How to Present Your Data Science Portfolio on GitHub
Part One — git and GitHub tutorial
GitHub is built around a technology called git, a distributed version control system. This may sound intimidating, but all it means is that it lets you create checkpoints of your code at various points in time, then switch between those checkpoints at will. For example, let's say I have the following Python script, taken from the scikit-learn examples:
lr = linear_model.LinearRegression()
boston = datasets.load_boston()
y = boston.target
predicted = cross_val_predict(lr, boston.data, y, cv=10)
I now make a checkpoint using git, and add some more lines to the code. In the below code, we:
- Change the dataset
- Change the number of CV folds
- Show a plot
lr = linear_model.LinearRegression()
diabetes = datasets.load_diabetes()
y = diabetes.target
predicted = cross_val_predict(lr, diabetes.data, y, cv=20)
fig, ax = plt.subplots()
ax.scatter(y, predicted)
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
plt.show()
If we make another checkpoint with git, we'll be able to go back to the first checkpoint whenever we want, and switch between the two freely. A checkpoint is more commonly known as a commit, and we'll be using that term going forward. We can upload the commits to GitHub, which enables other people to see our code. git is much more powerful than just a commit system, and you should try our git course if you want to learn more. However, for the purposes of uploading your portfolio, it's fine to think of it this way.
Setting up git and Github
In order to create a commit with git and upload it to GitHub, you first need to install and configure git. The full instructions are here, but we'll summarize the steps here:
- Install git using this link
- Open the terminal application on your computer
-
Set up your git email by typing:
$ git config --global user.email YOUR_EMAILReplace
YOUR_EMAILwith an email account. -
Set up your git name by typing:
$ git config --global user.name YOUR_NAMEReplace
YOUR_NAMEwith your full name, likeJohn Smith.
Once you've done this, git is setup and configured. Next, we need to create an account on GitHub, then configure git to work with GitHub:
- Create a GitHub account. Ideally, you should use the same email you used earlier to configure git.
- Create an SSH key
- Add the key to your GitHub account
The above setup will let you push commits to GitHub, and pull commits from Github.
Creating a repository
Commits in git occur inside of a repository. A repository is analogous to the folder your project is in. For this part of the tutorial, we'll use a folder with a file structure like this:
loans
│ README.md
│ main.py
│
└───data
│ test.csv
│ train.csv
You can download the zip file of the folder yourself here and use it in the next steps. You can extract it with any program that unzips files. The git repository in the above diagram would be the project folder, or loans. In order to create commits, we first need to initialize the folder as a git repository. We can do this by navigating to the folder, then typing git init:
$ cd loans
$ git init
Initialized empty Git repository in /loans/.git/
This will create a folder called .git inside the loans folder. You'll get output indicating that the repository was initialized properly. git uses the .git folder to store information about commits:
loans
│ README.md
│ main.py
└───.git
│
└───data
│ test.csv
│ train.csv
The contents of the .git folder aren't necessary to explore in this tutorial, but you may want to look through and see if you can figure out how the commit data is stored. After we've initialized the repository, we need to add files to a potential commit. This adds files to a staging area. When we're happy with the files in the staging area, we can generate a commit. We can do this using git add:
$ git add README.mdThe above command will add the README.md file to the staging area. This doesn't change the file on disk, but tells git that we want to add the current state of the file to the next commit. We can check the status of the staging area with git status:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.md
Untracked files:
(use "git add </file><file>..." to include in what will be committed)
data/
main.py
</file>You'll see that we've added the README.md file to the staging area, but there are still some untracked files, that haven't been added. We can add all the files with git add .. After we've added all the files to the staging area, we can create a commit using git commit:
$ git commit -m "Initial version"
[master (root-commit) 907e793] Initial version
4 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 README.md
create mode 100644 data/test.csv
create mode 100644 data/train.csv
create mode 100644 main.py
The -m option specifies a commit message. You can look back on commit messages later to see what files and changes are contained in a commit. A commit takes all the files from the staging area, and leaves the staging area empty.
