30+ Data Engineering Interview Questions and Answers for 2026 [Entry-Level Guide With Code]
You have a data engineering interview coming up and you’re not sure what to expect. Maybe you’re switching careers, recently finished a bootcamp, or self-taught your way here. Either way, you need to know what questions will actually be asked, and how to answer them.
This guide covers 30+ data engineering interview questions specifically for entry-level candidates. Unlike other guides that dump 100 questions without context, we include code examples for every technical question and explain what interviewers are really evaluating. One hiring manager put it this way:

This guide will help you prepare for your data engineering interview. We’ll cover SQL, Python, data modeling, ETL pipelines, system design basics, and behavioral questions, the exact categories that appear in real interviews. You’ll also learn the red flags that get candidates rejected, straight from practitioners who conduct these interviews.
If you need to build these skills before your interview, Dataquest's Data Engineering Career Path and Data Engineering Roadmap can help. But first, let's understand what you're walking into.
What's Inside
- Understanding the Interview Process
- SQL Interview Questions (8 questions)
- Python Interview Questions (6 questions)
- Data Modeling Questions (4 questions)
- ETL/ELT and Pipeline Questions (4 questions)
- System Design for Entry-Level (2 questions)
- Modern Data Stack & Governance (5 questions)
- Behavioral Questions (4 questions)
- Mistakes That Get Candidates Rejected
- How to Prepare
- FAQs
Understanding the Data Engineering Interview Process
Before tackling specific questions, you need to understand how data engineering interviews are structured. The process typically involves 3-6 rounds, though this varies significantly by company type.
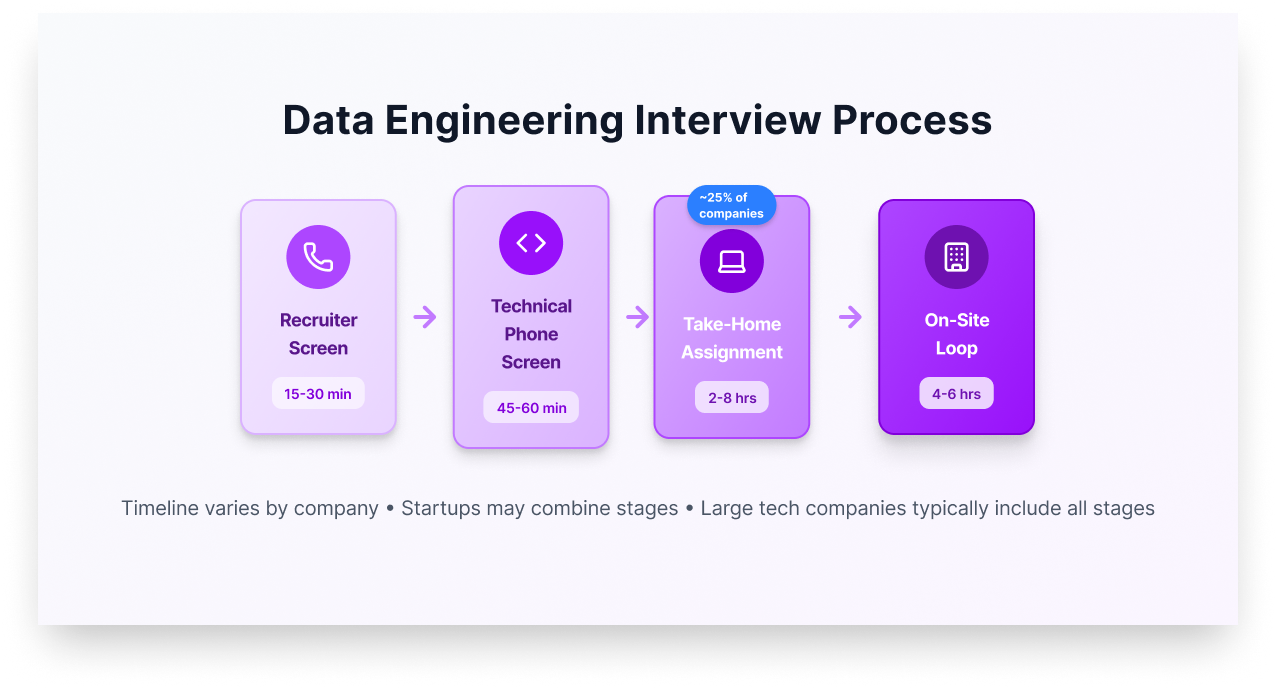
Typical interview stages:
The process usually starts with a recruiter screen (15-30 minutes) covering your background, salary expectations, and basic fit. Next comes a technical phone screen (45-60 minutes) with 1-3 coding problems and SQL questions. About 25% of companies include a take-home assignment lasting 2-8 hours. Finally, you’ll face an on-site loop (4-6 hours total) covering coding, SQL, system design, data modeling, and behavioral questions.
How interviews differ by company type:
At startups, expect 2-3 compressed rounds focused on day-one contribution. They want to know if you can ship quickly. Big tech companies run 4-6 standardized rounds with more emphasis on system design and scale. Traditional enterprises vary widely, some focus heavily on legacy systems like Informatica or SSIS.
What interviewers actually evaluate:
Technical skills matter, but they’re not everything. Hiring managers consistently mention these evaluation criteria: how you think through problems (not just whether you get the right answer), your ability to explain technical concepts clearly, whether you ask clarifying questions before jumping into solutions, and your honesty about what you don’t know.
One practitioner shared a common mistake: “In the architecture round, if they speak about what tools they would use instead of what problem they are trying to solve, that’s a concer” Focus on demonstrating problem-solving, not tool memorization.
SQL Interview Questions
SQL is the foundation of every data engineering interview. You’ll face SQL questions in almost every technical round, so this section deserves serious preparation.
Entry-Level SQL Questions
Q1: What is the difference between INNER JOIN, LEFT JOIN, and FULL OUTER JOIN?
