Tutorial: Building An Analytics Data Pipeline In Python
If you've ever wanted to learn Python online with streaming data, or data that changes quickly, you may be familiar with the concept of a data pipeline. Data pipelines allow you transform data from one representation to another through a series of steps. Data pipelines are a key part of data engineering, which we teach in our new Data Engineer Path. In this tutorial, we're going to walk through building a data pipeline using Python and SQL.
A common use case for a data pipeline is figuring out information about the visitors to your web site. If you're familiar with Google Analytics, you know the value of seeing real-time and historical information on visitors. In this blog post, we'll use data from web server logs to answer questions about our visitors.
If you're unfamiliar, every time you visit a web page, such as the Dataquest Blog, your browser is sent data from a web server. To host this blog, we use a high-performance web server called Nginx. Here's how the process of you typing in a URL and seeing a result works:

The process of sending a request from a web browser to a server.
First, the client sends a request to the web server asking for a certain page. The web server then loads the page from the filesystem and returns it to the client (the web server could also dynamically generate the page, but we won't worry about that case right now). As it serves the request, the web server writes a line to a log file on the filesystem that contains some metadata about the client and the request. This log enables someone to later see who visited which pages on the website at what time, and perform other analysis.
Here are a few lines from the Nginx log for this blog:
X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/css/jupyter.css HTTP/1.1" 200 30294 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)"
X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/js/jquery-1.11.1.min.js HTTP/1.1" 200 95786 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)
"X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/js/markdeep.min.js HTTP/1.1" 200 58713 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)"
X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/js/index.js HTTP/1.1" 200 3075 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)"
X.X.X.X - - [09/Mar/2017:01:16:00 +0000] "GET /blog/atom.xml HTTP/1.1" 301 194 "-" "UniversalFeedParser/5.2.1 +https://code.google.com/p/feedparser/"
X.X.X.X - - [09/Mar/2017:01:16:01 +0000] "GET /blog/feed.xml HTTP/1.1" 200 48285 "-" "UniversalFeedParser/5.2.1 +https://code.google.com/p/feedparser/"
Each request is a single line, and lines are appended in chronological order, as requests are made to the server. The format of each line is the Nginx combined format, which looks like this internally:
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent"
Note that the log format uses variables like $remote_addr, which are later replaced with the correct value for the specific request. Here are descriptions of each variable in the log format:
-
$remote_addr— the ip address of the client making the request to the server. For the first line in the log, this isX.X.X.X(we removed the ips for privacy). -
$remote_user— if the client authenticated with basic authentication, this is the user name. Blank in the first log line. -
$time_local— the local time when the request was made.09/Mar/2017:01:15:59 +0000in the first line. -
$request— the type of request, and the URL that it was made to.GET /blog/assets/css/jupyter.css HTTP/1.1in the first line. -
$status— the response status code from the server.200in the first line. -
$body_bytes_sent— the number of bytes sent by the server to the client in the response body.30294in the first line. -
$http_referrer— the page that the client was on before sending the current request.https://www.dataquest.io/blog/in the first line. -
$http_user_agent— information about the browser and system of the client.Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)in the first line.
The web server continuously adds lines to the log file as more requests are made to it. Occasionally, a web server will rotate a log file that gets too large, and archive the old data.
As you can imagine, companies derive a lot of value from knowing which visitors are on their site, and what they're doing. For example, realizing that users who use the Google Chrome browser rarely visit a certain page may indicate that the page has a rendering issue in that browser.
Another example is in knowing how many users from each country visit your site each day. It can help you figure out what countries to focus your marketing efforts on. At the simplest level, just knowing how many visitors you have per day can help you understand if your marketing efforts are working properly.
In order to calculate these metrics, we need to parse the log files and analyze them. In order to do this, we need to construct a data pipeline.
Thinking About The Data Pipeline
Here's a simple example of a data pipeline that calculates how many visitors have visited the site each day:

Getting from raw logs to visitor counts per day.
As you can see above, we go from raw log data to a dashboard where we can see visitor counts per day. Note that this pipeline runs continuously -- when new entries are added to the server log, it grabs them and processes them. There are a few things you've hopefully noticed about how we structured the pipeline:
-
Each pipeline component is separated from the others, and takes in a defined input, and returns a defined output.
- Although we don't show it here, those outputs can be cached or persisted for further analysis.
- We store the raw log data to a database. This ensures that if we ever want to run a different analysis, we have access to all of the raw data.
- We remove duplicate records. It's very easy to introduce duplicate data into your analysis process, so deduplicating before passing data through the pipeline is critical.
- Each pipeline component feeds data into another component. We want to keep each component as small as possible, so that we can individually scale pipeline components up, or use the outputs for a different type of analysis.
Now that we've seen how this pipeline looks at a high level, let's implement it in Python.
Processing And Storing Webserver Logs
In order to create our data pipeline, we'll need access to webserver log data. We created a script that will continuously generate fake (but somewhat realistic) log data. Here's how to follow along with this post:
After running the script, you should see new entries being written to log_a.txt in the same folder. After 100 lines are written to log_a.txt, the script will rotate to log_b.txt. It will keep switching back and forth between files every 100 lines.
Once we've started the script, we just need to write some code to ingest (or read in) the logs. The script will need to:
- Open the log files and read from them line by line.
- Parse each line into fields.
- Write each line and the parsed fields to a database.
- Ensure that duplicate lines aren't written to the database.
The code for this is in the store_logs.py file in this repo if you want to follow along.
In order to achieve our first goal, we can open the files and keep trying to read lines from them.
The below code will:
- Open both log files in reading mode.
-
Loop forever.
-
Figure out where the current character being read for both files is (using the
tellmethod). -
Try to read a single line from both files (using the
readlinemethod). -
If neither file had a line written to it, sleep for a bit then try again.
-
Before sleeping, set the reading point back to where we were originally (before calling
readline), so that we don't miss anything (using theseekmethod).
-
Before sleeping, set the reading point back to where we were originally (before calling
- If one of the files had a line written to it, grab that line. Recall that only one file can be written to at a time, so we can't get lines from both files.
-
Figure out where the current character being read for both files is (using the
f_a = open(LOG_FILE_A, 'r')
f_b = open(LOG_FILE_B, 'r')
while True:
where_a = f_a.tell()
line_a = f_a.readline()
where_b = f_b.tell()
line_b = f_b.readline()
if not line_a and not line_b:
time.sleep(1)
f_a.seek(where_a)
f_b.seek(where_b)
continue
else:
if line_a:
line = line_a
else:
line = line_b
Once we've read in the log file, we need to do some very basic parsing to split it into fields. We don't want to do anything too fancy here -- we can save that for later steps in the pipeline. You typically want the first step in a pipeline (the one that saves the raw data) to be as lightweight as possible, so it has a low chance of failure. If this step fails at any point, you'll end up missing some of your raw data, which you can't get back!
In order to keep the parsing simple, we'll just split on the space () character then do some reassembly:

Parsing log files into structured fields.
In the below code, we:
-
Take a single log line, and split it on the space character (
). -
Extract all of the fields from the split representation.
- Note that some of the fields won't look "perfect" here -- for example the time will still have brackets around it.
