Best AI Projects to Build in 2026 (Sequenced for Hiring)
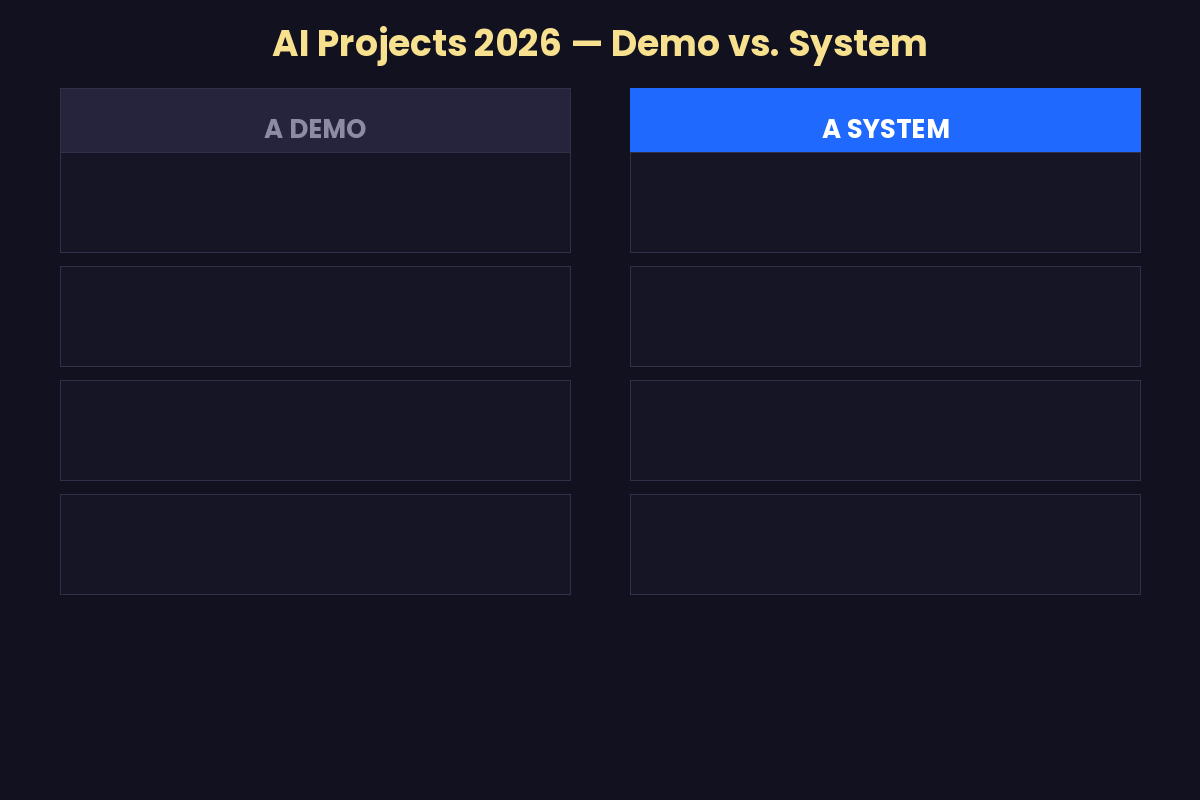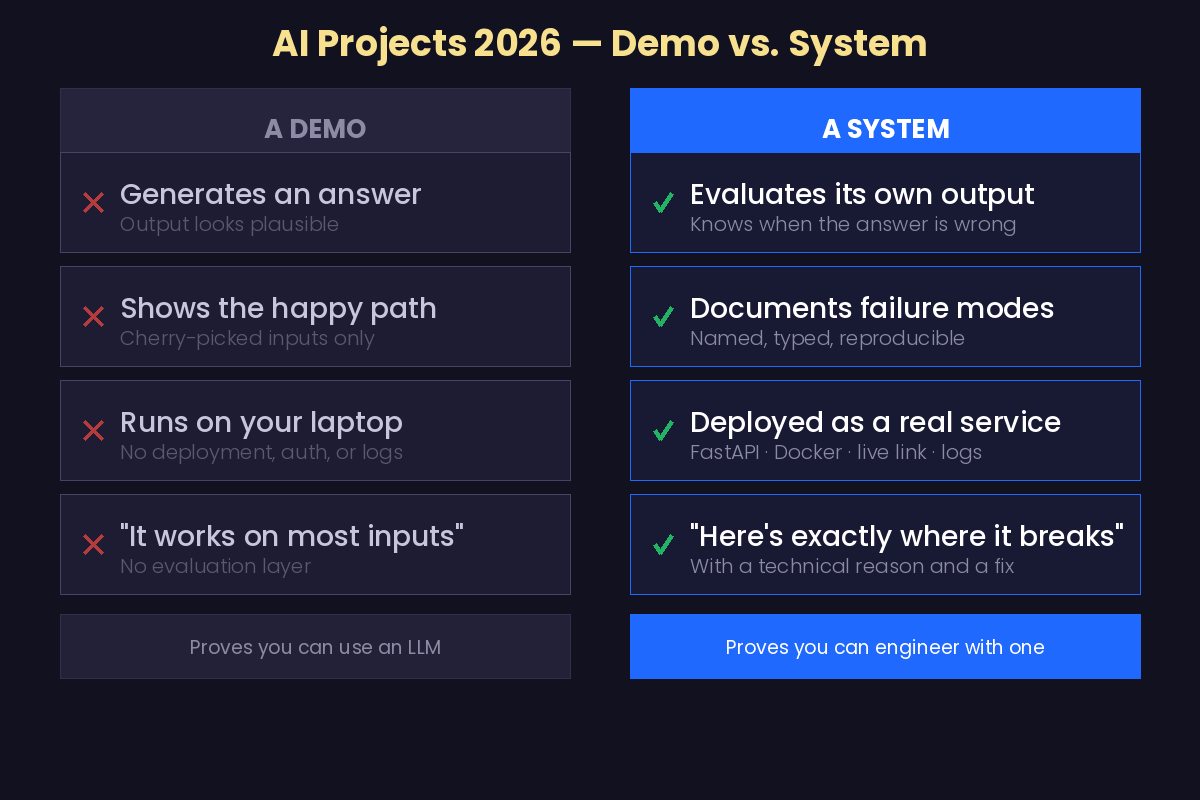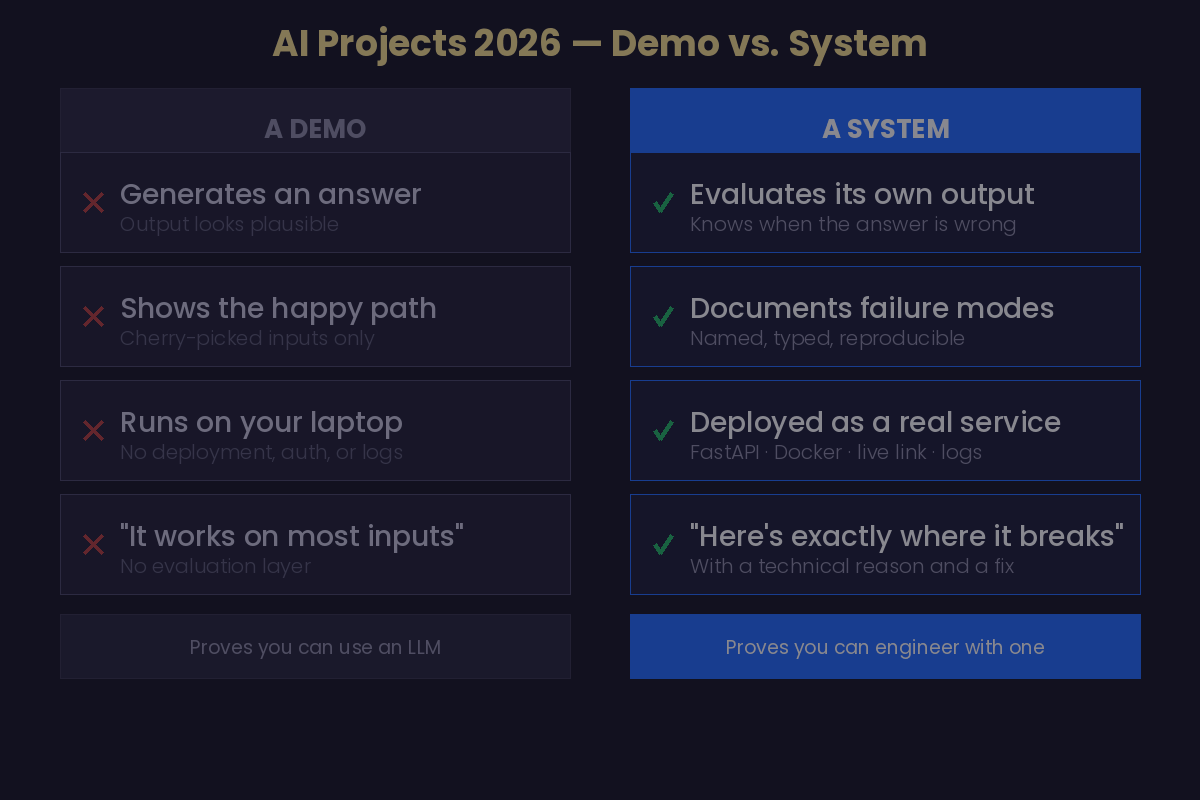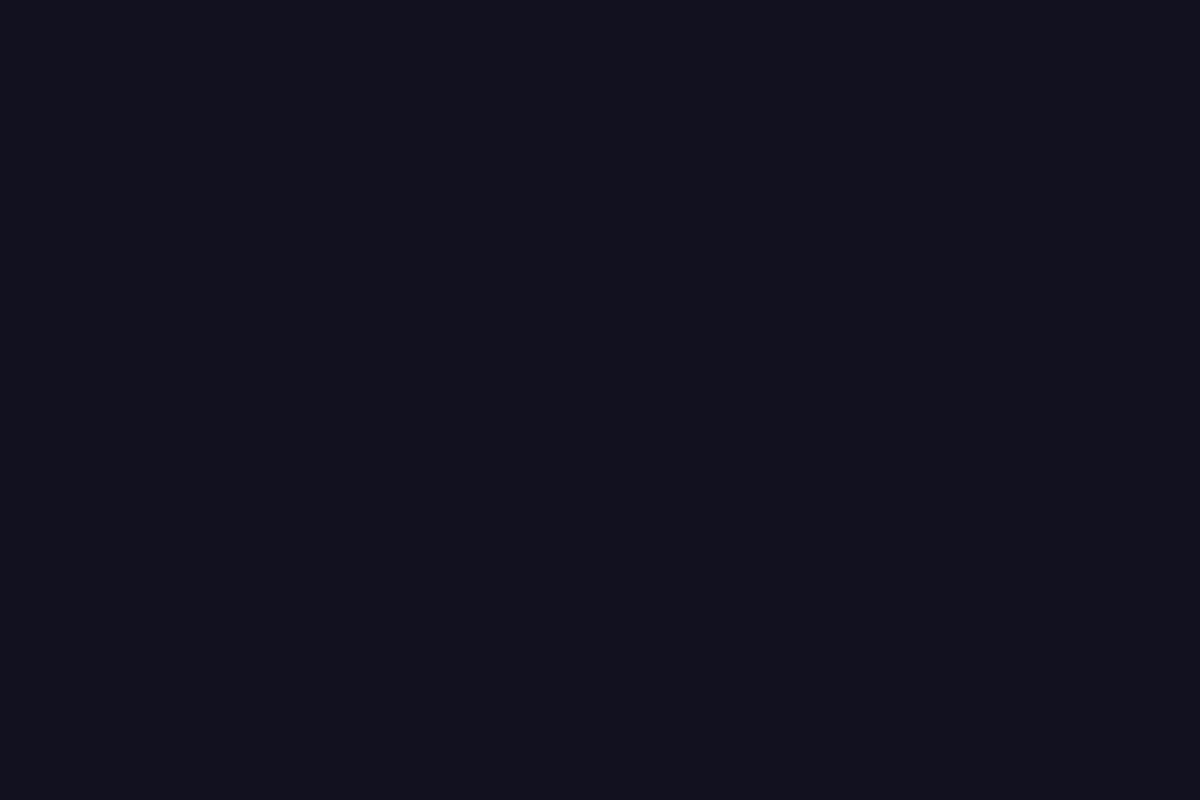
The best AI projects to build in 2026 aren't the most complex ones. They're the ones that prove you can evaluate your system's output and tell an interviewer exactly where it fails.
50 project ideas sound helpful until you have to pick one. This post gives you the top 10 AI projects for 2026 — sequenced from beginner foundations to portfolio-ready