-- INNER JOIN: Returns only matching rows from both tables
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.id;
-- LEFT JOIN: Returns all rows from left table, matching rows from right
SELECT e.name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.id;
-- FULL OUTER JOIN: Returns all rows from both tables
SELECT e.name, d.department_name
FROM employees e
FULL OUTER JOIN departments d ON e.dept_id = d.id;Why interviewers ask this: They want to confirm you understand relational data and can choose the right join for business requirements. Many candidates confuse LEFT and INNER joins, which leads to missing or duplicated data in production.
Bonus gotcha (real interview trap): Some SQL systems like MySQL don't support FULL OUTER JOIN. Interviewers sometimes include it on purpose, not to see if you've memorized syntax, but to see if you notice when a query won't run in the real world and can explain a workaround (typically LEFT JOIN + RIGHT JOIN with UNION, while handling duplicates).
Q2: Explain the difference between WHERE and HAVING clauses.
-- WHERE filters rows BEFORE grouping
SELECT department, COUNT(*) as emp_count
FROM employees
WHERE salary > 50000
GROUP BY department;
-- HAVING filters groups AFTER aggregation
SELECT department, COUNT(*) as emp_count
FROM employees
GROUP BY department
HAVING COUNT(*) > 5;Why interviewers ask this: This tests whether you understand the SQL execution order. WHERE filters individual rows before GROUP BY runs. HAVING filters the aggregated results after grouping. Mixing these up causes queries to fail or return wrong results.
Q3: Write a query to find duplicate records in a table.
-- Find duplicate emails
SELECT email, COUNT(*) as occurrence
FROM users
GROUP BY email
HAVING COUNT(*) > 1;
-- Find and return the actual duplicate rows
SELECT *
FROM users
WHERE email IN (
SELECT email
FROM users
GROUP BY email
HAVING COUNT(*) > 1
);Why interviewers ask this: Duplicate detection is a daily task in data engineering. Dirty source data, failed pipeline retries, and merge issues all create duplicates. This question tests practical problem-solving, not just syntax knowledge.
Intermediate SQL Questions
Q4: What is a CTE (Common Table Expression) and when would you use one?
-- Without CTE: Nested, hard to read
SELECT *
FROM orders
WHERE customer_id IN (
SELECT customer_id
FROM customers
WHERE region = 'West'
AND signup_date > '2024-01-01'
);
-- With CTE: Clear, readable, reusable
WITH west_customers AS (
SELECT customer_id
FROM customers
WHERE region = 'West'
AND signup_date > '2024-01-01'
)
SELECT o.*
FROM orders o
JOIN west_customers wc ON o.customer_id = wc.customer_id;Why interviewers ask this: CTEs are essential for writing maintainable SQL. If you can’t use CTEs, your production queries become unreadable nested messes. This is explicitly called out as a red flag by hiring managers.
Q5: Write a query using window functions to rank employees by salary within each department.
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) as salary_rank,
DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) as dense_salary_rank,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) as row_num
FROM employees;| name | department | salary | salary_rank | dense_salary_rank | row_num |
|---|---|---|---|---|---|
| Alice | Engineering | 150000 | 1 | 1 | 1 |
| Bob | Engineering | 150000 | 1 | 1 | 2 |
| Carol | Engineering | 120000 | 3 | 2 | 3 |
| Dan | Sales | 90000 | 1 | 1 | 1 |
Why interviewers ask this: Window functions separate junior SQL users from intermediate ones. RANK, DENSE_RANK, and ROW_NUMBER behave differently with ties, and choosing wrong creates incorrect analytics. This appears in almost every SQL interview.
Q6: Explain LEAD and LAG functions with an example.
-- Calculate day-over-day sales change
SELECT
sale_date,
daily_sales,
LAG(daily_sales, 1) OVER (ORDER BY sale_date) as previous_day,
daily_sales - LAG(daily_sales, 1) OVER (ORDER BY sale_date) as daily_change,
LEAD(daily_sales, 1) OVER (ORDER BY sale_date) as next_day
FROM daily_sales_summary;Why interviewers ask this: Time-series analysis is everywhere in data engineering—comparing today vs. yesterday, calculating running totals, identifying trends. LEAD/LAG are the tools for this work.
Advanced SQL Concepts
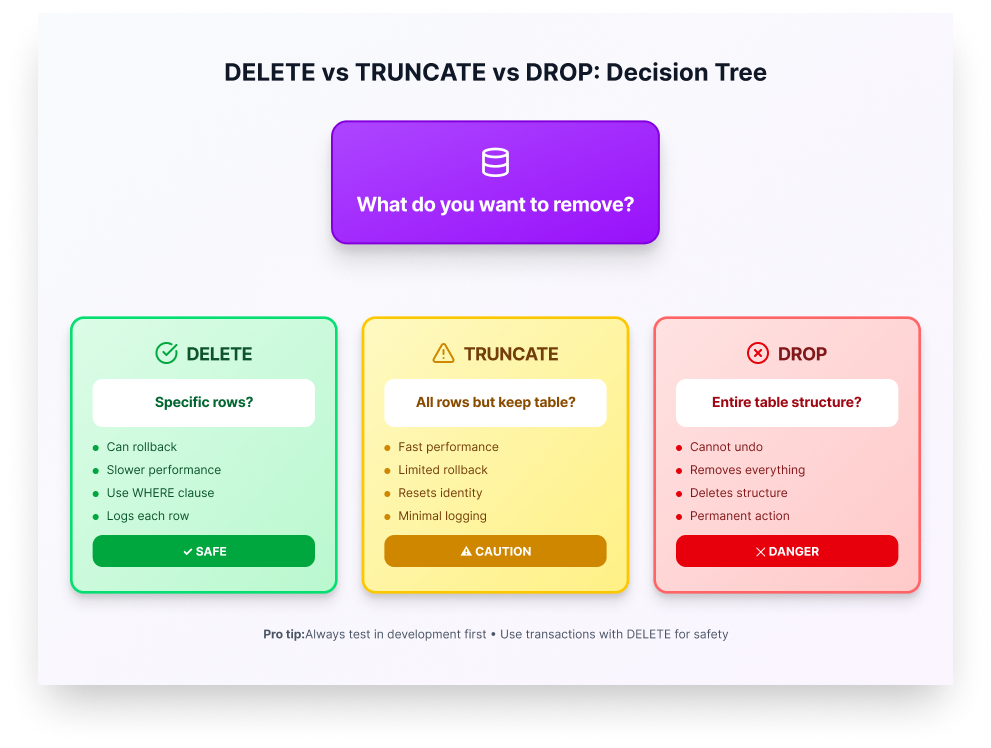
Q7: Explain the difference between DELETE, TRUNCATE, and DROP.
