Building a Data Science Portfolio: Machine Learning Project
(This is the third in a series of posts on how to build a Data Science Portfolio. You can find links to the other posts in this series at the bottom of the post.)
The first step in making a high-quality portfolio is to know what skills to demonstrate. The primary skills that companies want in data scientists, and thus the primary skills they want a portfolio to demonstrate, are:
- Ability to communicate
- Ability to collaborate with others
- Technical competence
- Ability to reason about data
- Motivation and ability to take initiative
Any good portfolio will be composed of multiple projects, each of which may demonstrate 1-2 of the above points. This is the third post in a series that will cover how to make a well-rounded data science portfolio.
In this post, we'll cover how to make the second project in your portfolio, and how to build an end to end machine learning project. At the end, you'll have a project that shows your ability to reason about data, and your technical competence.
Here's the completed project if you want to take a look.
An End to End Machine Learning Project
As a data scientist, there are times when you'll be asked to take a data set and figure out how to tell a story with it. In times like this, it's important to communicate very well, and walk through your process. Tools like Jupyter notebook, which we used in a previous post, are very good at helping you do this. The expectation here is that the deliverable is a presentation or document summarizing your findings.
However, there are other times when you'll be asked to create a project that has operational value. A project with operational value directly impacts the day-to-day operations of a company, and will be used more than once, and often by multiple people. A task like this might be "create an algorithm to forecast our churn rate", or "create a model that can automatically tag our articles".
In cases like this, storytelling is less important than technical competence. You need to be able to take a data set, understand it, then create a set of scripts that can process that data. It's often important that these scripts run quickly, and use minimal system resources like memory. It's very common that these scripts will be run several times, so the deliverable becomes the scripts themselves, not a presentation. The deliverable is often integrated into operational flows, and may even be user-facing. The main components of building an end to end project are:
- Understanding the context
- Exploring the data and figuring out the nuances
- Creating a well-structured project, so its easy to integrate into operational flows
- Writing high-performance code that runs quickly and uses minimal system resources
- Documenting the installation and usage of your code well, so others can use it
In order to effectively create a project of this kind, we'll need to work with multiple files. Using a text editor like Atom, or an IDE like PyCharm is highly recommended. These tools will allow you to jump between files, and edit files of different types, like markdown files, Python files, and csv files.
Structuring your project so it's easy to version control and upload to collaborative coding tools like Github is also useful.  This project on Github. We'll use our editing tools along with libraries like Pandas and scikit-learn in this post. We'll make extensive use of Pandas DataFrames, which make it easy to read in and work with tabular data in Python.
This project on Github. We'll use our editing tools along with libraries like Pandas and scikit-learn in this post. We'll make extensive use of Pandas DataFrames, which make it easy to read in and work with tabular data in Python.
Finding Good Data Sets
A good data set for an end to end machine learning project can be hard to find. The data set needs to be sufficiently large that memory and performance constraints come into play. It also needs to potentially be operationally useful. For instance, this data set, which contains data on the admission criteria, graduation rates, and graduate future earnings for US colleges would be a great data set to use to tell a story.
However, as you think about the data set, it becomes clear that there isn't enough nuance to build a good end to end project with it. For example, you could tell someone their potential future earnings if they went to a specific college, but that would be a quick lookup without enough nuance to demonstrate technical competence. You could also figure out if colleges with higher adlessons standards tend to have graduates who earn more, but that would be more storytelling than operational.
These memory and performance constraints tend to come into play when you have more than a gigabyte of data, and when you have some nuance to what you want to predict, which involves running algorithms over the data set. A good operational data set enables you to build a set of scripts that transform the data, and answer dynamic questions.
A good example would be a data set of stock prices. You would be able to predict the prices for the next day, and keep feeding new data to the algorithm as the markets closed. This would enable you to make trades, and potentially even profit. This wouldn't be telling a story -- it would be adding direct value. Some good places to find data sets like this are:
- /r/datasets — a subreddit that has hundreds of interesting data sets.
- Google Public Data sets — public data sets available through Google BigQuery.
- Awesome data sets — a list of data sets, hosted on Github.
As you look through these data sets, think about what questions someone might want answered with the data set, and think if those questions are one-time ("how did housing prices correlate with the S&P 500?"), or ongoing ("can you predict the stock market?"). The key here is to find questions that are ongoing, and require the same code to be run multiple times with different inputs (different data).
