NLP Project Part 2: How to Clean and Prepare Data for Analysis
This is the second in a series of posts describing my natural language processing (NLP) project. To really benefit from this NLP article, you should read the first post, understand how to use pandas to work with text data, and be aware of list comprehensions and lambda functions. We're also going to write a few functions and import a lot of packages and tools. It's worth familiarizing yourself with those concepts before you continue.
The main purpose of this post is to analyze the responses that learners are receiving on the Dataquest Community. Dataquest encourages learners to publish their guided projects on their forum. After publishing a project, other learners or staff members can share their opinions of the project. We're interested in the content of those opinions.
In the first post, we learned how to perform web scraping using Beautiful Soup. We gathered the data from Dataquest's forum pages and organized it in a pandas DataFrame:
- We extracted the title, link to the post, number of replies, and number of views of each post
- We also scraped the post's website — specifically, we targeted the first reply to the post
This is where we'll continue our work. In this post, we'll clean and analyze the text data. We'll start small: cleaning and organizing the title data, then we'll perform some data analysis for each title's numeric information (views, replies). We're mostly going to show the potential and quickly move on.
Next, we'll process and analyze the feedback posts. We'll use various NLP techniques to analyze the content of the feedback:
- Tokenization
- N-grams
- Part of Speech tagging
- Chunking
- Lemmatization
We'll use all of the techniques mentioned above. Our main goal is to understand what feedback is being provided. We're specifically interested in the technical advice regarding our projects. Instead of sentiment analysis, we're more interested in what technical remarks are most common.
You can find this project's folder on my Github. All the files are already within that folder, so if you want to play around with the data without scraping it, you can just download the dataset. Notebooks are also available. If you have any questions, feel free to reach out and ask me anything: Dataquest, LinkedIn.
Part 1: The Title Problem — Everybody Wants a Different Title
We're all guilty: we want to publish our project and gain attention. What's the easiest way to get at least some amount of attention? Think of an interesting and original title! So now when someone wants to group all the posts by their titles. We get 1,102 results, because there are 1,102 different titles. We know that the number of different projects is closer to 20 or 30. So let's try to group those posts by their content.
Lowercase, Punctuation, and Stopwords
Before we move on to some cleaning duties, let's establish a simple fact:
'ebay' == 'Ebay'Output
FalseAs demonstrated above, Python is a case-sensitive language — "e" is not the same as "E." That is why one of the first steps in cleaning string data is to convert all the words to lowercase:
df['title'] = df['title'].str.lower()Now let's move on to removing the punctuation; we'll create a simple function and apply it to every "title" cell:
import string
# create function for punctuation removal:
def remove_punctuations(text):
for char in string.punctuation:
text = text.replace(char, '')
return text
# apply the function:
df['title'] = df['title'].apply(remove_punctuations)Notice how we've imported a list of punctuation signs from "string" package instead of creating a list and filling it manually with all those signs. We're going to use this method more frequently because it's faster and easier.
The above approach is an easy-to-understand function, but it isn't the most efficient method. If your dataset is very large, you should check Stack Overflow for a better solution.
Stopwords
Last but not least, we're going to remove the stopwords. What are stopwords? If we just ask a search engine, we should receive an answer for a dictionary:
stopword — a word that is automatically omitted from a computer-generated concordance or index.
Definitions from Oxford Languages
There's a lot of "the," "in," "I," and other words that make our titles grammatically correct but very often don't serve any other purpose.
Let's check one of the titles for a removal example:
# import list of stopwords:
from nltk.corpus import stopwords
stop = stopwords.words('english')
# remove stopwords from the below example:
example1 = 'guided project visualizing the gender gap in college degrees'
' '.join([word for word in example1.split() if word not in stop])Output
'guided project visualizing gender gap college degrees'We've removed the stopwords, yet the content is still easy to understand. It's worth mentioning that sometimes removing stopwords isn't the best idea.
We can apply the above method to all the "title" cells, but before we do that, we want to add a few words of our choosing to that list. We know that many of the titles contain words like "project," "feedback," etc. They don't give us any information about the contents of the post, so we should remove them:
# add more words to stopwords list:
guided_list = ['guided', 'project', 'feedback']
stop_extended = stop + guided_list
# create a column without the stopwords:
df['title_nostop'] = df['title'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop_extended]))Let's check how many unique titles we have after those initial few steps:
len(df['title_nostop'].unique())Output
927That's still a very large number, compared to the expected 20-30 titles. We're going to have to get creative!