-- DELETE: Removes specific rows, can be rolled back, logs each row
DELETE FROM orders WHERE order_date < '2020-01-01';
-- TRUNCATE: Removes ALL rows, faster, minimal logging, resets identity
TRUNCATE TABLE temp_staging;
-- DROP: Removes the entire table structure
DROP TABLE old_backup_table;| Command | Removes | Rollback? | Speed | Use Case |
|---|---|---|---|---|
| DELETE | Specific rows | Yes | Slow | Selective removal |
| TRUNCATE | All rows | Limited | Fast | Clear staging tables |
| DROP | Entire table | No | Fast | Remove unused tables |
Important note: Exact behavior varies by database (e.g., transaction support, identity/sequence handling, logging).
Why interviewers ask this: Running the wrong command in production is a classic mistake. Interviewers want to know you understand the consequences before touching production data.
Q8: How would you optimize a slow-running query?
Answer framework:
- Check the execution plan using EXPLAIN / EXPLAIN ANALYZE
- Look for full table scans: Add indexes on filtered/joined columns (when appropriate)
- Check the join + filters: Confirm you’re joining on the right keys, and that your filters match the business logic
- Reduce data early: Filter rows before big joins/aggregations so the database has less work to do
- Avoid functions on indexed columns : WHERE YEAR(date_col) = 2024 can prevent index usage
- Consider partitioning for very large tables (especially time-based tables)
-- Before: Full table scan
SELECT * FROM orders WHERE YEAR(order_date) = 2024;
-- After: Index-friendly
SELECT * FROM orders
WHERE order_date >= '2024-01-01' AND order_date < '2025-01-01';Why interviewers ask this: Slow queries cost money and frustrate users. Data engineers must diagnose and fix performance issues, not just write queries that work.
For more SQL practice, see Dataquest’s SQL Interview Questions guide and SQL JOINs Interview Questions.
Python Interview Questions
Python is the dominant language in data engineering, appearing in 74% of job postings, so yo need to know it. But interviewers care how you write your Python code, not just whether it works. They’re looking for code that’s clear, maintainable, and safe to run in real pipelines where data is messy, volumes are large, and failures happen.
Python Fundamentals
Q9: What’s wrong with this code, and how would you fix it?
# Red flag version
data = ['apple', 'banana', 'cherry']
for i in range(0, len(data)):
print(data[i])
# Idiomatic Python
data = ['apple', 'banana', 'cherry']
for item in data:
print(item)
# If you need the index too
for i, item in enumerate(data):
print(f"{i}:{item}")Why interviewers ask this: This tests whether you write readable, Pythonic code. The range(len()) pattern is a red flag because it adds complexity without benefit. Code readability matters in production systems maintained by teams.
Q10: Explain the difference between a list and a dictionary. When would you use each?
# List: Ordered collection, access by index
fruits = ['apple', 'banana', 'cherry']
print(fruits[0]) # O(1) access by index
print('apple' in fruits) # O(n) search
# Dictionary: Key-value pairs, access by key
fruit_prices = {'apple': 1.50, 'banana': 0.75, 'cherry': 3.00}
print(fruit_prices['apple']) # O(1) access by key
print('apple' in fruit_prices) # O(1) searchWhy interviewers ask this: Choosing the right data structure affects performance. If you’re checking membership frequently, a dictionary (or set) is O(1) vs. O(n) for a list. This matters when processing millions of records.
Q11: Write a function to validate data quality in a DataFrame.
import pandas as pd
def validate_dataframe(df, rules):
"""
Validate a DataFrame against specified rules.
Returns dict with validation results.
"""
results = {'passed': True, 'errors': []}
# Check for required columns
if 'required_columns' in rules:
missing = set(rules['required_columns']) - set(df.columns)
if missing:
results['passed'] = False
results['errors'].append(f"Missing columns: {missing}")
# Check for null values in specified columns
if 'no_nulls' in rules:
for col in rules['no_nulls']:
null_count = df[col].isnull().sum()
if null_count > 0:
results['passed'] = False
results['errors'].append(f"{col} has{null_count} null values")
# Check for valid ranges
if 'ranges' in rules:
for col, (min_val, max_val) in rules['ranges'].items():
invalid = df[(df[col] < min_val) | (df[col] > max_val)]
if len(invalid) > 0:
results['passed'] = False
results['errors'].append(f"{col} has{len(invalid)} out-of-range values")
return results
# Usage
rules = {
'required_columns': ['user_id', 'email', 'age'],
'no_nulls': ['user_id', 'email'],
'ranges': {'age': (0, 120)}
}
df = pd.DataFrame() # Replace with your actual DataFrame
validation = validate_dataframe(df, rules)Why interviewers ask this: Data quality is a core responsibility. This tests whether you can write reusable validation code, not just one-off checks. Production pipelines need systematic quality gates.