builds, with a prerequisite check, realistic time estimates, and a clear answer to "which three should I actually build?”. Every recommendation was shaped by the Dataquest team who built our AI Engineering in Python career path from scratch: Anna Pershyna (CTO), Anna Strahl (curriculum director), and Mike Levy (content developer).
The 10 AI projects, at a glance:
| # | Project | Tier | Time |
|---|---|---|---|
| 1 | Document Q&A Assistant | Beginner | 1–2 weekends |
| 2 | Structured Output Classifier | Beginner | 1 weekend |
| 3 | Meeting Notes & Action Extractor | Beginner | 1 weekend |
| 4 | Churn Prediction + Explanation Dashboard | Intermediate | 1–2 weeks |
| 5 | AI Data Analyst Assistant | Intermediate | 2 weeks |
| 6 | Deployed AI Service | Intermediate | 1–2 weeks |
| 7 | RAG System with Failure Analysis | Portfolio-ready | 3–4 weeks |
| 8 | AI Agent with Loop Design | Portfolio-ready | 3–4 weeks |
| 9 | Mini Data Pipeline for AI-Ready Data | Portfolio-ready | 2 weeks |
| 10 | The One You Invent | Any | 4 weeks |
Jump to any project, or keep reading for the full context on what hiring managers actually look for in 2026.