-
Initialize a
createdvariable that stores when the database record was created. This will enable future pipeline steps to query data.
split_line = line.split(" ")
remote_addr = split_line[0]
time_local = split_line[3] + " " + split_line[4]
request_type = split_line[5]
request_path = split_line[6]
status = split_line[8]
body_bytes_sent = split_line[9]
http_referer = split_line[10]
http_user_agent = " ".join(split_line[11:])
created = datetime.now().strftime("%Y-%m-%dT%H:%M:%S")
We also need to decide on a schema for our SQLite database table and run the needed code to create it. Because we want this component to be simple, a straightforward schema is best. We'll use the following query to create the table:
CREATE TABLE IF NOT EXISTS logs (
raw_log TEXT NOT NULL UNIQUE,
remote_addr TEXT,
time_local TEXT,
request_type TEXT,
request_path TEXT,
status INTEGER,
body_bytes_sent INTEGER,
http_referer TEXT,
http_user_agent TEXT,
created DATETIME DEFAULT CURRENT_TIMESTAMP
)
Note how we ensure that each raw_log is unique, so we avoid duplicate records. Also, note how we insert all of the parsed fields into the database along with the raw log. There's an argument to be made that we shouldn't insert the parsed fields since we can easily compute them again. However, adding them to fields makes future queries easier (we can select just the time_local column, for instance), and it saves computational effort down the line.
Keeping the raw log helps us in case we need some information that we didn't extract, or if the ordering of the fields in each line becomes important later. For these reasons, it's always a good idea to store the raw data.
Finally, we'll need to insert the parsed records into the logs table of a SQLite database. Choosing a database to store this kind of data is very critical. We picked SQLite in this case because it's simple, and stores all of the data in a single file. If you're more concerned with performance, you might be better off with a database like Postgres.
In the below code, we:
- Connect to a SQLite database.
- Instantiate a cursor to execute queries.
-
Put together all of the values we'll insert into the table (
parsedis a list of the values we parsed earlier) - Insert the values into the database.
- Commit the transaction so it writes to the database.
- Close the connection to the database.
conn = sqlite3.connect(DB_NAME)
cur = conn.cursor()
args = [line] + parsed
cur.execute('INSERT INTO logs VALUES (?,?,?,?,?,?,?,?,?)', args)
conn.commit()
conn.close()
We just completed the first step in our pipeline! Now that we have deduplicated data stored, we can move on to counting visitors.
Counting Visitors With A Data Pipeline
We can use a few different mechanisms for sharing data between pipeline steps:
- Files
- Databases
- Queues
In each case, we need a way to get data from the current step to the next step. If we point our next step, which is counting ips by day, at the database, it will be able to pull out events as they're added by querying based on time. Although we'll gain more performance by using a queue to pass data to the next step, performance isn't critical at the moment.
We'll create another file, count_visitors.py, and add in some code that pulls data out of the database and does some counting by day.
We'll first want to query data from the database. In the below code, we:
- Connect to the database.
- Query any rows that have been added after a certain timestamp.
- Fetch all the rows.
def get_lines(time_obj):
conn = sqlite3.connect(DB_NAME)
cur = conn.cursor()
cur.execute("SELECT remote_addr,time_local FROM logs WHERE created > ?", [time_obj])
resp = cur.fetchall()
return resp
We then need a way to extract the ip and time from each row we queried. The below code will:
- Initialize two empty lists.
- Pull out the time and ip from the query response and add them to the lists.
def get_time_and_ip(lines):
ips = []
times = []
for line in lines:
ips.append(line[0])
times.append(parse_time(line[1]))
return ips, times
You may note that we parse the time from a string into a datetime object in the above code. The code for the parsing is below:
def parse_time(time_str):
time_obj = datetime.strptime(time_str, '[%d/%b/%Y:%H:%M:%S %z]')
return time_objOnce we have the pieces, we just need a way to pull new rows from the database and add them to an ongoing visitor count by day. The below code will:
- Get the rows from the database based on a given start time to query from (we get any rows that were created after the given time).
-
Extract the ips and
datetimeobjects from the rows. - If we got any lines, assign start time to be the latest time we got a row. This prevents us from querying the same row multiple times.
-
Create a key,
day, for counting unique ips. - Add each ip to a set that will only contain unique ips for each day.
lines = get_lines(start_time)
ips, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for ip, time_obj in zip(ips, times):
day = time_obj.strftime("%d-%m-%Y")
if day not in unique_ips:
unique_ips[day] = set()
unique_ips[day].add(ip)
This code will ensure that unique_ips will have a key for each day, and the values will be sets that contain all of the unique ips that hit the site that day.
After sorting out ips by day, we just need to do some counting. In the below code, we:
-
Assign the number of visitors per day to
counts. -
Extract a list of tuples from
counts. - Sort the list so that the days are in order.
- Print out the visitor counts per day.
for k, v in unique_ips.items():
counts[k] = len(v)
count_list = counts.items()
count_list = sorted(count_list, key=lambda x: x[0])
for item in count_list:
print("{}: {}".format(*item))
We can then take the code snippets from above so that they run every 5 seconds:
unique_ips = {}
counts = {}
start_time = datetime(year=2017, month=3, day=9)
while True:
lines = get_lines(start_time)
ips, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for ip, time_obj in zip(ips, times):
day = time_obj.strftime("%d-%m-%Y")
if day not in unique_ips:
unique_ips[day] = set()
unique_ips[day].add(ip)
for k, v in unique_ips.items():
counts[k] = len(v)
count_list = counts.items()
count_list = sorted(count_list, key=lambda x: x[0])
for item in count_list:
print("{}: {}".format(*item))
time.sleep(5)
Pulling The Pipeline Together
We've now taken a tour through a script to generate our logs, as well as two pipeline steps to analyze the logs. In order to get the complete pipeline running:
- Clone the analytics_pipeline repo from Github if you haven't already.
- Follow the README.md file to get everything setup.
-
Execute
log_generator.py. -
Execute
store_logs.py. -
Execute
count_visitors.py.
After running count_visitors.py, you should see the visitor counts for the current day printed out every 5 seconds. If you leave the scripts running for multiple days, you'll start to see visitor counts for multiple days.
Congratulations! You've setup and run a data pipeline. Let's now create another pipeline step that pulls from the database.
Adding Another Step To The Data Pipeline
One of the major benefits of having the pipeline be separate pieces is that it's easy to take the output of one step and use it for another purpose. Instead of counting visitors, let's try to figure out how many people who visit our site use each browser. This will make our pipeline look like this:
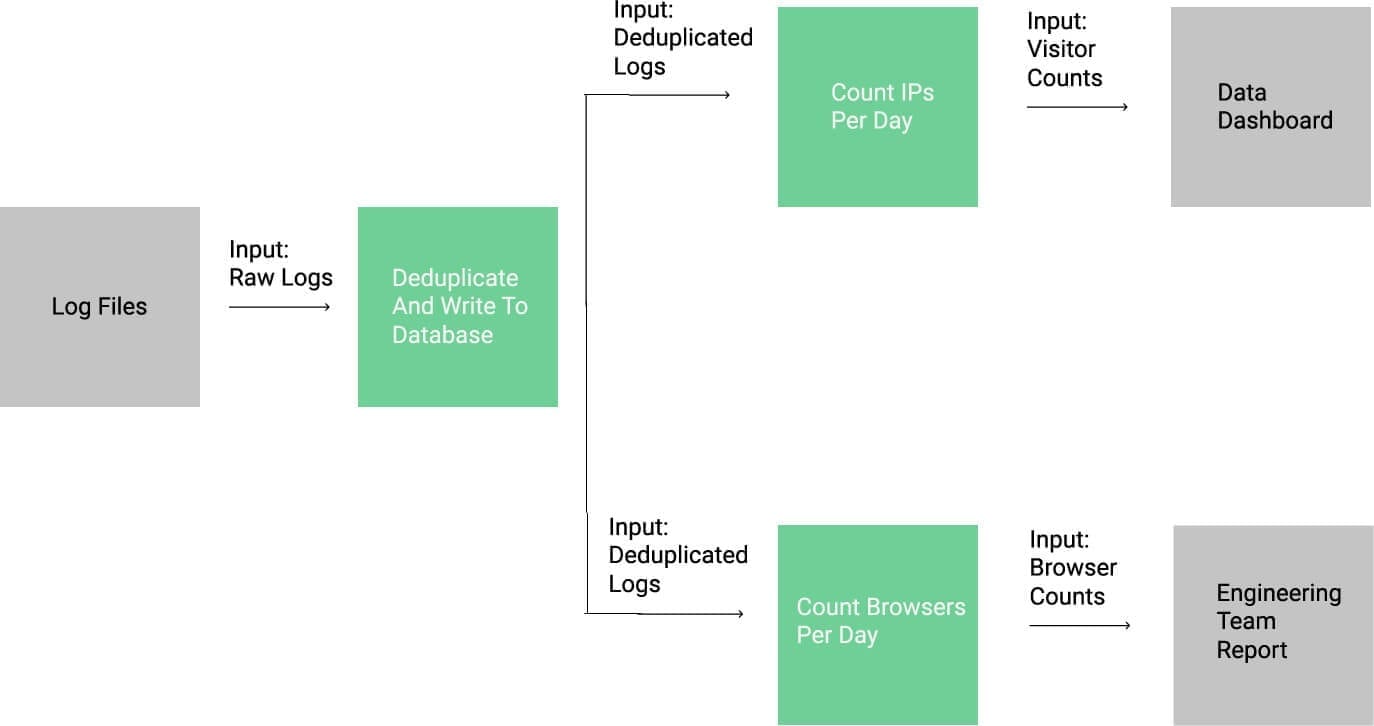
We now have one pipeline step driving two downstream steps.
As you can see, the data transformed by one step can be the input data for two different steps. If you want to follow along with this pipeline step, you should look at the count_browsers.py file in the repo you cloned.
In order to count the browsers, our code remains mostly the same as our code for counting visitors. The main difference is in us parsing the user agent to retrieve the name of the browser. In the below code, you'll notice that we query the http_user_agent column instead of remote_addr, and we parse the user agent to find out what browser the visitor was using:
def get_lines(time_obj):
conn = sqlite3.connect(DB_NAME)
cur = conn.cursor()
cur.execute("SELECT time_local,http_user_agent FROM logs WHERE created > ?", [time_obj])
resp = cur.fetchall()
return resp
def get_time_and_ip(lines):
browsers = []
times = []
for line in lines:
times.append(parse_time(line[0]))
browsers.append(parse_user_agent(line[1]))
return browsers, times
def parse_user_agent(user_agent):
browsers = ["Firefox", "Chrome", "Opera", "Safari", "MSIE"]
for browser in browsers:
if browser in user_agent:
return browser
return "Other"We then modify our loop to count up the browsers that have hit the site:
browsers, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for browser, time_obj in zip(browsers, times):
if browser not in browser_counts:
browser_counts[browser] = 0
browser_counts[browser] += 1
Once we make those changes, we're able to run python count_browsers.py to count up how many browsers are hitting our site.
We've now created two basic data pipelines, and demonstrated some of the key principles of data pipelines:
- Making each step fairly small.
- Passing data between pipelines with defined interfaces.
- Storing all of the raw data for later analysis.
Extending Data Pipelines
After this data pipeline tutorial, you should understand how to create a basic data pipeline with Python. But don't stop now! Feel free to extend the pipeline we implemented. Here are some ideas:
- Can you make a pipeline that can cope with much more data? What if log messages are generated continuously?
- Can you geolocate the IPs to figure out where visitors are?
- Can you figure out what pages are most commonly hit?
If you have access to real webserver log data, you may also want to try some of these scripts on that data to see if you can calculate any interesting metrics.
Want to take your skills to the next level with interactive, online data engineering courses? Try our Data Engineer Path, which helps you learn data engineering from the ground up.