For the purposes of this post, we'll look at Fannie Mae Loan Data. Fannie Mae is a government sponsored enterprise in the US that buys mortgage loans from other lenders. It then bundles these loans up into mortgage-backed securities and resells them. This enables lenders to make more mortgage loans, and creates more liquidity in the market. This theoretically leads to more home ownership, and better loan terms.
From a borrowers perspective, things stay largely the same, though.
Fannie Mae releases two types of data -- data on loans it acquires, and data on how those loans perform over time. In the ideal case, someone borrows money from a lender, then repays the loan until the balance is zero. However, some borrowers miss multiple payments, which can cause foreclosure. Foreclosure is when the house is seized by the bank because mortgage payments cannot be made.
Fannie Mae tracks which loans have missed payments on them, and which loans needed to be foreclosed on. This data is published quarterly, and lags the current date by 1 year.
As of this writing, the most recent data set that's available is from the first quarter of 2015. Acquisition data, which is published when the loan is acquired by Fannie Mae, contains information on the borrower, including credit score, and information on their loan and home. Performance data, which is published every quarter after the loan is acquired, contains information on the payments being made by the borrower, and the foreclosure status, if any.
A loan that is acquired may have dozens of rows in the performance data. A good way to think of this is that the acquisition data tells you that Fannie Mae now controls the loan, and the performance data contains a series of status updates on the loan. One of the status updates may tell us that the loan was foreclosed on during a certain quarter.  A foreclosed home being sold.
A foreclosed home being sold.
Picking an Angle
There are a few directions we could go in with the Fannie Mae data set. We could:
- Try to predict the sale price of a house after it's foreclosed on.
- Predict the payment history of a borrower.
- Figure out a score for each loan at acquisition time.
The important thing is to stick to a single angle. Trying to focus on too many things at once will make it hard to make an effective project. It's also important to pick an angle that has sufficient nuance. Here are examples of angles without much nuance:
- Figuring out which banks sold loans to Fannie Mae that were foreclosed on the most.
- Figuring out trends in borrower credit scores.
- Exploring which types of homes are foreclosed on most often.
- Exploring the relationship between loan amounts and foreclosure sale prices
All of the above angles are interesting, and would be great if we were focused on storytelling, but aren't great fits for an operational project. With the Fannie Mae data set, we'll try to predict whether a loan will be foreclosed on in the future by only using information that was available when the loan was acquired. In effect, we'll create a "score" for any mortgage that will tell us if Fannie Mae should buy it or not. This will give us a nice foundation to build on, and will be a great portfolio piece.
Understanding the Data
Let's take a quick look at the raw data files. Here are the first few rows of the acquisition data from quarter 1 of 2012:
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
Here are the first few rows of the performance data from quarter
1 of 2012:
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||Before proceeding too far into coding, it's useful to take some time and really understand the data. This is more critical in operational projects -- because we aren't interactively exploring the data, it can be harder to spot certain nuances unless we find them upfront.
In this case, the first step is to read the materials on the Fannie Mae site:
- Overview
- Glossary of useful terms
- FAQs
- Columns in the Acquisition and Performance files
- Sample Acquisition data file (no longer available)
- Sample Performance data file (no longer available)
After reading through these files, we know some key facts that will help us:
-
There's an Acquisition file and a Performance file for each quarter, starting from the year
2000to present. There's a1year lag in the data, so the most recent data is from2015as of this writing. -
The files are in text format, with a pipe (
|) as a delimiter. - The files don't have headers, but we have a list of what each column is.
-
All together, the files contain data on
22million loans. -
Because the Performance files contain information on loans acquired in previous years, there will be more performance data for loans acquired in earlier years (ie loans acquired in
2014won't have much performance history).
These small bits of information will save us a ton of time as we figure out how to structure our project and work with the data.
Structuring the Project
Before we start downloading and exploring the data, it's important to think about how we'll structure the project. When building an end-to-end project, our primary goals are:
- Creating a solution that works
- Having a solution that runs quickly and uses minimal resources
- Enabling others to easily extend our work
- Making it easy for others to understand our code
- Writing as little code as possible
In order to achieve these goals, we'll need to structure our project well. A well structured project follows a few principles:
- Separates data files and code files.
- Separates raw data from generated data.
-
Has a
README.mdfile that walks people through installing and using the project. -
Has a
requirements.txtfile that contains all the packages needed to run the project. -
Has a single
settings.pyfile that contains any settings that are used in other files.-
For example, if you are reading the same file from multiple Python scripts, it's useful to have them all import
settingsand get the file name from a centralized place.