What AI Engineering Portfolios Need to Prove in 2026”
Most content about AI projects focuses on what to build, not how to tell if what you're building is any good. Mike Levy, who designed Dataquest's RAG curriculum, put a number on the gap:
"The ratio of 'here's how to build it' content to 'here's how to tell if it's working' content is probably 50 to 1."
That gap matters because the easy part is no longer impressive. In 2024, a working chatbot was enough. In 2026, a hiring manager wants to know whether you can tell a good answer from a wrong one.
Four signals show up again and again in AI engineering roles:
- Retrieval (pulling the right context into the prompt)
- Structured output (getting models to return data your code can use)
- Evaluation (systematically testing LLM outputs against defined criteria)
- Deployment (serving, monitoring, and managing cost at scale)
Not model selection, not prompt engineering alone, but the system built around the model.
Anna Pershyna, Dataquest's CTO, argues that the projects worth building teach primitives that outlast the current naming cycle — retrieval, validation, evaluation, cost control — rather than chasing whatever vocabulary dominates this month's job descriptions.
"The biggest mistake is choosing 'build an agent' as the project goal. A lot of first agent projects are really just an LLM in a loop with a few tools attached. There is no state model, no checkpointing, no clear stop condition, no cost ceiling, no evaluation per iteration. While it was a hot topic in 2025, that does not read as advanced in 2026 anymore. The mistake is not choosing an agent. The mistake is making the word 'agent' carry the whole project."
— Anna Pershyna, CTO, Dataquest
The list below follows that principle: what you build around the loop matters more than the loop itself.
Before You Start: A Prerequisite Check
Anna Strahl, Dataquest's curriculum director, thinks about learner readiness in four levels. They're useful here because they map directly to what hiring managers screen for, and they tell you honestly which projects in this list you're ready to take on.

Level 1: Chatting with an LLM. You use ChatGPT or Claude daily. You can write a good prompt and iterate on the output. This is where most people are. It is not yet AI engineering.
Level 2: Working through an API. You can call an LLM API programmatically, read the response, handle errors, and build something simple around it. You're comfortable with Python, virtual environments, and reading documentation. This is the entry point for the beginner projects in this list.
Level 3: Shipping something others can use. You've taken a local script and turned it into a real service — deployed, accessible, not just running on your machine. This is where "AI Engineer" has something to point at. It's the milestone that separates power users from engineers.
Level 4: RAG, evaluation, and agentic patterns. You understand retrieval, structured output, and how to measure whether a system is working. This is the portfolio-ready tier.
If you’re not at Level 2 yet, start with Python fundamentals and basic API calls before this list. The AI Engineer Roadmap is the right place to map that path.
Beginner AI Projects: Build Your Foundation

Anna Strahl's observation about first projects is worth keeping in mind before you start:
"People tend to choose a first project based on how impressive it sounds rather than whether they can build and understand it at their current level. Someone wants their first AI project to be an autonomous agent that books their travel before they're comfortable calling an API and reading the response."
The fix is to choose a project that sits just above your current skill level, where you can build most of it yourself and only stretch for a piece or two.
Start with these three projects. Each one takes a weekend or two, and each teaches a pattern the rest of this list assumes you already have.
1. Document Q&A Assistant
What you'll build: A chatbot that answers questions from your own PDFs, notes, or knowledge base using retrieval-augmented generation (RAG), not the model's training data.
Skills you'll practice:
- Chunking and embedding documents
- Vector similarity search
- Prompt construction with retrieved context
- Source citation in generated answers
Time estimate: 1–2 weekends
Tools: Python, OpenAI, Anthropic, or Google API, ChromaDB or FAISS, Streamlit
What this proves: You understand retrieval, not just generation. You know the difference between "the model knows the answer" and "the model found the answer."
Wrong for you if: You haven't made a successful API call using Python yet. Get comfortable with that first. The retrieval layer will make more sense once the API call is intuitive.
Take it further: Add a confidence filter that refuses to answer when retrieved chunks fall below a similarity threshold.
2. Structured Output Classifier
What you'll build: A system that reads an incoming message (a support ticket, email, or form submission) and returns a validated JSON object: category, urgency, routing_destination, and a confidence field.
Skills you'll practice:
- Prompting for structured output
- Schema validation with Pydantic
- Handling cases where the model returns malformed output
- Logging rejected or low-confidence responses
Time estimate: 1 weekend
Tools: Python, OpenAI or Anthropic API, Pydantic
What this proves: You understand that LLM output needs validation, not trust. Reliable agent systems are built on this pattern: structured output is the interface between model and code.