Making changes to a repository
When we make further changes to a repository, we can add the changed files to the staging area and make a second commit. This allows us to keep a history of the repository over time. We can add changes to a commit the same way we did before. Lets say we change the README.md file. We'd first run git status to see what changed:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- </file><file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
We can then see exactly what changed with git diff. If the changes are what we expected, we can add these changes to a new commit:
$ git add .And then we can commit again:
$ git commit -m "Update README.md"
[master 5bec608] Update README.md
1 file changed, 1 insertion(+) You may have noticed that the word master appears after many of these commands are executed. master is the name of the branch that we're currently on. Branches allow multiple people to work on a repository at once, or one person to work on multiple features at the same time. Branches are extremely powerful, but we won't dive into them here. If you're interested in learning more, our Dataquest interactive git tutorial covers working with multiple branches in detail. For now, it's enough to know that the primary branch in a repository is called master. We've made all of our changes so far to the master branch. We'll be pushing master to GitHub, and this is what other people will see.
Pushing to GitHub
Once you've created a commit, you're ready to push your repository to GitHub. In order to do this, you first need to create a public repository in the GitHub interface. You can do this by:
- Clicking the "+" icon in the top right of the GitHub interface, then "New Repository".
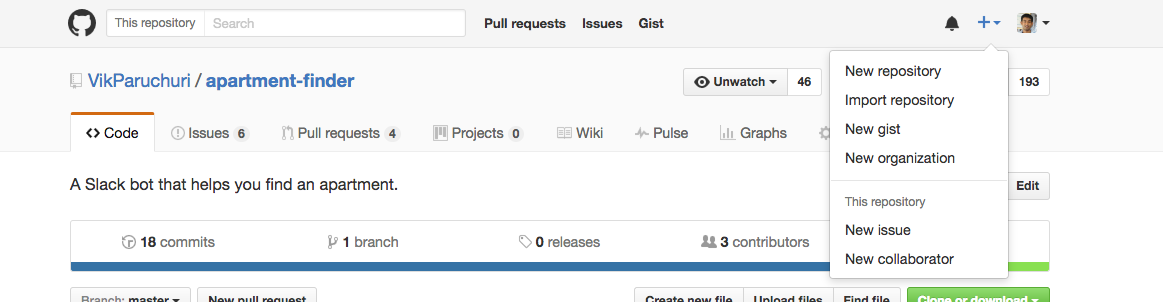
Create a GitHub repository.
- Enter a name for the repository, and optionally enter a description. Then, decide if you want it to be public or private. If it's public, anyone can see it immediately. You can change a repository from public to private, or vice versa, at any time. It's recommended to keep the repository private until it's ready to share. Note that creating a private repository requires a paid plan. When you're ready, click "Create Repository" to finalize.
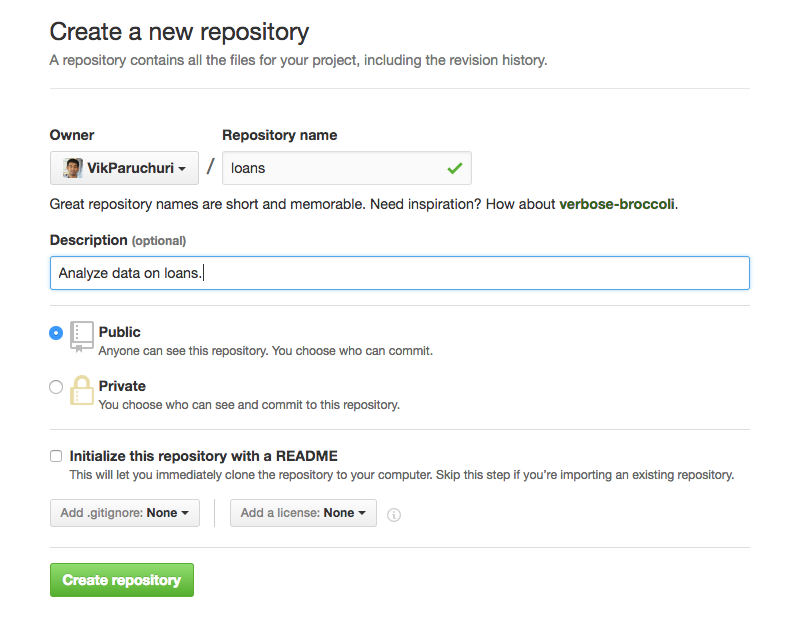
Finalize repository creation.