-
For example, if you are reading the same file from multiple Python scripts, it's useful to have them all import
-
Has a
.gitignorefile that prevents large or secret files from being committed. -
Breaks each step in our task into a separate file that can be executed separately.
- For example, we may have one file for reading in the data, one for creating features, and one for making predictions.
-
Stores intermediate values. For example, one script may output a file that the next script can read.
- This enables us to make changes in our data processing flow without recalculating everything.
Our file structure will look something like this shortly:
loan-prediction
├── data
├── processed
├── .gitignore
├── README.md
├── requirements.txt
├── settings.py
Creating the Initial Files
To start with, we'll need to create a loan-prediction folder. Inside that folder, we'll need to make a data folder and a processed folder. The first will store our raw data, and the second will store any intermediate calculated values.
Next, we'll make a .gitignore file. A .gitignore file will make sure certain files are ignored by git and not pushed to Github. One good example of such a file is the .DS_Store file created by OSX in every folder. A good starting point for a .gitignore file is here.
We'll also want to ignore the data files because they are very large, and the Fannie Mae terms prevent us from redistributing them, so we should add two lines to the end of our file:
data
processed
Here's an example .gitignore file for this project. Next, we'll need to create README.md, which will help people understand the project. .md indicates that the file is in markdown format. Markdown enables you write plain text, but also add some fancy formatting if you want. Here's a guide on markdown. If you upload a file called README.md to Github, Github will automatically process the markdown, and show it to anyone who views the project. Here's an example. For now, we just need to put a simple description in README.md:
Loan Prediction
-----------------------
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](https://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
Now, we can create a requirements.txt file. This will make it easy for other people to install our project. We don't know exactly what libraries we'll be using yet, but here's a good starting point:
pandas
matplotlib
scikit-learn
numpy
ipython
scipy
The above libraries are the most commonly used for data analysis tasks in Python, and its fair to assume that we'll be using most of them. Here's an example requirements file for this project. After creating requirements.txt, you should install the packages. For this post, we'll be using Python 3.
If you don't have Python installed, you should look into using Anaconda, a Python installer that also installs all the packages listed above. Finally, we can just make a blank settings.py file, since we don't have any settings for our project yet.
Acquiring the Data
Once we have the skeleton of our project, we can get the raw data. Fannie Mae has some restrictions around acquiring the data, so you'll need to sign up for an account. You can find the download page here. After creating an account, you'll be able to download as few or as many loan data files as you want.
The files are in zip format, and are reasonably large after decompression. For the purposes of this blog post, we'll download everything from Q1 2012 to Q1 2015, inclusive. We'll then need to unzip all of the files. After unzipping the files, remove the original .zip files. At the end, the loan-prediction folder should look something like this:
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
├── .gitignore
├── README.md
├── requirements.txt
├── settings.py
After downloading the data, you can use the head and tail shell commands to look at the lines in the files. Do you see any columns that aren't needed? It might be useful to consult the pdf of column names while doing this.
Reading in the Data
There are two issues that make our data hard to work with right now:
- The acquisition and performance data sets are segmented across multiple files.
- Each file is missing headers.
Before we can get started on working with the data, we'll need to get to the point where we have one file for the acquisition data, and one file for the performance data. Each of the files will need to contain only the columns we care about, and have the proper headers.
One wrinkle here is that the performance data is quite large, so we should try to trim some of the columns if we can. The first step is to add some variables to settings.py, which will contain the paths to our raw data and our processed data. We'll also add a few other settings that will be useful later on:
DATA_DIR = "data"
PROCESSED_DIR = "processed"
MINIMUM_TRACKING_QUARTERS = 4
TARGET = "foreclosure_status"
NON_PREDICTORS = [TARGET, "id"]
CV_FOLDS = 3
Putting the paths in settings.py will put them in a centralized place and make them easy to change down the line. When referring to the same variables in multiple files, it's easier to put them in a central place than edit them in every file when you want to change them. Here's an example settings.py file for this project.
The second step is to create a file called assemble.py that will assemble all the pieces into 2 files. When we run python assemble.py, we'll get 2 data files in the processed directory. We'll then start writing code in assemble.py.
We'll first need to define the headers for each file, so we'll need to look at pdf of column names and create lists of the columns in each Acquisition and Performance file:
HEADERS = {
"Acquisition": [
"id",
"channel",
"seller",
"interest_rate",
"balance",
"loan_term",
"origination_date",
"first_payment_date",
"ltv",
"cltv",
"borrower_count",
"dti",
"borrower_credit_score",
"first_time_homebuyer",
"loan_purpose",
"property_type",
"unit_count",
"occupancy_status",
"property_state",
"zip",
"insurance_percentage",
"product_type",
"co_borrower_credit_score"
],
"Performance": [
"id",
"reporting_period",
"servicer_name",
"interest_rate",
"balance",
"loan_age",
"months_to_maturity",
"maturity_date",
"msa",
"delinquency_status",
"modification_flag",
"zero_balance_code",
"zero_balance_date",
"last_paid_installment_date",
"foreclosure_date",
"disposition_date",
"foreclosure_costs",
"property_repair_costs",
"recovery_costs",
"misc_costs",
"tax_costs",
"sale_proceeds",
"credit_enhancement_proceeds",
"repurchase_proceeds",
"other_foreclosure_proceeds",
"non_interest_bearing_balance",
"principal_forgiveness_balance"
]
}
The next step is to define the columns we want to keep. Since all we're measuring on an ongoing basis about the loan is whether or not it was ever foreclosed on, we can discard many of the columns in the performance data. We'll need to keep all the columns in the acquisition data, though, because we want to maximize the information we have about when the loan was acquired (after all, we're predicting if the loan will ever be foreclosed or not at the point it's acquired). Discarding columns will enable us to save disk space and memory, while also speeding up our code.
SELECT = {
"Acquisition": HEADERS["Acquisition"],
"Performance": [
"id",
"foreclosure_date"
]
}
Next, we'll write a function to concatenate the data sets. The below code will:
-
Import a few needed libraries, including
settings. -
Define a function
concatenate, that:-
Gets the names of all the files in the
datadirectory. -
Loops through each file.
- If the file isn't the right type (doesn't start with the prefix we want), we ignore it.
-
Reads the file into a DataFrame with the right settings using the Pandas read_csv function.
-
Sets the separator to
|so the fields are read in correctly. -
The data has no header row, so sets
headertoNoneto indicate this. -
Sets names to the right value from the
HEADERSdictionary -- these will be the column names of our DataFrame. -
Picks only the columns from the DataFrame that we added in
SELECT.
-
Sets the separator to
- Concatenates all the DataFrames together.
- Writes the concatenated DataFrame back to a file.
-
Gets the names of all the files in the
import os
import settings
import pandas as pd
def concatenate(prefix="Acquisition"):
files = os.listdir(settings.DATA_DIR)
full = []
for f in files:
if not f.startswith(prefix):
continue
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
data = data[SELECT[prefix]]
full.append(data)
full = pd.concat(full, axis=0)
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
We can call the above function twice with the arguments
Acquisition and Performance to concatenate all the acquisition and performance files together. The below code will:
-
Only execute if the script is called from the command line with
python assemble.py. -
Concatenate all the files, and result in two files:
-
processed/Acquisition.txt -
processed/Performance.txt
-
if __name__ == "__main__":
concatenate("Acquisition")
concatenate("Performance")
We now have a nice, compartmentalized assemble.py that's easy to execute, and easy to build off of. By decomposing the problem into pieces like this, we make it easy to build our project. Instead of one messy script that does everything, we define the data that will pass between the scripts, and make them completely separate from each other.
When you're working on larger projects, it's a good idea to do this, because it makes it much easier to change individual pieces without having unexpected consequences on unrelated pieces of the project. Once we finish the assemble.py script, we can run python assemble.py. You can find the complete assemble.py file here. This will result in two files in the processed directory:
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
│ ├── Acquisition.txt
│ ├── Performance.txt
├── .gitignore
├── assemble.py
├── README.md
├── requirements.txt
├── settings.py
Computing Values From the Performance Data
The next step we'll take is to calculate some values from processed/Performance.txt. All we want to do is to predict whether or not a property is foreclosed on. To figure this out, we just need to check if the performance data associated with a loan ever has a foreclosure_date. If foreclosure_date is None, then the property was never foreclosed on.