Using the tag number
df['content'][1]Output
<tr class="topic-list-item category-share-guided-project tag-python tag-pandas tag-469 tag-data-analysis-business tag-469-11 has-excerpt ember-view" data-topic-id="558226" id="ember77">\n<td class="main-link clearfix" colspan="">\n<div class="topic-details">\n<div class="topic-title">\n<span class="link-top-line">\n<a class="title raw-link raw-topic-link" data-topic-id="558226" href="https://community.dataquest.io/t/re-upload-project-feedback-popular-data-science-questions/558226/2" level="2" role="heading"><span dir="ltr">[Re-upload]Project Feedback - Popular Data Science Questions</span></a>\n<span class="topic-post-badges"></span>\n</span>\n</div>\n<div class="discourse-tags"><a class="discourse-tag bullet" data-tag-name="python" href="https://community.dataquest.io/tag/python">python</a> <a class="discourse-tag bullet" data-tag-name="pandas" href="https://community.dataquest.io/tag/pandas">pandas</a> <a class="discourse-tag bullet" data-tag-name="469" href="https://community.dataquest.io/tag/469">469</a> <a class="discourse-tag bullet" data-tag-name="data-analysis-business" href="https://community.dataquest.io/tag/data-analysis-business">data-analysis-business</a> <a class="discourse-tag bullet" data-tag-name="469-11" href="https://community.dataquest.io/tag/469-11">469-11</a> </div>\n<div class="actions-and-meta-data">\n</div>\n</div></td>\n<td class="posters">\n<a class="" data-user-card="kevindarley2024" href="https://community.dataquest.io/u/kevindarley2024"><img alt="" aria-label="kevindarley2024 - Original Poster" class="avatar" height="25" src="./Latest Share_Guided Project topics - Dataquest Community_files/50(1).png" title="kevindarley2024 - Original Poster" width="25"/></a>\n<a class="latest" data-user-card="jesmaxavier" href="https://community.dataquest.io/u/jesmaxavier"><img alt="" aria-label="jesmaxavier - Most Recent Poster" class="avatar latest" height="25" src="./Latest Share_Guided Project topics - Dataquest Community_files/50(2).png" title="jesmaxavier - Most Recent Poster" width="25"/></a>\n</td>\n<td class="num posts-map posts" title="This topic has 3 replies">\n<button class="btn-link posts-map badge-posts">\n<span aria-label="This topic has 3 replies" class="number">3</span>\n</button>\n</td>\n<td class="num likes">\n</td>\n<td class="num views"><span class="number" title="this topic has been viewed 47 times">47</span></td>\n<td class="num age activity" title="First post: Nov 14, 2021 2:57 am\nPosted: Nov 18, 2021 6:38 pm">\n<a class="post-activity" href="https://community.dataquest.io/t/re-upload-project-feedback-popular-data-science-questions/558226/4"><span class="relative-date" data-format="tiny" data-time="1637221085326">3d</span></a>\n</td>\n</tr>Every lesson with a guided project has a unique number. Most of the published projects are tagged with those numbers. Using that knowledge, we can extract the tag numbers whenever it's possible:
df['tag'] = df['content'].str.extract('data-tag-name="(\d+)" href')Now, let's check how many posts were tagged with a lesson number:
df['tag'].value_counts().sum()Output
700700 out of 1,102 posts have been tagged with the lesson number; now we have to fill out the missing ones. Here's how we're going to solve this problem:
- Check the most common word occurring in the title for each lesson number
- If the word occurs more than once, or is not related to the project content, remove it from all titles
- Loop trough the top 25 (can be adjusted to a different number) tags, for each tag, do the following:
- Check the most common word for that tag
- Select the rows with the title containing the most common word and "tag" value empty
- Assign the current tag to those rows
Step 1. Check the most common word for each tag
from collections import Counter
for a_tag in df['tag'].value_counts()[:25].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(1)[0][0]
print(a_tag,top_word)Output
294 ebay
356 hacker
350 app
257 cia
146 college
348 exit
149 gender
201 wars
217 nyc
191 sql
524 traffic
469 data
155 car
310 best
288 fandango
529 exchange
65 stock
213 predicting
240 predicting
210 jeopardy
382 lottery
544 sql
244 building
505 covid19
433 spam
Step 2: Remove recurring words
Most of the above keywords point to lessons that we've all had to endure. But "best" or "data" doesn't really give us any information about the project. On top of that, two different tags have the same word ("predicting") as the most common word. Let's remove those words:
more_stop = ['predicting','best','analyzing','data','exploring']
df['title_nostop'] = df['title_nostop'].apply(lambda x: ' '.join([word for word in x.split() if word not in (more_stop)]))
for a_tag in df['tag'].value_counts()[:25].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(1)[0][0]
print(a_tag,top_word)Step 3: Loop trough the tag numbers
for a_tag in df['tag'].value_counts()[:25].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(1)[0][0]
df.loc[(df['title_nostop'].str.contains(top_word)) & df['tag'].isnull(), 'tag'] = a_tag
df[df['tag'].isnull()].shapeThe "car" issue
You may have noticed that tag 155's most common word is car; unfortunately, that word can be very common among eBay projects. Here's a quick fix to the problem of assigning incorrect tag numbers to incorrect projects:
df.loc[(df['title_nostop'].str.contains('german')) & (df['tag']=='155'),'tag'] = '294'
df[df['tag'].isnull()].shapeOutput
(59, 8)We can remove 59 rows to get a consistent dataset; while we're doing that, let's remove the original "title" column:
df = df[~(df['tag'].isnull())].copy()
df = df.drop(columns='title')Ok, so we have a dataset where each row has an assigned lesson number, but to perform further analysis, we don't want to rely on those numbers too much. After all, "294" doesn't tell us much, but "ebay" already gives us a clue about the project. But one word is sometimes not enough, so let's check the most common two words for each lesson number and create a column for them. Sometimes that combination isn't going to be in the desired order, but it will clearly point to the topic of the project.
