Python List Tutorial: Lists, Loops, and More!
Lists are one of the most powerful data types in Python. In this Python List Tutorial, you'll learn how to work with lists while analyzing data about mobile apps.
In this tutorial, we assume you know the very fundamentals of Python, including working with strings, integers, and floats. If you're not familiar with these, you might like to try our free Python Fundamentals course.
We'll be working with this table of data, taken from Mobile App Store data set (Ramanathan Perumal):
| name | price | currency | rating_count | rating |
|---|---|---|---|---|
| 0.0 | USD | 2974676 | 3.5 | |
| 0.0 | USD | 2161558 | 4.5 | |
| Clash of Clans | 0.0 | USD | 2130805 | 4.5 |
| Temple Run | 0.0 | USD | 1724546 | 4.5 |
| Pandora - Music & Radio | 0.0 | USD | 1126879 | 4.0 |
Each value in the table is a data point. For instance, the first row (after the column titles) has five data points:
Facebook0.0USD29746763.5
A collection of data points make up a dataset. We can understand our entire table above as a collection of data points, so we call the entire table a dataset. We can see that our data set has five rows and five columns.
Using our understanding of Python types, we might think we could store each data point in its own variable — for instance, this is how we might store the first row's data points:

Above, we stored:
- The text "Facebook" as a string
- The price 0.0 as a float
- The text "USD" as a string
- The rating count 2,974,676 as an integer
- The user rating 3.5 as a float
Creating a variable for each data point in our data set would be a cumbersome process. Fortunately, we can store data more efficiently using lists. This is how we can create a list of data points for the first row:

To create the list above, we:
- Typed out a sequence of data points and separated each with a comma:
'Facebook', 0.0, 'USD', 2974676, 3.5 - Surrounded the sequence with brackets:
['Facebook', 0.0, 'USD', 2974676, 3.5]
After we created the list, we stored it in the computer's memory by assigning it to a variable named row_1.
To create a list of data points, we only need to:
- Separate the data points with a comma.
- Surround the sequence of data points with brackets.
Now let's create five lists, one for each row in our dataset:
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
row_3 = ['Clash of Clans', 0.0, 'USD', 2130805, 4.5]
row_4 = ['Temple Run', 0.0, 'USD', 1724546, 4.5]
row_5 = ['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0]Indexing Python Lists
A list can contain a variety of data types. A list like [4, 5, 6] has identical data types (only integers), while the list ['Facebook', 0.0, 'USD', 2974676, 3.5] has mixed data types:
- Two strings (
'Facebook', 'USD') - Two floats (
0.0,3.5) - One integer (
2974676)
The ['Facebook', 0.0, 'USD', 2974676, 3.5] list has five data points. To find the length of a list, we can use the len() command:

For small lists, we can just count the data points on our screens to find the length, but the len() command will prove very useful whenever you work with lists containing many elements, or need to write code for data where you don't know the length ahead of time.
Each element (data point) in a list has a specific number associated with it, called an index number. The indexing always starts at 0, so the first element will have the index number 0, the second element the index number 1, and so on.

To quickly find the index of a list element, identify its position number in the list, and then subtract 1. For example, the string 'USD' is the third element of the list (position number 3), so its index number must be 2 since 3 - 1 = 2.
The index numbers help us retrieve individual elements from a list. Looking back at the list row_1 from the code example above, we can retrieve the first element (the string 'Facebook') with the index number 0 by running the code row_1[0].

The syntax for retrieving individual list elements follows the model list_name[index_number]. For instance, the name of our list above is row_1 and the index number of the first element is 0 — following the list_name[index_number] model, we get row_1[0], where the index number 0 is in square brackets after the variable name row_1.

This is how we can retrieve each element in row_1:

Retrieving list elements makes it easier to perform operations. For instance, we can select the ratings for Facebook and Instagram, and find the average or the difference between the two:

Let's use list indexing to extract the number of ratings from the first three rows and then average them:
ratings_1 = row_1[3]
ratings_2 = row_2[3]
ratings_3 = row_3[3]
total = ratings_1 + ratings_2 + ratings_3
average = total / 3
print(average)2422346.3333333335
Using Negative Indexing with Lists
In Python, we have two indexing systems for lists:
- Positive indexing: the _first) element has the index number 0, the second element has the index number 1, and so on.
- Negative indexing: the last element has the index number -1, the second to last element has the index number -2, and so on.

In practice, we almost always use positive indexing to retrieve list elements. Negative indexing is useful when we want to select the last element of a list — especially if the list is long, and we can't tell the length by counting.

Notice that if we use an index number that is outside the range of the two indexing systems, we'll get an IndexError.

Let's use negative indexing to extract the user rating (the last value) from each of the first three rows and then average them.
rating_1 = row_1[-1]
rating_2 = row_2[-1]
rating_3 = row_3[-1]
total_rating = rating_1 + rating_2 + rating_3
average_rating = total_rating / 3
print(average)2422346.3333333335
Slicing Python Lists
Instead of selecting list elements individually, we can use a syntax shortcut to select two or more consecutive elements:

When we select the first n elements (n stands for a number) from a list named a_list, we can use the syntax shortcut a_list[0:n]. In the example above, we needed to select the first three elements from the list row_3, so we used row_3[0:3].
When we selected the first three elements, we sliced a part of the list. For this reason, the process of selecting a part of a list is called list slicing.
There are many ways that we might want to slice a list:

To retrieve any list slice we want:
- We first need to identify the first and the last element of the slice.
- We then need to identify the index numbers of the first and the last element of the slice.
- Finally we can retrieve the list slice we want by using the syntax
a_list[m:n], where:mrepresents the index number of the first element of the slice; andnrepresents the index number of the last element of the slice plus one (if the last element has the index number 2, then wenwill be 3, if the last element has the index number 4, thennwill be 5, and so on).

When we need to select the first or last x elements (x stands for a number), we can use even simpler syntax shortcuts:
a_list[:x]when we want to select the firstxelements.a_list[-x:]when we want to select the lastxelements.

Let's look at how we extract the first four elements from the first row (with data about Facebook):
first_4_fb = row_1[:4]
print(first_4_fb)['Facebook', 0.0, 'USD', 2974676]
The last three elements from that same row:
last_3_fb = row_1[-3:]
print(last_3_fb)['USD', 2974676, 3.5]
And elements three and four from the fifth row (with data about Pandora):
pandora_3_4 = row_5[2:4]
print(pandora_3_4)['USD', 1126879]
Python List of Lists
Previously, we introduced lists as a better alternative to using one variable per data point. Instead of having a separate variable for each of the five data points 'Facebook', 0.0, 'USD', 2974676, 3.5, we can bundle the data points together into a list, and then store the list in a single variable.
So far, we've been working with a data set having five rows, and we've been storing each row as a list in a separate variable (the variables row_1, row_2, row_3, row_4, and row_5). If we had a data set with 5,000 rows, however, we'd end up with 5,000 variables, which will make our code messy and almost impossible to work with.
To solve this problem, we can store our five variables in a single list:

As we can see, data_set is a list that stores five other lists (row_1, row_2, row_3, row_4, and row_5). A list that contains other lists is called a list of lists.
The data_set variable is still a list, which means we can retrieve individual list elements and perform list slicing using the syntax we learned. Below, we:
- Retrieve the first list element (
row_1) usingdata_set[0]. - Retrieve the last list element (
row_5) usingdata_set[-1]. - Retrieve the first two list elements (
row_1androw_2) by performing list slicing usingdata_set[:2].

We'll often need to retrieve individual elements from a list that's part of a list of lists — for instance, we may want to retrieve the value 3.5 from ['Facebook', 0.0, 'USD', 2974676, 3.5], which is part of the data_set list of lists. Below, we extract 3.5 from data_set using what we've learned:
- We retrieve
row_1usingdata_set[0], and assign the result to a variable namedfb_row. - We print
fb_row, which outputs['Facebook', 0.0, 'USD', 2974676, 3.5]. - We retrieve the last element from
fb_rowusingfb_row[-1](sincefb_rowis a list), and assign the result to a variable namedfb_rating. - Print
fb_rating, which outputs3.5

Above, we retrieved 3.5 in two steps: we first retrieved data_set[0], and then we retrieved fb_row[-1]. However, there's an easier way to retrieve the same value of 3.5 by chaining the two indices ([0] and [-1]) — the code data_set[0][-1] retrieves 3.5:

Above, we've seen two ways of retrieving the value 3.5. Both ways lead to the same output (3.5), but the second way involves less typing because it elegantly combines the steps we see in the first case. While you can choose either option, people generally choose the second one.
Let's transform our five individual lists into a list of lists:
app_data_set = [row_1, row_2, row_3, row_4, row_5]
print(app_data_set)Repetitive List Processes
Previously in this lesson, we were interested in computing the average rating of an app. This was a doable task when we were working with only three rows, but the more rows we add the harder it becomes. Using our strategy from earlier, we'll:
- Retrieve each individual rating.
- Sum up the ratings.
- Divide by the number of ratings.

As you can see, with five ratings this becomes complex. If we were working with data containing 1,000s of rows, it would require an impractical amount of code! We need to find a simple way to retrieve many ratings.
Looking at the code example above, we see that a process keeps repeating: we select the last list element for each list within app_data_set. The app_data_set stores five lists, so we repeat the same process five times. What if we could tell Python directly that we want to repeat this process for each list in app_data_set?
Fortunately, we can do that — Python offers us an easy way to repeat a process, which helps us enormously when we need to repeat a process hundreds, thousands, or even millions of times.
Let's say we have a list [3, 5, 1, 2] assigned to a variable ratings, and we want to repeat the following process: for each element in ratings, print that element. This is how we could translate that into Python syntax:

In our first example above, the process we wanted to repeat was _"extract the last element for each list in app_data_set"_. This is how we can translate that process into Python syntax:

Let's try to get a better understanding of what happens above. Python isolates, one at a time, each list element from app_data_set, and assigns it to each_list (which basically becomes a variable that stores a list — we'll discuss this more on the next screen):

The code in the last diagram above is a much more simplified and abstracted version of the code below:

Using the technique above requires us to write a line of code for every row in the data set. But using the for each_list in app_data_set technique requires us to write only two lines of code regardless of the number of rows in the data set — the data set can have five rows or one million.
Our intermediate goal is to use this new technique to compute the average rating for our five rows above, and our final goal is to compute the average rating for our data set with 7,197 rows. We'll do exactly that over the next few screens of this lesson, but for now, we'll focus on practicing this technique to get a good grasp of it.
Before writing any code, we need to indent the code we want repeated four space characters to the right:

Technically, we only need to indent the code at least one space character to the right, but the convention in the Python community is to use four space characters. This helps with readability — it will be easier for other people who follow this convention to read your code, and it will be easier for you to read theirs.
Let's use this technique to print the name and rating of each app:
for each_list in app_data_set:
name = each_list[0]
rating = each_list[-1]
print(name, rating)Facebook 3.5 Instagram 4.5 Clash of Clans 4.5 Temple Run 4.5 Pandora - Music & Radio 4.0
Lists and For Loops in Python
The technique we've just learned is called a loop. Loops are an incredibly useful tool that are used to perform repetitive processes with Python lists. Because we always start with for (like in for some_variable in some_list:), this technique is known as a for loop.
These are the structural parts of a for loop:

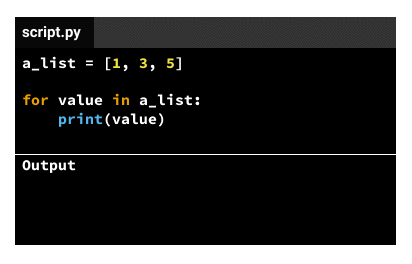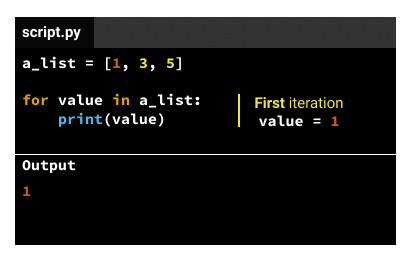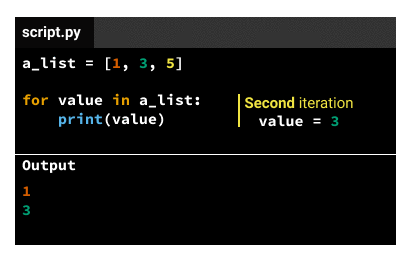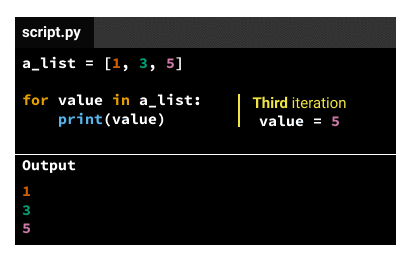
The indented code in the body gets executed the same number of times as elements in the iterable variable. If the iterable variable is a list that has three elements, the indented code in the body gets executed three times. We call each code execution an iteration, so there'll be three iterations for a list that has three elements. For each iteration, the iteration variable will take a different value, following this pattern:
- For the first iteration, the value is the first element of the iterable (from the example above,
1). - For the second iteration, the value is the second element of the iterable (from the example above,
3). - For the third iteration, the value is the third element of the iterable (from the example above,
5).
The name of the interation variable can be whatever you like - if you replaced value in the code above with dog, the code will work exactly the same way. That said, it's convention to use something that helps communicate what the data is.
The code outside the loop body can interact with the code inside the loop body. For instance, in the code below we:
- Initialize a variable
a_sumwith a value of zero outside the loop body. - We loop (or iterate) over
a_list. For every iteration of the loop, we:- Perform an addition (inside the loop body) between the current value of the iteration variable
valueand the current value stored ina_sum(a_sumwas defined outside the loop body). - Assign the result of the addition back to
a_sum(inside the loop body). - Print the value of the
a_sumvariable (inside the loop body). Notice that the value ofa_sumchanges after each addition. At the end of the loop,a_sumhas the value9, which is equivalent to the sum of the numbers ina_list(1 + 3 + 5).
- Perform an addition (inside the loop body) between the current value of the iteration variable

Above, we created a way to sum up the numbers in a list. We can use this technique to sum up the ratings in our dataset. Once we have the sum, we only need to divide by the number of ratings to get the average value.
rating_sum = 0
for row in app_data_set:
rating = row[-1]
rating_sum = rating_sum + rating
avg_rating = rating_sum / len(app_data_set)
print(avg_rating)4.2
We've covered the fundamentals of for loops here, but if you'd like some more practice, we also have tutorials on for loop basics and advanced for loops that you can check out.
Alternative Way to Compute a List Average
Now we'll learn an alternative way to compute the average rating value. Once we create a list, we can add (or append) values to it using the append() command.

Unlike other commands we've learned, notice that append() has a special syntactical usage, following the pattern list_name.append() rather than being simply used as append().
Now that we know how to append values to a list, we can take the steps below to compute the average app rating:
- We initialize an empty list.
- We start looping over our data set and extract the ratings.
- We append the ratings to the empty list we created at step one.
- Once we have all the ratings, we:
- use the
sum()command to sum up all the ratings (to be able to usesum(), we'll need to store the ratings as floats or integers); and then - we divide the sum by the number of ratings (which we can get using the
len()command).
- use the
Below, we can see the steps above implemented for our data set with five rows:

We can also use append() to add another row to our list of lists by appending the data as a list. Let's look at how that works:
row_6 = ['Pinterest', 0.0, 'USD', 1061624, 4]
app_data_set.append(row_6)
print(app_data_set)Now, let's use the technique we learned above to calculate the average rating of all six apps:
all_ratings = []
for row in app_data_set:
rating = float(row[-1])
all_ratings.append(rating)
avg_rating = sum(all_ratings) / len(all_ratings)
print(avg_rating)4.166666666666667
Next Steps
In this tutorial we learned how to:
- use Python lists to store and work with data
- access values stored in lists using positive and negative indexing
- use lists of lists to work with tabular data
- use for loops to automate repetitive tasks
- append values to lists
If you'd like to practice working with Python lists, this tutorial is based on part of our free Python Fundamentals course. The course can be taken from your web browser, and you'll write code to analyze the full dataset of over 7,000 mobile apps!