Wrong for you if: The goal is to build something that demos well in a screenshot. This project produces a validation layer that catches failure, which means you need to be interested in the failure cases, not just the successes.
Take it further: Feed misclassified outputs back into a labeled evaluation set. After 50 examples, you'll have a real benchmark.
3. Meeting Notes and Action-Item Extractor
What you'll build: A tool that takes a meeting transcript and returns a structured summary that includes key decisions, action items with owners, deadlines, and follow-up questions.
Skills you'll practice:
- Long-context prompting
- Structured output (tied to the Structured Output Classifier
- Handling inconsistent or messy input
- Output formatting for different audiences
Time estimate: 1 weekend
Tools: Python, Whisper (for audio) or paste-in transcript, LLM API, Streamlit
What this proves: Workflow automation combined with structured output. This project also has an authenticity advantage. You can run it in a real meeting and demo it with real output, which is harder to fake than cherry-picked chatbot responses.
Wrong for you if: You need an end-to-end audio pipeline from day one. Start with pasted transcripts and add audio transcription as a stretch goal once the extraction logic is solid.
Take it further: Add a "decision register" that persists across meetings and flags when a deadline has passed without a resolution.
Intermediate AI Projects: Real Production Signals

The beginner tier teaches patterns. The intermediate tier tests whether you can apply them when the inputs aren't clean and the requirements aren't simple. Here are three AI projects that require handling real data, building for real users, or both.
4. Customer Churn Prediction with Explanation Dashboard
The one classical ML project on this list — included because explainable prediction is still a core part of real AI and data work.
What you'll build: A model that predicts which customers are likely to leave, surfaced in a Streamlit dashboard that shows the top drivers for each prediction, not just the score.
Skills you'll practice:
- Feature engineering on tabular business data
- Binary classification with scikit-learn
- SHAP values for model explanation
- Building a dashboard that non-technical stakeholders can read
Time estimate: 1–2 weeks
Tools: Python, scikit-learn, SHAP, Streamlit, a public churn dataset from Kaggle
What this proves: You can communicate model decisions to non-technical stakeholders. Classical ML is still common in business analytics, and the explanation layer is what makes it an engineering project rather than a notebook exercise. For a deeper foundation on the modeling side, see Dataquest's machine learning projects guide.
Wrong for you if: The goal is to maximize accuracy. The goal is to explain the predictions well enough that someone could act on them.
Take it further: Add a monitoring view that shows how the model's confidence distribution shifts week over week. This is a first step toward production drift detection.
5. AI Data Analyst Assistant
What you'll build: A tool where a user uploads a CSV, asks a question in plain language, and receives a chart, a summary, and a list of caveats about what the data can and can't support.
Skills you'll practice:
- Code-interpreter pattern (generating and executing Python from natural language)
- Data validation and edge-case handling
- Communicating uncertainty: caveats matter as much as the charts
- Streamlit for rapid UI
Time estimate: 2 weeks
Tools: Python, pandas, LLM API with sandboxed code execution, Streamlit
What this proves: You understand that LLMs should augment data work, not replace it. The candidate who ships this and can explain why the caveats section exists understands something about AI reliability that most portfolios skip.
Wrong for you if: The dataset is a cleaned, toy CSV with no edge cases. It’s better to use a genuinely messy public dataset. The interesting engineering is in handling the rows that the model doesn't expect.
Take it further: Add a query log that stores every question and its output. After 20 questions, you have the start of an evaluation set.
6. Deployed AI Service
What you'll build: Take your Document Q&A Assistant from Project 1 and ship it as a real service using a FastAPI endpoint, containerized with Docker, deployed on Render, Railway, or a similar cloud platform, with environment variable configuration and basic request logging.
Skills you'll practice:
- REST API design with FastAPI
- Docker containerization and Docker Compose
- Environment variable management (no hardcoded API keys)
- Logging and basic observability
- Deployment to a cloud service
Time estimate: 1–2 weeks
Tools: Python, FastAPI, Docker, Render or Railway
What this proves: This is the Level 3 milestone. Anna Strahl describes what happens when learners cross it: "You stop being someone who can talk to an LLM and start being someone who can build with one. That's where the 'engineering' in 'AI Engineer' finally has something to point at."
A deployed link that a hiring manager can actually click is worth more than a notebook with clean output. The engineering decisions that come up during deployment (how to handle secrets, what to log, how to structure the API) are the ones that appear in job interviews.
Wrong for you if: You haven't built Document Q&A Assistant yet. The deploy project only has something to say if there's a real system underneath it.
