| Germany | 6.68 |
Here's how it works:
- The subquery
(SELECT COUNT(*) FROM invoice)calculates the total number of invoices. - For each country, you count the number of invoices using
COUNT(*). - You divide this count by the total number of invoices (from the subquery).
- You multiply by 100 to get a percentage and use
ROUND(..., 2)to limit to two decimal places. - The result shows you the proportion of sales for each country.
At Dataquest, we use SQL techniques to analyze our bug tracking system, which helps us identify areas for improvement in our development process. For instance, we regularly use a scalar subquery to investigate our bug resolution efficiency. We use this to determine what percentage of bugs are being addressed within our service level agreement (SLA) of 2 weeks.
Here's a simplified version of the query we use:
SELECT ROUND(
(SELECT COUNT(*)
FROM bugs
WHERE resolution_date - reported_date <= 14) * 100.0 /
(SELECT COUNT(*) FROM bugs), 2) AS sla_compliance_rate
FROM bugs;
This query calculates the percentage of bugs resolved within our 2-week SLA. Here's how it works:
- The inner subquery
(SELECT COUNT(*) FROM bugs WHERE resolution_date - reported_date <= 14)counts the number of bugs resolved within 14 days (2 weeks). - We divide this by the total number of bugs
(SELECT COUNT(*) FROM bugs). - We multiply by 100 to get a percentage and use
ROUND(..., 2)to limit to two decimal places.
The result shows us the total percentage of bugs that are being resolved within the SLA. We use this information to refine our bug triage process, and to direct more resources to fixing bugs when needed.
By regularly running and analyzing queries like this, we've been able to steadily improve our bug resolution efficiency. It's a testament to the power of SQL in driving meaningful changes in our development process.
When using scalar subqueries, keep the following tips in mind:
- Make sure your subquery returns only one value. If it might return multiple rows, you'll need to use an aggregate function like
COUNT,SUM, orAVG. - Experiment with different placements of subqueries in
SELECT,WHERE, andHAVINGclauses. - Be mindful of performance. While subqueries are powerful, they can slow down your query if overused, especially with large datasets.
You're just getting started on your SQL journey—the possibilities are endless! In the next section, we'll build on this knowledge and explore multi-row and multi-column subqueries, which open up even more possibilities for sophisticated data analysis.
You've learned scalar subqueries, and now it's time to explore the powerful tools of multi-row and multi-column subqueries. You'll be able to tackle complex data problems with confidence.
Lesson 2 – Multi-row and Multi-column Subqueries in SQL

Step 1: The original table
Step 2: The original table is aggregated finding the maximum for each country
Step 3: Previous table is aggregated, finding the average of the maxima
Multi-row subqueries return multiple rows of results instead of just one. They're great for comparing values or working with groups.
Let's take a closer look at another example. At Dataquest, we use the Chinook database for many of our SQL lessons. Here's a query I used to count how many tracks in our database use the MPEG format:
SELECT COUNT(*) AS tracks_tally
FROM track
WHERE media_type_id IN (SELECT media_type_id
FROM media_type
WHERE name LIKE '%MPEG%');
This query returned:
| tracks_tally |
|---|
| 3248 |
The subquery returns a list of all MPEG-related media type IDs, and the outer query counts tracks matching these IDs. The IN operator is key here, allowing us to use multiple results in our WHERE clause.
Now that we've covered multi-row subqueries, let's explore multi-column subqueries. While multi-row subqueries return multiple rows of a single column, multi-column subqueries return multiple columns. For example, you might need to identify customers who match specific demographics, such as age and location. By using multi-column subqueries, you can filter and analyze data based on multiple criteria, making it easier to gain insights and make informed decisions.
I often use these in our bug tracking system at Dataquest. For example, to join customer information with their average invoice totals:
SELECT c.last_name, c.first_name, i.total_avg
FROM customer AS c
JOIN (SELECT customer_id, AVG(total) AS total_avg
FROM invoice
GROUP BY customer_id) AS i
ON c.customer_id = i.customer_id;
This query gives us results like:
| last_name | first_name | total_avg |
|---|---|---|
| Gonçalves | Luís | 8.376923 |
| Köhler | Leonie | 7.470000 |
| Tremblay | François | 11.110000 |
| ... | ... | ... |
The subquery returns two columns: customer_id and their average invoice total. We then join this with the customer table to get names alongside average totals. This helps us understand customer behavior and identify high-value customers.
As you start using these techniques, here are a few tips to keep in mind:
- Start with simple queries and work your way up to more complex ones.
- Use aliases to make your queries more readable.
- Test your subqueries separately before using them in larger queries.
- Be mindful of performance, especially with large datasets.
As you practice, you'll become more comfortable using subqueries in your queries.
Now that you've learned multi-row and multi-column subqueries, you're ready to explore even more advanced techniques, including correlated subqueries and the EXISTS operator. These will give you even more ways to analyze your data and uncover valuable insights.
Now that we've explored scalar, multi-row, and multi-column subqueries, it's time to explore more advanced techniques. Let's take a closer look at nested and correlated subqueries—powerful tools that allow us to perform complex data analysis by combining multiple queries in sophisticated ways.
Lesson 3 – Nested and Correlated Subqueries in SQL
A correlated subquery is like having a personal assistant who needs specific information from you to complete their task. It's a subquery that relies on the outer query for its values, running once for each row in the outer query. This enables row-by-row analysis, allowing for more sophisticated data insights.
Unlike regular subqueries that run once for the entire outer query, a correlated subquery runs repeatedly, processing each row individually. While this flexibility comes at the cost of potential performance impacts, especially with large datasets, correlated subqueries can be a powerful tool in your SQL toolkit.
