Introduction to AWS for Data Scientists
These days, many businesses use cloud based services; as a result various companies have started building and providing such services. Amazon began the trend, with Amazon Web Services (AWS). While AWS began in 2006 as a side business, it now makes $14.5 billion in revenue each year.
Other leaders in this area include:
- Google—Google Cloud Platform (GCP)
- Microsoft—Azure Cloud Services
- IBM—IBM Cloud
Cloud services are useful to businesses of all sizes—small companies benefit from the low cost, as compared to buying servers. Larger companies gain reliability and productivity, with less cost, since the services run on optimum energy and maintenance.
These services are also powerful tools that you can use to ease your work. Setting up a Hadoop cluster to work with Spark manually could take days if it’s your first time, but AWS sets that up for you in minutes.
We are going to focus on AWS here because it comes with more products relevant to data scientists. In general, we can say familiarity with AWS helps data scientists to:
- Prepare the infrastructure they need for their work (e.g. Hadoop clusters) with ease
- Easily set up necessary tools (e.g. Spark)
- Decrease expenses significantly—such as by paying for huge Hadoop clusters only when needed
- Spend less time on maintenance, as there's no need for tasks like manually backing up data
- Develop products and features that are ready to launch without needing help from engineers (or, at least, needing very little help)
In this post, I'll give an overview of useful AWS services for data scientists — what they are, why they're useful, and how much they cost.
Elastic Compute Cloud (EC2)
Many other AWS services are built around EC2, making it a core piece of AWS. EC2s are in fact (virtual) servers that you can rent from Amazon and set up or run any program/application on it. These servers come in different operating systems and Amazon charges you based on the computing power and capacity of the server (i.e. Hard Drive capacity, CPU, Memory, etc.) and the duration the server been up.
EC2 benefits
For example, you can rent a Linux or Windows server with computation power and storage capacity that fits your specific needs and Amazon charges you based on these specifications and the duration you use the server. Note that previously AWS charged at least for one hour for each instance you run, but they recently changed their policy to per-second billing.
One of the good things about EC2 is its scalability—by changing memory, number of vCPUs, bandwidth, and so on, you can easily scale your system up or down. Therefore, if you think a system doesn't have enough power for running a specific task or a calculation in your project is taking too long, you can scale up to finish your work and later scale down again to reduce the cost. EC2 is also very reliable, since Amazon takes care of the maintenance.
EC2 cost
EC2 instances are relatively low-cost, and there are different types of instances for different use cases. For example, there are instances that are optimized for computation and those have relatively lower cost on CPU usage. Or those optimized for memory have lower cost on memory usage.
To give you an idea on EC2 cost, a general purpose medium instance with 2 vCPUs and 4 GIG of memory (at the time of writing this article) costs $0.0464 per hour for a linux server, see Amazon EC2 Pricing for prices and more information. AWS also now has spot instance pricing, which calculates the price based on supply/demand at the time and provides up to a 90
Note that you have to add storage costs to the above as well. Most EC2 instances use Elastic Block Store (EBS) systems, which cost around $0.1/GIG/month; see the prices here. Storage optimized instances use Solid State Drive (SSD) systems, which are more expensive.

EBS acts like an external hard drive. You can attach it to an instance, de-attach it, and re-attach it to another instance. You can also stop or terminate an instance after your work is done and not pay for the instance when it is idle.
If you stop an instance, AWS will still keep the EBS live and as a result the data you have on the hard drive will remain intact (it’s like powering off your computer). Later you can restart stopped instances and get access to the data you generated, or even tools you installed there in the previous sessions. However, when you stop an instance instead of terminating it, Amazon will still charge you for the attached EBS (~$0.1/GIG/month). If you terminate the instance, the EBS will get cleaned so you will lose all the data on that instance, but you no longer need to pay for the EBS.
If you need to keep the data on EBS for your future use (let’s say you have custom tools installed on that instance and you don’t want to redo your work again later) you can make a snapshot of the EBS and can later restore it in a new EBS and attach it to a new instance.
Snapshots get stored on S3 (Amazon’s cheap storage system; we will get to it later) so it will cost you less ($0.05 per GB-month) to keep the data in EBS like that. However, it takes time (depending on the size of the EBS) to get snapshot and restoring it. Besides, reattaching a restored EBS to EC2 instance is not that straight forward, so it only make sense to use a snapshot like that if you know you are not going to use that EBS for a while.
Note that to scale an instance up or down, you have to first stop the instance and then change the instance specifications. You can't decrease the EBS size, only increase it, and it's more difficult. You have to:
- Stop the instance
- Make a snapshot out of the EBS
- Restore the snapshot in an EBS with the new size
- De-attach previous EBS
- Attach the new one.
Simple Storage Service (S3)
S3 is AWS object (file) storage service. S3 is like Dropbox or Google drive, but way more scalable and is made particularly to work with codes and applications.
S3 doesn’t provide a user friendly interface since it is designed to work with online applications, not the end user. Therefore, working with S3 through APIs is easier than through its web console and there are many libraries and APIs developed (in various languages) to work with this service. For example, Boto3 is a S3 library written in Python (in fact Boto3 is suitable for working with many other AWS services as well) .
S3 stores files based on buckets and keys. Buckets are similar to root folders, and keys are similar to subfolders and files. So if you store a file named my_file.txt on s3 like myproject/mytextfiles/my_file.txt, then “myproject” is the bucket you are using and then mytextfiles/my_file.txt is the key to that file. This is important to know since APIs will ask for the bucket and key separately when you want to retrieve your file from s3.
S3 benefits
There is no limit on the size of data you can store on S3—you just have to pay for the storage based on the size you need per month.
S3 is also very reliable and “it is designed to deliver 99.999999999
The cost is low, starting at $0.023 per GB per month for standard access, if you want to get access to these files regularly. It could go down even lower if you don’t need to load data too frequently. See Amazon S3 Pricing for more information. AWS may charge you for other S3 related actions such as requests through APIs, but the cost for those are insignificant (less than $0.05 per 1,000 requests in most cases). AWS RDS is a relational database service in the cloud. RDS currently supports SQL Server, MySQL, PostgreSQL, ORACLE, and a couple of other SQL-based frameworks. AWS sets up the system you need and configures the parameters so you can have a relational database up and running in minutes. RDS also handles backup, recovery, software patching, failure detection, and repairs by itself so you don’t need to maintain the system. RDS is scalable, both computing power and the storage capacity can be scaled up or down easily. RDS system runs on EC2 servers (as I mentioned EC2 servers are the core of most of AWS services, including RDS service) so by computing power here we mean the computing power of the EC2 server our RDS service is running on, and you can scale up the computing power of this system up to 32 vCPUs and 244 GiB of RAM and changing the scale would not take more than few minutes. Scaling the storage requirements up or down is also possible. Amazon Aurora is a version of MySQL and PostgreSQL with some additional features, and can automatically scale up when more storage space is needed (you can define the maximum). The MySQL, MariaDB, Oracle, and PostgreSQL engines allow you to scale up on the fly without downtime. The cost of RDS servers is based on three factors: computational power, storage, and data transfer. For example, a PostgreSQL system with medium computational power (2 vCPUs and 8 gig of memory) costs $0.182 per hour; you can pay less if you go under a one- or three-year contract. For storage, there are a variety of options and prices. If you choose single availability zone General Purpose SSD Storage (gp2), a good option for data scientists, the cost for a server in north Virginia at the time of writing this article is $0.115 per GB-month, and you can select from 5 GB to 16 TB of SSD. For data transfer, the cost varies a little based on the source and destination of data (one of which is RDS). For example, all data transferred from the internet into RDS is free. The first gig of data transferred from RDS to the internet is free as well, and for the next 10 terabytes of data in a month it costs $0.09 per GB; the cost decreases for transfering more data than that. Redshift is Amazon's data warehouse service; it is a distributed system (something like the Hadoop framework) which lets you store huge amounts of data and get queries. The difference between this service and RDS is its high capacity and ability to work with big data (terabytes and petabytes). You can use simple SQL queries on Redshift as well. Redshift works on a distributed framework—data is distributed on different nodes (servers) connected on a cluster. Simply put, queries on a distributed system run in parallel on all the nodes and then the results get collected from each node and get summarized. Redshift is highly scalable, meaning in theory (depending on the query, network structure and design, service specification, etc.) the speed of getting query out of 1 terabyte of data and 1 petabyte of data can match by scaling up (adding more cluster to) the system. When you create a table on Redshift, you can choose one of three distribution styles: EVEN, KEY, or ALL. Redshift has two types of instances: Dense Compute or Dense Storage. Dense Compute is optimized for fast querying and it is cost effective for less than 500GB of data in size (~$5,500/TB/Year for a three-year contract with partial upfront). Dense Storage is optimized for high size storage (~$1,000/TB/Year for a three-year contract with partial upfront) and is cost effective for +500GB, but it is slower. You can find more general pricing here. You can also save a large amount of data on S3 and use Amazon Redshift Spectrum to run SQL query on that data. For Redshift Spectrum, AWS charges you by the number of bytes scanned by Redshift Spectrum per query; and $5 per terabyte of data scanned (10 megabyte minimum per query). EMR is suitable for setting up Hadoop clusters with Spark and other distributed type applications. A Hadoop cluster can be used as a compute engine or a (distributed) storage system. However, if the data is so big that you need a distributed system to handle it, Redshift is more suitable and way cheaper than storing in EMR. There are three types of nodes on a cluster: Since you can set EMR to install Apache Spark, this service is good for for cleaning, reformatting, and analyzing big data. You can use EMR on-demand, meaning you can set it to grab the code and data from a source (e.g. S3 for the code, and S3 or RDS for the data), run the task on the cluster, and store the results somewhere (again s3, RDS, or Redshift) and terminate the cluster. By using the service in such a way, you can reduce the cost of your cluster significantly. In my opinion, EMR is one of the most useful AWS services for data scientists. To setup an EMR cluster, you need to first configure applications you want to have on the cluster. Note that different versions of EMR come with different versions of the applications. For example, if you configure EMR version 5.10.0 to install Spark, the default version of the Spark for this version is 2.2.0. So if your code works only on Spark 1.6, you need to run EMR on the 4.x version. EMR will set up the network and configures all the nodes on the cluster along with needed tools. An EMR cluster comes with one master instance and a number of core nodes (slave instances). You can choose the number of core nodes, and can even select to have no core node and only use the master server for your work. Like other services, you can choose the computational power of the servers and the storage size available on each node. You can use autoscale option for your core nodes, meaning you can add rules to the system to add/remove core node (up to a maximum number you choose) if needed while running your code. See Using Automatic Scaling in Amazon EMR for more information on auto scaling. EMR pricing is based on the computational power you choose for different instances (master, core and task nodes). Basically, it is the cost of the EC2 servers plus the cost of EMR. You can find detailed pricing here. I have developed many end-to-end data-driven products (including reporting, machine learning models, and product health checking systems) for our company using Python and Spark on AWS, which later became good sources of income for the company. Experience working with cloud services, especially a well-known one like AWS, is a huge plus in your data scientist career. Many companies depend on these services now and use them constantly, so you being familiar with these services will give them the confidence that you need less training to get on board. With more and more people moving into data science, you want your resume to stand out as much as possible. Do you have cloud tips to add? Let us know.S3 cost
Relational Database Service (RDS)
RDS benefits
RDS cost

Redshift
Redshift benefits
Redshift cost
Elastic MapReduce (EMR)
EMR benefits
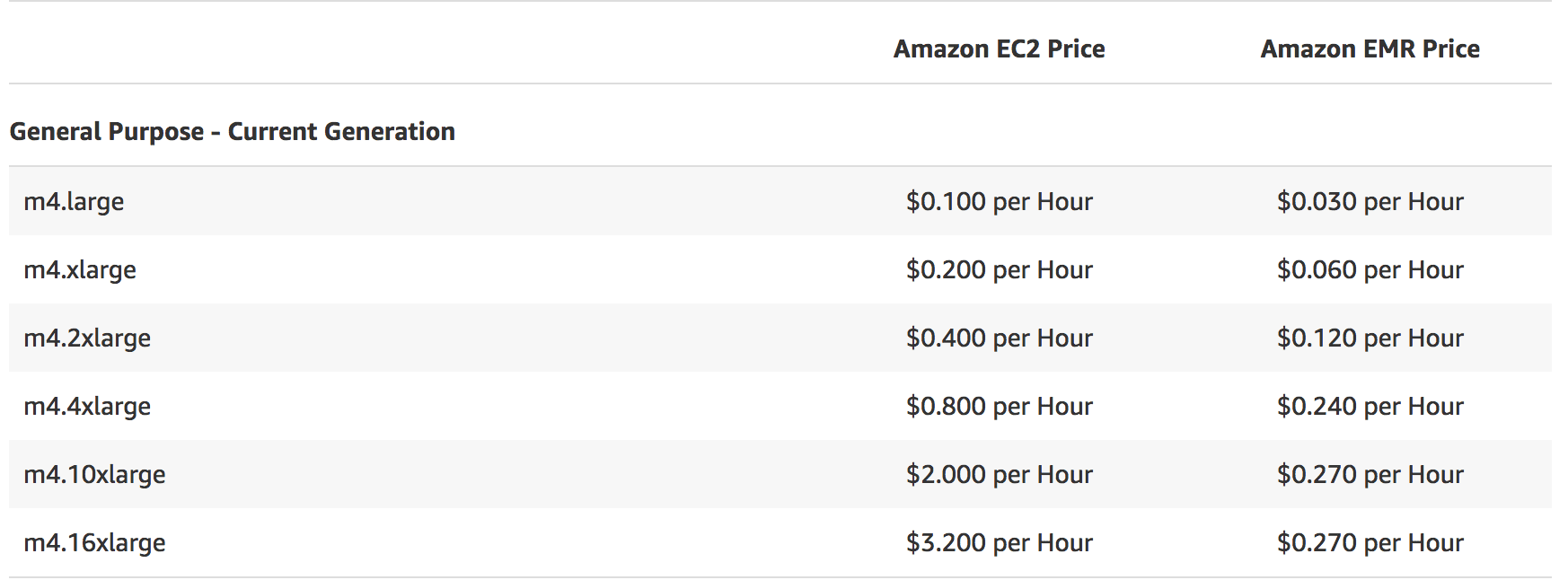
EMR pricing
Conclusion