There's one catch: we can only do that with the first 29 lesson numbers; the rest of them occur only once, so we can't check for the most common words if the title occurs only once in the dataset.
# create empty dictionary and a column filled with '0's
pop_tags = {}
df['short_title'] = None
# loop trough first 29 tags and extract 2 most common words, merge them into 1 string and store it in a dictionary:
for a_tag in df['tag'].value_counts()[:29].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(2)[0][0]
top_word2 = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(2)[1][0]
pop_tags[a_tag] = top_word+' '+top_word2Now, that we have a dictionary filled with the two most common words for every lesson number, let's assign them to every row:
for a_tag in df['tag'].value_counts()[:29].index:
df.loc[df['tag']==a_tag, 'short_title'] = pop_tags[a_tag]Let's check the 10 most popular short titles:
df['short_title'].value_counts()[:10]Output
| news hacker | 163 |
| ebay car | 155 |
| app profitbale | 138 |
| college visualizing | 87 |
| cia factbook | 81 |
| exit employee | 68 |
| wars star | 48 |
| gender gap | 43 |
| nyc high | 42 |
| sql using | 38 |
| Name: short_title | dtype: int64 |
Part 2: the EDA Potential
"wars star" is not a catchy name for a space opera, but we can recognize a familiar topic. Now that we can categorize each unique title to a specific project, we can start analyzing the dataset. Which project had the highest number of posts?
import matplotlib.pyplot as plt
# group the dataset by project title:
plot_index = df.groupby('short_title')['views'].sum().sort_values()[-15:].index
plot_counts = df.groupby('short_title')['views'].count().sort_values()[-15:].values
# create a plot:
fig, ax = plt.subplots(figsize=(16,12))
plt.barh(plot_index,plot_counts, label='number of posts')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.set_xlabel('Number of posts')
plt.title('Number of posts for each project',fontsize=22,pad=24)
plt.show()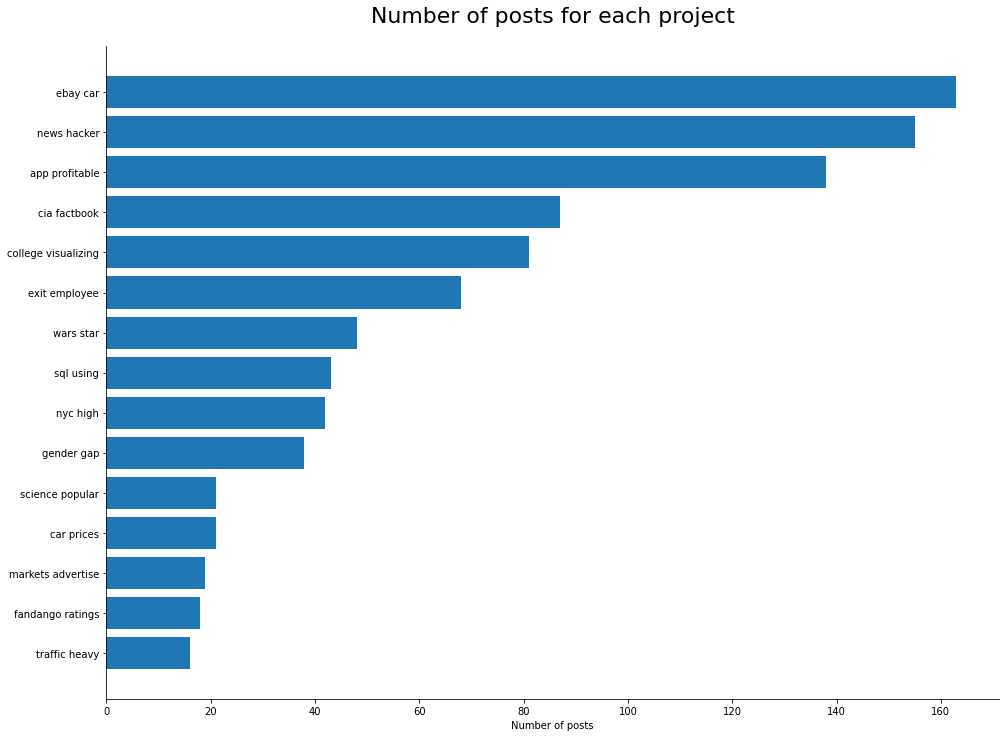
This is just one of many possible plots we can generate using the current dataset; here are a few ideas for more plots:
- Average number of views for each project
- Average number of replies for each project
- Proportion of views/numbers of posts
We can also continue extracting data from the original chunk of HTML that we scraped — we can still extract dates and track the popularity of topics across time.
