NLP Project Part 1: Scraping the Web to Gather Data
This is the first in a series of posts describing my natural language processing (NLP) project. To really benefit from this NLP article, you should understand the pandas library and know regex for cleaning data. We'll also focus on web scraping, so elementary knowledge of HTML (the language used for creating websites) is very helpful, but it's not essential.
This NLP project is around scraping and analyzing posts from the Dataquest community! If you aren't familiar with the Dataquest community, it's a great place to get feedback on your projects. I share my projects in the community, and I've benefited a lot from people sharing their insights on my work. As I've progressed, I've started giving back and showing other people what I would have done differently in their notebooks.
I even started writing a generic post with advice from the community around how to build good projects. To include more interesting content in my post, I started looking at other users' feedback on guided projects. Then, I had an idea! Wait a second . . . what if we combine all of the feedback data to every guided project in one dataset?
Based on this, I decided to scrape all of the project feedback from the Dataquest community and analyze it to find the most common project feedback.
Structure
I've divided this project into three stages. These stages aren't that complicated on their own, but combining them may feel a bit overwhelming. I will cover each stage in a separate article:
- Part 1: Gather the data. We'll use the BeautifulSoup library to scrape all the necessary string values from the website and store them in a pandas DataFrame. We'll discuss this part in the article below.
- Part 2: Clean and analyze the data. Web scraping very often yields "dirty" text values. It's normal for the scraper to pick up a few extra signs or lines of HTML during the process. We'll use regular expression techniques to transform that data into a more useful format and then analyze it.
- Part 3: Use machine learning models on the data. Why perform the analysis yourself when you can send the machine to do it for you? Expanding on our work from part 2, we'll test different machine learning approaches to analyzing text data.
You can access all the projects files on my GitHub. I'll be adding more files and fine-tuning the existing ones as I publish the next articles.
Ready? Let's get to work . . .
Part 1 — Web Scraping for Natural Language Processing Project
If you haven't used BeautifulSoup yet, then I encourage you to check my introduction notebook. It follows a path similar to the one we're going to take: scraping not one but many websites. Also, here's a more in-depth article at Dataquest introducing us to web scraping.
Let's look at how the actual guided project post category looks to get a better idea of what we want to achieve:
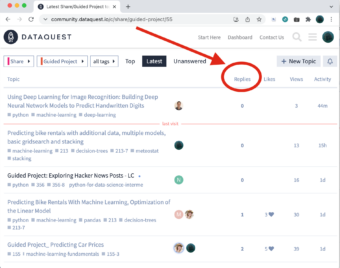
This is the main thread of Guided Projects. It contains all of our Guided Projects that we've decided to publish. Most of them received a reply with some comments — we're interested in the contents of that reply. Here's a sample post:
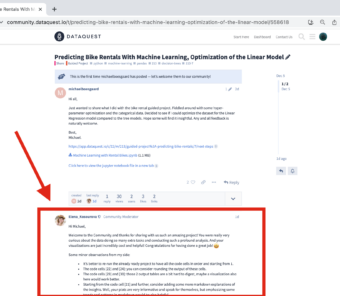
In this post, Michael published his project, and Elena replied with some remarks to his work. We're interested in scraping only the content of Elena's remarks. It's not going to be as easy as scraping one website. We want to scrape a specific part of many websites, for which we don't have the links . . . yet. Here's the plan of attack:
- We don't have the links to all of the guided project posts — we need to extract them, which means we'll have to scrape the main thread of guided projects.
- After scraping the main thread, we'll create a DataFrame containing posts, titles, links, views, and the number of replies (we'll filter out posts with no replies).
- The remaining dataset should contain only the posts that received feedback and the links to those posts — we can commence scraping the actual individual posts
Very Basic Introduction to HTML
Before we start, have you ever seen HTML code? It differs from Python. If you've never experienced HTML code, here's a very basic example of a table in HTML:
<html>
<body>
<table border=1>
<tr>
<td>Emil</td>
<td>Tobias</td>
<td><a href="https://www.dataquest.io/">dataquest</a></td>
</tr>
</table>
</body>
</html>| Emil | Tobias | dataquest |
In HTML, we use tags to define elements. Many elements have an opening tag and a closing tag — for example . . .
