Working with DataFrames in PySpark
In our previous tutorial, you learned about RDDs and saw how Spark's distributed processing makes big data analysis possible. You worked with transformations, actions, and experienced lazy evaluation across clusters of machines.
But as powerful as RDDs are, they require you to do a lot of manual work: parsing strings, managing data types, writing custom lambda functions for every operation, and building transformation logic line by line. When you're building data pipelines or working with structured datasets, you'll usually want a much more efficient and intuitive approach.
Spark DataFrames are the solution to this manual overhead. They provide a higher-level API that handles data parsing, type management, and common operations automatically. Think of them as pandas DataFrames designed for distributed computing. They let you explore and manipulate structured data using familiar operations like filtering, selecting, grouping, and aggregating, while Spark handles the optimization and execution details behind the scenes.
Unlike RDDs, DataFrames understand the schema of your data. They know column names, data types, and relationships, which means you can write cleaner, more expressive code, and Spark can optimize it automatically using its built-in Catalyst optimizer.
To demonstrate these concepts, we'll work with a real-world dataset from the 2010 U.S. Census containing demographic information by age group. This type of structured data processing represents exactly the kind of work where DataFrames excel: transforming raw data into insights with clean, readable code.
By the end of this tutorial, you'll be able to:
- Create DataFrames from JSON files and understand their structure
- Explore and transform columns using expressive DataFrame syntax
- Filter rows and compute powerful aggregations
- Chain operations to build complete data processing pipelines
- Convert DataFrames between PySpark and pandas for visualization
- Understand when DataFrames offer advantages over RDDs for structured data work
Let's see what makes DataFrames Spark's most powerful data abstraction for working with structured information.
Why DataFrames Matter for Data Engineers
DataFrames have become the preferred choice for most Spark applications, especially in production environments. Here's why they're so valuable.
Automatic Optimization with Catalyst
When you write DataFrame operations, Spark's Catalyst optimizer analyzes your code and creates an optimized execution plan. Unlike RDDs where you're responsible for performance optimization, DataFrames automatically apply techniques like:
- Predicate pushdown: Moving filters as early as possible in the processing pipeline
- Column pruning: Reading only the columns you actually need
- Join optimization: Choosing the most efficient join strategy based on data size and distribution
This means your DataFrame code often runs faster than equivalent RDD operations, even when the RDD code is well-optimized.
Schema Validation and Data Quality
DataFrames provide schema awareness, meaning they automatically detect and enforce the structure of your data, including column names, data types, and constraints. This brings several production advantages:
- Early error detection: Type mismatches and missing columns are caught at execution time
- Consistent data contracts: Your pipelines can rely on expected column names and types
- Better debugging: Schema information helps you understand data structure issues quickly
This is particularly valuable when building ETL pipelines that need to handle changing data sources or enforce data quality standards.
Familiar Pandas-like and SQL-like Operations
DataFrames provide an API that feels natural whether you're coming from pandas or SQL background:
# Pandas-style operations you might know:
# df[df['age'] > 21] # filtering
# df[['age', 'total']] # selecting columns
# df.groupby('age').count() # grouping
# Equivalent Spark DataFrame operations:
df.filter(df.age > 21) # filtering
df.select("age", "total") # selecting columns
df.groupBy("age").count() # groupingThis familiarity makes DataFrame code more readable and maintainable, especially for teams with mixed backgrounds.
Integration with the Broader Spark Ecosystem
DataFrames integrate naturally with other Spark components:
- Spark SQL: Write SQL queries directly against DataFrames
- MLlib: Machine learning algorithms work natively with DataFrame inputs
- Structured Streaming: Process real-time data using the same DataFrame API
While DataFrames offer compelling advantages, RDDs still have their place. When you need fine-grained control over data distribution, custom algorithms, or processing of unstructured data, RDDs provide the flexibility you need. But for structured data processing—which represents the majority of production workloads—DataFrames offer a more powerful and maintainable approach.
Exploring Raw Data First
Before we start loading data into DataFrames, let's take a look at what we're working with. Understanding your raw data structure is always a good first step in any data project.
We'll be using a dataset from the 2010 U.S. Census that contains population counts broken down by age and gender. You can download this dataset locally to follow along with the code.
Let's examine the raw JSON file structure first:
# Open and examine the raw file
with open('census_2010.json') as f:
for i in range(4):
print(f.readline(), end=""){"females": 1994141, "total": 4079669, "males": 2085528, "age": 0, "year": 2010}
{"females": 1997991, "total": 4085341, "males": 2087350, "age": 1, "year": 2010}
{"females": 2000746, "total": 4089295, "males": 2088549, "age": 2, "year": 2010}
{"females": 2002756, "total": 4092221, "males": 2089465, "age": 3, "year": 2010}
This gives us valuable insights into our data structure:
- Each line is a valid JSON object (not an array of objects)
- Every record has the same five fields:
females,total,males,age, andyear - All values appear to be integers
- The data represents individual age groups from the 2010 Census
With RDDs, you'd need to handle this parsing manually: reading each line, parsing the JSON, converting data types, and dealing with any inconsistencies. DataFrames will handle all of this automatically, but seeing the raw structure first helps us appreciate what's happening behind the scenes.
From JSON to DataFrames
Now let's see how much simpler the DataFrame approach is compared to manual parsing.
Setting Up and Loading Data
import os
import sys
from pyspark.sql import SparkSession
# Ensure PySpark uses the same Python interpreter
os.environ["PYSPARK_PYTHON"] = sys.executable
# Create SparkSession
spark = (SparkSession.builder
.appName("CensusDataAnalysis")
.master("local[*]")
.getOrCreate()
)
# Load JSON directly into a DataFrame
df = spark.read.json("census_2010.json")
# Preview the data
df.show(4)+---+-------+-------+-------+----+
|age|females| males| total|year|
+---+-------+-------+-------+----+
| 0|1994141|2085528|4079669|2010|
| 1|1997991|2087350|4085341|2010|
| 2|2000746|2088549|4089295|2010|
| 3|2002756|2089465|4092221|2010|
+---+-------+-------+-------+----+
only showing top 4 rowsThat's it! With just spark.read.json(), we've accomplished what would take dozens of lines of RDD code. Spark automatically:
- Parsed each JSON line
- Inferred column names from the JSON keys
- Determined appropriate data types for each column
- Created a structured DataFrame ready for analysis
The .show() method displays the data in a clean, tabular format that's much easier to read than raw JSON.
Understanding DataFrame Structure and Schema
One of DataFrame's biggest advantages is automatic schema detection. Think of a schema as a blueprint that tells Spark exactly what your data looks like. Just like how a blueprint helps architects understand a building's structure, a schema helps Spark understand your data's structure.
Exploring the Inferred Schema
Let's examine what Spark discovered about our census data:
# Display the inferred schema
df.printSchema()root
|-- age: long (nullable = true)
|-- females: long (nullable = true)
|-- males: long (nullable = true)
|-- total: long (nullable = true)
|-- year: long (nullable = true)This schema tells us several important things:
- All columns contain
longintegers (perfect for population counts) - All columns are
nullable = true(can contain missing values) - Column names match our JSON keys exactly
- Spark automatically chose appropriate data types
We can also inspect the schema programmatically:
# Get column names and data types for further inspection
column_names = df.columns
column_types = df.dtypes
print("Column names:", column_names)
print("Column types:", column_types)Column names: ['age', 'females', 'males', 'total', 'year']
Column types: [('age', 'bigint'), ('females', 'bigint'), ('males', 'bigint'), ('total', 'bigint'), ('year', 'bigint')]Why Schema Awareness Matters
This automatic schema detection provides immediate benefits:
- Performance: Spark can optimize operations because it knows data types in advance
- Error Prevention: Type mismatches are caught early rather than producing wrong results
- Code Clarity: You can reference columns by name rather than by position
- Documentation: The schema serves as living documentation of your data structure
Compare this to RDDs, where you'd need to maintain type information manually and handle schema validation yourself. DataFrames make this effortless while providing better performance and error checking.
Core DataFrame Operations
Now that we understand DataFrames and have our census data loaded, let's explore the core operations you'll use in most data processing workflows.
Selecting Columns
Column selection is one of the most fundamental DataFrame operations. The .select() method lets you focus on specific attributes:
# Select specific columns for analysis
age_gender_df = df.select("age", "males", "females")
age_gender_df.show(10)+---+-------+-------+
|age| males|females|
+---+-------+-------+
| 0|2085528|1994141|
| 1|2087350|1997991|
| 2|2088549|2000746|
| 3|2089465|2002756|
| 4|2090436|2004366|
| 5|2091803|2005925|
| 6|2093905|2007781|
| 7|2097080|2010281|
| 8|2101670|2013771|
| 9|2108014|2018603|
+---+-------+-------+
only showing top 10 rowsNotice that .select() returns a new DataFrame with only the specified columns. This is useful for:
- Reducing data size before executing expensive operations
- Preparing specific column sets for different analytical purposes
- Creating focused views of your data for team members
Creating New Columns
DataFrames excel at creating calculated fields. The .withColumn() method lets you add new columns based on existing data:
from pyspark.sql.functions import col
# Calculate female-to-male ratio
df_with_ratio = df.withColumn("female_male_ratio", col("females") / col("males"))
# Show the enhanced dataset
ratio_preview = df_with_ratio.select("age", "females", "males", "female_male_ratio")
ratio_preview.show(10)+---+-------+-------+------------------+
|age|females| males| female_male_ratio|
+---+-------+-------+------------------+
| 0|1994141|2085528|0.9561804013180355|
| 1|1997991|2087350|0.9571902172611205|
| 2|2000746|2088549|0.9579598084603234|
| 3|2002756|2089465|0.9585018174508786|
| 4|2004366|2090436|0.9588267710659403|
| 5|2005925|2091803|0.9589454647497876|
| 6|2007781|2093905|0.9588691941611487|
| 7|2010281|2097080|0.9586095904781887|
| 8|2013771|2101670| 0.958176592899932|
| 9|2018603|2108014|0.9575851963032503|
+---+-------+-------+------------------+
only showing top 10 rowsThe data reveals that the female-to-male ratio is consistently below 1.0 for younger age groups, meaning there are slightly more males than females born each year. This is a well-documented demographic phenomenon.
Filtering Rows
DataFrame filters are both more readable and better optimized than RDD equivalents. Let's find age groups where males outnumber females:
# Filter rows where female-to-male ratio is less than 1
male_dominated_df = df_with_ratio.filter(col("female_male_ratio") < 1)
male_dominated_preview = male_dominated_df.select("age", "females", "males", "female_male_ratio")
male_dominated_preview.show(5)+---+-------+-------+------------------+
|age|females| males| female_male_ratio|
+---+-------+-------+------------------+
| 0|1994141|2085528|0.9561804013180355|
| 1|1997991|2087350|0.9571902172611205|
| 2|2000746|2088549|0.9579598084603234|
| 3|2002756|2089465|0.9585018174508786|
| 4|2004366|2090436|0.9588267710659403|
+---+-------+-------+------------------+
only showing top 5 rowsThese filtering patterns are common in data processing workflows where you need to isolate specific subsets of data based on business logic or analytical requirements.
Aggregations for Summary Analysis
Aggregation operations are where DataFrames really shine compared to RDDs. They provide SQL-like grouping and summarization with automatic optimization.
Basic Aggregations
Let's start with simple aggregations across the entire dataset:
from pyspark.sql.functions import sum
# Calculate total population by year (since all data is from 2010)
total_by_year = df.groupBy("year").agg(sum("total").alias("total_population"))
total_by_year.show()+----+----------------+
|year|total_population|
+----+----------------+
|2010| 312247116|
+----+----------------+This gives us the total U.S. population for 2010 (~312 million), which matches historical Census figures and validates our dataset's accuracy.
More Complex Aggregations
We can create more sophisticated aggregations by grouping data into categories. Let's explore different age ranges:
from pyspark.sql.functions import when, avg, count
# Create age categories and analyze patterns
categorized_df = df.withColumn(
"age_category",
when(col("age") < 18, "Child")
.when(col("age") < 65, "Adult")
.otherwise("Senior")
)
# Group by category and calculate multiple statistics
category_stats = categorized_df.groupBy("age_category").agg(
sum("total").alias("total_population"),
avg("total").alias("avg_per_age_group"),
count("age").alias("age_groups_count")
)
category_stats.show()+------------+---------------+------------------+----------------+
|age_category|total_population|avg_per_age_group|age_groups_count|
+------------+---------------+------------------+----------------+
| Child| 74181467| 4121192.6111111 | 18|
| Adult| 201292894| 4281124.9574468 | 47|
| Senior| 36996966| 1027693.5 | 36|
+------------+---------------+------------------+----------------+This breakdown reveals important demographic insights:
- Adults (18-64) represent the largest population segment (~201M)
- Children (0-17) have the highest average per age group, showing higher birth rates in recent years
- Seniors (65+) have much smaller age groups on average, reflecting historical demographics
Chaining Operations for Complex Analysis
One of DataFrame's greatest strengths is the ability to chain operations into readable, maintainable data processing pipelines.
Building Analytical Pipelines
Let's build a complete analytical workflow that transforms our raw census data into insights:
# Chain multiple operations together for child demographics analysis
filtered_summary = (
df.withColumn("female_male_ratio", col("females") / col("males"))
.withColumn("gender_gap", col("females") - col("males"))
.filter(col("age") < 18)
.select("age", "female_male_ratio", "gender_gap")
)
filtered_summary.show(10)+---+------------------+----------+
|age| female_male_ratio|gender_gap|
+---+------------------+----------+
| 0|0.9561804013180355| -91387|
| 1|0.9571902172611205| -89359|
| 2|0.9579598084603234| -87803|
| 3|0.9585018174508786| -86709|
| 4|0.9588267710659403| -86070|
| 5|0.9589454647497876| -85878|
| 6|0.9588691941611487| -86124|
| 7|0.9586095904781887| -86799|
| 8| 0.958176592899932| -87899|
| 9|0.9575851963032503| -89411|
+---+------------------+----------+
only showing top 10 rowsThis single pipeline performs multiple operations:
- Data enrichment: Calculates gender ratios and gaps
- Quality filtering: Focuses on childhood age groups (under 18)
- Column selection: Returns only the metrics we need for analysis
The results show that across all childhood age groups, there are consistently more males than females (negative gender gap), with the pattern being remarkably consistent across ages.
Performance Benefits of DataFrame Chaining
This chained approach offers several advantages over equivalent RDD processing:
Automatic Optimization: Spark's Catalyst optimizer can combine operations, minimize data scanning, and generate efficient execution plans for the entire pipeline.
Readable Code: The pipeline reads like a description of the analytical process, making it easier for teams to understand and maintain.
Memory Efficiency: Intermediate DataFrames aren't materialized unless explicitly cached, reducing memory pressure.
Compare this to an RDD approach, which would require multiple separate transformations, manual optimization, and much more complex code to achieve the same result.
PySpark DataFrames vs Pandas DataFrames
Now that you've worked with PySpark DataFrames, you might be wondering how they relate to the pandas DataFrames you may already know. While they share many concepts and even some syntax, they're designed for very different use cases.
Key Similarities
Both PySpark and pandas DataFrames share:
- Tabular Structure: Both organize data in rows and columns with named columns
- Similar Operations: Both support filtering, grouping, selecting, and aggregating data
- Familiar Syntax: Many operations use similar method names like
.select(),.filter(), and.groupBy()
Let’s compare their syntax for a common select and filter operation:
# PySpark
pyspark_result = df.select("age", "total").filter(col("age") > 21)
# Pandas
df_pandas = df.toPandas() # Convert PySpark df to pandas
pandas_result = df_pandas[df_pandas["age"] > 21][["age", "total"]]
print("PySpark Result:")
{pyspark_result.show(5)}
print(f"Pandas Result: \n{pandas_result[:5]}")PySpark Result:
+---+-------+
|age| total|
+---+-------+
| 22|4362678|
| 23|4351092|
| 24|4344694|
| 25|4333645|
| 26|4322880|
+---+-------+
only showing top 5 rows
Pandas Result:
age total
22 22 4362678
23 23 4351092
24 24 4344694
25 25 4333645
26 26 4322880Key Differences
However, there are important differences:
- Scale: pandas DataFrames run on a single machine and are limited by available memory, while PySpark DataFrames can process terabytes of data across multiple machines.
- Execution: pandas operations execute immediately, while PySpark uses lazy evaluation and only executes when you call an action.
- Data Location: pandas loads all data into memory, while PySpark can work with data stored across distributed systems.
When to Use Each
Use PySpark DataFrames when:
- Working with large datasets (>5GB)
- Data is stored in distributed systems (HDFS, S3, etc.)
- You need to scale processing across multiple machines
- Building production data pipelines
Use pandas DataFrames when:
- Working with smaller datasets (<5GB)
- Doing exploratory data analysis
- Creating visualizations
- Working on a single machine
Working Together
The real power comes from using both together. PySpark DataFrames handle the heavy lifting of processing large datasets, then you can convert results to pandas for visualization and final analysis.
Visualizing DataFrame Results
Due to PySpark's distributed nature, you can't directly create visualizations from PySpark DataFrames. The data might be spread across multiple machines, and visualization libraries like matplotlib expect data to be available locally. The solution is to convert your PySpark DataFrame to a pandas DataFrame first.
Converting PySpark DataFrames to Pandas
Let's create some visualizations of our census analysis. First, we'll prepare aggregated data and convert it to pandas:
# Create age group summaries (smaller dataset suitable for visualization)
age_summary = (df.withColumn("female_male_ratio", col("females") / col("males"))
.select("age", "total", "female_male_ratio")
.filter(col("age") <= 60)
)
# Convert to pandas DataFrame
age_summary_pandas = age_summary.toPandas()
print("Converted to pandas:")
print(f"Type: {type(age_summary_pandas)}")
print(f"Shape: {age_summary_pandas.shape}")
print(age_summary_pandas.head())Converted to pandas:
Type: <class 'pandas.core.frame.DataFrame'>
Shape: (61, 3)
age total female_male_ratio
0 0 4079669 0.956180
1 1 4085341 0.957190
2 2 4089295 0.957960
3 3 4092221 0.958502
4 4 4094802 0.958827Creating Visualizations
Now we can create visualizations using matplotlib:
import matplotlib.pyplot as plt
# Create visualizations
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Plot 1: Population by age
ax1.plot(age_summary_pandas['age'], age_summary_pandas['total'], marker='o')
ax1.set_title('Population by Age (Ages 0-60)')
ax1.set_xlabel('Age')
ax1.set_ylabel('Total Population')
ax1.grid(True)
# Plot 2: Female-to-Male Ratio by age
ax2.plot(age_summary_pandas['age'], age_summary_pandas['female_male_ratio'],
marker='s', color='red')
ax2.axhline(y=1.0, color='black', linestyle='--', alpha=0.7, label='Equal ratio')
ax2.set_title('Female-to-Male Ratio by Age')
ax2.set_xlabel('Age')
ax2.set_ylabel('Female-to-Male Ratio')
ax2.legend()
ax2.grid(True)
plt.tight_layout()
plt.show()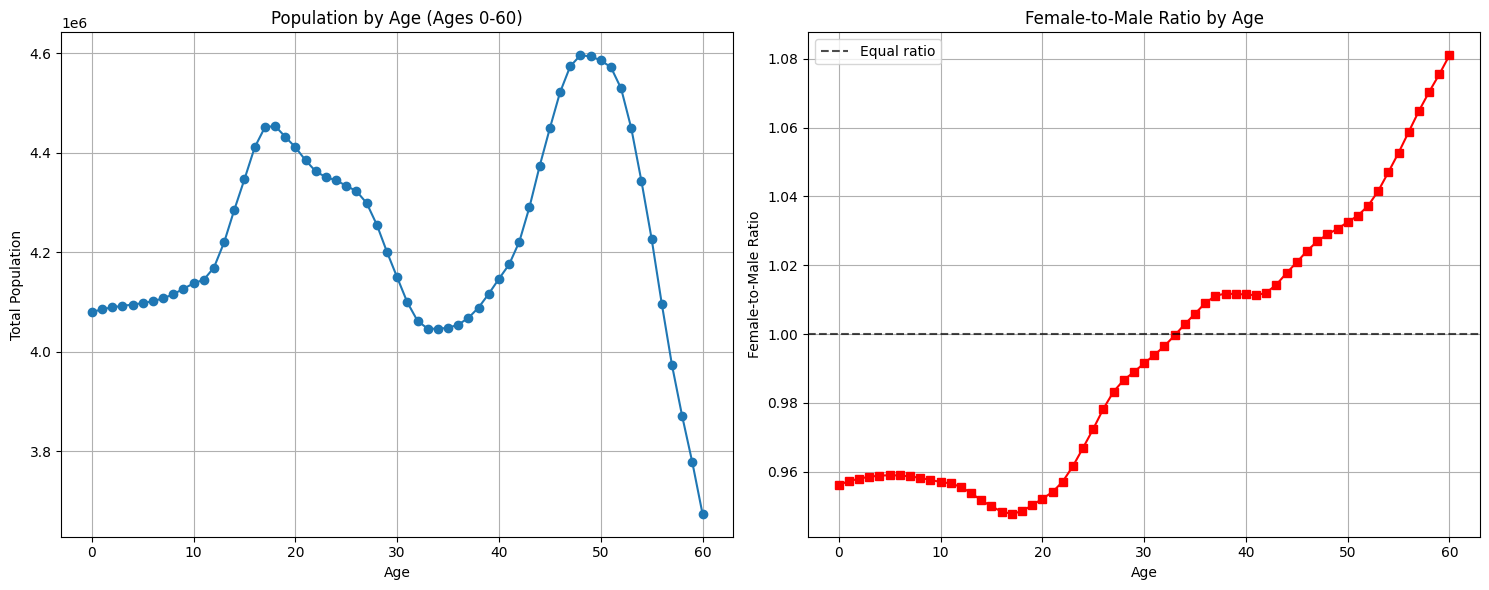
These visualizations reveal demographic patterns that would be difficult to spot in raw numbers:
- Two distinct population peaks: One around ages 17-18 and another larger peak around ages 47-50, likely reflecting baby boom generations
- Birth ratio patterns: More males are born than females (ratio below 1.0 for young ages), which is a well-documented biological phenomenon
- Aging demographics: The female-to-male ratio crosses 1.0 around age 34 and continues rising, reflecting longer female life expectancy
- Generation effects: The dramatic population drop after age 50 and the valley around ages 30-35 reveal distinct generational cohorts in the 2010 census data
Important Considerations for Conversion
When converting PySpark DataFrames to pandas, keep these points in mind:
-
Size Limitations: pandas DataFrames must fit in memory on a single machine. Always filter or aggregate your PySpark DataFrame first to reduce size.
-
Use Sampling: For very large datasets, consider sampling before conversion:
# Sample of data before converting sample_df = large_df.sample(fraction=0.1) sample_pandas = sample_df.toPandas() -
Aggregate First: Create summaries in PySpark, then convert the smaller result:
# Aggregate in PySpark, then convert summary = df.groupBy("category").agg(sum("value").alias("total")) summary_pandas = summary.toPandas() # Much smaller than original
This workflow—process big data with PySpark, then convert summaries to pandas for visualization—represents a common and powerful pattern in data analysis.
DataFrames vs RDDs: Choosing the Right Tool
After working with both RDDs and DataFrames, you have a practical foundation for choosing the right tool. Here's a decision framework to help you weigh your options:
Choose DataFrames When:
- Working with structured data: If your data has a clear schema with named columns and consistent types, DataFrames provide significant advantages in readability and performance.
- Building ETL pipelines: DataFrames excel at the extract, transform, and load operations common in data engineering workflows. Their SQL-like operations and automatic optimization make complex transformations more maintainable.
- Team collaboration: DataFrame operations are more accessible to team members with SQL backgrounds, and the structured nature makes code reviews easier.
- Performance matters: For most structured data operations, DataFrames will outperform equivalent RDD code due to Catalyst optimization.
Choose RDDs When:
- Processing unstructured data: When working with raw text, binary data, or complex nested structures that don't fit the tabular model.
- Implementing custom algorithms: If you need fine-grained control over data distribution, partitioning, or custom transformation logic.
- Working with key-value pairs: Some RDD operations like
reduceByKey()andaggregateByKey()provide more direct control over grouped operations. - Maximum flexibility: When you need to implement operations that don't map well to DataFrame's SQL-like paradigm.
A Practical Example
Consider processing web server logs. You might start with RDDs to parse raw log lines:
# RDD approach for initial parsing of unstructured text
log_rdd = spark.sparkContext.textFile("server.log")
parsed_rdd = log_rdd.map(parse_log_line).filter(lambda x: x is not None)But once you have structured data, switch to DataFrames for analysis:
# Convert to DataFrame for structured analysis
log_schema = ["timestamp", "ip", "method", "url", "status", "size"]
log_df = spark.createDataFrame(parsed_rdd, log_schema)
# Use DataFrame operations for analysis
error_summary = (log_df
.filter(col("status") >= 400)
.groupBy("status", "url")
.count()
.orderBy("count", ascending=False)
)This hybrid approach uses the strengths of both abstractions: RDD flexibility for parsing and DataFrame optimization for analysis.
Next Steps and Resources
You've now learned Spark DataFrames and understand how they bring structure, performance, and expressiveness to distributed data processing. You've seen how they differ from both RDDs and pandas DataFrames, and you understand when to use each tool.
Throughout this tutorial, you learned:
- DataFrame fundamentals: How schema awareness and automatic optimization make structured data processing more efficient
- Core operations: Selecting, filtering, transforming, and aggregating data using clean, readable syntax
- Pipeline building: Chaining operations to create maintainable data processing workflows
- Integration with pandas: Converting between PySpark and pandas DataFrames for visualization
- Tool selection: A practical framework for choosing between DataFrames and RDDs
The DataFrame concepts you've learned here form the foundation for most modern Spark applications. Whether you're building ETL pipelines, preparing data for machine learning, or creating analytical reports, DataFrames provide the tools you need to work efficiently at scale.
Moving Forward
Your next steps in the Spark ecosystem build naturally on this DataFrame foundation:
Spark SQL: Learn how to query DataFrames using familiar SQL syntax, making complex analytics more accessible to teams with database backgrounds.
Advanced DataFrame Operations: Explore window functions, complex joins, and advanced aggregations that handle sophisticated analytical requirements.
Performance Tuning: Discover caching strategies, partitioning techniques, and optimization approaches that make your DataFrame applications run faster in production.
Keep Learning
For deeper exploration of these concepts, check out the rest of our tutorial series:
- PySpark Tutorial for Beginners - Install and Learn Apache Spark with Python
- Working with RDDs in PySpark
- Working with DataFrames in PySpark ― You are here
- Using Spark SQL in PySpark for Distributed Data Analysis
- Build Your First ETL Pipeline with PySpark
You've taken another significant step in understanding distributed data processing. The combination of RDD fundamentals and DataFrame expressiveness gives you the flexibility to tackle big data challenges. Keep experimenting, keep building, and most importantly, keep learning!