Another potential approach is to categorize the projects into different skill levels and track all the metrics based on the difficulty of the project.
Before we do any of the above, we should organize the titles and make sure the order of words is logical so we don't get any more "wars star" cases.
We could do all of that and more, but this isn't the time or place to do so. This post is about NLP techniques, and we haven't covered them thoroughly yet. That's why we'll skip the exploratory data analysis of numeric data and move on to part 3.
Part 3: Feedback Analysis Using NLP Techniques
Cleaning Text Data
df['feedback'][0]Output
\nprocessing data inside a function saves memory (the variables you create stay inside the function and are not stored in memory, when you’re done with the function) it’s important when you’re working with larger datasets - if you’re interested with experimenting:\nhttps://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page\nTry cleaning 1 month of this dataset on kaggle notebook (and look at your RAM usage) outside the function and inside the function, compare the RAM usage in both examples\nLet's start with removing the unnecessary HTML code and lowercasing all letters. In the next step, we'll expand all the contractions (expand "don't" into "do not" etc.) — we'll use a handy contractions package for that. After that, we'll remove the punctuation and store the results in a new column. Why? Removing punctuation stops us from recognizing sentences, and we will want to analyze individual sentences. That's why we want to keep both options: strings with and without punctuation. Going further, we'll remove stopwords and the 10 most frequently occurring words.
import contractions
# remove '\n' and punctuation, lowercase all letters
df['feedback'] = df['feedback'].str.replace('\n',' ').str.lower()
# expand contractions
df['feedback'] = df['feedback'].apply(lambda x: contractions.fix(x))
# remove punctuations
df['feedback_clean'] = df['feedback'].apply(remove_punctuations)
# remove stopwords
df['feedback_clean'] = df['feedback_clean'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
# check 10 most common words:
freq10 = pd.Series(' '.join(df['feedback_clean']).split()).value_counts()[:10]
# remove 10 most common words:
df['feedback_clean2'] = df['feedback_clean'].apply(lambda x: ' '.join([word for word in x.split() if word not in (freq10)]))Most Popular Words
We've cleaned the data. We have it stored in a few columns depending on intensity of cleaning the text. Now we can start some analysis. Let's start with something very simple: checking the most popular words.
Remember that we haven't removed the stopwords from the "feedback" column. We won't check it — the most popular words from that column will be stopwords. Knowing how many occurrences of "the," "to," or "you" are in the text won't give us any idea about the content. Instead, we're going to check "feedback_clean" and "feedback_clean2":
from collections import Counter
# function for checking popular words:
def popular_words(series):
df['temp_list'] = series.apply(lambda x:str(x).split())
top = Counter([item for sublist in df['temp_list'] for item in sublist])
temp = pd.DataFrame(top.most_common(10))
temp.columns = ['Common_words','count']
return temp
popular_words(df['feedback_clean'])Output
| Common_words | count | |
|---|---|---|
| 0 | project | 2239 |
| 1 | code | 1140 |
| 2 | good | 721 |
| 3 | like | 551 |
| 4 | would | 544 |
| 5 | sharing | 525 |
| 6 | hi | 522 |
| 7 | also | 521 |
| 8 | well | 494 |
| 9 | work | 435 |
popular_words(df['feedback_clean2'])Output
| Common_words | count | |
|---|---|---|
| 0 | data | 434 |
| 1 | thanks | 421 |
| 2 | great | 394 |
| 3 | use | 389 |
| 4 | better | 385 |
| 5 | cell | 368 |
| 6 | happy | 361 |
| 7 | community | 353 |
| 8 | comments | 347 |
| 9 | conclusion | 343 |
We could continue the process of eliminating words that don't give us any important information ("thanks," "great," "happy") or try a different approach. But before we do that, let's learn how to tokenize the text.
Tokenization
Many NLP techniques require an input of tokenized strings. What is tokenization? In essence, it's splitting a string into smaller units (tokens). The most common method is word tokenizing. Here's a simple example:
from nltk.tokenize import word_tokenize
word_tokenize('The most common method is word tokenizing.')Output
['The', 'most', 'common', 'method', 'is', 'word', 'tokenizing', '.']After tokenizing the sentence we are provided with a list of all words (and signs) within the sentence. Another common method is sentence tokenization, which splits the text into a list of sentences:
from nltk.tokenize import sent_tokenize
sent_tokenize("You can also come across sentence tokenizing. This is a simple example.")Output
['You can also come across sentence tokenizing.', 'This is a simple example.']You should know at least these two types of tokenizations; there are many ways of achieving the desired output. We're not going to focus on them in this article, but if you're interested, here are some to explore: more reading on tokenization
Sidenote: NLTK
By now, you've probably noticed that we've imported some packages from nltk library. When working with text data, you should familiarize yourself with their website and the potential of nltk tools. We'll be using many packages and functions imported from their libraries.
N-grams
So why did we split all those texts into lists anyway? Well, as we mentioned, many NLP techniques require an input of tokenized text. Let's start with n-grams. n-gram is a sequence of N words:
- Unigram: "computer"
- Bigram: "fast computer"
- Trigram: "very fast computer"
etc.
Having amassed more than 1,000 feedback posts, we hope to see some of the n-grams occur more often, which should indicate our common mistakes in the shared projects.
from nltk.util import ngrams
import collections
trigrams = ngrams(word_tokenize(df['feedback_clean2'].sum()), 3)
trigrams_freq = collections.Counter(trigrams)
trigrams_freq.most_common(10)Did you notice that we had to pass a tokenized text into the n-grams function?
Output
[(('otherwise', 'everything', 'look'), 47),
(('cell', 'order', 'start'), 30),
(('order', 'start', '1'), 30),
(('upload', 'ipynb', 'file'), 29),
(('upcoming', 'project', 'happy'), 28),
(('best', 'upcoming', 'project'), 27),
(('everything', 'look', 'nice'), 25),
(('project', '’', 's'), 25),
(('guide', 'community', 'helpful'), 25),
(('community', 'helpful', 'difficulty'), 25)]Unfortunately, many of the n-grams are some positive variations of congratulations and compliments; it's very nice, but it doesn't give us any information in relation to the content of the feedback. If we could filter out only certain n-grams, we would get a better picture. We're assuming that n-grams starting with the words like: "consider," "make," or "use" should be very interesting to us. On the other hand, if an n-gram contains words like "happy," "congratulations," or "community" it serves no purpose to us. This shouldn't be that hard since we can pass the collections. Counter output into a pandas DataFrame:
f4grams = ngrams(word_tokenize(df['feedback_clean2'].sum()), 4)
f4grams_freq = collections.Counter(f4grams)
df_4grams = pd.DataFrame(f4grams_freq.most_common())
df_4grams.head()Output
| 0 | 1 | |
|---|---|---|
| 0 | (cell, order, start, 1) | 30 |
| 1 | (best, upcoming, project, happy) | 26 |
| 2 | (guide, community, helpful, difficulty) | 25 |
| 3 | (community, helpful, difficulty, get) | 25 |
| 4 | (helpful, difficulty, get, help) | 25 |
Here are the steps we're going to follow:
- Create a list of words we want to avoid — we'll exclude n-grams containing those words
- Create a list of words that are the most interesting to us — we'll filter out the rows that don't contain those words in the first word
# lists of words to exclude and include:
exclude = ['best','help', 'happy', 'congratulation', 'learning', 'community', 'feedback', 'project', 'guided','guide', 'job', 'great', 'example',
'sharing', 'suggestion', 'share', 'download', 'topic', 'everything', 'nice', 'well', 'done', 'look', 'file', 'might']
include = ['use', 'consider', 'should', 'make', 'get', 'give', 'should', 'better', "would", 'code', 'markdown','cell']
# change the name of the columns:
df_4grams.columns = ['n_gram','count']
# filter out the n-grams:
df_4grams = df_4grams[(~df_4grams['n_gram'].str[0].isin(exclude))&(~df_4grams['n_gram'].str[1].isin(exclude))&(~df_4grams['n_gram'].str[2].isin(exclude))&(~df_4grams['n_gram'].str[3].isin(exclude))]
df_4grams = df_4grams[df_4grams['n_gram'].str[0].isin(include)]
df_4grams[:10]Output
| n_gram | count | |
|---|---|---|
| 42 | (consider, rerunning, sequential, ordering) | 434 |
| 80 | (make, proper, documentation, beginning) | 421 |
| 89 | (use, technical, word, documentation) | 394 |
| 125 | (use, uniform, style, quote) | 389 |
| 129 | (make, projects, professional, social) | 385 |
| 225 | (use, “, we, ”) | 368 |
| 248 | (make, always, consider, rerunning) | 361 |
| 278 | (use, type, successful, data) | 353 |
| 290 | (better, use, uniform, quote) | 347 |
| 291 | (use, uniform, quote, mark) | 343 |
Voila! We can clearly see some proper advice in the above n-grams. It looks like most of our n-grams contain a verb as the first word. It would be great if we could somehow filter out only the n-grams with a verb at the beginning. Come to think of it, a verb followed by a noun or an adjective would be perfect. If only there were a way . . .
Part-of-Speech (POS) Tagging
In corpus linguistics, part-of-speech tagging, also called "grammatical tagging" is the process of marking up a word in a text as corresponding to a particular part of speech, based on both its definition and its context.
source: Wikipedia
If you prefer practice over theory, here's an example of POS:
from nltk import pos_tag
pos_tag(word_tokenize('The most common method is word tokenizing.'))Output
[('The', 'DT'),
('most', 'RBS'),
('common', 'JJ'),
('method', 'NN'),
('is', 'VBZ'),
('word', 'NN'),
('tokenizing', 'NN'),
('.', '.')]We're getting some analysis! We can quickly decipher most of the tags (NN - Noun, JJ - adjective etc.). But to get the full list, just use this 1 line:
nltk.help.upenn_tagset()...or check this article
Chunking
We can tag each word, so let's try looking for specific patterns (a.k.a. chunks!). What are we looking for? One of the recurring themes in many feedback posts is a suggestion to add or change something. How do we grammatically structure that sentence? Let's check!
pos_tag(word_tokenize('You should add more color.'))Output
[('You', 'PRP'),
('should', 'MD'),
('add', 'VB'),
('more', 'JJR'),
('color', 'NN'),
('.', '.')]We're interested only in the "add more color" part, which is tagged as VB, JJR, and NN. (Verb, comparative adjective, and noun). How do we target only the specific parts of our text? Here's the battle plan:
- We'll save a short paragraph to a variable; this paragraph will include our desired chunk grammar (similar to "add more color")
- We'll tokenize that variable, and then we'll tag parts of speech
Here comes the new part:
-
Name the chunk we're after (e.g., "target_phrase") and use POS tags to specify what we're looking for.
-
Parse the paragraph, and print the results.
from nltk import RegexpParser
1. our paragraph:
paragraph = 'I think you can improve content. You should add more information. I do it that way and I am always right'
2. tokenize the paragraph and then use POS tagging:
paragraph_tokenized = word_tokenize(paragraph) paragraph_tagged = pos_tag(paragraph_tokenized)
3. name and structure the grammar we're seeking:
grammar = "target_phrase: {<VB><JJR><NN>}" cp = nltk.RegexpParser(grammar)
4. parse the tagged paragraph:
result = cp.parse(paragraph_tagged) print(result)
Output
(S
I/PRP
think/VBP
you/PRP
can/MD
improve/VB
content/NN
./.
You/PRP
should/MD
(target_phrase add/VB more/JJR information/NN)
./.
I/PRP
do/VBP
it/PRP
that/DT
way/NN
and/CC
I/PRP
am/VBP
always/RB
right/RB)What if we're only interested in the chunk we're after? We don't want to display the entire text! We'll have a lot of text in our feedback posts!
target_chunks = []
for subtree in result.subtrees(filter=lambda t: t.label() == 'target_phrase'):
target_chunks.append(tuple(subtree))
print(target_chunks)Output
[(('add', 'VB'), ('more', 'JJR'), ('information', 'NN'))]Okay, that solves the problem. Now the last thing we want to do is count the number of times our chunk popped up in the text:
from collections import Counter
# create a Counter:
chunk_counter = Counter()
# loop through the list of target_chunks
for chunk in target_chunks:
chunk_counter[chunk] += 1
print(chunk_counter)Output
Counter({(('add', 'VB'), ('more', 'JJR'), ('information', 'NN')): 1})Having done Part-of-Speech tagging and chunking on a small paragraph, let's move on to a bigger set: all of the feedback posts. We'll follow a similar path to analyze the feedback posts. To make it easier to analyze different texts and POS patterns, we'll create three separate functions so that we can swap the input text data, or POS regex pattern, anytime we want to.