<table>. . . opens the building of a table, and at the very end of coding the table, we write . . .
</table>. . . to close it. This table has 1 row with 3 cells in that row. In the third cell, we've used a link
<a href=...>HTML tags can have attributes (we've used the "border" attribute in the "table" tag and the "href" attribute in the "a" tag).
Step 1: Web Scraping the Main Thread of Guided Projects
Inspecting the website
We'll begin with inspecting the contents of the entire website: https://community.dataquest.io/c/share/guided-project/55
We can use our browser for this; I use Chrome. Just hover your mouse above the title of the post, right-click it, and choose Inspect. (Notice that I've chosen a post that's a few posts below the top — just in case the first post has a different class.)
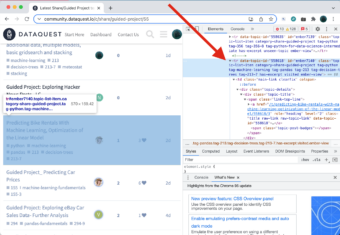
Now we can look at the website's code. When you hover over certain elements of the code in the right window, the browser will highlight that element in the left window. In the example below, my cursor is hovering over the following:
<tr data-topic-id=...>On the left side, we can observe a big chunk of the website in the highlight:
First Attempts at Web Scraping
For our first attempt, we'll try to get only the links of every post. Notice that the actual link has a class — "title raw-link raw-topic-link" — in the second line of the code below:
<a href="https://www.dataquest.io/t/predicting-bike-rentals-with-machine-learning-optimization-of-the-linear-model/558618/3" role="heading" level="2" class="title raw-link raw-topic-link" data-topic-id="558618"><span dir="ltr">Predicting Bike Rentals
With Machine Learning, Optimization of the Linear Model</span></a>We'll use the following code to scrape all the links with that class into one list and see how many we've managed to extract:
# imports: from bs4 import BeautifulSoup from urllib.request import urlopen, Request</code> # step 1 lets scrape the guided project website with all the posts: url = "https://community.dataquest.io/c/share/guided-project/55" html = urlopen(url) soup = BeautifulSoup(html, 'html.parser') # look for every 'a' tag with 'class' title raw-link raw-topic-link: list_all = soup.find_all("a", class_="title raw-link raw-topic-link") # check how many elements we've extracted: len(list_all)[Output]: 30
Our list has only 30 elements! We were expecting a bigger number, so what happened? Unfortunately, we're trying to scrape a dynamic website. Dataquest loads only the first 30 posts when our browser opens the forums page; if we want to see more, we have to scroll down. But how do we program our scraper to scroll down? Selenium is a go-to solution for that issue, but we're going to use a simpler approach:
- Scroll down to the bottom of the website.
- When we reach the end, save the website as a file.
- Instead of processing a link with BeautifulSoup, we'll process that file.
Let's get to scrolling down:

Yes, that is an actual fork pushing the down arrow on the keyboard, weighted down with an empty coffee cup (the author of this post does not encourage any unordinary use of cutlery or flatware around your electronic equipment). Having scrolled down to the very bottom, we can save the website using File > Save Page As... Now we can load that file into our notebook and commence scraping; this time we'll target every new row:
<tr>. Because ultimately, we're not interested in scraping only the links — we want to extract as much data as possible. Not only the title, with a link, but also the number of replies, views, etc.
import codecs
# this is the file of the website, after scrolling all the way down:
file = codecs.open("../input/dq-projects/projects.html", "r", "utf-8")
# parse the file:
parser = BeautifulSoup(file, 'html.parser')
# look for every 'tr' tag, scrape its contents and create a pandas series from the list:
list_all = parser.find_all('tr')
series_4_df = pd.Series(list_all)
# create a dataframe from pandas series:
df = pd.DataFrame(series_4_df, columns=['content'])
df['content'] = df['content'].astype(str)
df.head()| content | ||
| 0 | <tr><th class="default" data-sort-order="defau... |
|
| 1 | <tr class="topic-list-item category-share-guid... |
|
| 2 | <tr class="topic-list-item category-share-guid... |
|
| 3 | <tr class="topic-list-item category-share-guid... |
|
| 4 | <tr class="topic-list-item category-share-guid... |
Step 2: Extracting Data from HTML
We have created a DataFrame filled with HTML code. Let's inspect the contents of one cell:
df.loc[2,'content']
<tr class="topic-list-item category-share-guided-project tag-257 tag-sql-fundamentals tag-257-8 has-excerpt
unseen-topic ember-view" data-topic-id="558357" id="ember71">\n<td class="main-link clearfix" colspan="">\n
<div class="topic-details">\n<div class="topic-title">\n<span class="link-top-line">\n<a class="title raw-link
raw-topic-link" data-topic-id="558357" href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357"
level="2" role="heading"><span dir="ltr">Analyzing CIA Factbook with SQL - Full Project</span></a>\n<span
class="topic-post-badges">\xa0<a class="badge badge-notification new-topic"
href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357"
title="new topic"></a></span>\n</span>\n</div>\n<div class="discourse-tags"><a class="discourse-tag bullet"
data-tag-name="257" href="https://community.dataquest.io/tag/257">257</a> <a class="discourse-tag bullet"
data-tag-name="sql-fundamentals" href="https://community.dataquest.io/tag/sql-fundamentals">sql-fundamentals</a>
<a class="discourse-tag bullet" data-tag-name="257-8" href="https://community.dataquest.io/tag/257-8">257-8</a>
</div>\n<div class="actions-and-meta-data">\n</div>\n</div></td>\n<td class="posters">\n<a class="latest single"
data-user-card="noah.gampe" href="https://community.dataquest.io/u/noah.gampe"><img alt=""
aria-label="noah.gampe - Original Poster, Most Recent Poster" class="avatar latest single" height="25"
src="./Latest Share_Guided Project topics - Dataquest Community_files/12175_2.png"
title="noah.gampe - Original Poster, Most Recent Poster" width="25"/></a>\n</td>\n<td class="num posts-map posts"
title="This topic has 0 replies">\n<button class="btn-link posts-map badge-posts">\n<span
aria-label="This topic has 0 replies" class="number">0</span>\n</button>\n</td>\n<td class="num
likes">\n</td>\n<td class="num views"><span class="number" title="this topic has been viewed 9 times">9</span>
</td>\n<td class="num age activity" title="First post: Nov 20, 2021 9:25 am\nPosted: Nov 20, 2021 9:27 am">\n
<a class="post-activity" href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357/1">
<span class="relative-date" data-format="tiny" data-time="1637360860367">1d</span></a>\n</td>\n</tr>Extracting the data from HTML:
How to find order in this chaos? We only need two elements from the code above (but we'll try to extract more). The title in the block of code above is "Analyzing CIA Factbook with SQL - Full Project." We can find the title inside the span element:
<span dir="ltr">Analyzing CIA Factbook with SQL - Full Project</span>The previous element is the link we want:
<a class="title raw-link raw-topic-link" data-topic-id="558357" href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357" level="2" role="heading">The number of views should be useful:
<span class="number" title="this topic has been viewed 9 times">9</span>The last bit of information we want is the number of replies for each post:
<span aria-label="This topic has 0 replies" class="number">0</span>We could use BeautifulSoup to target those specific elements and extract their content, but this dataset isn't that big, and extracting the information we need directly from the cell in the same row seems like a safer option. We'll follow this plan:
- Remove the first row (which is not a post element).
- Proceed with regex techniques to extract the title, link, number of replies, and number of views. (Here's a regex cheatsheet.)
- Remove the rows with 0 replies.