Data Manipulation with Python
Q12: How do you handle missing data in pandas?
import pandas as pd
import numpy as np
df = pd.DataFrame({
'name': ['Alice', 'Bob', None, 'Diana'],
'age': [25, None, 35, 28],
'salary': [50000, 60000, None, 55000]
})
# Option 1: Remove rows with any missing values
df_clean = df.dropna()
# Option 2: Fill with a specific value
df['age'] = df['age'].fillna(df['age'].median())
# Option 3: Fill with forward/backward fill (for time series)
df['salary'] = df['salary'].fillna(method='ffill')
# Option 4: Add indicator column for missing values
df['salary_was_missing'] = df['salary'].isnull().astype(int)Why interviewers ask this: Every real dataset has missing values. Your choice of handling strategy (drop, fill, flag) depends on business context. Interviewers want to see you consider the tradeoffs.
Q13: How would you handle a dataset that doesn’t fit in memory?
# Option 1: Process in chunks with pandas
chunk_size = 100000
results = []
for chunk in pd.read_csv('large_file.csv', chunksize=chunk_size):
# Process each chunk
processed = chunk.groupby('category')['value'].sum()
results.append(processed)
final_result = pd.concat(results).groupby(level=0).sum()
# Option 2: Use Dask for larger-than-memory processing
import dask.dataframe as dd
ddf = dd.read_csv('large_file.csv')
result = ddf.groupby('category')['value'].sum().compute()
# Option 3: Use PySpark for distributed processing
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('large_data').getOrCreate()
df = spark.read.csv('large_file.csv', header=True, inferSchema=True)
result = df.groupBy('category').sum('value')Why interviewers ask this: Data engineers work with large datasets daily. This tests whether you know multiple approaches and can choose appropriately based on data size and infrastructure.
Q14: Write a function to connect to an API and handle rate limits.
import requests
import time
from typing import Optional, Dict, Any
def fetch_with_retry(
url: str,
max_retries: int = 5,
backoff_factor: float = 2.0
) -> Optional[Dict[Any, Any]]:
"""
Fetch data from API with exponential backoff for rate limits.
"""
for attempt in range(max_retries):
response = requests.get(url, timeout=10)
if response.status_code == 200:
return response.json()
elif response.status_code == 429: # Rate limited
wait_time = backoff_factor ** attempt
print(f"Rate limited. Waiting{wait_time}s before retry...")
time.sleep(wait_time)
else:
print(f"Error{response.status_code}:{response.text}")
return None
print(f"Failed after{max_retries} attempts")
return None
# Usage
data = fetch_with_retry('https://api.example.com/data')Why interviewers ask this: APIs are common data sources, and rate limiting is a real constraint. This tests practical skills. For example, can you build robust data ingestion that doesn’t break at 3 AM?
For more Python practice, explore Dataquest’s Python courses and Data Engineering Courses Catalog.
Data Modeling Interview Questions
One practitioner called data modeling “the most important part of any data engineering interview. In my professional opinion, this is the make or break round.” If you nail the technical coding but stumble here, you likely won’t get the offer.
Q15: Explain the difference between star schema and snowflake schema.
Star Schema:
- Fact table at the center, dimension tables connected directly
- Denormalized dimensions (some redundancy)
- Simpler queries, faster reads
- More storage space
Snowflake Schema:
- Dimensions are normalized into multiple related tables
- Less redundancy, better data integrity
- More complex queries with additional joins
- Less storage space
-- Star Schema: Simple query
SELECT
d.product_name,
SUM(f.sales_amount) as total_sales
FROM fact_sales f
JOIN dim_product d ON f.product_id = d.product_id
GROUP BY d.product_name;
-- Snowflake Schema: More joins needed
SELECT
p.product_name,
SUM(f.sales_amount) as total_sales
FROM fact_sales f
JOIN dim_product p ON f.product_id = p.product_id
JOIN dim_category c ON p.category_id = c.category_id
GROUP BY p.product_name;Why interviewers ask this: This is foundational data warehouse knowledge. Your choice impacts query performance, storage costs, and maintenance complexity.
Q16: What are fact tables and dimension tables?
Fact tables contain measurable, quantitative data (metrics). They’re typically large and grow continuously. Examples: sales transactions, website clicks, order line items.
Dimension tables contain descriptive attributes that provide context. They’re typically smaller and change slowly. Examples: products, customers, dates, locations.
-- Fact table: Who bought what, when, for how much
CREATE TABLE fact_orders (
order_id INT,
customer_id INT, -- FK to dimension
product_id INT, -- FK to dimension
order_date_id INT, -- FK to dimension
quantity INT, -- Measure
unit_price DECIMAL, -- Measure
total_amount DECIMAL -- Measure
);
-- Dimension table: Descriptive attributes (with surrogate key for SCD Type 2 compatibility)
CREATE TABLE dim_customer (
customer_key BIGINT PRIMARY KEY, -- Surrogate key
customer_id INT, -- Business key (not unique for Type 2)
customer_name VARCHAR(100),
email VARCHAR(100),
city VARCHAR(50),
state VARCHAR(50),
signup_date DATE,
is_current BOOLEAN,
start_date DATE,
end_date DATE
);Why interviewers ask this: This tests whether you understand how analytical databases are structured. Confusing facts and dimensions leads to poorly designed schemas.
Q17: Explain SCD Type 1, Type 2, and Type 3 (Slowly Changing Dimensions).
Type 1: Overwrite the old value. No history preserved.
-- Customer moves from NYC to LA
UPDATE dim_customer SET city = 'Los Angeles' WHERE customer_id = 123;Type 2: Create a new row. Full history preserved.
-- Add new row, mark old row as inactive
UPDATE dim_customer SET is_current = FALSE, end_date = CURRENT_DATE
WHERE customer_id = 123 AND is_current = TRUE;
INSERT INTO dim_customer (customer_id, city, is_current, start_date, end_date)
VALUES (123, 'Los Angeles', TRUE, CURRENT_DATE, '9999-12-31');Type 3: Add a column for previous value. Limited history.