Take it further: Add rate limiting and a basic health check endpoint. Both are standard in production services and are realistic extensions once the service is deployed.
Portfolio-Ready AI Projects: The Evaluation Tier

The three projects in this tier share one requirement that the earlier tiers don't: they include a deliberate evaluation layer. Not a demo that shows the happy path, but a documented investigation of where the system fails and why.
This is the tier that most portfolios fail to reach. The candidates who advance past it aren't the ones with the most projects. They're the ones who can sit in an interview and describe a failure they found and what it told them.
7. RAG System with Failure Analysis
This is the project most AI portfolios are missing — and the one that will do the most work in an interview.
What you'll build: A RAG pipeline over a real document set from a domain you actually know, with an evaluation harness that systematically identifies where retrieval fails, where generation fails, and where the two failures are different problems.
The full structure:
- A working RAG pipeline over real documents (company policies, product docs, technical manuals, legal filings, or any domain where you have genuine context)
- An eval set of 20–30 real queries with expected answers, written by you, not generated
- A failure taxonomy: retrieval failures (wrong chunks returned), generation failures (model ignores retrieved evidence), and citation mismatches (source chunk contradicts the model's claim)
- A README section titled "Where this breaks and why"
Time estimate: 3–4 weeks
Tools: Python, OpenAI or Anthropic API, ChromaDB, FastAPI, Docker, a real document set. Dataquest's Introduction to Retrieval-Augmented Generation course covers the full pipeline this project assumes, including diagnosing retrieval and generation failures.
What this proves: Mike Levy describes the exact moment this project is designed to produce: "The shift happens when learners stop building and start diagnosing. They find the model confidently answering questions using the wrong chunks. They find it ignoring retrieved evidence and falling back on its own training data. They find citation mismatches where the system says 'according to the documentation' and the source chunk says something different. That's the moment. It's the realization that 'it gave me an answer' and 'it gave me a good answer' are completely different things."
A hiring manager reviewing this project wants to see three things:
- Real design decisions you can defend (why this chunk size? why reranking over top-k similarity?)
- Documented failure modes rather than cherry-picked demos
- Cost awareness: token counts, latency per query, approximate dollars per 1,000 requests.
Wrong for you if: The document set is a public Wikipedia export or a generic FAQ. Use a domain where you can write eval questions from genuine knowledge. That's what makes the failure analysis meaningful rather than mechanical.
Take it further: Build a regression test that runs your eval set against any change to the pipeline. One failing test that catches a prompt change that breaks citation accuracy is worth a hundred passing prompts that only show the happy path.
"One project, built honestly, with real failure analysis, beats a portfolio of five polished demos that only show the happy path."
— Mike Levy, Content developer, Dataquest
8. AI Agent with Loop Design

Agents are real. They're worth learning. The problem is the frame: most "I built an agent" projects are actually an LLM called in a loop with a few tools attached, with no state model, no stop condition, and no cost ceiling. That framing was impressive last year. It isn't today.
What you'll build: An agent that can call 3–4 real tools (a calculator, a web API lookup, a database query, and a file reader) with a defined goal state, a cost ceiling, logging of every decision, and a documented failure mode section.
The full structure:
- A defined task the agent is trying to complete (not "answer any question" but a bounded goal with a clear success condition)
- 3–4 callable tools with typed inputs and outputs
- A maximum token budget per task run
- Step-level logging: what the agent decided, what tool it called, what it received back
- A stop condition that isn't "the model says it's done"
- A failure analysis: what happens when a tool returns an error, a timeout, or an unexpected format
Time estimate: 3–4 weeks
Tools: Python, OpenAI Agents SDK, LangGraph, or a lightweight custom loop, real APIs or mocked tools with realistic failure modes
What this proves: Anna Pershyna describes what the evaluation tier of agent work actually looks like: "The harder part is deciding how the system should actually behave over time. What is it trying to do? What information does it keep? What does a good result look like? When should it stop? When should a human approve something? What happens when the model is uncertain, retrieval is weak, or the tool output looks wrong?" The build above is structured to answer every one of those questions.
Wrong for you if: The goal is to build an agent that can do anything. Scope it precisely: one class of task, a small number of tools, a documented boundary on what the agent is allowed to do.
Take it further: Add a human-in-the-loop approval step for any tool call that would write to an external system. This is standard in production agent deployments and takes the architecture from prototype to production-credible.
9. Mini Data Pipeline for AI-Ready Data
Most AI failures are not model failures. They're data failures: inconsistent formats, missing fields, schema drift, encoding issues. The model handles these gracefully on clean inputs and unpredictably on messy ones. This project proves you understand that.