# remove 1st row:
df = df.iloc[1:,:]
# extract title, link and number of replies:
df['title'] = df['content'].str.extract('<span dir="ltr">(.*?)</span>')
df['link'] = df['content'].str.extract('href=(.*?)level="2"')
df['replies'] = df['content'].str.extract("This topic has (.*?) re").astype(int)
df['views'] = df['content'].str.extract("this topic has been viewed (.*?) times")
df['views'] = df['views'].str.replace(',','').astype(int)
# remove 1 generic post and posts with 0 replies:
df = df[df['replies']>0]
df = df[df['replies']<100]
df.head()| content | title | link | replies | views | |
|---|---|---|---|---|---|
| 4 | <tr class="topic-list-item category-share-guid... | Predicting house prices | https://community.dataquest.io/t/predicting-ho... | 1 | 26 |
| 5 | <tr class="topic-list-item category-share-guid... | [Re-upload]Project Feedback - Popular Data Sci... | https://community.dataquest.io/t/re-upload-pro... | 3 | 47 |
| 7 | <tr class="topic-list-item category-share-guid... | GP: Clean and Analyze Employee Exit Surveys ++ | https://community.dataquest.io/t/gp-clean-and-... | 2 | 53 |
| 10 | <tr class="topic-list-item category-share-guid... | Project Feedback - Popular Data Science Questions | https://community.dataquest.io/t/project-feedb... | 5 | 71 |
| 12 | <tr class="topic-list-item category-share-guid... | Guided Project: Answer to Albums vs. Singles w... | https://community.dataquest.io/t/guided-projec... | 5 | 370 |
Step 3: Scraping the Individual Posts
This last step isn't much different than step 1. We have to inspect an individual post and deduce which page element is responsible for the content of the first reply to the post. We're assuming that the most valuable content will be stored in the first reply to the published project. We'll ignore all the other replies.
To process this amount of text data, we'll create a function. All the heavy data processing is in the function, and we don't have to worry about some variables occupying the memory after we're done working with them.
# create a function for scraping the actual posts website:
def get_reply(one_link):
response = requests.get(one_link)
content = response.content
parser = BeautifulSoup(content, 'html.parser')
tag_numbers = parser.find_all("div", class_="post")
# we're only going to scrape the content of the first reply (that's usually the feedback)
feedback = tag_numbers[1].text
return feedbackTesting the Scraper
Here's a very important rule I follow whenever performing web-scraping: Start small!
# create a test dataframe to test scraping on 5 rows:
df_test = df[:5].copy()
# we'll use a loop on all the elements of pd.Series (faster than using 'apply')
feedback_list = []
for el in df_test['link2']:
feedback_list.append(get_reply(el))
df_test['feedback'] = feedback_list
df_testLooks promising — let's check the entire cell:
df_test['feedback'][4]Processing data in a function saves memory (the variables you create stay in the function and are not stored in memory when you’re finished with the function). This is important when you’re working with larger datasets — if you’re interested with experimenting, try cleaning 1 month of this dataset on Kaggle notebook (and look at your RAM usage) outside the function and inside the function. Compare the RAM usage in both examples.
Whole reply, ready for cleaning.
Scraping All of the Feedback
Now let's move on (this will take a while):
# this lets scrape all the posts, not just 5 of them:
def scrape_replies(df):
feedback_list = []
for el in df['link']:
feedback_list.append(get_reply(el))
df['feedback'] = feedback_list
return df
df = scrape_replies(df)That's it, we've extracted all the raw data we wanted from Dataquest's websites. In the next post, we'll focus on cleaning and analyzing this data using natural language processing techniques. We'll try to find the most common patterns in the content of projects feedback. But before you go, here are a few things to think about:
Scraping tool
Consider the server
If you're constantly requesting a lot of content from a website, most of the servers will pick up on it and very often cut you off. Remember to start small. In our specific example, we asked for a chunk of data and received it without any problems. But it's common to run into some problems, like this one:
ConnectionError: HTTPSConnectionPool(host='en.wikipedia.orghttps', port=443): Max retries exceeded with url:[...]The important part is Max retries exceeded. It means we've been requesting data too many times. It's a good habit to stop web scraping every now and then to mimic natural human behavior. How do we do that? We need to smuggle in this line of code:
time.sleep(np.random.randint(1,20))This will pause our algorithm for a random number (1-20) of seconds, naturally, that extends the amount of time it takes to extract the data but also makes it possible. Remember that we need to put this one-liner in an adequate spot in our code:
# this lets scrape all the posts, not just 5 of them:
def scrape_replies(df):
feedback_list = []
for el in df['link']:
# go to sleep first, then do your work:
time.sleep(np.random.randint(1,20))
feedback_list.append(get_reply(el))
df['feedback'] = feedback_list
return df
df = scrape_replies(df)If you're interested in other web scraping tricks, read this article.