The first function will prepare the text data for NLP work: it will tokenize the sentences and words then tag Parts of Speech. It will return a list of POS-tagged words.
def prep_text(text):
# tokenize sentences:
sent_tokenized = sent_tokenize(text)
# tokenize words:
word_tokens = []
for sent in sent_tokenized:
word_tokens.append(word_tokenize(sent))
# POS tagging:
pos_tagged = []
for sent in word_tokens:
pos_tagged.append(pos_tag(sent))
return pos_taggedWe'll use the first function to prepare the text data from all of the feedback posts:
all_feedback = df['feedback'].sum()
all_feedback_tagged = prep_text(all_feedback)The second function will parse all of the tagged text data and look for a specific chunk grammar we'll provide; if tags of the words match the provided pattern, it will tag the chunk with a label.
def parser(regex_pattern, pos_tagged):
np_chunk_grammar = regex_pattern
np_chunk_parser = RegexpParser(np_chunk_grammar)
np_chunked_text = []
for pos_tagged_sentence in pos_tagged:
np_chunked_text.append(np_chunk_parser.parse(pos_tagged_sentence))
return np_chunked_textchunked_text = parser("bingo: {<VB|NN|NNP><JJR><NN|NNS>}",all_feedback_tagged)The last function will filter out only the chunks we're after and count how many times they occur, it will also display the top 10:
def chunk_counter(chunked_sentences):
chunks = []
# loop through each chunked sentence to extract phrase chunks of our desired sequence:
for chunked_sentence in chunked_sentences:
for subtree in chunked_sentence.subtrees(filter=lambda t: t.label() == 'bingo'):
chunks.append(tuple(subtree))
# create a Counter object and loop through the list of chunks
chunk_counter = Counter()
for chunk in chunks:
chunk_counter[chunk] += 1
# return 10 most frequent chunks
return chunk_counter.most_common(10)chunk_counter(chunked_text)Output
[((('add', 'VB'), ('more', 'JJR'), ('information', 'NN')), 3),
((('add', 'VB'), ('more', 'JJR'), ('weight', 'NN')), 3),
((('see', 'VB'), ('more', 'JJR'), ('projects', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('explanations', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('comments', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('info', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('readability', 'NN')), 2),
((('find', 'VB'), ('more', 'JJR'), ('tips', 'NNS')), 1),
((('add', 'VB'), ('more', 'JJR'), ('detail', 'NN')), 1),
((('attract', 'NN'), ('more', 'JJR'), ('users', 'NNS')), 1)]Because our text is already tagged, if we want to look for a different pattern, we only have to swap input for the last two functions:
chunked_text = parser("bingo: {<VB|NN><RB|VBG>?<JJ><NN|NNS><NN|NNS>?}",all_feedback_tagged)
np_chunk_counter(chunked_text)[((('make', 'VB'), ('proper', 'JJ'), ('documentation', 'NN')), 9),
((('have', 'VB'), ('sequential', 'JJ'), ('ordering', 'NN')), 6),
((('combine', 'VB'), ('adjacent', 'JJ'), ('code', 'NN'), ('cells', 'NNS')),
4),
((('vs', 'NN'), ('shallow', 'JJ'), ('copy', 'NN'), ('vs', 'NN')), 4),
((('avoid', 'VB'),
('too', 'RB'),
('obvious', 'JJ'),
('code', 'NN'),
('comments', 'NNS')),
3),
((('combine', 'VB'), ('subsequent', 'JJ'), ('code', 'NN'), ('cells', 'NNS')),
3),
((('rotate', 'VB'), ('x-tick', 'JJ'), ('labels', 'NNS')), 3),
((('remove', 'VB'), ('unnecessary', 'JJ'), ('spines', 'NNS')), 3),
((('remove', 'VB'), ('empty', 'JJ'), ('lines', 'NNS')), 2),
((('show', 'NN'), ('original', 'JJ'), ('hi', 'NN')), 2)]chunked_text = parser("bingo: {<VB><DT><NN|NNS>}",all_feedback_tagged)
chunk_counter(chunked_text)Output
[((('have', 'VB'), ('a', 'DT'), ('look', 'NN')), 19),
((('take', 'VB'), ('a', 'DT'), ('look', 'NN')), 14),
((('improve', 'VB'), ('the', 'DT'), ('readability', 'NN')), 13),
((('view', 'VB'), ('the', 'DT'), ('jupyter', 'NN')), 12),
((('re-run', 'VB'), ('the', 'DT'), ('project', 'NN')), 12),
((('add', 'VB'), ('a', 'DT'), ('title', 'NN')), 11),
((('create', 'VB'), ('a', 'DT'), ('function', 'NN')), 11),
((('add', 'VB'), ('a', 'DT'), ('conclusion', 'NN')), 11),
((('follow', 'VB'), ('the', 'DT'), ('guideline', 'NN')), 9),
((('add', 'VB'), ('some', 'DT'), ('information', 'NN')), 9)]chunked_text = parser("bingo: {<JJR><NN|NNS>}",all_feedback_tagged)
np_chunk_counter(chunked_text)Output
[((('better', 'JJR'), ('readability', 'NN')), 15),
((('more', 'JJR'), ('information', 'NN')), 12),
((('more', 'JJR'), ('comments', 'NNS')), 11),
((('better', 'JJR'), ('understanding', 'NN')), 10),
((('more', 'JJR'), ('projects', 'NNS')), 7),
((('more', 'JJR'), ('explanations', 'NNS')), 6),
((('more', 'JJR'), ('clarification', 'NN')), 5),
((('more', 'JJR'), ('details', 'NNS')), 5),
((('more', 'JJR'), ('detail', 'NN')), 4),
((('more', 'JJR'), ('users', 'NNS')), 4)]Notice how some combinations are almost identical: "more detail" and "more details." This gives us a good opportunity to introduce lemmatization
Lemmatization
We can describe lemmatization as stripping the word to its root form. It can be useful if our text is full of singular or plural forms of the same word, or different tenses of the same verb. Here's a simple example: look at the text below the function; we'll analyze the function after having a look at the text.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def lemmatize_it(sent):
empty = []
for word, tag in pos_tag(word_tokenize(sent)):
wntag = tag[0].lower()
wntag = wntag if wntag in ['a', 'r', 'n', 'v'] else None
if not wntag:
lemma = word
empty.append(lemma)
else:
lemma = lemmatizer.lemmatize(word, wntag)
empty.append(lemma)
return ' '.join(empty)
string1 = 'Adam wrote this great article, spending many hours on his computer. He is truly amazing.'
lemmatize_it(string1)Output
Adam write this great article , spend many hour on his computer . He be truly amazingWe can see all the verbs reduced to their root forms. Also, "hours," being the only plural noun, reduced to the singular form. If we look at the function above, we can see that lemmatization required POS tagging first. If we were to ignore POS tagging, the lemmatizer would only take the nouns to their singular form. Most of the verbs would stay the way they are.
Let's see what happens, when we use our POS pipeline on lemmatized text:
lemmatized = lemmatize_it(df['feedback'].sum())
feedback_lemmed_tagged = prep_text(lemmatized)
chunked_text = parser("bingo: {<VB|NN><RB|VBG>?<JJ><NN|NNS><NN|NNS>?}",feedback_lemmed_tagged)
chunk_counter(chunked_text)Output
[((('render', 'VB'), ('good', 'JJ'), ('output', 'NN')), 11),
((('make', 'VB'), ('proper', 'JJ'), ('documentation', 'NN')), 9),
((('be', 'VB'), ('not', 'RB'), ('skip', 'JJ'), ('sql', 'NN')), 7),
((('have', 'VB'), ('sequential', 'JJ'), ('ordering', 'NN')), 6),
((('combine', 'VB'), ('adjacent', 'JJ'), ('code', 'NN'), ('cell', 'NN')), 4),
((('v', 'NN'), ('shallow', 'JJ'), ('copy', 'NN'), ('v', 'NN')), 4),
((('add', 'VB'), ('empty', 'JJ'), ('line', 'NN')), 3),
((('combine', 'VB'), ('subsequent', 'JJ'), ('code', 'NN'), ('cell', 'NN')),
3),
((('rotate', 'VB'), ('x-tick', 'JJ'), ('label', 'NN')), 3),
((('remove', 'VB'), ('unnecessary', 'JJ'), ('spine', 'NN')), 3)]Looking at the results of POS tagging, we can see that the first place is occupied by a combination that wasn't even included in the top 10. It gives us a better representation of the most common combinations, but on the other hand, lemmatizing the words makes those structures harder to understand. Another important factor is the computing power and time required for lemmatisation. It doubled the amount of time required for generating the above output.
We haven't covered a baby brother of lemmatization: stemming. It's computationally much cheaper, but the results aren't as good. If you're interested in how they differ, read this thread on Stack Overflow: stemming vs lemmatization.
Final Word
If you feel like that was a lot to take in, here's a summary of the main steps we took:
- Properly clean the text data:
- Apply lowercase
- Remove stopwords
- Remove punctuation
- Keep both the original text and cleaned version (or versions)
- Tokenize the text data
- Use stemming or lemmatization (remember proper lemmatization requires POS tagging)
- Depending on dataset size/goal/memory availability you can check the following:
- Most popular words
- Common n-grams
- Look for specific grammar chunks
Further Work
If you want more coding experience, here are a few ideas to consider:
- Group the projects into 2-3 difficulty levels so we can analyze the most common n-grams, POS, etc. in both beginner and advanced projects to see how they differ.
- Redo the n-gram analysis after lemmatization.
- Consider how much time and computational power each method takes — after you've considered it, do the actual calculations.
Any questions?
Feel free to reach out and ask me anything: Dataquest, LinkedIn, GitHub