What you'll build: A pipeline that ingests a real messy data source, validates and cleans it, stores it in a structured format, and feeds it reliably into a RAG app or analytics dashboard — with logging that makes failures visible rather than silent.
The full structure:
- Real messy input: a public CSV, an API with inconsistent responses, or scraped data from a domain you care about
- Schema validation at ingestion (reject or flag malformed records, don't silently drop them)
- Transformation and storage (DuckDB or SQLite is sufficient for this; it is not a Spark project)
- A downstream consumer: the Document Q&A Assistant from Project 1, or a simple dashboard
- A log of every rejected or transformed record, with a reason
Time estimate: 2 weeks
Tools: Python, pandas, DuckDB or SQLite, a real messy data source from Kaggle or a public API
What this proves: You understand that reliability in AI systems begins before the model is called. A candidate who can trace an LLM hallucination back to a malformed input record and show a log that caught it is demonstrating production thinking that most portfolios don't get near.
Wrong for you if: The dataset is already clean. Import something genuinely messy, or the project won't teach you what it's designed to teach.
Take it further: Add a data quality score that tracks the percentage of records rejected per run. If that number changes over time, you've built the start of a monitoring system.
10: The One You Invent
This is the only project on the list that can’t be fully prescribed.
Every project above teaches a pattern. This one asks you to find a problem that the patterns apply to, in a domain where you have genuine knowledge or genuine curiosity. The difference between a prescribed project and an invented one is exactly the difference between an answer that looks right and an answer a hiring manager believes.
Here is a 5-step framework for finding your project.
- List five things you work with, study, or are frustrated by. These are your candidate domains. The more specific, the better: not "finance" but "the way my team tracks project budgets in three separate spreadsheets."
- For each, ask yourself: what data exists, and is it messy enough to be interesting? Messy data is good data for a portfolio project. Clean data means the interesting problems are already solved.
- Pick one where "where does this break?" is the most interesting question to answer. The domain that makes you curious about failure is the domain where you'll build something worth showing.
- Write a one-sentence problem statement: "A system that [does X] from [data source Y], where success means [measurable Z]." If you can't fill in the measurable Z, the project isn't scoped yet.
- Set a four-week time box. At the end of four weeks, you evaluate: is the failure analysis interesting? If yes, keep going. If the project is too easy or too hard, the time box limits the cost of a wrong turn.
The evaluation requirement applies here too. Whatever domain you choose, the README for your project must include a "Where this breaks" section. That requirement is what makes this more than a copy-paste tutorial exercise.
Real projects people have built along these lines include:
- A question-answering bot over a tabletop game's rulebook (RAG over PDFs, with a failure analysis of multi-document queries).
- A classifier for personal finance transactions built on sanitized or synthetic transaction data, then tested systematically on realistic edge cases like ambiguous merchants, transfers, refunds, subscriptions, and split categories.
- A multi-LLM review committee for academic literature that compared outputs across three models and documented where they disagreed.
None of these are on any "AI project ideas" list. All of them generate better interview conversations than a generic churn model trained on a standard Kaggle dataset with no explanation layer or failure analysis.
How to Choose Your Three
If you can't build all ten, three well-chosen projects are enough. The question is which three, and that depends on where you're starting and where you're going.
| If you are | Build these three | Why |
|---|---|---|
| Career changer with limited time | 1, 6, 7 | Foundation + deploy + RAG with failure analysis. This covers the three signals a hiring manager checks for in one progression. |
| Student building their first portfolio | 1, 2, 8 | Foundation + structured output + agent with loop design. Shows range without requiring full deployment infrastructure. |
| Employed engineer pivoting to AI | 6, 7, 9 | Deploy + RAG with failure analysis + data pipeline. Assumes existing Python fluency; focuses on the production signals that distinguish AI engineering from data science. |
| Building toward the full AI Engineering path | All 10, in order | The sequence above mirrors the structure of the Dataquest AI Engineering in Python career path. |
Anna Pershyna and Mike Levy both converged on the same one-project recommendation when asked what a career changer with limited time should build: a bounded RAG application over a real document set from a domain they actually know, deployed as a real service, with documented failure modes.
When working on AI projects, Anna Pershyna's five-point proof checklist is worth keeping nearby:
- Real design decisions you can defend
- An evaluation layer
- Documented failure modes
- Deployed like software with FastAPI and Docker
- Cost awareness in the README
"One thorough project like that beats five polished demos," she said. "It gives a hiring manager something to dig into."

How to Present Your AI Projects
A hiring manager reviewing portfolios has roughly 90 seconds per project before deciding whether to read further. A well-presented project gets read. A project with a good README and a live deployment link gets tested.