In order to avoid including loans with little performance history in our sample, we'll also want to count up how many rows exist in the performance file for each loan. This will let us filter loans without much performance history from our training data. One way to think of the loan data and the performance data is like this: 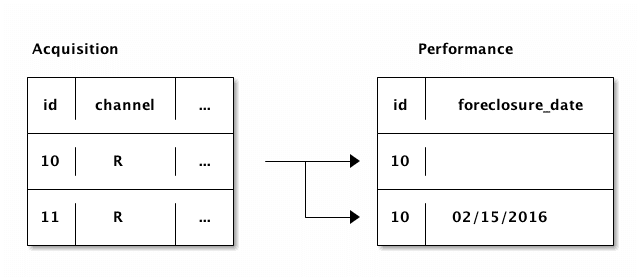
As you can see above, each row in the Acquisition data can be related to multiple rows in the Performance data. In the Performance data, foreclosure_date will appear in the quarter when the foreclosure happened, so it should be blank prior to that. Some loans are never foreclosed on, so all the rows related to them in the Performance data have foreclosure_date blank.
We need to compute foreclosure_status, which is a Boolean that indicates whether a particular loan id was ever foreclosed on, and performance_count, which is the number of rows in the performance data for each loan id. There are a few different ways to compute the counts we want:
-
We could read in all the performance data, then use the Pandas groupby method on the DataFrame to figure out the number of rows associated with each loan
id, and also if theforeclosure_dateis ever notNonefor theid.- The upside of this method is that it's easy to implement from a syntax perspective.
-
The downside is that reading in all
129236094lines in the data will take a lot of memory, and be extremely slow.
-
We could read in all the performance data, then use apply on the acquisition DataFrame to find the counts for each
id.- The upside is that it's easy to conceptualize.
-
The downside is that reading in all
129236094lines in the data will take a lot of memory, and be extremely slow.
-
We could iterate over each row in the performance data set, and keep a separate dictionary of counts.
- The upside is that the data set doesn't need to be loaded into memory, so it's extremely fast and memory-efficient.
- The downside is that it will take slightly longer to conceptualize and implement, and we need to parse the rows manually.
Loading in all the data will take quite a bit of memory, so let's go with the third option above. All we need to do is to iterate through all the rows in the Performance data, while keeping a dictionary of counts per loan id.
In the dictionary, we'll keep track of how many times the id appears in the performance data, as well as if foreclosure_date is ever not None. This will give us foreclosure_status and performance_count. We'll create a new file called annotate.py, and add in code that will enable us to compute these values. In the below code, we'll:
- Import needed libraries.
-
Define a function called
count_performance_rows.-
Open
processed/Performance.txt. This doesn't read the file into memory, but instead opens a file handler that can be used to read in the file line by line. -
Loop through each line in the file.
-
Split the line on the delimiter (
|) -
Check if the
loan_idis not in thecountsdictionary.-
If not, add it to
counts.
-
If not, add it to
-
Increment
performance_countfor the givenloan_idbecause we're on a row that contains it. -
If
dateis notNone, then we know that the loan was foreclosed on, so setforeclosure_statusappropriately.
-
Split the line on the delimiter (
-
Open
import os
import settings
import pandas as pd
def count_performance_rows():
counts = {}
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
for i, line in enumerate(f):
if i == 0:
# Skip header row
continue
loan_id, date = line.split("|")
loan_id = int(loan_id)
if loan_id not in counts:
counts[loan_id] = {
"foreclosure_status": False,
"performance_count": 0
}
counts[loan_id]["performance_count"] += 1
if len(date.strip()) > 0:
counts[loan_id]["foreclosure_status"] = True
return counts
Getting the Values
Once we create our counts dictionary, we can make a function that will extract values from the dictionary if a loan_id and a key are passed in:
def get_performance_summary_value(loan_id, key, counts):
value = counts.get(loan_id, {
"foreclosure_status": False,
"performance_count": 0
})
return value[key]The above function will return the appropriate value from the counts dictionary, and will enable us to assign a foreclosure_status value and a performance_count value to each row in the Acquisition data. The get method on dictionaries returns a default value if a key isn't found, so this enables us to return sensible default values if a key isn't found in the counts dictionary.
Annotating the Data
We've already added a few functions to annotate.py, but now we can get into the meat of the file. We'll need to convert the acquisition data into a training data set that can be used in a machine learning algorithm. This involves a few things:
- Converting all columns to numeric.
- Filling in any missing values.
-
Assigning a
performance_countand aforeclosure_statusto each row. -
Removing any rows that don't have a lot of performance history (where
performance_countis low).