-- Add previous_city column
ALTER TABLE dim_customer ADD COLUMN previous_city VARCHAR(50);
UPDATE dim_customer SET previous_city = city, city = 'Los Angeles'
WHERE customer_id = 123;| Type | History | Storage | Query Complexity | Use Case |
|---|---|---|---|---|
| Type 1 | None | Low | Simple | Corrections, typos |
| Type 2 | Full | High | Complex | Audit requirements |
| Type 3 | Limited | Medium | Medium | Track one previous value |
Why interviewers ask this: Real business data changes over time. How you handle changes affects reporting accuracy and storage costs.
Q18: Design a schema for a ride-sharing application like Uber.
This is a scenario-based question. Walk through your thinking:
- Identify the business process: Rides connecting riders with drivers
- Identify the grain: One row per ride
- Identify dimensions: rider, driver, vehicle, pickup_location, dropoff_location, date/time
- Identify facts/measures: fare, distance, duration, tip, surge_multiplier
-- Fact table
CREATE TABLE fact_rides (
ride_id BIGINT PRIMARY KEY,
rider_id INT,
driver_id INT,
vehicle_id INT,
pickup_location_id INT,
dropoff_location_id INT,
ride_start_datetime TIMESTAMP,
ride_end_datetime TIMESTAMP,
distance_miles DECIMAL(10,2),
duration_minutes INT,
base_fare DECIMAL(10,2),
surge_multiplier DECIMAL(3,2),
tip_amount DECIMAL(10,2),
total_fare DECIMAL(10,2)
);
-- Dimension tables
CREATE TABLE dim_rider (...);
CREATE TABLE dim_driver (...);
CREATE TABLE dim_vehicle (...);
CREATE TABLE dim_location (...);Why interviewers ask this: This tests whether you can apply theoretical knowledge to real scenarios. They want to see your thought process, not just the final answer.
ETL/ELT and Data Pipeline Questions
Understanding how data moves through systems is core to the job. These questions test whether you can design and troubleshoot production pipelines.
Q19: What is the difference between ETL and ELT?
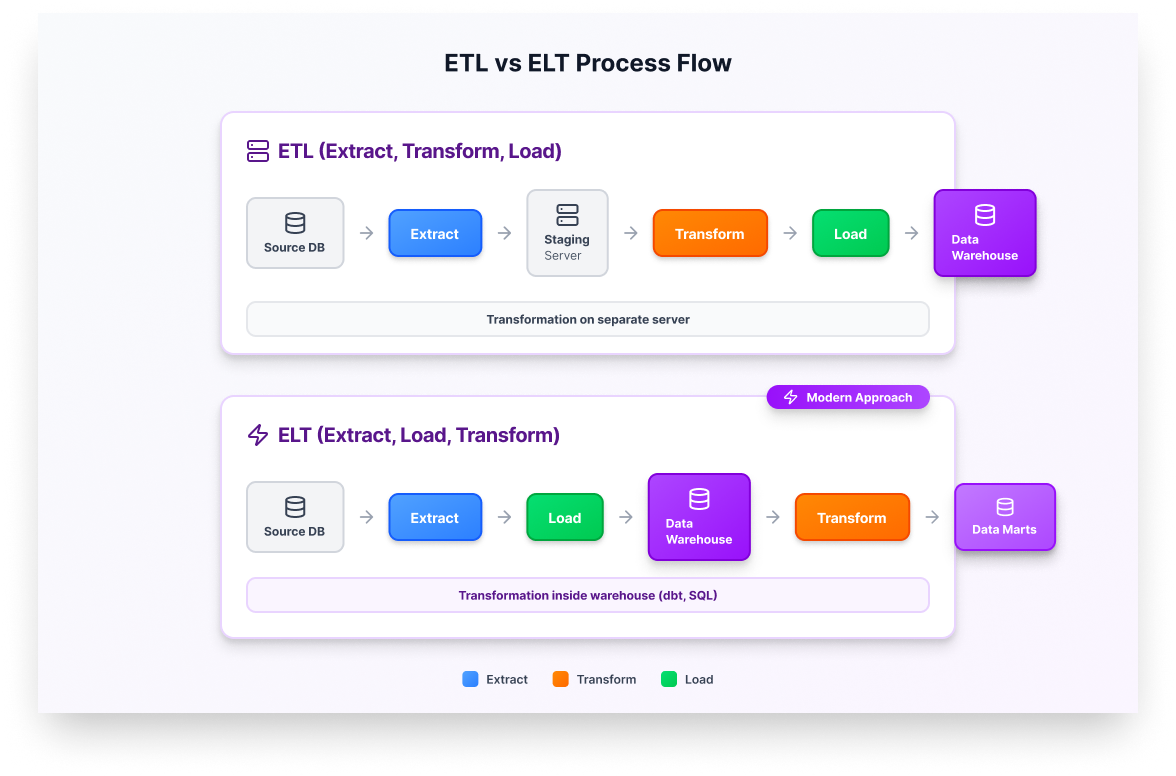
ETL (Extract, Transform, Load):
- Transform data before loading into the warehouse
- Transformation happens on a separate processing server
- Traditional approach, works well with on-premise systems
- Example: Extract from Oracle, transform in Informatica, load to SQL Server
ELT (Extract, Load, Transform):
- Load raw data first, then transform inside the warehouse
- Leverages the warehouse’s processing power
- Modern approach, works well with cloud warehouses
- Example: Extract from APIs, load raw to Snowflake, transform with dbt
Why interviewers ask this: The industry has shifted toward ELT with cloud warehouses. This tests whether you understand the tradeoffs and current practices.
Q20: What is a DAG in data orchestration?
A DAG (Directed Acyclic Graph) defines the order of tasks in a pipeline. “Directed” means tasks flow one direction. “Acyclic” means no circular dependencies.
# Airflow DAG example
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
with DAG(
'daily_sales_pipeline',
start_date=datetime(2024, 1, 1),
schedule_interval='@daily'
) as dag:
extract = PythonOperator(
task_id='extract_sales_data',
python_callable=extract_function
)
transform = PythonOperator(
task_id='transform_sales_data',
python_callable=transform_function
)
load = PythonOperator(
task_id='load_to_warehouse',
python_callable=load_function
)
# Define dependencies
extract >> transform >> loadWhy interviewers ask this: Orchestration tools like Airflow, Dagster, and Prefect are industry standard. Understanding DAGs shows you can work with production pipelines.
Q21: How do you ensure a data pipeline is idempotent?
An idempotent pipeline produces the same result whether run once or multiple times. This is critical for handling retries and backfills.
Strategies:
- Use MERGE/UPSERT instead of INSERT:
MERGE INTO target_table AS target
USING staging_table AS source
ON target.id = source.id
WHEN MATCHED THEN UPDATE SET ...
WHEN NOT MATCHED THEN INSERT ...;- Delete before insert (for date-partitioned data):
DELETE FROM sales_daily WHERE sale_date = '2024-01-15';
INSERT INTO sales_daily SELECT * FROM staging WHERE sale_date = '2024-01-15';- Use processing timestamps, not wall-clock time:
# Bad: Uses current time
df['processed_at'] = datetime.now()
# Good: Uses logical execution date
df['processed_at'] = execution_date # Passed from orchestratorWhy interviewers ask this: Pipelines fail. Networks timeout. Idempotency means you can safely retry without creating duplicates or data corruption.
Q22: What is backfilling and when is it needed?
Backfilling is re-running a pipeline for historical dates. Common scenarios:
- Bug fix: You discovered a calculation error and need to recalculate past data
- New column: Business wants a new metric added to historical reports
- Pipeline failure: A job failed for 3 days and you need to catch up
- Late-arriving data: Source data arrived after the scheduled run
# Airflow backfill command
# airflow dags backfill -s 2024-01-01 -e 2024-01-31 daily_sales_pipelineKey considerations:
- Can your source system provide historical data?
- Will backfill overload downstream systems?
- Is your pipeline idempotent (safe to re-run)?
Why interviewers ask this: Every data engineer will need to backfill eventually. This tests whether you’ve thought about failure recovery.
For hands-on practice, see Dataquest’s PySpark ETL tutorial and Apache Airflow introduction.
System Design for Entry-Level Candidates
System design interviews can feel intimidating, but entry-level expectations are reasonable. You won’t be asked to design Netflix’s streaming architecture. Instead, expect questions about basic pipeline design.
Q23: Walk me through how you’d design a batch pipeline for daily sales data.
Framework for answering:
1. Clarify requirements first:
- Where does the source data come from? (Database? Files? API?)
- How much data per day? (This affects tool choice)
- Who consumes the output? (Analysts? Dashboards? ML models?)
- What’s the latency requirement? (By 6 AM? Within 1 hour of data arriving?)
2. Propose a high-level architecture:
Source DB → [Extract] → Raw Storage → [Transform] → Data Warehouse → BI Tool
(Python) (S3/GCS) (Spark/dbt) (Snowflake) (Tableau)3. Address key concerns:
- Scheduling: “I’d use Airflow to orchestrate, running at 2 AM after source systems close”
- Error handling: “Add alerts on failure, implement retries with exponential backoff”
- Data quality: “Run validation checks before loading to production tables”
- Idempotency: “Use delete-insert pattern for daily partitions so reruns are safe”
Why interviewers ask this: They want to see structured thinking, not perfect answers. Ask clarifying questions. State your assumptions. Explain tradeoffs.
Q24: How would you handle data quality issues in a pipeline?
Prevention:
- Validate data at ingestion (schema, null checks, ranges)
- Add data contracts with upstream teams
- Monitor source data drift
Detection:
- Implement automated quality checks after each pipeline stage
- Compare row counts between source and target
- Track metrics over time (sudden 50% drop in rows = problem)
Response:
- Don’t write bad data to production—quarantine it
- Alert on-call engineer
- Have a documented runbook for common issues
# Example quality check
def check_completeness(df, date_column, expected_date):
actual_dates = df[date_column].unique()
if expected_date not in actual_dates:
raise DataQualityError(f"Missing data for{expected_date}")
row_count = len(df[df[date_column] == expected_date])
if row_count < MIN_EXPECTED_ROWS:
raise DataQualityError(f"Only{row_count} rows, expected{MIN_EXPECTED_ROWS}+")Why interviewers ask this: Bad data causes bad decisions. Data engineers are responsible for catching problems before they reach dashboards.
Modern Data Stack and Governance Questions
Modern data engineering has shifted toward tools like dbt, Airflow, Snowflake, and Databricks. You don’t need deep expertise, but you should understand what these tools do and when to use them.
Modern Tools
Q25: What is dbt and when would you use it?
dbt (data build tool) transforms data inside your warehouse using SQL. It’s the “T” in ELT.
Key features:
- Write transformations as SQL SELECT statements
- Automatic dependency management between models
- Built-in testing and documentation
- Version control friendly (SQL files in git)
-- dbt model: models/marts/sales_summary.sql
{{ config(materialized='table') }}
SELECT
date_trunc('month', order_date) as month,
product_category,
SUM(amount) as total_sales,
COUNT(DISTINCT customer_id) as unique_customers
FROM {{ ref('stg_orders') }}
GROUP BY 1, 2Why interviewers ask this: dbt has become standard for analytics engineering. Understanding it shows you’re current with industry practices.
Q26: What is the difference between batch and stream processing?
Batch processing:
- Process data in scheduled chunks (hourly, daily)
- Higher latency, but simpler to build and maintain
- Good for: Daily reports, historical analysis, ML training
- Tools: Spark, dbt, SQL
Stream processing:
- Process data continuously as it arrives
- Low latency (seconds to minutes)
- More complex: handle late data, out-of-order events
- Good for: Real-time dashboards, fraud detection, alerting
- Tools: Kafka, Flink, Spark Streaming
Entry-level reality: Most roles focus on batch processing. Stream processing is “good to know” but rarely expected for junior positions.
Data Governance and Privacy
Q27: How do you handle PII (Personally Identifiable Information) in a data pipeline?
Strategies:
- Identify PII columns: Name, email, SSN, phone, address, IP address
- Mask or hash at ingestion:
import hashlib
def hash_pii(value):
if value is None:
return None
return hashlib.sha256(value.encode()).hexdigest()
df['email_hash'] = df['email'].apply(hash_pii)
df = df.drop(columns=['email']) # Remove original- Implement access controls: Not everyone needs to see raw PII
- Document data lineage: Know where PII flows through your systems
- Set retention policies: Delete PII you no longer need
Why interviewers ask this: GDPR, CCPA, and other regulations make privacy a legal requirement. Data engineers must handle PII responsibly.
Q28: What is data lineage and why does it matter?
Data lineage tracks where data comes from, how it’s transformed, and where it goes. It answers: “How was this number calculated?”
Why it matters:
- Debugging: “Sales are wrong, which upstream table changed?”
- Impact analysis: “If I modify this column, what breaks downstream?”
- Compliance: “Auditors want to know how we calculated this metric”
- Trust: Business users trust data they can trace
Tools: dbt (automatic lineage from refs), DataHub, Amundsen, Monte Carlo
Q29: What are data quality checks and where do you implement them?
Types of checks:
- Schema: Are expected columns present? Correct data types?
- Completeness: Any unexpected nulls? Missing dates?
- Uniqueness: Are primary keys actually unique?
- Range: Are values within expected bounds? (Age between 0-120)
- Referential: Do foreign keys match parent tables?
- Business rules: Does revenue = quantity × price?
Where to implement:
- At ingestion (before loading raw data)
- After transformation (before exposing to users)
- Monitoring dashboards (detect drift over time)
# Great Expectations example
import great_expectations as gx
expectation_suite = {
"expectations": [
{"expectation_type": "expect_column_to_exist", "kwargs": {"column": "user_id"}},
{"expectation_type": "expect_column_values_to_not_be_null", "kwargs": {"column": "user_id"}},
{"expectation_type": "expect_column_values_to_be_between", "kwargs": {"column": "age", "min_value": 0, "max_value": 120}}
]
}Behavioral Interview Questions
Technical skills get you to the final round; behavioral questions determine the offer.
Q30: A BI developer tells you a report shows incorrect data. Walk me through how you’d investigate.
Framework answer:
- Understand the problem: “What specifically looks wrong? Which metric? What did you expect vs. what you see?”
- Check the obvious first: “Is the dashboard filtering correctly? Cached data?”
- Trace the data lineage: “Let me follow this metric from the dashboard back through the transformations to the source”
- Compare at each stage: “Does the source data look right? Does the staging table match? Where does it diverge?”
- Communicate throughout: “I’ll update you in 30 minutes with what I’ve found”
- Document and prevent: “Once fixed, I’ll add a test to catch this in the future”
Why interviewers ask this: They want to see your troubleshooting process, communication skills, and whether you take responsibility beyond “my pipeline is fine.”
Q31: Tell me about a time you made a mistake in production.
Everyone has done this. The interviewer wants to see how you respond.
Framework (STAR method):
- Situation: “I was deploying a pipeline update on a Friday afternoon…”
- Task: “…and accidentally ran a DELETE without a WHERE clause on a staging table that turned out to feed a production dashboard”
- Action: “I immediately notified my manager, identified the backup, restored the data within 2 hours, and communicated with affected stakeholders”
- Result: “Dashboard was down for 90 minutes. I documented the incident and added a pre-deployment checklist that the team still uses”
Key points to hit:
- Own the mistake (no blame-shifting)
- Explain what you learned
- Show how you prevented recurrence
Q32: How do you handle working with incomplete requirements?
“It happens constantly. My approach is to start with clarifying questions to understand the business goal—not just the technical ask. If I still don’t have clarity, I’ll build a minimal version, share it early, and iterate based on feedback. I document my assumptions so stakeholders can correct me if I’m wrong.”
Q33: Describe a situation where you had to explain technical concepts to non-technical stakeholders.
Example answer:
“Our marketing team wanted to understand why their customer counts differed from the data warehouse. Instead of explaining LEFT JOINs and deduplication logic, I drew a Venn diagram showing ‘customers in marketing system’ vs. ‘customers in warehouse’ and where they overlap. I explained we count unique customers, while their system counts email addresses, so one person with two emails becomes two records in their view. They immediately understood and we documented the definition for future reference.”
Mistakes That Get Candidates Rejected
Based on practitioner feedback, here are mistakes that get candidates rejected:
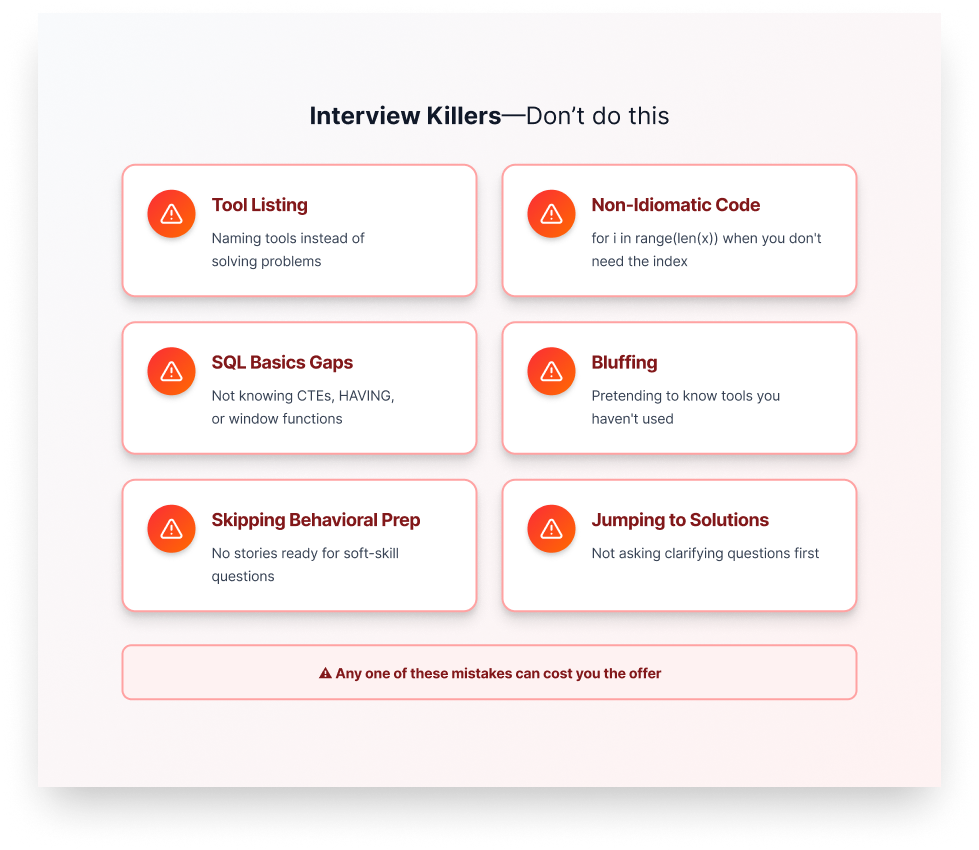
1. Listing tools instead of discussing problems
Bad: “I’d use Airflow to schedule, Spark to process, Snowflake to store…”
Better: “First, I’d understand the data volume and latency requirements, then choose tools that fit…”
2. Writing non-idiomatic code
Bad: for i in range(0, len(data)): when you don’t need the index
Better: for item in data: or for i, item in enumerate(data):
3. Not knowing SQL basics
CTEs, HAVING, window functions, DELETE vs. TRUNCATE—these are table stakes.
4. Bluffing about tools you don’t know
If they ask about Kafka and you haven't used it, you say so. Instead, explain what you know conceptually and how you’d learn it. Interviewers can always tell when you're making things up.
5. Neglecting behavioral preparation
Come with 3-5 stories ready: a debugging win, a cross-team collaboration, a mistake you learned from, a time you disagreed with someone.
6. Not asking clarifying questions
In system design, jumping straight to solutions without understanding requirements is a red flag.
How to Prepare
Four-Week Study Plan for Entry-Level Candidates
Week 1: SQL foundations
- Practice 2-3 SQL problems daily on LeetCode or DataLemur
- Focus on: JOINs, GROUP BY, window functions, CTEs
- Review Dataquest's SQL Skills Path
Week 2: Python and data manipulation
- Write Python daily—focus on idiomatic patterns
- Practice pandas operations: filtering, grouping, merging, handling nulls
- Build one small data pipeline project
Week 3: Data modeling and pipelines
- Study star schema, snowflake schema, fact/dimension tables
- Understand ETL vs. ELT, batch vs. stream
- Practice explaining system designs out loud
Week 4: Behavioral and mock interviews
- Prepare 5 STAR-format stories
- Do at least 2 mock interviews with friends or services
The “5 Interviews” Rule
From Reddit: “Complete 5+ real interviews before targeting your dream company.” Early interviews are practice. You’ll bomb some questions, learn what’s asked, and improve. Don’t waste your top-choice company on interview #1.
Portfolio Projects That Impress
Projects beat certificates. Build something that shows:
- End-to-end data pipeline (extract, transform, load)
- SQL queries with business context
- Documentation explaining your decisions

Final Advice
Data engineering interviews test a specific set of skills: SQL fluency, Python proficiency, data modeling intuition, and the ability to think through pipeline design. It may seem like a lot, but you can learn the skills, and the questions are predictable.
Focus your preparation on the fundamentals covered here. Practice SQL daily. Write idiomatic Python. Understand why star schemas exist. Know how to handle failures and ensure data quality. Prepare your behavioral stories.
Most importantly, remember what hiring managers actually evaluate: how you think through problems, how you communicate, and whether you’re honest about what you don’t know. Technical skills get you in the room; problem-solving and communication get you the offer.
Ready to build these skills systematically? Start with Dataquest's Data Engineering Career Path or explore our online data engineering courses to focus on specific topics.
Frequently Asked Questions
Is data engineering harder than data science?
Neither is objectively harder—they require different skills.
Data engineering demands strong software engineering fundamentals and systems thinking. Data science requires statistical depth and business intuition.
Choose based on what energizes you, not perceived difficulty.
What’s the most important skill for entry-level DE interviews?
SQL. It appears in every interview.
If you can write complex queries with window functions, CTEs, and aggregations confidently, you’re ahead of most candidates.
How much system design should I know?
At entry level, expect simple scenarios like:
“Design a batch pipeline for X.”
You won’t be asked to architect distributed systems. Focus on:
- Understanding requirements
- Choosing appropriate tools
- Handling failures
- Ensuring data quality
Should I learn Hadoop in 2026?
Hadoop knowledge is helpful for understanding distributed computing concepts, but it’s no longer the focus of most job postings.
Prioritize:
- SQL
- Python
- Spark
- Cloud warehouses (Snowflake, Databricks, BigQuery)
- Orchestration tools like Airflow
Mention Hadoop if asked, but don’t center your preparation on it.