Let's explore a simple example:
SELECT e.first_name, e.last_name, e.salary
FROM employee e
WHERE e.salary > (SELECT AVG(salary) FROM employee WHERE department_id = e.department_id);
This query identifies employees who earn more than the average salary in their department. The subquery calculates the average salary for each department, correlating with the outer query through the department_id column.
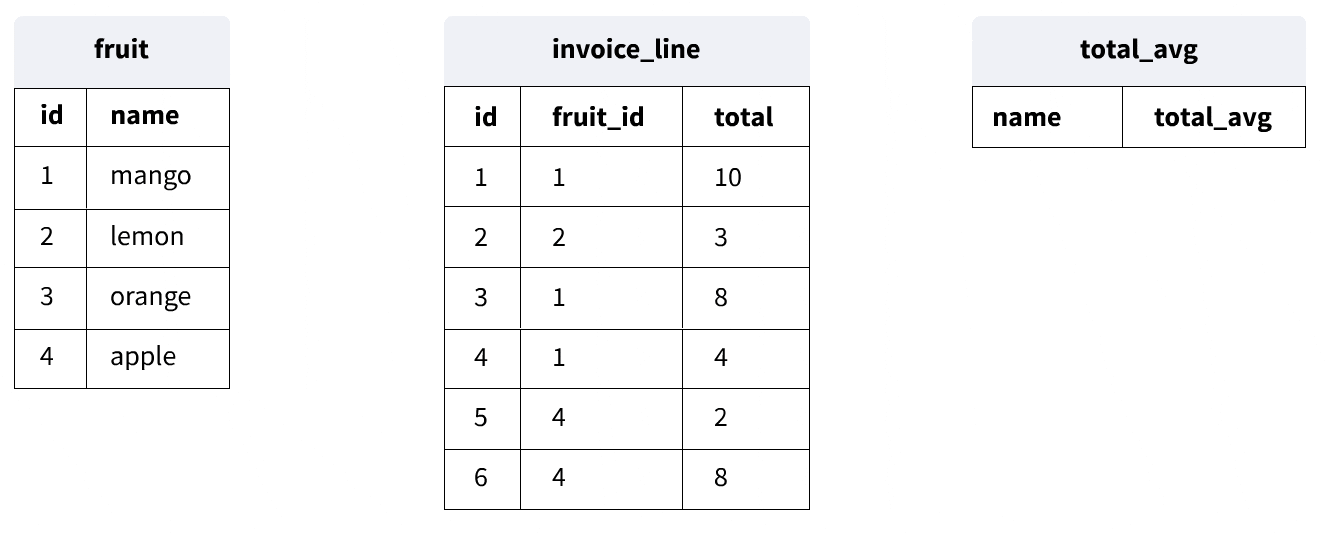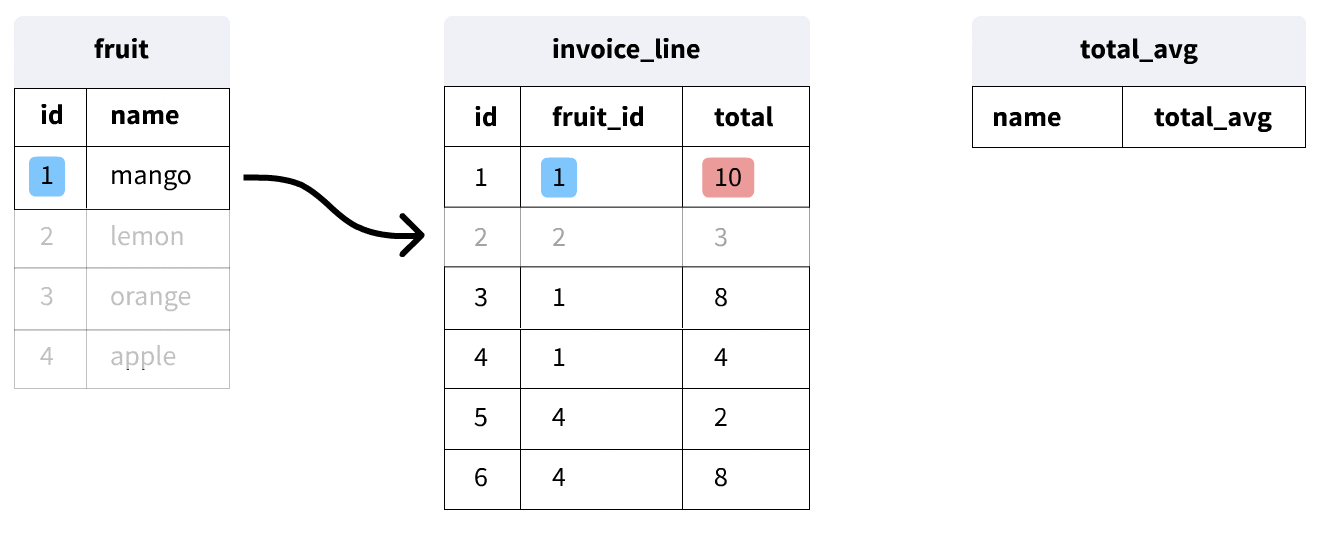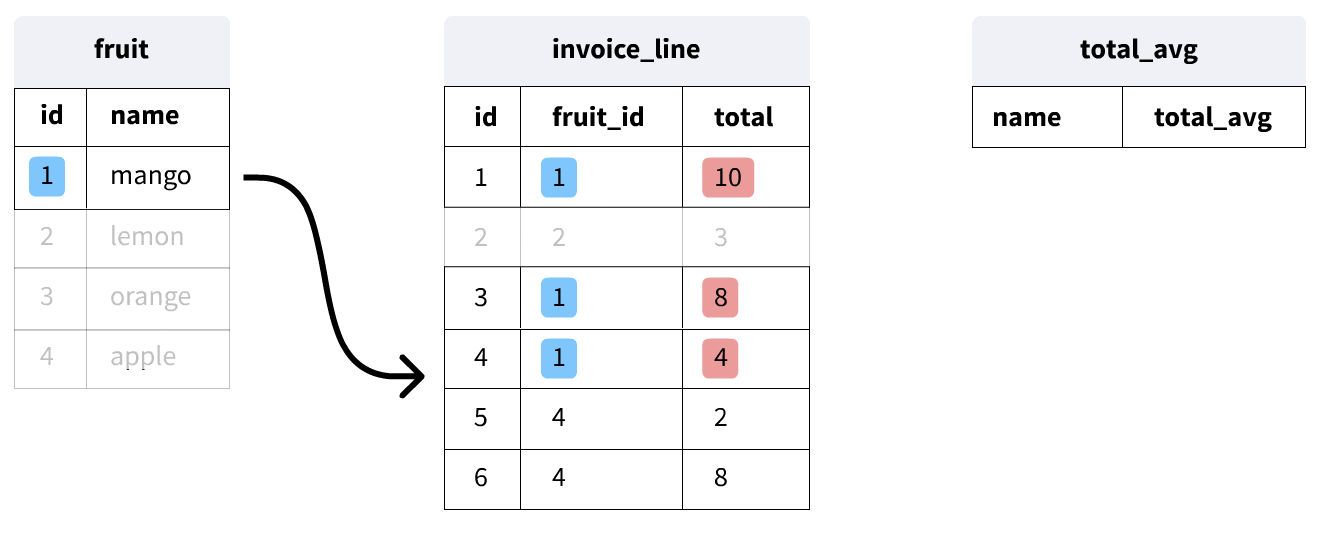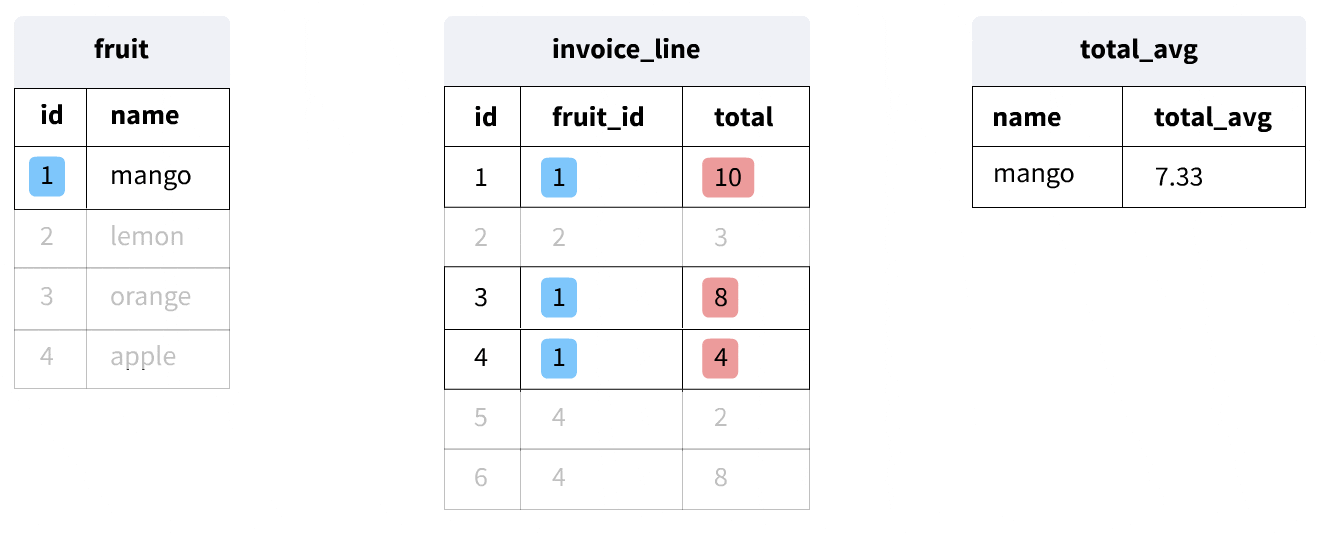
Now, let's look at a more complex example:
SELECT last_name,
first_name,
(SELECT AVG(total)
FROM invoice i
WHERE c.customer_id = i.customer_id) total_avg
FROM customer c;
This query calculates the average total sale for each customer and returns the same results that we saw in our last query. Here's how it works:
- The outer query selects from the customer table.
- For each customer, the inner query (inside the parentheses) calculates the average total from their invoices.
- The inner query uses the
customer_idfrom the current row of the outer query to find the matching invoices.
At Dataquest, I use similar queries to analyze our bug tracking data. For instance, we might want to know the average time it takes each developer to resolve bugs. This helps us identify who might need additional support or who's particularly efficient at squashing bugs.
Another tool that pairs well with correlated subqueries is the EXISTS operator. It's used to check if a subquery returns any rows, acting like a Boolean test. Here's an example:
SELECT first_name, last_name
FROM customer c
WHERE EXISTS(SELECT *
FROM invoice i
WHERE c.customer_id = i.customer_id);
This query finds all customers who have made at least one purchase. The EXISTS operator returns true if the subquery finds any matching rows, and false otherwise. It's particularly useful when you're more interested in the presence or absence of a match rather than the actual data returned. Here's what the results look like:
| first_name | last_name |
|---|---|
| Luís | Gonçalves |
| Leonie | Köhler |
| François | Tremblay |
| ... | ... |
In our work at Dataquest, we use similar queries to identify active users or to find courses that have received feedback. This helps us focus our efforts on engaging with active users and improving popular courses.
Here are some tips to keep in mind when working with these techniques:
- Be mindful of performance: Correlated subqueries can be slow on large datasets because they run for each row in the outer query. Consider alternatives like joins if you're dealing with big data.
- Build your query step by step: It's easier to debug a complex query if you build it piece by piece. Start with the innermost query and work your way out.
- Use clear and descriptive aliases: This makes your queries more readable, especially when you have multiple subqueries.
- Consider your options: Sometimes, a join or a
Common Table Expression (CTE)might be more appropriate than a nested subquery. Always weigh your options. - Test with small datasets: Before running your query on a large dataset, test it with a smaller subset of your data to make sure it's working as expected.
Remember, these advanced SQL techniques are tools to help you uncover insights that might be hidden in your data. They allow you to ask more sophisticated questions and explore your datasets in more detail.
As you practice with nested and correlated subqueries, you'll likely encounter some challenges. Take your time, and don't be afraid to experiment and try new approaches. With practice, you'll develop a deeper understanding of how SQL processes these complex queries.
Now that we've explored various types of subqueries, let's look at an alternative way to structure complex queries: Common Table Expressions.
Lesson 4 – Common Table Expression in SQL

As we continue to explore the world of SQL, let's discover a powerful tool that can make complex queries more manageable and readable: Common Table Expressions (CTEs). I still remember the "aha" moment when I first learned about CTEs—it was like finding a new way to approach complex problems.
So, what are CTEs? Think of them as temporary named result sets that you can reference within a SELECT, INSERT, UPDATE, DELETE, or MERGE statement. They're especially useful when you need to reference the same subquery multiple times in a single statement. Here's a basic example:
WITH city_sales_table AS (
SELECT billing_city, COUNT(*) AS billing_city_tally
FROM invoice
GROUP BY billing_city
)
SELECT AVG(billing_city_tally) AS billing_country_tally_avg
FROM city_sales_table;
This query calculates the average number of sales per billing city. We define the CTE, named 'city_sales_table', and then use it in our main query as if it were a regular table. Here are the results:
| billing_country_tally_avg |
|---|
| 11.584905660377359 |
In real-world scenarios, CTEs can greatly simplify complex queries. At Dataquest, we use CTEs extensively in our bug tracking system. I recall a complex query we needed to write to analyze bug resolution times across different teams. By breaking the query into several CTEs, we made it much easier to understand and maintain. Each CTE represented a logical step in our analysis, from gathering all content bugs to focusing on those outside our service level agreement (SLA). This approach not only made our code more readable but also allowed us to quickly identify bottlenecks in our bug resolution process, leading to a significant improvement in our response times.
But CTEs aren't just for simple queries. They can also be recursive, which is incredibly useful for working with hierarchical data. Recursive CTEs are particularly useful for working with hierarchical or tree-structured data, such as organization charts, bill of materials, or file systems. While powerful, they can be complex, so let's break down this example:
WITH RECURSIVE under_adams_table(employee_id, last_name, first_name, level) AS (
SELECT employee_id, last_name, first_name, 0 AS level
FROM employee
WHERE employee_id = 1
UNION ALL
SELECT e.employee_id,
e.last_name,
e.first_name,
u.level + 1 AS level
FROM employee e
JOIN under_adams_table u
ON e.reports_to = u.employee_id
ORDER BY level
)
SELECT *
FROM under_adams_table;
This recursive CTE starts with Andrew Adams (the top-level employee) and then recursively finds all employees who report to each person in the hierarchy. The 'level' column shows the depth in the reporting structure. Check out the results:
| employee_id | last_name | first_name | level |
|---|---|---|---|
| 1 | Adams | Andrew | 0 |
| 2 | Edwards | Nancy | 1 |
| 6 | Mitchell | Michael | 1 |
| 3 | Peacock | Jane | 2 |
| 4 | Park | Margaret | 2 |
| 5 | Johnson | Steve | 2 |
| 7 | King | Robert | 2 |
| 8 | Callahan | Laura | 2 |
When working with CTEs, keep these tips in mind:
- Choose descriptive names for your CTEs to indicate what data they're providing.
- Keep each CTE focused on a single logical step in your overall query.
- For complex queries, consider breaking them down into multiple CTEs to make them more manageable.
- Remember that CTEs are calculated every time they're referenced, so consider performance for very large datasets.
As you continue to work with SQL, you'll find that CTEs can make your queries more organized and easier to understand. They're a valuable addition to the subquery techniques we've discussed earlier, especially when dealing with complex data analysis tasks.
Lesson 5 – Views in SQL

Remember when we discussed subqueries? Well, I've got something even better to share with you today: views. They're a feature in SQL that I've found really useful in my work, and I think you'll find them useful too.
Think of views as virtual tables created from SELECT statements. They don't store data themselves, but instead offer a specific way to look at data from one or more tables. I use views for two main reasons: they simplify complex queries and enhance data security.
Now, let's explore how views can improve data security. For instance, consider this example:
CREATE VIEW customer_email (
customer_id, first_name, last_name, country, partial_email
) AS
SELECT customer_id, first_name,
last_name, country,
'****' || SUBSTRING(email, 5) AS partial_email
FROM customer;
This view creates a new way to look at our customer data that partially hides email addresses. Instead of giving users direct access to the customer table, we can let them query this view. As a result, they get the information they need, but sensitive data stays protected.
We can now query this view as if it were a table:
SELECT *
FROM customer_email
LIMIT 3;
And here's what we get:
| customer_id | first_name | last_name | country | partial_email |
|---|---|---|---|---|
| 1 | Luís | Gonçalves | Brazil | ****[email protected] |
| 2 | Leonie | Köhler | Germany | ****[email protected] |
| 3 | François | Tremblay | Canada | ****[email protected] |
Views offer several advantages:
- Simplification: They can simplify complex queries, making your database easier to use.
- Security: Views can restrict access to certain columns or rows, enhancing data security.
- Consistency: They ensure that everyone is working with the same definition of the data.
However, views also have some limitations:
- Performance: Views, especially those with complex underlying queries, can sometimes be slower than direct table queries.
- Maintenance: If the underlying tables change, you need to update the view definitions.
Views are particularly useful when you have complex queries that you run frequently, or when you need to provide restricted access to your data. We can also create more complex views that combine data from multiple tables. Here's an example:
CREATE VIEW genres_most_revenue
(genre_name, quantity, revenue) AS
SELECT g.name,
COUNT(i.quantity) AS quantity,
ROUND(SUM(i.unit_price * i.quantity), 2) AS revenue
FROM invoice_line AS i
INNER JOIN track AS t
ON t.track_id = i.track_id
INNER JOIN genre AS g
ON t.genre_id = g.genre_id
GROUP BY g.genre_id
HAVING ROUND(SUM(i.unit_price * i.quantity), 2) > 100
ORDER BY revenue DESC;
This view joins several tables, performs aggregations, and filters the results to show only genres with over $100 in revenue. Once we create this view, we can query it as if it were a table. This saves us from writing this complex query every time we need this information. Let's take a look:
| genre_name | quantity | revenue |
|---|---|---|
| Rock | 2635 | 2608.65 |
| Metal | 619 | 612.81 |
| Alternative & Punk | 492 | 487.08 |
| Latin | 167 | 165.33 |
| R&B/Soul | 159 | 157.41 |
| Blues | 124 | 122.76 |
| Jazz | 121 | 119.79 |
| Alternative | 117 | 115.83 |
At Dataquest, we use views frequently in our bug tracking system. I recall when we first set up a view that combined data from our tasks, users, and projects tables. It allowed us to quickly see which bugs were taking the longest to resolve and who was working on them. This view became a key resource for our weekly team meetings, helping us prioritize our work more effectively.
When working with views, keep the following tips in mind:
- Use views to simplify complex logic that you use frequently.
- Be mindful of performance—views can sometimes be slower than direct table queries, especially for large datasets.
- Update your views when the underlying tables change to keep them accurate.
As you continue learning SQL, I encourage you to try creating your own views. They're a powerful tool for organizing and simplifying your data access. Moreover, understanding views will help you tackle more complex data analysis tasks as we move forward in our challenge. So go ahead, give views a try, and see how they can make your SQL queries more efficient and your data more secure.
Guided Project: Customers and Products Analysis Using SQL
Now that we've explored various SQL techniques, it's time to put your skills to the test with a hands-on project. As someone who's been in your shoes, I can attest to the value of project work in cementing your knowledge and seeing SQL in action.
Imagine you're a data analyst at a model car company, tasked with using SQL to drive business decisions. This project gives you the opportunity to tackle questions like optimizing inventory, tailoring marketing strategies, and determining customer acquisition budgets.
Let's take a closer look at an example query that calculates customer profitability. This query combines JOINs and aggregate functions to calculate each customer's total profit:
SELECT o.customerNumber,
SUM(quantityOrdered * (priceEach - buyPrice)) AS profit
FROM products p
JOIN orderdetails od
ON p.productCode = od.productCode
JOIN orders o
ON o.orderNumber = od.orderNumber
GROUP BY o.customerNumber;
For instance, you might discover the name of our most profitable customer. This kind of insight could shape your customer retention strategies.
When choosing your own project, look for datasets that spark your curiosity. If you're interested in music, try analyzing the Chinook database we've been using. If you love sports, find a dataset with player statistics. The key is to start simple and gradually increase complexity as you gain confidence.
Here are some tips to keep in mind for your project work:
- Start with basic
SELECTqueries to explore your data - Gradually incorporate
JOINs, subqueries, and other advanced techniques - Use CTEs to break down complex problems into manageable steps
- Create views for frequently used query logic
- Don't forget to document your process and findings
By working on projects like this, you're not just practicing SQL – you're developing the analytical thinking that's important in data-related roles. You're learning to uncover insights that could drive real decisions and shape business strategies.
When choosing a project of your own, try to apply as many of the concepts you've learned, so that your SQL knowledge really sticks.
Advice from a SQL Expert
As we conclude our exploration of SQL subqueries, Common Table Expressions (CTEs), and views, I hope you've seen how these tools can enhance your data analysis work. They're not just advanced SQL features—they're practical solutions to everyday problems.
I rely on these techniques daily at Dataquest, and they've greatly improved how I tackle data challenges. The real value of these SQL skills lies in their ability to help you think more critically about your data and ask more insightful questions. When you can combine data from multiple tables or create dynamic reports that automatically filter for specific conditions, you can gain new insights and make more informed decisions.
If you're feeling inspired to take your SQL skills further, I encourage you to keep practicing. Try writing a subquery to answer a question about your own data. Experiment with CTEs to break down a complex problem into steps. The more you practice, the more intuitive these techniques will become. And if you're looking for structured guidance, our SQL Subqueries course is an excellent next step. It builds on the concepts we've covered here, with hands-on practice using real-world scenarios. If you're looking to learn even more, our SQL Fundamentals path covers everything from the basics to advanced techniques.
Remember, learning SQL is a continuous process. Each new skill you learn is a tool you can use to solve problems and uncover insights. So keep exploring, keep questioning, and keep pushing yourself. Whether you're tracking bugs, analyzing customer behavior, or tackling any other data challenge, your growing SQL skills will serve you well.
Frequently Asked Questions
What are subqueries in SQL and how can they improve my data analysis?
Subqueries in SQL are a powerful tool that allows you to nest one query within another, enabling more complex and insightful data analysis. Think of them as a way to ask a question within a question, helping you to extract more meaningful information from your data.
Subqueries can significantly enhance your data analysis capabilities by:
- Comparing individual values to aggregates (e.g., finding sales above the average)
- Applying sophisticated filtering conditions
- Performing calculations using results from other queries
- Analyzing data across multiple dimensions simultaneously
There are several types of subqueries in SQL:
- Scalar subqueries return a single value. For example, you might use one to calculate the average track length in a music database.
- Multi-row subqueries return multiple rows of results. These are useful for operations like finding all tracks that use a specific media format.
- Multi-column subqueries return multiple columns, allowing for more complex data comparisons.
Here's an example of a scalar subquery that calculates the percentage of sales for each country:
SELECT billing_country,
ROUND(COUNT(*) * 100.0 /
(SELECT COUNT(*)
FROM invoice), 2) AS sales_prop
FROM invoice
GROUP BY billing_country
ORDER BY sales_prop DESC
LIMIT 5;
In real-world applications, subqueries in SQL can help analyze bug resolution efficiency in software development, identify high-value customers in sales data, or calculate average course completion rates in online learning platforms.
When working with subqueries, it's essential to keep in mind that they can impact query performance on large datasets. To avoid this, start with simple queries and gradually increase complexity as you become more comfortable with the technique.
By using subqueries in SQL, you can uncover deeper insights from your data, enabling more informed decision-making across various business contexts. Whether you're analyzing sales figures, user behavior, or system performance, subqueries provide the flexibility to extract valuable information and drive smarter business strategies.
What are some effective strategies for learning and practicing subqueries in SQL?
Subqueries in SQL can be a powerful tool to help you extract insights from your data. To get the most out of them, consider the following strategies:
- Start with simple subqueries: Begin by learning subqueries that return a single value. This will help you build a strong foundation for understanding more complex types.
- Use real-world data: Practice with actual datasets to make your learning more relevant and engaging. This will help you see how subqueries can be applied in real-world scenarios.
- Gradually increase complexity: As you become more comfortable with simple subqueries, try more advanced ones, such as subqueries that return multiple rows or columns. This step-by-step approach will help you solidify your understanding.
- Experiment with different clauses: Try placing subqueries in various clauses, such as
SELECT,WHERE, andHAVING. This will help you understand how to use subqueries in different contexts. - Analyze existing queries: Study and break down complex queries that use subqueries. This will help you understand how experienced SQL users apply these techniques.
For example, let's say you want to calculate the percentage of sales for each country. You can use a subquery to calculate the total number of invoices, which can then be used to calculate the percentage of sales for each country.
SELECT billing_country,
ROUND(COUNT(*) * 100.0 /
(SELECT COUNT(*)
FROM invoice), 2) AS sales_prop
FROM invoice
GROUP BY billing_country
ORDER BY sales_prop DESC
LIMIT 5;
This query uses a subquery to calculate the total number of invoices, which is then used to calculate the percentage of sales for each country. It demonstrates how subqueries can perform complex calculations within a larger query.
In real-world applications, subqueries in SQL can help analyze bug resolution efficiency in software development. For instance, you could use a subquery to calculate the percentage of bugs resolved within a specific timeframe, helping to identify areas for improvement in the development process.
Remember, the key to becoming proficient in subqueries is to practice regularly. Start with simple queries, experiment with different types, and gradually tackle more complex problems. As you become more comfortable with subqueries in SQL, you'll be able to extract deeper insights from your data, enabling more informed decision-making across various business contexts.
How do subqueries differ from joins, and when should I use each in my SQL queries?
When working with data from multiple tables, you have two powerful techniques at your disposal: subqueries and joins. While they share some similarities, they serve different purposes and are best suited for different scenarios.
Subqueries are essentially nested queries within a larger query. They can return a single value, multiple rows, or multiple columns, and are often used in SELECT, FROM, or WHERE clauses. Subqueries are particularly useful when you need to:
- Compare individual values to aggregated results (e.g., finding sales above the average)
- Apply complex filtering conditions
- Perform calculations using results from other queries
- Analyze data across multiple dimensions simultaneously
For example, you might use a subquery to find tracks longer than the average length or to calculate the percentage of sales for each country.
On the other hand, joins combine rows from two or more tables based on a related column between them. They're preferable when you need to:
- Combine data from multiple tables into a single result set
- Perform operations on related data across tables
- Create more readable queries for complex data relationships
- Analyze relationships between entities (e.g., customers and their orders)
An example of a join might be combining customer information with their average invoice totals.
So, how do you decide between subqueries and joins? Consider the following factors:
- Query complexity: Subqueries can make complex queries more readable by breaking them into smaller parts.
- Performance: Joins are often more efficient for large datasets, while subqueries can be slower if not optimized properly.
- Data relationships: Joins are typically better for one-to-many or many-to-many relationships.
- Aggregation needs: Subqueries excel at comparing individual values to aggregated results.
In practice, many queries can be written using either technique. The choice often comes down to personal preference, query readability, and specific performance considerations for your database system. As you gain experience with both subqueries and joins, you'll develop a better intuition for when to use each technique to solve complex data problems efficiently.
Can you provide examples of real-world scenarios where subqueries are particularly useful?
Subqueries in SQL can be incredibly helpful in a variety of real-world situations, allowing businesses to gain deeper insights from their data. Here are some practical examples:
- Customer Profitability Analysis: Subqueries can help identify high-value customers by comparing individual purchase amounts to overall averages. For instance, a retail company might use a subquery to find customers whose average purchase exceeds the company-wide average, allowing for targeted marketing strategies.
- Inventory Optimization: In a model car company, subqueries can analyze product performance by comparing sales of individual items to category averages. This insight helps businesses make informed decisions about stock levels and product offerings, potentially reducing costs and improving sales.
- Bug Tracking Efficiency: Software development teams can use subqueries to improve their bug resolution process. For example:
- Sales Performance Analysis: Subqueries can calculate the percentage of sales for each country, providing valuable insights for market expansion and resource allocation. For instance, a query might reveal that the USA accounts for 21.34% of sales, followed by Canada at 12.38%, guiding decisions on where to focus marketing efforts or expand operations.
- Employee Performance Evaluation: Human resources departments can use subqueries to compare individual employee performance against department averages, helping to identify top performers or those who might need additional support.
SELECT ROUND(
(SELECT COUNT(*)
FROM bugs
WHERE resolution_date - reported_date <= 14) * 100.0 /
(SELECT COUNT(*) FROM bugs), 2) AS sla_compliance_rate
FROM bugs;
This query calculates the percentage of bugs resolved within a 2-week service level agreement (SLA). The inner subquery counts bugs resolved within 14 days, while the outer subquery provides the total bug count. This information helps teams identify areas for improvement in their development process.
When using subqueries in SQL for these scenarios, it's essential to consider performance implications, especially with large datasets. Start with simple queries and gradually increase complexity as you become more comfortable with the technique.
Subqueries in SQL offer a flexible approach to data analysis, allowing businesses to ask more sophisticated questions of their data. By using subqueries, you can gain a deeper understanding of your customers, optimize your inventory, improve your development process, and evaluate market performance. This can lead to more informed decision-making across various business contexts.
What is the difference between scalar subqueries and multi-row subqueries in SQL?
Subqueries in SQL are powerful tools that allow you to nest one query within another, enabling more complex and insightful data analysis. To get the most out of subqueries, it's essential to understand the difference between scalar and multi-row subqueries.
Scalar subqueries return a single value (one row and one column) that can be used in the outer query for comparison, calculation, or filtering. Think of them as a mini-query that performs a quick calculation for you. For example:
SELECT track_name, milliseconds
FROM track
WHERE milliseconds > (SELECT AVG(milliseconds) FROM track);This query uses a scalar subquery to find tracks longer than the average track length. Scalar subqueries are particularly useful for calculations like finding above-average values or percentages.
On the other hand, multi-row subqueries return multiple rows of results. They're great for comparing values or working with groups of data. Here's an example:
SELECT COUNT(*) AS tracks_tally
FROM track
WHERE media_type_id IN (SELECT media_type_id
FROM media_type
WHERE name LIKE '%MPEG%');This query uses a multi-row subquery to count tracks that use MPEG format. Multi-row subqueries excel in scenarios like filtering based on multiple criteria or working with hierarchical data.
So, what are the key differences between scalar and multi-row subqueries?
- Output: Scalar subqueries return a single value, while multi-row subqueries return multiple rows.
- Usage: Scalar subqueries are often used in
SELECT,WHERE, orHAVINGclauses for single value comparisons. Multi-row subqueries are typically used with operators likeIN,ANY, orALLfor multiple value comparisons. - Performance: Scalar subqueries can be more efficient for single value lookups, while multi-row subqueries are better for operations involving lists or sets of data.
In real-world applications, you might use a scalar subquery to calculate the percentage of sales for each country. Multi-row subqueries could be used in more complex scenarios, such as analyzing bug resolution times across different teams or identifying customers who have made purchases.
By understanding the strengths of each type of subquery, you can write more efficient and effective SQL queries, leading to better decision-making and more sophisticated data analysis.
What are some common pitfalls when working with subqueries, and how can I avoid them?
When working with subqueries in SQL, you may encounter some challenges that can be tricky to overcome, even for experienced data analysts. Let's take a closer look at some common pitfalls and how to avoid them:
- Performance slowdowns: Subqueries, especially correlated ones, can be resource-intensive on large datasets. For example, a query analyzing bug resolution times across different teams might run slowly if not optimized. To address this, consider using joins or Common Table Expressions (CTEs) as alternatives when dealing with big data.
- Misplaced subqueries: Putting a subquery in the wrong clause can lead to unexpected results or errors. Make sure you're using the right type of subquery (scalar, multi-row, or multi-column) in the appropriate clause (
SELECT,FROM,WHERE, etc.). For instance, a scalar subquery works well in aSELECTclause, while a multi-row subquery is better suited for aWHEREclause withINoperators. - Scalar subquery returning multiple rows: Scalar subqueries should return only one value. If you're calculating an average or count, ensure your subquery doesn't accidentally return multiple rows. Use aggregate functions like
AVG,COUNT, orMAXto ensure a single result. - Forgetting to correlate subqueries: In correlated subqueries, it's essential to reference the outer query. Here's an example that calculates the average invoice total for each customer:
- Overcomplicating queries: Nesting multiple subqueries can make your code hard to read and maintain. Instead, consider using CTEs to break down complex logic into manageable steps. This approach can make your queries more readable and easier to troubleshoot.
SELECT last_name, first_name,
(SELECT AVG(total)
FROM invoice i
WHERE c.customer_id = i.customer_id) AS total_avg
FROM customer c;
To avoid these pitfalls:
- Start with simple subqueries and gradually increase complexity as you become more comfortable with them.
- Test your subqueries independently before incorporating them into larger queries.
- Use clear and descriptive aliases to make your queries more readable.
- Be mindful of performance, especially when working with large datasets. Consider using
EXPLAIN PLANor similar tools to analyze query performance. - Explore alternatives like CTEs or views for complex logic. These can often simplify your queries and improve readability.
By being aware of these common pitfalls and actively working to avoid them, you'll be able to write more efficient, readable, and powerful SQL queries. With practice and experience, you'll become more confident in your ability to work with subqueries and tackle complex data challenges.
How do Common Table Expressions (CTEs) complement subqueries in SQL, and when should I use each?
In SQL, both Common Table Expressions (CTEs) and subqueries are useful for analyzing data. However, they serve distinct purposes. A subquery is a nested query within a larger query, returning a single value, multiple rows, or multiple columns.
On the other hand, a CTE is a temporary named result set that you can reference multiple times within a statement. This can be particularly helpful when you need to use the same subquery multiple times or work with hierarchical data.
One key advantage of CTEs is that they can simplify complex queries, making them easier to understand and work with. For example, if you need to calculate the average number of sales per billing city, a CTE can break down the query into more manageable parts. In contrast, subqueries are often better suited for simpler operations or when you only need to use the result once.
So, how do you decide between CTEs and subqueries in SQL? Consider the complexity of your query and how often you'll need to reference the result. If you're dealing with a complex query that requires multiple references or recursive operations, a CTE might be the way to go. For simpler calculations, a subquery could be a more straightforward choice. By understanding when to use each, you'll become more proficient in your ability to analyze data with SQL.
What are SQL views, and how can they help simplify complex queries involving subqueries?
SQL views are virtual tables that simplify complex queries and enhance data security. By encapsulating query logic into reusable objects, views allow you to treat them like regular tables, making it easier to work with subqueries and intricate joins.
Views offer several advantages:
- They simplify complex queries by breaking them down into manageable pieces.
- They enhance data security by controlling access to sensitive information, such as specific columns or rows.
- They ensure consistency in data interpretation across different users.
For instance, consider a view that masks email addresses for improved data security:
CREATE VIEW customer_email (
customer_id, first_name, last_name, country, partial_email
) AS
SELECT customer_id, first_name,
last_name, country,
'****' || SUBSTRING(email, 5) AS partial_email
FROM customer;
This view can be queried like a regular table, providing only the masked email addresses to users who don't need full access to customer data. This approach demonstrates how views can help simplify complex queries and improve data security.
Views complement subqueries by providing a way to store and reuse complex query logic. Unlike subqueries, which are nested within a larger query, views persist in the database and can be accessed by multiple users. This makes them ideal for frequently used complex queries.
When working with views, keep the following best practices in mind:
- Use views to simplify frequently used complex logic, making it easier to maintain and update.
- Be aware that views can sometimes be slower than direct table queries, so use them judiciously.
- Update views when underlying tables change to ensure accuracy and consistency.
In practice, views can significantly improve data analysis workflows. They enable analysts to create pre-filtered datasets, implement complex business logic consistently across queries, and provide controlled access to sensitive data. By using views effectively, you can streamline your SQL queries, enhance data security, and make your database more user-friendly for your entire team.
How do subqueries fit into the broader landscape of SQL skills for data analysis?
Subqueries play a significant role in the world of data analysis. By nesting one query within another, you can explore data more thoroughly and gain deeper insights. Subqueries complement other techniques like joins, Common Table Expressions (CTEs), and views, providing a versatile toolkit for tackling various data challenges.
Subqueries offer several key benefits in data analysis:
- They enable sophisticated filtering and comparisons.
- They allow for calculations using results from other queries.
- They facilitate analysis across multiple dimensions simultaneously.
There are different types of subqueries in SQL, each serving specific purposes:
- Scalar subqueries return a single value, useful for comparisons or calculations. For instance, you can use a scalar subquery to find tracks longer than the average length in a music database.
- Multi-row subqueries return multiple rows, ideal for filtering based on lists of values. These are great for operations like finding all tracks that use a specific media format.
- Correlated subqueries reference the outer query, allowing for row-by-row analysis. These are particularly useful for comparing individual values to group averages.
Real-world applications of subqueries in SQL are numerous. For example, a model car company might use subqueries to calculate the percentage of sales for each country, helping inform decisions about market expansion and resource allocation. Other applications include analyzing customer profitability, optimizing inventory, and evaluating employee performance.
While subqueries can be powerful tools, they can also present challenges, particularly with large datasets. It's essential to consider performance implications and sometimes explore alternatives like joins or CTEs for complex queries.
As you develop your SQL skills, becoming proficient in subqueries will enable you to tackle increasingly complex data analysis tasks. By incorporating subqueries into your toolkit, you'll be better equipped to uncover deeper insights from your data and drive informed decision-making in various business contexts.