Six elements separate a README that gets read from one that gets skimmed past:
- A one-sentence problem statement specific enough to mean something
- An architecture summary short enough to scan
- Evaluation results that show real numbers instead of a vibe
- One documented tradeoff with its reasoning
- Approximate cost or latency data
- A limitations section
None of these require a long README. They're rare because each one means admitting where the project falls short, and "it works well" is easier than naming the failure. That admission is exactly what a hiring manager is looking for.
Mike Levy's standard for interview readiness applies directly:
"What gets you hired is being able to sit in an interview and say: 'My system struggles with questions that span multiple documents because the chunking splits the answer across boundaries. Here's how I diagnosed that, here's the tradeoff I evaluated, and here's what I'd do differently with more time.' That's an engineer talking, not someone who followed a tutorial."
For more on portfolio presentation, see Dataquest's guide to sharing your data science portfolio.
Start Building This Week
The market is not short of AI projects. It's short of candidates who built one carefully enough to know where it breaks.
Pick one domain: something you work with, study, or are genuinely curious about. Write a one-sentence problem statement. Build the Document Q&A Assistant over that domain. Then, before you ship it or add it to your portfolio, run 25 real queries and find the ones it gets wrong. Write down why. That "why" is the beginning of the failure analysis that will make this project worth showing.
One project, built honestly, will carry a portfolio. Five demos that only show the happy path won't.
Frequently Asked Questions
What is the best AI project for beginners in 2026?
The best first AI project in 2026 is a Document Q&A Assistant: a system that answers questions from your own PDFs or knowledge base using retrieval rather than the model's training data. It teaches the core RAG pattern, requires you to make real engineering decisions about chunking and similarity thresholds, and scales naturally into more advanced projects. The key is to choose a document set from a domain you actually know, so you can evaluate the answers from genuine knowledge rather than guessing whether the output looks right.
How long does it take to build an AI project?
Beginner projects in this list take one to two weekends if you already have Python and API basics. Intermediate projects take one to two weeks. Portfolio-ready projects — particularly the RAG system with failure analysis — take three to four weeks when you include the evaluation harness and documentation. These estimates assume you're building and understanding the project, not generating it with an AI assistant and submitting the output. The learning lives in the parts that are hard.
Do I need a GPU to build AI projects?
No. All ten projects in this list run on a standard laptop using cloud LLM APIs (OpenAI, Anthropic, or Google). The API calls cost money, but many small development projects can be built for a few dollars if you monitor usage and choose models carefully. Dataquest's curriculum teaches with paid API calls intentionally, because understanding inference costs is part of understanding how production AI systems work.
Open-source models via Ollama are a valid path if you want to run locally, and Dataquest's curriculum covers local deployment and fine-tuning as a core skill elsewhere in the AI Engineering path. For the ten projects in this list specifically, the cloud API route gets you to the evaluation work faster, since that's what each project is designed to teach. If you're a Dataquest Premium subscriber, you can run those API calls directly inside the Dataquest interface at no extra cost.
What's the difference between AI projects and machine learning projects?
Classical machine learning projects (churn prediction, image classification, regression models) train a model on a labeled dataset and evaluate it on held-out data. The model is the artifact. AI engineering projects in 2026 build systems around existing foundation models: retrieval pipelines, structured output validators, agents with tool access, evaluation harnesses. The model is a component, not the output. Both matter. The Churn Prediction with Explanation Dashboard in this list is a classical ML project, but it signals different skills to a hiring manager. For a deeper guide to ML-specific projects, see Dataquest's machine learning projects guide.
What AI projects look good on a resume?
Projects that show retrieval, structured output, evaluation, and deployment look good on a resume in 2026 because they're the patterns that appear in AI engineering job descriptions. More specifically: a RAG system with documented failure modes, a deployed AI service with a live link, and an agent with explicit loop design will carry more weight than ten notebook-based ML projects. The presentation matters as much as the build. A project with a clear README, a live deployment, and a limitations section reads differently than the same project as a Jupyter notebook.
How do I know if my AI project is good enough?
Apply Mike Levy's interview test: can you describe a specific failure your system has, the technical reason it fails, how you diagnosed it, the tradeoff you evaluated, and what you'd do differently? If you can answer all five parts without hedging, the project is good enough. If you can only say "it works well on most inputs," the evaluation layer is missing and your project isn't finished yet.
Can I get hired with AI projects and no CS degree?
Yes, it’s possible, but the projects have to carry more evidence than they would for someone with a traditional CS background. A strong portfolio, particularly one with a deployed RAG system with documented failure modes, can help compensate for the absence of a formal credential because it demonstrates the same underlying competencies directly. The strongest hiring-manager signal that matters is not the credential but the evidence of judgment: that you made real decisions, tested them, found failures, and can explain all of it under interview conditions.