After creating the repo, you'll see a screen like this:
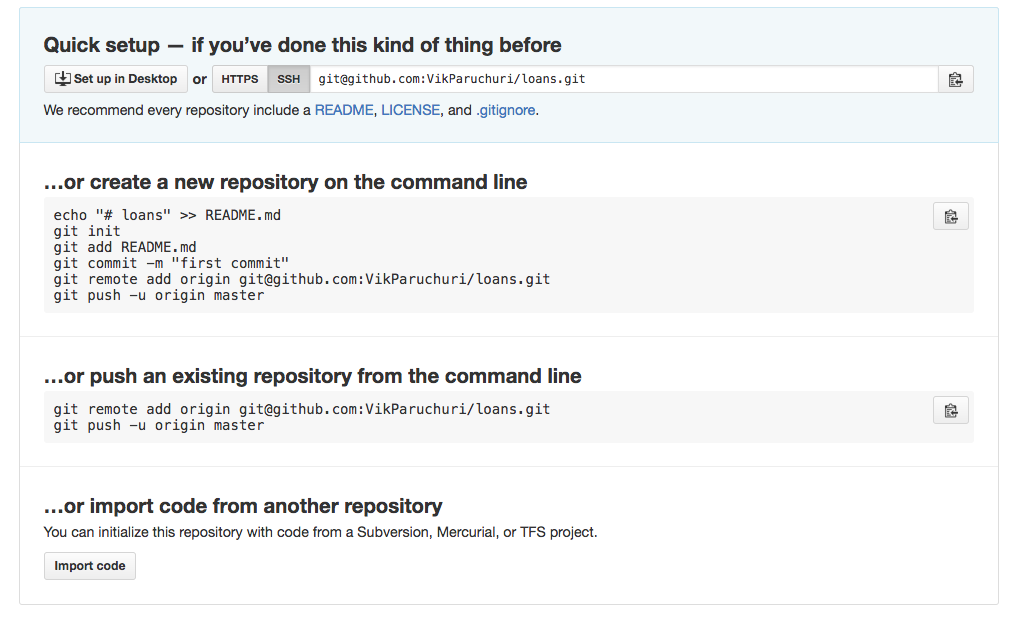
The options for using the repository.
Look under the "…or push an existing repository from the command line" section, and copy the two lines there. Then run them in the command line:
$ cd loans
$ git remote add origin [email protected]:YOUR_GITHUB_USERNAME/YOUR_GIT_REPO_NAME.git
$ git push -u origin master
Counting objects: 7, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 608 bytes | 0 bytes/s, done.
Total 7 (delta 0), reused 0 (delta 0)
To [email protected]:YOUR_GITHUB_USERNAME/YOUR_GIT_REPO_NAME.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin. If you reload the page on GitHub corresponding to your repo, you should now see the files you added. By default, the README.md will be rendered in the repository: 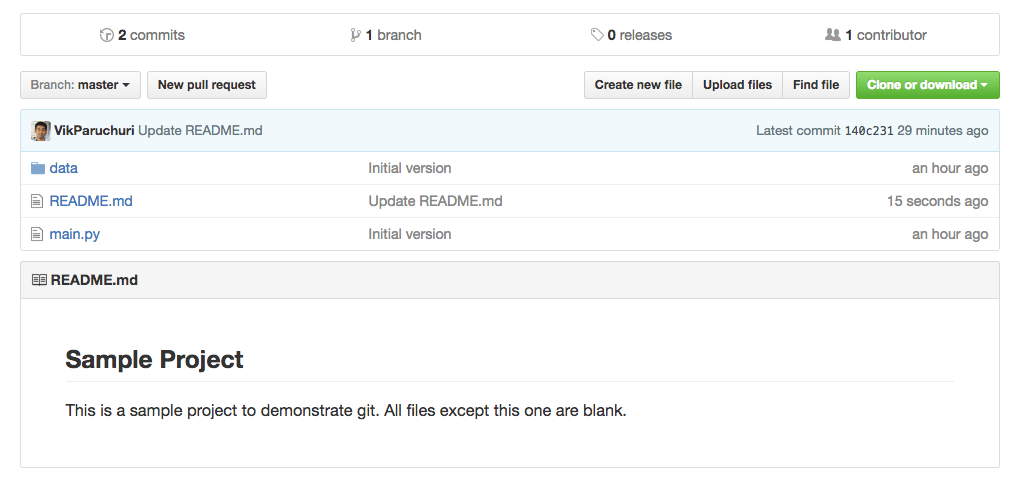
Viewing the project files and README.
Congratulations! You've now pushed a repository to GitHub. If you want to make it public, you can follow these instructions.
Part Two — Presenting your portfolio
Now that you know how to create and upload a repository, we'll cover how to present it. Before we go through this section, it may be useful to look at some example projects:
Requirements
It's important to make sure anyone can install and run your work. Even if your work is a Jupyter Notebook, there may be packages other people need to install. You can list out all the packages your project is using with pip freeze if you're using a virtual environment. You'll get output like this:
$ pip freeze
Django==1.10.5
MechanicalSoup==0.6.0
Pillow==4.0.0
The output is the library name, then a version number. The above output tells us that we have Django version 1.10.5 installed, for example. You'll want to copy these requirements into a folder in your project called requirements.txt. The file should look like this:
Django==1.10.5
MechanicalSoup==0.6.0
Pillow==4.0.0
Now, anyone can install the requirements for your project using:
$ pip install -r requirements.txtThis will install the exact version of the libraries that we have on our machine. If you want to instead install whatever the latest version of each library is, you can leave off the version numbers in requirements.txt:
Django
MechanicalSoup
Pillow
If you want to make a requirements.txt file, but didn't use a virtualenv for your project, you'll want to manually look through the libraries you imported in your project, and add them to requirements.txt without version numbers, like:
pandas
numpy
Pillow
Paths
It's common when you're working locally to hardcode absolute paths to data files, like /Users/vik/Documents/data.csv. Other people who want to run your project won't have those same paths on their computer, so they won't be able to run your project. You can fairly easily replace these with relative paths, which allow people who have the data in the same folder as your project, but don't have the same absolute paths, to use your code. Let's say we have this code:
with open("/Users/vik/Documents/data.csv") as f:
data = f.read()
Let's say our project code is at /Users/vik/Documents/Project.ipynb. We can replace the code with a relative path, like:
with open("data.csv") as f:
data = f.read()
It's generally a good idea to put the data in the same folder as your project, or in a subfolder, to make relative paths and loading the data easier.
Additional files
By default, running git add . and git commit -m "Message"" will add all the files in a folder to a git commit. However, there are many artifact files that you don't want added. Here's an example folder:
loans
│ __pycache__
│ main.py
│ main.pyc
│ temp.json
│
└───data
│ test.csv
│ train.csv
Note files like __pycache__, main.pyc, and temp.json. The main code of the project is in main.py, and the data is in data/test.csv, and data/train.csv. For someone to run the project, those are the only files they need. Folders like __pycache__ and main.pyc are automatically generated by Python when we run code or install packages. These enable Python scripts and package installation to be faster and more reliable. However, these files aren't part of your project, and thus shouldn't be distributed to others. We can ignore files like this with a .gitignore file. We can add a .gitignore file to our folder:
loans
│ .gitignore
│ __pycache__
│ main.py
│ main.pyc
│ temp.json
│
└───data
│ test.csv
│ train.csv
The content of the .gitignore file is a list of files to ignore. We can create a .gitignore file, then add *.pyc and __pycache__ to ignore the generated files in our folder:
*.pyc
__pycache__
This still leaves the temp.json file. We can add another line to ignore this file:
*.pyc
__pycache__
temp.json
This will ensure that these files are not tracked by git, and added to new git commits when you run git add .. However, if you've already added the files to a git commit before, you'll need to remove them first with git rm temp.json --cached. It's recommended to create a .gitignore file as soon as possible, and to add entries for temporary files quickly. You can find a good starter gitignore file here. It's usually recommended to use this as your .gitignore file, then add new entries as needed. It's a good idea to ignore any dynamic, generated, or temporary files. You should only commit your source code, documentation, and data (depending on how large your data is -- we'll cover this in another section).
Secret keys or files
Many projects use secret keys to access resources. A good example is api keys, such as AWS_ACCESS_KEY="3434ffdsfd". You absolutely don't want to share your secret keys with other people -- this allows them to access your resources, and could cost you money. Here's some example code that uses a secret key:
import forecastio
forecast = forecastio.load_forecast("34343434fdfddf", 37.77493, -122.41942)
In the above code, "34343434fdfddf" is a secret key that we're passing into a library to get a weather forecast. If we commit the code as is, anyone browsing Github will be able to see our secret data. Fortunately, there's an easy way to fix this, and enable anyone using the project to supply their own keys, so they can still run the code. First, we create a file called settings.py, with the following lines:
API_KEY = ""
try:
from .private import *
except Exception:
pass
The above code defines a key called API_KEY. It also tries to import from a file called private.py, and doesn't do anything if the file doesn't exist. We then need to add a private.py with the following content:
API_KEY = "34343434fdfddf"Then, we need to add private.py to .gitignore so it doesn't get committed:
private.pyThen, we modify our original code:
import settings
forecast = forecastio.load_forecast(settings.API_KEY, 37.77493, -122.41942)
All the changes we've made above result in the following:
- The code imports the settings file
-
The settings file imports the
private.pyfile-
This overwrites the
API_KEYvariable in the settings file with theAPI_KEYdefined in the private file
-
This overwrites the
-
The code uses
API_KEYfrom the settings file, which equals"34343434fdfddf"
The next time you make a git commit, private.py will be ignored. However, if someone else looks at your repository, they'll see that they need to fill out settings.py with their own settings to get things to work properly. So everything will work for you, you won't share your secret keys with others, and things will work for others.
Large or restricted data files
It's important to look at the user agreement when you're downloading a data file. Some files are not allowed to be redistributed. Some files are also too large to make downloading useful. Other files are updated quickly, and distributing them doesn't make sense — you want the user to download a fresh copy. In cases like these, it makes sense to add the data files to the .gitignore file. This ensures that the data file won't be included in the repository. It's important to have information on how to download the data in the README.md, though. We'll cover this in the next section.
The README file
The README file is very critical to your project. The README is usually named README.md, and is in Markdown format. GitHub will automatically parse Markdown format and render it. Your README file should describe:
- The goals of your project
- Your though process and methods in creating the project
- How to install your project
- How to run your project
You want an average technically competent stranger to be able to read your README file and then run the project on their own. This ensures that more technical hiring managers can reproduce your work and check your code. You can find good README examples here and here. It's important to go through the installation steps yourself in a new folder or on a new computer, to make sure everything works. The README is also the first and potentially only thing someone will look at, because GitHub renders it below the repository file view. It's important to "sell" what the project is, why you made it, and what's interesting about it. Here's an example:
# Loan Price Prediction
In this project, I analyzed data on loans issued through the [LendingClub](https://www.lendingclub.com/) platform. On the LendingClub platform, potential lenders see some information about potential borrowers, along with an interest rate they'll be paid. The potential lenders then decide if the interest on the loan is worth the risk of a default (the loan not being repaid), and decide whether to lend to the borrower. LendingClub publishes anonymous data about its loans and their repayment rates.
Using the data, I analyzed factors that correlated with loans being repaid on time, and did some exploratory visualization and analysis. I then created a model that predicts the chance that a loan will be repaid given the data surfaced on the LendingClub site. This model could be useful for potential lenders trying to decide if they should fund a loan. You can see the exploratory data analysis in the Exploration.ipynb notebook above. You can see the model code and explanations in the algo folder.
Your README should be more extensive and go into more depth than the above example, but this is a good starting point. Ideally, you'd also want:
- Some bullet points with interesting observations you found in exploration
- Any interesting charts or diagrams you created
- Information about the model, such as algorithm
- Error rates and other information about the predictions
- Any notes about real-world usage of the model
The summary here is that the README is the best way to sell your project, and you shouldn't neglected. Don't spend a lot of effort making a good project, then have people skip looking through it because they don't find it interesting!
Inline explanations
If you're writing Python script files, you'll want to include lots of inline comments to make your logic easier to follow. You don't want to share something like this:
def count_performance_rows():
counts = {}
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
for i, line in enumerate(f):
if i == 0:
continue
loan_id, date = line.split("|")
loan_id = int(loan_id)
if loan_id not in counts:
counts[loan_id] = {
"foreclosure_status": False,
"performance_count": 0
}
counts[loan_id]["performance_count"] += 1
if len(date.strip()) > 0:
counts[loan_id]["foreclosure_status"] = True
return counts
A better alternative is:
def count_performance_rows():
"""
A function to count the number of rows that deal with performance for each loan.
Each row in the source text file is a loan_id and date.
If there's a date, it means the loan was foreclosed on.
We'll return a dictionary that indicates if each loan was foreclosed on, along with the number of performance events per loan.
"""
counts = {}
# Read the data file.
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
for i, line in enumerate(f):
if i == 0:
# Skip the header row
continue
# Each row is a loan id and a date, separated by a |
loan_id, date = line.split("|")
# Convert to integer
loan_id = int(loan_id)
# Add the loan to the counts dictionary, so we can count the number of performance events.
if loan_id not in counts:
counts[loan_id] = {
"foreclosure_status": False,
"performance_count": 0
}
# Increment the counter.
counts[loan_id]["performance_count"] += 1
# If there's a date, it indicates that the loan was foreclosed on
if len(date.strip()) > 0:
counts[loan_id]["foreclosure_status"] = True
return counts
In the above, it's much more clear what the function is doing, and why. It's important to reduce the mental effort of following your logic as much as possible. Reading code is time consuming, and not everyone looking through your project will make that investment. Comments make things smoother, and ensure that more people read through your project.
Jupyter Notebooks
Jupyter Notebooks, like this one, are automatically rendered by GitHub, so people can view them in the browser. It's important to verify a few things for every notebook you upload:
- Make sure it looks good when it renders in the interface
-
Make sure explanations are frequent, and it's clear what's happening at each step
- A good ratio is no more than 2 code cells per markdown cell
- Ensure all explanations in the notebook are clear and easy to follow. You can learn more about this in our previous blog post.
- Make sure the README links to the notebook, and briefly explains what you did in the notebook
The second and last steps is especially important. You want people to be able to easily figure out that your analysis is in the notebook, and what analysis you did. A notebook with only code cells is very hard to follow, and doesn't demonstrate your data science skills. Employers are looking for people who can code
and communicate effectively.
Making your work public
After you've followed all the steps above, you'll want to do a final review of your project, then set it public! You can do this from the repository settings button:

The repository settings button is at the right.
Next Steps
You now know how to put projects on GitHub, and hopefully have a few projects you can upload. The next step is to add your projects to your resume and portfolio pages. Some things to consider:
- If you have a blog, write about each project as a separate post that goes into depth about how you built it, and what you found
- Add your projects to your LinkedIn profile
- Add your projects to your AngelList profile
- List your projects on your resume
- If you have a personal website, make a portfolio page that lists your projects
If you have dozens of projects, and don't want to add links to each repository in your resume, one strategy is to make a single Github repository called portfolio. In the README of this repository, list all of your projects, along with a short explanation of each one and a link. This will enable you to share a single link, but still let people see all of your projects. Make sure to provide good explanations, so people are willing to click through! You should now know enough to put your portfolio on Github, and impress hiring managers. If you have any comments or feedback about the post, we'd love to hear from you.
Next steps
If you liked this, you might like to read the other posts in our ‘Build a Data Science Portfolio’ series: