Data Retrieval and Cleaning: Tracking Migratory Patterns
Advancing your skills is an important part of being a data scientist. When starting out, you mostly focus on learning a programming language, proper use of third party tools, displaying visualizations, and the theoretical understanding of statistical algorithms. The next step is to test your skills on more difficult data sets.
Sometimes these data sets require extensive cleaning, are poorly formatted, or are just very difficult to find. There is a lot of content out there around the importance of understanding the data around us, but there is little to be found on how you actually get the data.
The initial data investigation, exploration, and retrieval are the most important steps to learn as you grow as a data scientist. Finding and cleaning a data set from a combination of sources admittedly incurs an upfront cost — but once you have this cleaned, well-formed, and understandable dataset, the potential for answering multiple questions on the data greatly increases.
In this post, we walk through investigating, retrieving, and cleaning a real world data set. In honor of World Migratory Bird Day, we'll use migratory bird data. We will also describe the cost benefits and necessary tools involved in building your own data sets. With these basics, you will be able to go into the wild and find your own data sets to use.
Researching available migratory bird data sets
You should start every investigation with one key question: what are we trying to learn? Armed with that question, it's easier to find the apprioriate data sets. For our example, we want to learn about the migration patterns of birds in North America. To understand these patterns, we need to find accurate migration data over several years.
Obscure data like this is tough to find. There might be hobbyists who host their own data on personal websites, forums, or other channels, but amateur data sets are commonly frought with errors and contain missing data. Instead, we should look for more professional data sets that are hosted on either government or university websites.
Googling the keywords "bird migration," "database," and "america," we found a couple websites that had information on bird migrations. The first, eBird, contains bird migration data hosted by Cornell labs. The second is from the US Fish and Wildlife Services (USFWS) website, which uses partnerships and citizen research data to create their reports. We wanted to use data sets from both services so that we could cross check the data and determine inconsistencies.
Let's start with the eBirds data set.
Navigating to the downloads page, you'll be asked to create an account with the Cornell Research Lab. Once logged in, you're able to get to the downloads page. But before you can access the full data set, you'll need to fill out a form describing how you intend to use the data. We successfully filled out the form and waited a few days, before gaining full access to the data set. Takes time, but not too difficult.
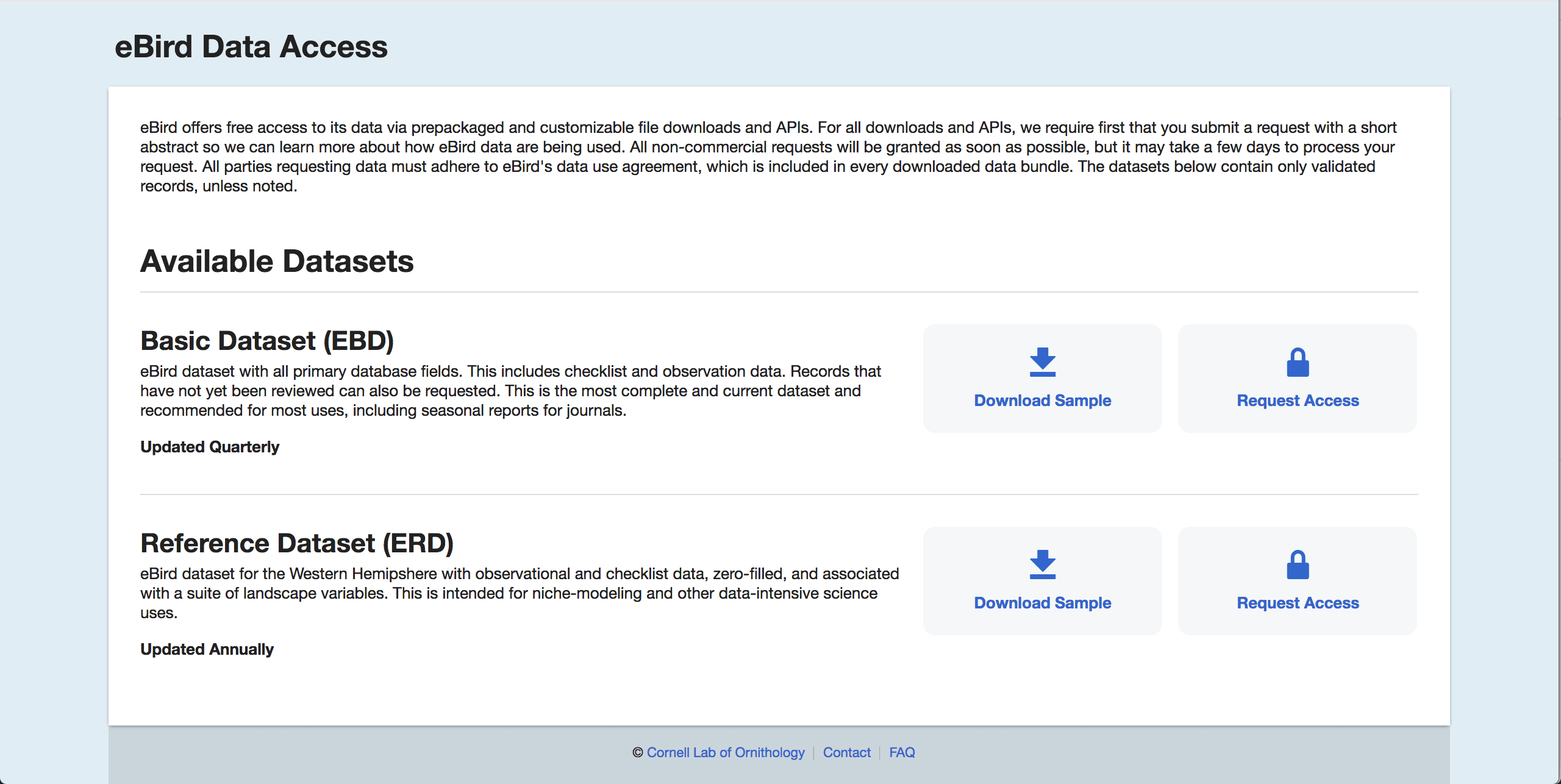
Next, let's look at USFWS. At first glance, this site seems much easier to work with than the eBirds portal. There's a clear link that guides us to a full database list of different birds, geographical data points, and migration flyway paths. These well ordered and categorized data sets would have been extremely helpful and easy to analyze, if they had working links.

Unfortunately, retrieving the data from the USFWS portal is not easy. There are multiple dead links, poorly formatted data sets, and HTML buttons that don't work as advertised. While these issues are mostly poor interface design, all the HTTP endpoints seem to work, and with a little bit of Python code, we'll find that we're able to get the data we need.
Finding the data
Due to the vast amount of links the USFWS site provides, it's difficult just to find possible data set endpoints. When we dive in, the first successful data set we find is by following links to the USFWS published databook of waterfowl flyway patterns. The databook supposedly contains all the information we need for our investigation, but there is a major flaw: it is stored as a PDF. It's difficult to parse PDFs due to their inconsistent structure, so this should be a last resort.
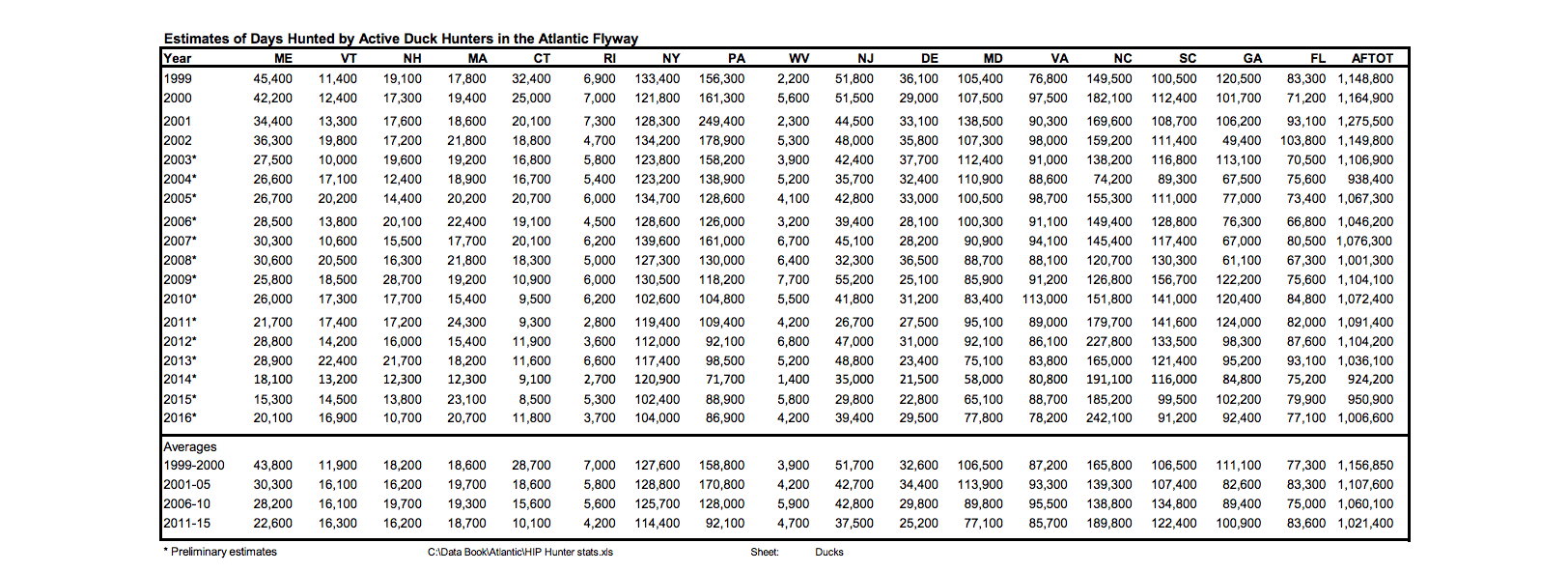
Committed to the data set of waterfowls flyway patterns, we decide to follow another link path to USFWS reports. These reports are described as survey data about the flyway pattern of North American waterfowls from 1995; exactly what we were looking for. Once we click on the link to the reports, we are greeted with a terms of service and disclaimer blocker. After accepting it, there is a report generation form that gives researchers the ability to restrict data on the types of waterfowls, state, or "plot" that the fowl was spotted in.
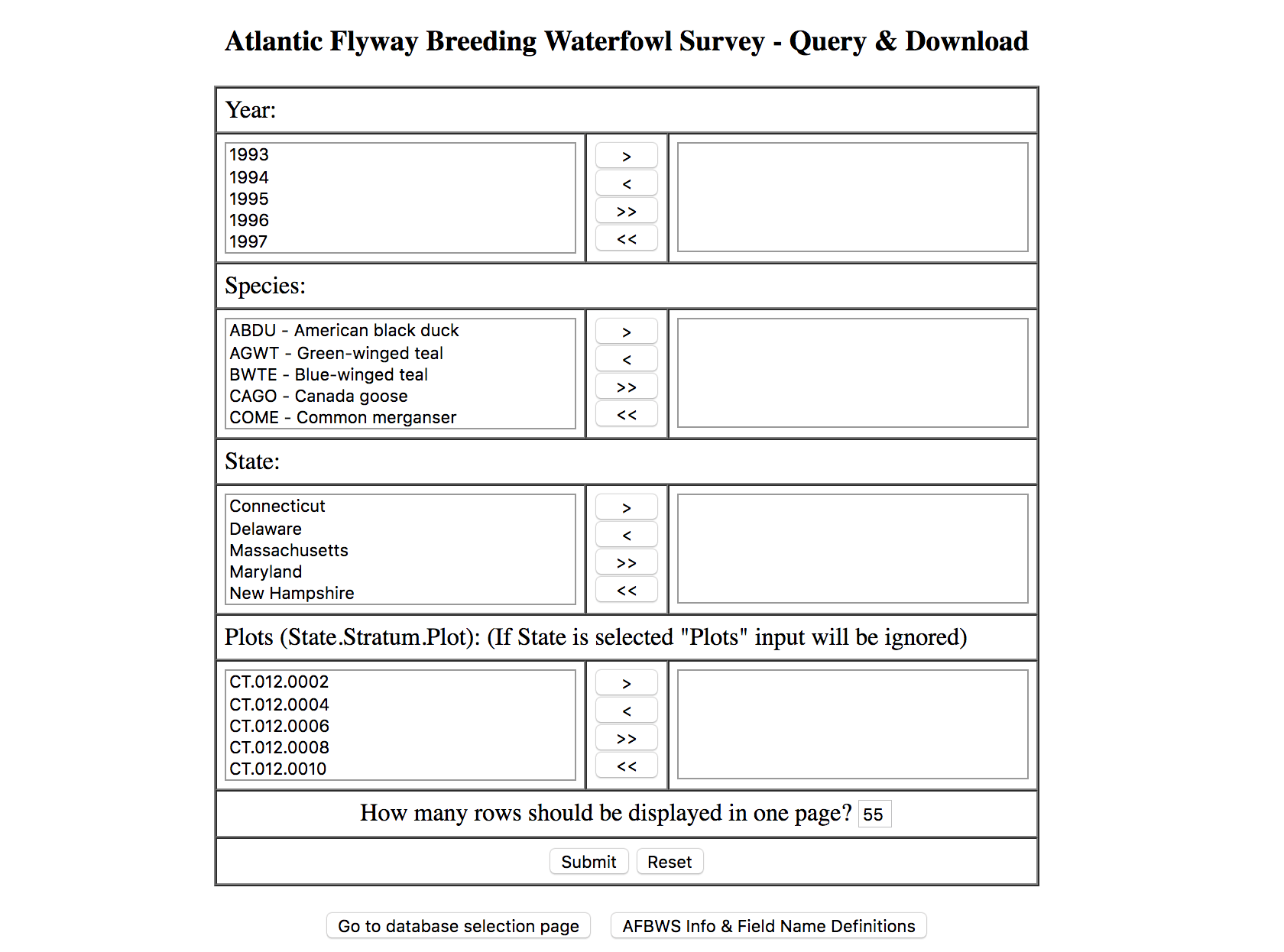
Instead of restricting the data, we select on every value in the form and pressed submit. Finally, we are presented with a paginated table containing a sample of the full data set.
Scrolling to the bottom of the page there is also a download button for the entire data set! Unfortunately, pressing the button redirects us to a 403 Unauthorized page.
A little frustrated, but not without hope, we look for a solution. First, we retrace the steps we took to retrieve the data. The steps were to navigate to the downloads page, submit a simple form submission, parse an HTML formatted table, and run the parser on each page of data. Thinking about the steps, we realize they can easily be automated using a Python web scraping script!
Downloading the data
There are two main packages that we'll use to scrape the data.
- requests (for making the HTTP requests)
- beautifulsoup (for parsing HTML)
Well start with requests to perform the HTTP requests, form submittion, and download the HTML table files. Using Chrome Dev Tools, we'll navigate to the survey form page and with all the values in the forms filled in, press the submit button, and inspect the headers of the request.
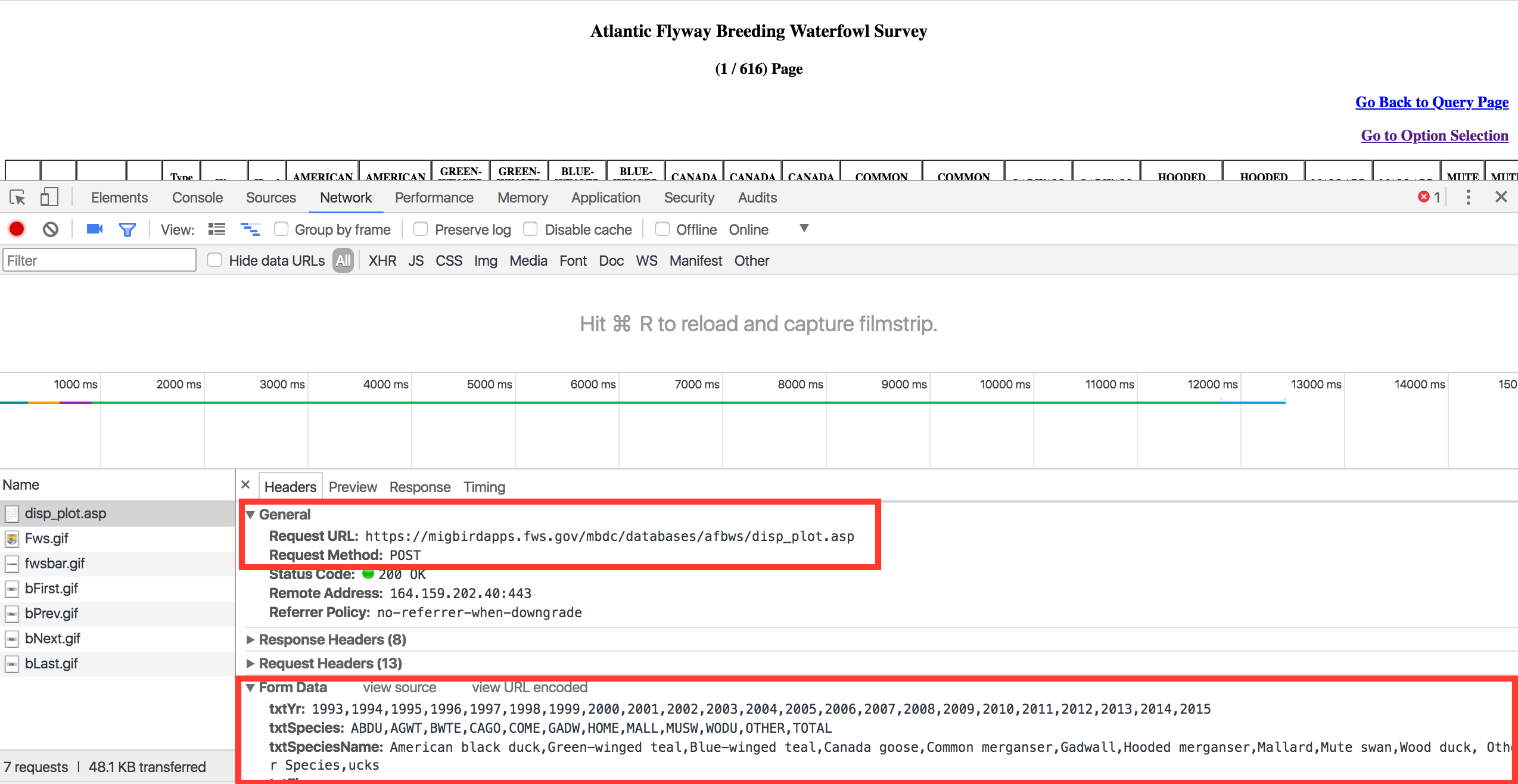
We have highlighted the request type, URL, and the fields of the form data, respectively. From the screenshot, to generate the report we'll need to send a POST request to the URL using the given form data. To make things easier, we'll use the form data source code that is URL encoded. Then, we'll use the following code snippet to issue our POST request using requests.post() and the x-www-form-urlencoded content type header.
import requests
import requests
form_data = {
"txtYr": "1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015",
"txtSpecies": "ABDU,AGWT,BWTE,CAGO,COME,GADW,HOME,MALL,MUSW,WODU,OTHER,TOTAL",
"txtSpeciesName": (
"American black duck,Green-winged teal,Blue-winged teal,Canada goose,"
"Common merganser,Gadwall,Hooded merganser,Mallard,Mute swan,Wood duck,Other Species,Ducks"
),
"txtFlyway": "",
"txtState": "CT,DE,MA,MD,NH,NJ,NY,PA,RI,VA,VT",
"txtPlots": "",
"db": 'request("db")',
"txtCurrPage": "1",
"LoadPage": "query",
"txtRows": "55",
"submit1": "Submit"
}
response = requests.post(
"https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp",
data=form_data,
headers={"Content-Type": "application/x-www-form-urlencoded"}
)
This feels correct, but we're missing a critical part before we can issue the request. If we were to run the snippet, our request would be blocked by the required terms and conditions page instead of returning the report. Recall that the USFWS requires you to accept their disclaimer before you can use the data.
To fix this, notice that when accepting the terms and conditions your browsing session has full access to the rest of the reports. To recreate this behavior in the Python script, we'll need to instantiate a persistant requests.Session object. Using the requests.Session object, we'll accept the disclaimer by navigating to the "accept" page, and with the authenticated session we'll submit the form data.
All together, it looks like:
import requests
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = {
"txtYr": "1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015",
"txtSpecies": "ABDU,AGWT,BWTE,CAGO,COME,GADW,HOME,MALL,MUSW,WODU,OTHER,TOTAL",
"txtSpeciesName": (
"American black duck,Green-winged teal,Blue-winged teal,Canada goose,"
"Common merganser,Gadwall,Hooded merganser,Mallard,Mute swan,Wood duck,Other Species,Ducks"
),
"txtFlyway": "",
"txtState": "CT,DE,MA,MD,NH,NJ,NY,PA,RI,VA,VT",
"txtPlots": "",
"db": 'request("db")',
"txtCurrPage": "1",
"LoadPage": "query",
"txtRows": "55",
"submit1": "Submit"
}
response = se.post(
"https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp",
data=form_data,
headers={"Content-Type": "application/x-www-form-urlencoded"}
)
Success! We got the report table as required, but notice that there are 616 pages of data to parse. One way we can reduce the amount is by choosing a higher number of textRows form value. Let's change it to the max value which is 99 rows per table.
import requests
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = {
"txtYr": "1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015",
"txtSpecies": "ABDU,AGWT,BWTE,CAGO,COME,GADW,HOME,MALL,MUSW,WODU,OTHER,TOTAL",
"txtSpeciesName": (
"American black duck,Green-winged teal,Blue-winged teal,Canada goose,"
"Common merganser,Gadwall,Hooded merganser,Mallard,Mute swan,Wood duck,Other Species,Ducks"
),
"txtFlyway": "",
"txtState": "CT,DE,MA,MD,NH,NJ,NY,PA,RI,VA,VT",
"txtPlots": "",
"db": 'request("db")',
"txtCurrPage": "1",
"LoadPage": "query",
"txtRows": "99", # Updated from 55 to 99.
"submit1": "Submit"
}
response = se.post(
"https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp",
data=form_data,
headers={"Content-Type": "application/x-www-form-urlencoded"}
)
Now that we have the maximum amount of rows per page, we can move to the HTML parsing step.
Parsing the data
To parse the data, we need to create a BeautifulSoup object with the report response HTML string. Under the hood, the BeautifulSoup object is converting the HTML string into a tree-like data structure. This makes it easy to query for tags such as the <table> tag which contains the report data.
import requests
from bs4 import BeautifulSoup
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = {
"txtYr": "1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015",
"txtSpecies": "ABDU,AGWT,BWTE,CAGO,COME,GADW,HOME,MALL,MUSW,WODU,OTHER,TOTAL",
"txtSpeciesName": (
"American black duck,Green-winged teal,Blue-winged teal,Canada goose,"
"Common merganser,Gadwall,Hooded merganser,Mallard,Mute swan,Wood duck,Other Species,Ducks"
),
"txtFlyway": "",
"txtState": "CT,DE,MA,MD,NH,NJ,NY,PA,RI,VA,VT",
"txtPlots": "",
"db": 'request("db")',
"txtCurrPage": "1",
"LoadPage": "query",
"txtRows": "99",
"submit1": "Submit"
}
response = se.post(
"https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp",
data=form_data,
headers={"Content-Type": "application/x-www-form-urlencoded"}
)
soup = BeautifulSoup(response.text, "lxml")
With our parsable object, we can now search the HTML document for the <table> tag. In the document, the report data is in the second <table>, so we'll use the .findAll() method and select the second item in the list. Then, we'll filter for all the rows of the table, <tr>, and set them to a rows variable.
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')Next we want to extract the header row and clean up the values. For reference, an HTML table's header row is formatted using the <th> tag and the data rows are formatted with <td>. To get the tag values, we need to call the .string attribute of a BeautifulSoup tag. We'll grab the header values from the first row of the table.
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string for col in rows[0].findAll('th') if col.string]With the header extracted, it's time to grab the data from the rows. We'll iterate through the reminaing rows of the table, find all the <td> tags, and assign it to a new row. Furthermore, we'll combine the header and rows, then clean up some of the whitespace surrounding values to make it easier to parse.
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string.strip() for col in rows[0].findAll('th') if col.string]
modified_rows = []
for row in rows[1:]:
modified_row = [col.string.strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rowsWith a some more unicode cleaning using unicodedata.normalize(), we should get the following output:
import unicodedata
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string.strip() for col in rows[0].findAll('th') if col.string]
modified_rows = []
for row in rows[1:]:
modified_row = [unicodedata.normalize('NFKD', col.string).strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rows
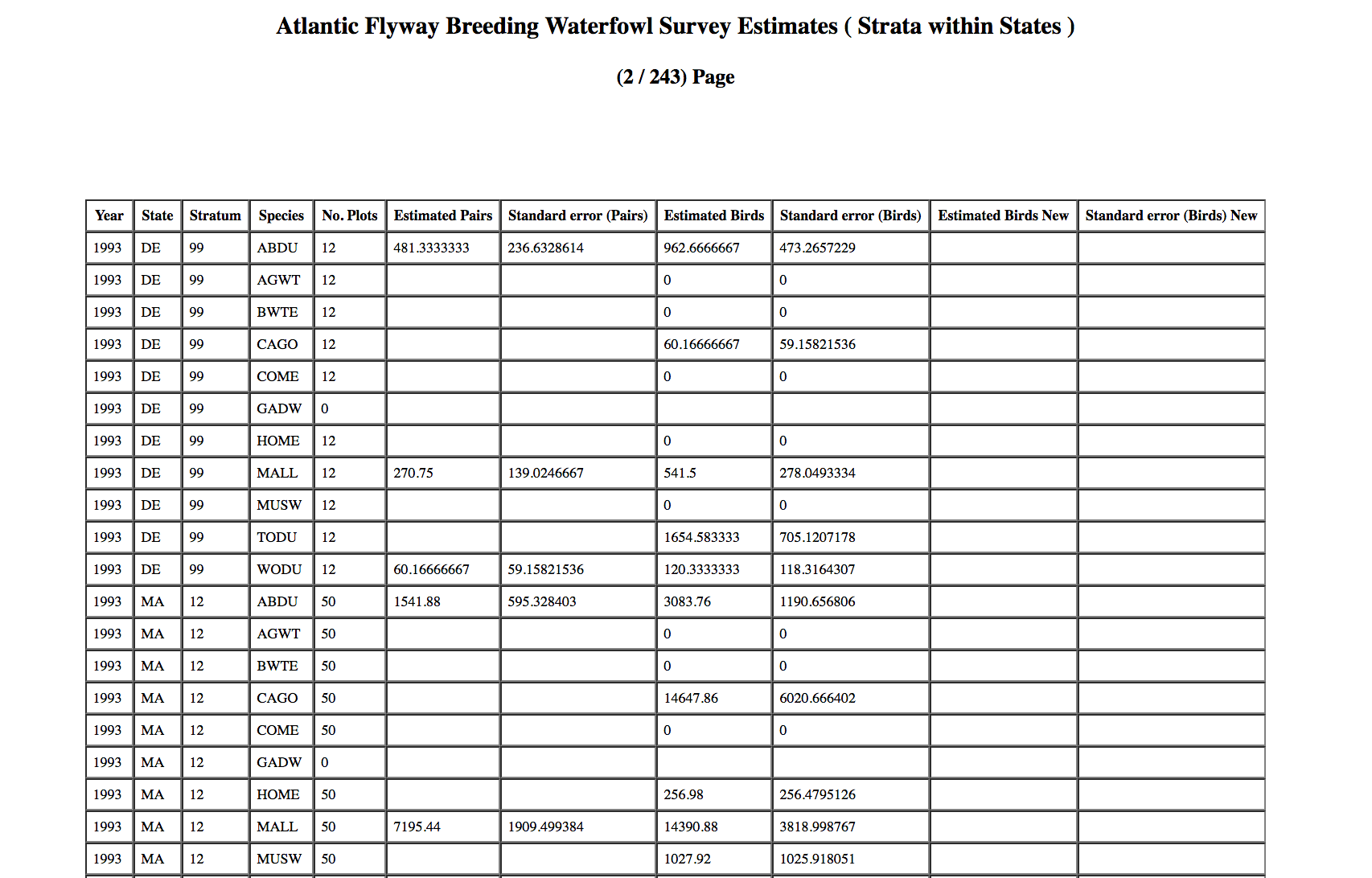
print(table[:3]) >> [['Year', 'State', 'Stratum', 'Plot', 'Type of check', 'Wet Habitat', 'AMERICAN BLACK DUCK TIP', 'AMERICAN BLACK DUCK TIB', 'GREEN-WINGED TEAL TIP', 'GREEN-WINGED TEAL TIB', 'BLUE-WINGED TEAL TIP', 'BLUE-WINGED TEAL TIB', 'CANADA GOOSE TIP', 'CANADA GOOSE TIB OLD', 'CANADA GOOSE TIB NEW', 'COMMON MERGANSER TIP', 'COMMON MERGANSER TIB', 'GADWALL TIP', 'GADWALL TIB', 'HOODED MERGANSER TIP', 'HOODED MERGANSER TIB', 'MALLARD TIP', 'MALLARD TIB', 'MUTE SWAN TIP', 'MUTE SWAN TIB', 'WOOD DUCK TIP', 'WOOD DUCK TIB', 'OTHER SPECIES TOTAL', 'TOTDUCKS'], ['1993', 'CT', '012', '0002', '2', 'Y', 'N', '0', '0', '', '0', '', '0', '', '0', '', '', '0', '', '', '', '0', '0', '0', '', '0', '1', '2', '', '2'], ['1993', 'CT', '012', '0004', '1', 'Y', 'Y', '0', '0', '', '0', '', '0', '', '2', '', '', '0', '', '', '', '0', '0', '0', '', '0', '0', '0', '', '0']]With our table parsed, we can iterate through each page of the data set and combine the values together.
Putting it all together
There are three pieces left to implement before the full data set is built:
- Find the total number of pages of data to paginate through.
- Create a
form_datatemplate to dynamically modify the form data. - Loop through the pages and combine all the rows.
We'll start with the first point. Peeking at the HTML for the report page, we see that the total number of pages is in the title. One way we could extract the total from the title would be to isolate the number from the title, and then cast it to an integer. This would work, but relying on a title string is too brittle of a solution.
Instead, if we take a closer look at the form data, there is a hidden input field that does the work for us. At the bottom of the markup, there's an input value with the name=txtLastPage. Using BeautifulSoup, we only have to search for an input tag and the matching name, and cast the value to an integer. Here's one potential implementation.
from bs4 import BeautifulSoup
import requests
import unicodedata
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = {
"txtYr": "1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015",
"txtSpecies": "ABDU,AGWT,BWTE,CAGO,COME,GADW,HOME,MALL,MUSW,WODU,OTHER,TOTAL",
"txtSpeciesName": (
"American black duck,Green-winged teal,Blue-winged teal,Canada goose,"
"Common merganser,Gadwall,Hooded merganser,Mallard,Mute swan,Wood duck,Other Species,Ducks"
),
"txtFlyway": "",
"txtState": "CT,DE,MA,MD,NH,NJ,NY,PA,RI,VA,VT",
"txtPlots": "",
"db": 'request("db")',
"txtCurrPage": "1",
"LoadPage": "query",
"txtRows": "99",
"submit1": "Submit"
}
response = se.post(
"https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp",
data=form_data,
headers={"Content-Type": "application/x-www-form-urlencoded"}
)
soup = BeautifulSoup(response.text, "lxml")
total_pages = soup.find('input', {'name': 'txtLastPage'}).get('value')
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string.strip() for col in rows[0].findAll('th') if col.string]
modified_rows = []
for row in rows[1:]:
modified_row = [unicodedata.normalize('NFKD', col.string).strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rowsNow, we want to add in the template and the pagination together. First, we'll create a string template of the form_data that uses string formatting to submit dynamic form data. In our case we want to dynamically modify the current page value. Next, we'll find use the total amount of pages value and keeep looping until we have exhuasted the data set. With a little bit of cleanup, we get the following final implementation:
from bs4 import BeautifulSoup
import requests
import unicodedata
# Set a url constant.
REPORT_URL = "https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp"
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data_template = {
"txtYr": "1993,1994,1995,1996,1997,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015",
"txtSpecies": "ABDU,AGWT,BWTE,CAGO,COME,GADW,HOME,MALL,MUSW,WODU,OTHER,TOTAL",
"txtSpeciesName": (
"American black duck,Green-winged teal,Blue-winged teal,Canada goose,"
"Common merganser,Gadwall,Hooded merganser,Mallard,Mute swan,Wood duck,Other Species,Ducks"
),
"txtFlyway": "",
"txtState": "CT,DE,MA,MD,NH,NJ,NY,PA,RI,VA,VT",
"txtPlots": "",
"db": 'request("db")',
"txtCurrPage": "{}", # Add format template.
"LoadPage": "query",
"txtRows": "99",
"submit1": "Submit"
}
# Find total pages.
re = se.post(REPORT_URL, data={**form_data_template, "txtCurrPage": "1"}, headers={'Content-Type': 'application/x-www-form-urlencoded'})
soup = BeautifulSoup(re.text, "lxml")
total_pages = int(soup.find('input', {'name': 'txtLastPage'}).get('value', 1))
# Take out the header and modified rows out of the loop.
header = []
modified_rows = []
for current_page in range(1, total_pages + 1):
re = se.post(REPORT_URL, data={**form_data_template, "txtCurrPage": str(current_page)}, headers={'Content-Type': 'application/x-www-form-urlencoded'})
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = header or [col.string.strip() for col in rows[0].findAll('th') if col.string]
for row in rows[1:]:
modified_row = [unicodedata.normalize('NFKD', col.string).strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rows
Awesome! We've extracted the full dataset and it's also in a Python readable state. From here, we can add some more data cleaning, save the table to a file, and perform some analysis against the data.
Conclusion
Using some basic Python web scraping we were able to:
- Use sessions to access authenticated only content.
- Parse HTML table data and map the data it to a Python list of lists.
- Automate data set scraping across multiple HTML pages.
From this one example, we were able to demonstrate Python's web scraping abilities for data investigation, cleaning, and retrieval. As mentioned in the beginning of the post, you'll need to seek out your own data sets when asking the more difficult problems in data science. There is a vast amount of data available all over the web. Once you have the tools and experience to find and gather this data, you'll be highly rewarded in your analysis.
If you wanted to update the example, here are some things to add on:
- Create a CSV file with the table data.
- Use coroutines or threads to speed up the blocking of network calls.
- Loop through the pages without having to request the first page twice.
- Add error handling to improve the robustness of the code.
Update: As of publication, it is now possible to download the ASCII CSV file containing all the data of the USFWS' waterfowl flyway paths. Nonetheless, this example provides a good introduction to web scraping, data retrieval, and the difficulty of maintaining these types of scripts in the long run.