Several of our columns are strings, which aren't useful to a machine learning algorithm. However, they are actually categorical variables, where there are a few different category codes, like R, S, and so on.
We can convert these columns to numeric by assigning a number to each category label: 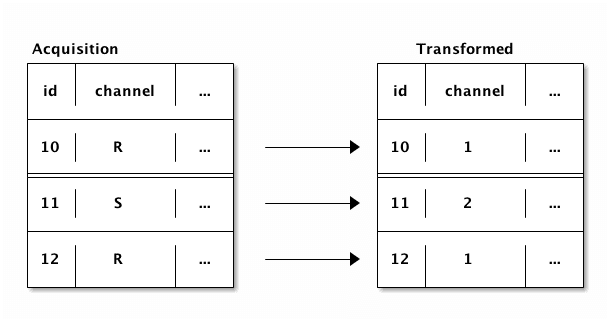 Converting the columns this way will allow us to use them in our machine learning algorithm. Some of the columns also contain dates (
Converting the columns this way will allow us to use them in our machine learning algorithm. Some of the columns also contain dates (first_payment_date and origination_date). We can split these dates into 2 columns each: 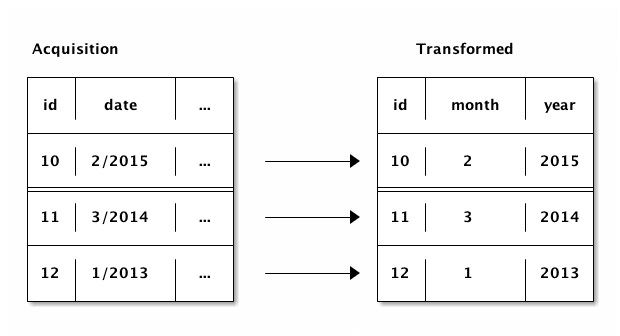
In the below code, we'll transform the Acquisition data. We'll define a function that:
-
Creates a
foreclosure_statuscolumn inacquisitionby getting the values from thecountsdictionary. -
Creates a
performance_countcolumn inacquisitionby getting the values from thecountsdictionary. -
Converts each of the following columns from a string column to an integer column:
-
channel -
seller -
first_time_homebuyer -
loan_purpose -
property_type -
occupancy_status -
property_state -
product_type
-
-
Converts
first_payment_dateandorigination_dateto2columns each:- Splits the column on the forward slash.
-
Assigns the first part of the split list to a
monthcolumn. -
Assigns the second part of the split list to a
yearcolumn. - Deletes the column.
-
At the end, we'll have
first_payment_month,first_payment_year,origination_month, andorigination_year.
-
Fills any missing values in
acquisitionwith-1.
def annotate(acquisition, counts):
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
for column in [
"channel",
"seller",
"first_time_homebuyer",
"loan_purpose",
"property_type",
"occupancy_status",
"property_state",
"product_type"
]:
acquisition[column] = acquisition[column].astype('category').cat.codes
for start in ["first_payment", "origination"]:
column = "{}_date".format(start)
acquisition["{}_year".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(1))
acquisition["{}_month".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(0))
del acquisition[column]
acquisition = acquisition.fillna(-1)
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
return acquisition
Pulling Everything Together
We're almost ready to pull everything together, we just need to add a bit more code to annotate.py. In the below code, we:
- Define a function to read in the acquisition data.
-
Define a function to write the processed data to
processed/train.csv -
If this file is called from the command line, like
python annotate.py:- Read in the acquisition data.
-
Compute the counts for the performance data, and assign them to
counts. -
Annotate the
acquisitionDataFrame. -
Write the
acquisitionDataFrame totrain.csv.
def read():
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
return acquisition
def write(acquisition):
acquisition.to_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"), index=False)
if __name__ == "__main__":
acquisition = read()
counts = count_performance_rows()
acquisition = annotate(acquisition, counts)
write(acquisition)
Once you're done updating the file, make sure to run it with python annotate.py, to generate the train.csv file. You can find the complete annotate.py file here. The folder should now look like this:
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
│ ├── Acquisition.txt
│ ├── Performance.txt
│ ├── train.csv
├── .gitignore
├── annotate.py
├── assemble.py
├── README.md
├── requirements.txt
├── settings.pyFinding an Error Metric for Our Machine Learning Project
We're done with generating our training data set, and now we'll just need to do the final step, generating predictions. We'll need to figure out an error metric, as well as how we want to evaluate our data.
In this case, there are many more loans that aren't foreclosed on than are, so typical accuracy measures don't make much sense. If we read in the training data, and check the counts in the foreclosure_status column, here's what we get:
import pandas as pd
import settings
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
train["foreclosure_status"].value_counts()
False 4635982
True 1585
Name: foreclosure_status, dtype: int64
Since so few of the loans were foreclosed on, just checking the percentage of labels that were correctly predicted will mean that we can make a machine learning model that predicts False for every row, and still gets a very high accuracy. Instead, we'll want to use a metric that takes the class imbalance into account, and ensures that we predict foreclosures accurately.
We don't want too many false positives, where we make predictions that a loan will be foreclosed on even though it won't, or too many false negatives, where we predict that a loan won't be foreclosed on, but it is. Of these two, false negatives are more costly for Fannie Mae, because they're buying loans where they may not be able to recoup their investment.
We'll define false negative rate as the number of loans where the model predicts no foreclosure but the loan was actually foreclosed on, divided by the number of total loans that were actually foreclosed on. This is the percentage of actual foreclosures that the model "Missed".
Here's a diagram:
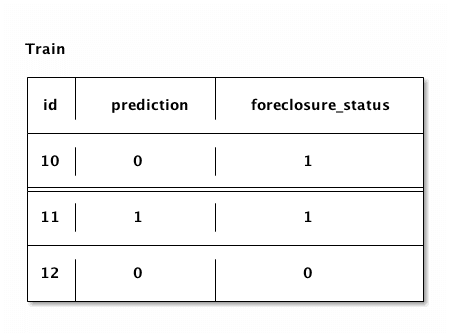
In the diagram above, 1 loan was predicted as not being foreclosed on, but it actually was. If we divide this by the number of loans that were actually foreclosed on, 2, we get the false negative rate, 50%. We'll use this as our error metric, so we can evaluate our model's performance.
Setting up the Classifier for Machine Learning
We'll use cross-validation to make predictions. With cross-validation, we'll divide our data into 3 groups. Then we'll do the following:
-
Train a model on groups
1and2, and use the model to make predictions for group3. -
Train a model on groups
1and3, and use the model to make predictions for group2. -
Train a model on groups
2and3, and use the model to make predictions for group1.
Splitting it up into groups this way means that we never train a model using the same data we're making predictions for. This avoids overfitting. If we overfit, we'll get a falsely low false negative rate, which makes it hard to improve our algorithm or use it in the real world. Scikit-learn has a function called cross_val_predict which will make it easy to perform cross validation.
We'll also need to pick an algorithm to use to make predictions. We need a classifier that can do binary classification. The target variable, foreclosure_status only has two values, True and False. We'll use logistic regression, because it works well for binary classification, runs extremely quickly, and uses little memory. This is due to how the algorithm works — instead of constructing dozens of trees, like a random forest, or doing expensive transformations, like a support vector machine, logistic regression has far fewer steps involving fewer matrix operations. We can use the logistic regression classifier algorithm that's implemented in scikit-learn.
The only thing we need to pay attention to is the weights of each class. If we weight the classes equally, the algorithm will predict False for every row, because it is trying to minimize errors. However, we care much more about foreclosures than we do about loans that aren't foreclosed on. Thus, we'll pass balanced to the class_weight keyword argument of the LogisticRegression class, to get the algorithm to weight the foreclosures more to account for the difference in the counts of each class. This will ensure that the algorithm doesn't predict False for every row, and instead is penalized equally for making errors in predicting either class.
Making Predictions
Now that we have the preliminaries out of the way, we're ready to make predictions. We'll create a new file called predict.py that will use the train.csv file we created in the last step. The below code will:
- Import needed libraries.
-
Create a function called
cross_validatethat:- Creates a logistic regression classifier with the right keyword arguments.
-
Creates a list of columns that we want to use to train the model, removing
idandforeclosure_status. -
Run cross validation across the
trainDataFrame. - Return the predictions.
import os
import settings
import pandas as pd
from sklearn.model_selection import cross_validation
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
def cross_validate(train):
clf = LogisticRegression(random_state=1, class_weight="balanced")
predictors = train.columns.tolist()
predictors = [p for p in predictors if p not in settings.NON_PREDICTORS]
predictions = cross_validation.cross_val_predict(clf, train[predictors], train[settings.TARGET], cv=settings.CV_FOLDS)
return predictions
Predicting Error
Now, we just need to write a few functions to compute error. The below code will:
-
Create a function called
compute_errorthat:-
Uses scikit-learn to compute a simple accuracy score (the percentage of predictions that matched the actual
foreclosure_statusvalues).
-
Uses scikit-learn to compute a simple accuracy score (the percentage of predictions that matched the actual
-
Create a function called
compute_false_negativesthat:- Combines the target and the predictions into a DataFrame for convenience.
- Finds the false negative rate.
-
Create a function called
compute_false_positivesthat:- Combines the target and the predictions into a DataFrame for convenience.
-
Finds the false positive rate.
- Finds the number of loans that weren't foreclosed on that the model predicted would be foreclosed on.
- Divide by the total number of loans that weren't foreclosed on.
def compute_error(target, predictions):
return metrics.accuracy_score(target, predictions)
def compute_false_negatives(target, predictions):
df = pd.DataFrame({"target": target, "predictions": predictions})
return df[(df["target"] == 1) & (df["predictions"] == 0)].shape[0] / (df[(df["target"] == 1)].shape[0] + 1)
def compute_false_positives(target, predictions):
df = pd.DataFrame({"target": target, "predictions": predictions})
return df[(df["target"] == 0) & (df["predictions"] == 1)].shape[0] / (df[(df["target"] == 0)].shape[0] + 1)
Putting It All Together
Now, we just have to put the functions together in predict.py. The below code will:
- Read in the data set.
- Compute cross validated predictions.
-
Compute the
3error metrics above. - Print the error metrics.
def read():
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
return train
if __name__ == "__main__":
train = read()
predictions = cross_validate(train)
error = compute_error(train[settings.TARGET], predictions)
fn = compute_false_negatives(train[settings.TARGET], predictions)
fp = compute_false_positives(train[settings.TARGET], predictions)
print("Accuracy Score: {}".format(error))
print("False Negatives: {}".format(fn))
print("False Positives: {}".format(fp))
Once you've added the code, you can run python predict.py to generate predictions. Running everything shows that our false negative rate is .26, which means that of the foreclosed loans, we missed predicting 26% of them.
This is a good start, but can use a lot of improvement! You can find the complete predict.py file here. Your file tree should now look like this:
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
│ ├── Acquisition.txt
│ ├── Performance.txt
│ ├── train.csv
├── .gitignore
├── annotate.py
├── assemble.py
├── predict.py
├── README.md
├── requirements.txt
├── settings.py
Writing Up a README
Now that we've finished our end to end project, we just have to write up a README.md file so that other people know what we did, and how to replicate it. A typical README.md for a project should include these sections:
- A high level overview of the project, and what the goals are.
- Where to download any needed data or materials.
-
Installation instructions.
- How to install the requirements.
-
Usage instructions.
- How to run the project.
- What you should see after each step.
-
How to contribute to the project.
- Good next steps for extending the project.
Here's a sample README.md for this project.
Next Steps
Congratulations, you're done making an end to end machine learning project! You can find a complete example project here.
It's a good idea to upload your project to Github once you've finished it, so others can see it as part of your portfolio. There are still quite a few angles left to explore with this data. Broadly, we can split them up into 3 categories -- extending this project and making it more accurate, finding other columns to predict, and exploring the data. Here are some ideas:
-
Generate more features in
annotate.py. -
Switch algorithms in
predict.py. - Try using more data from Fannie Mae than we used in this post.
- Add in a way to make predictions on future data. The code we wrote will still work if we add more data, so we can add more past or future data.
-
Try seeing if you can predict if a bank should have issued the loan originally (vs if Fannie Mae should have acquired the loan).
-
Remove any columns from
trainthat the bank wouldn't have known at the time of issuing the loan.- Some columns are known when Fannie Mae bought the loan, but not before.
- Make predictions.
-
Remove any columns from
-
Explore seeing if you can predict columns other than
foreclosure_status.- Can you predict how much the property will be worth at sale time?
-
Explore the nuances between performance updates.
- Can you predict how many times the borrower will be late on payments?
- Can you map out the typical loan lifecycle?
-
Map out data on a state by state or zip code by zip code level.
- Do you see any interesting patterns?
If you build anything interesting, please share in the community.
Next steps
If you liked this, you might like to read the other posts in our ‘Build a Data Science Portfolio’ series: