What is a Data Engineer?
From helping cars drive themselves to helping Facebook tag you in photos, data science has attracted a lot of buzz recently. Data scientists have become extremely sought after, and for good reason — a skilled data scientist can add incredible value to a business. But what about data engineers? Who are they, and what do they do?
A data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use. Data engineers are just as important as data scientists, but tend to be less visible because they tend to be further from the end product of the analysis.
A good analogy is a race car builder vs a race car driver. The driver gets the excitement of speeding along a track, and thrill of victory in front of a crowd. But the builder gets the joy of tuning engines, experimenting with different exhaust setups, and creating a powerful, robust, machine. If you're the type of person that likes building and tweaking systems, data engineering might be right for you. In this post, we'll explore the day to day of a data engineer, and discuss the skills required for the role.
The Data Engineer Role
The data science field is incredibly broad, encompassing everything from cleaning data to deploying predictive models. However, it's rare for any single data scientist to be working across the spectrum day to day. Data scientists usually focus on a few areas, and are complemented by a team of other scientists and analysts.
Data engineering is also a broad field, but any individual data engineer doesn't need to know the whole spectrum of skills. In this section, we'll sketch the broad outlines of data engineering, then walk through more specific descriptions that illustrate specific data engineering roles.
A data engineer transforms data into a useful format for analysis. Imagine that you're a data engineer working on a simple competitor to Uber called Rebu. Your users have an app on their device through which they access your service. They request a ride to a destination through your app, which gets routed to a driver, who then picks them up and drops them off. After the ride, they're charged, and have the option to rate their driver.
In order to maintain a service like this, you need:
- A mobile app for users
- A mobile app for drivers
- A server that can pass requests from users to drivers, and handle other details like updating payment information
Here's a diagram showing the communication:

As you may expect, this kind of system will generate huge amounts of data. You'll have a few different data stores:
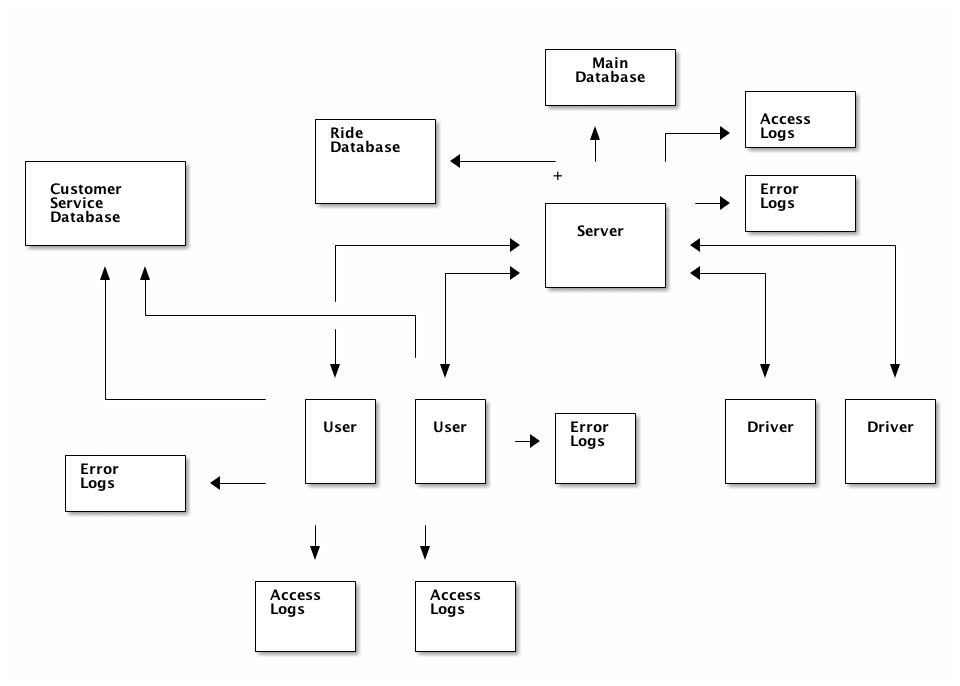
- The database that backs your main app. This contains user and driver information.
- Server analytics logs
- Server access logs. These contain one line per request made to the server from the app.
- Server error logs. These contain all the server-side errors generated by your app.
- App analytics logs
- App event logs. These contain information about what actions users and drivers took in the app. For example, you'd log when they clicked a button or updated their payment information.
- App error logs. These contain information about errors in the app.
- Ride database. This contains information about a single ride for user/driver pair, and contains status information on the ride.
- Customer service database. This contains information about customer interactions by customer service agents. It can include voice transcripts and email logs.
Here's an updated diagram showing the data sources:
Let's say a data scientist wants to analyze a user's action history with your service, and see what actions correlate with users who spend more. In order to enable them to create this, you'll need to combine information from the server access logs and the app event logs. You'll need to:
- Gather app analytics logs from user devices regularly
- Combine the app analytics logs with any server log entries that reference the user
- Create an API endpoint that returns the event history of any user
In order to solve this, you'll need to create a pipeline that can ingest mobile app logs and server logs in real-time, parse them, and attach them to a specific user. You'll then need to store the parsed logs in a database, so they can easily be queried by the API. You'll need to spin up several servers behind a load balancer to process the incoming logs.
Most of the issues that you'll run into will be around reliability and distributed systems. For example, if you have millions of devices to gather logs from, and variable demand (in the morning, you get a ton of logs, but not as many at midnight), you'll need a system that can automatically scale your server count up and down.
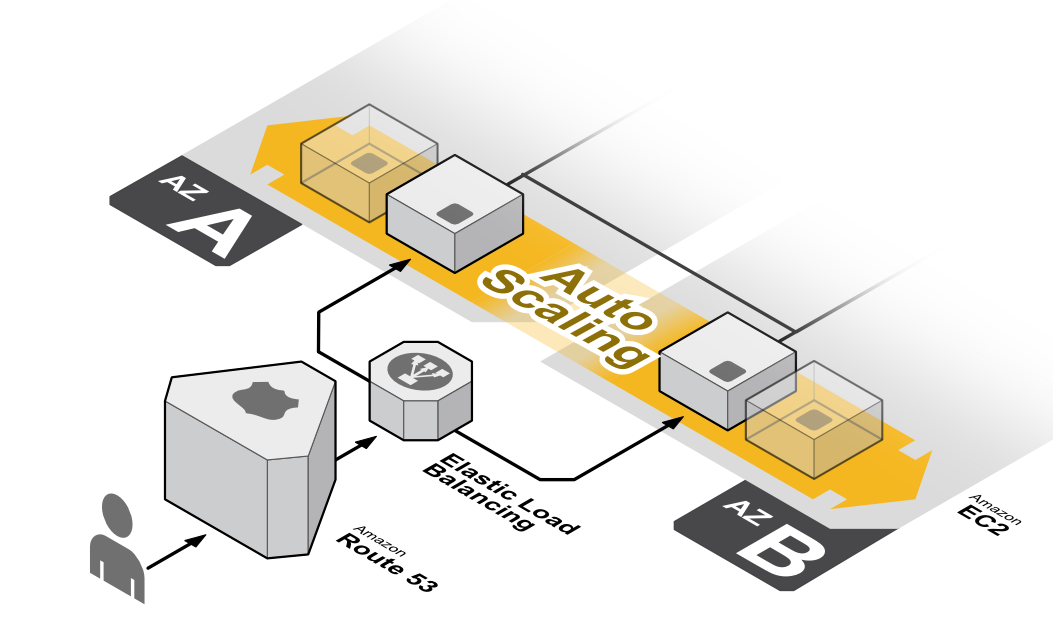
Running servers behind a load balancer. Servers are registered with the load balancer, and the load balancer sends traffic to them based on how busy they are. This means servers can be added or removed as needed.
Roughly, the operations in a data pipeline consist of the following phases:
- Ingestion — this involves gathering in the needed data.
- Processing — this involves processing the data to get the end results you want.
- Storage — this involves storing the end results for fast retrieval.
- Access — you'll need to enable a tool or user to access the end results of the pipeline.
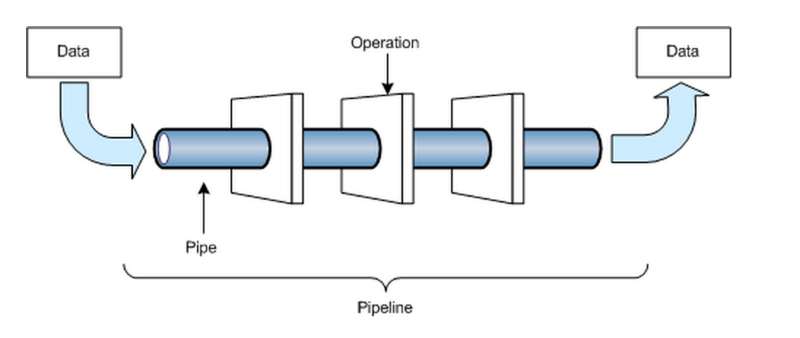
A data pipeline — input data is transformed in a series of phases into output data.
Finding bad quality rides
For a more complex example, imagine that a data scientist wants to build a system that finds all rides that ended prematurely due to app or driver issues. One way to do this is to look at the customer service database to see which rides ended with issues, and analyze their language logn with some data about the ride.
Before the data scientist can do this, they need a way to match up the logs in the customer service database with specific rides. As a data engineer, you'll want to create an API endpoint that allows the data scientist to query for all customer service messages related to a particular ride. In order to do this, you'll need to:
- Create a system that pulls data from the ride database, and figures out information about the ride, such as how long it was, and whether the destination matched the user's initial request.
- Combine the computed statistics on each ride with user information, such as name and user id.
- Extract error information from the app and server analytics logs pertaining to the user during the time period of the ride.
- Find all customer service queries by a user.
- Create some heuristic to match rides with customer service queries (a simple example is that a customer service query is always about the previous ride)
- Store values as needed to ensure that the API performs quickly, even for future rides.
- Create an API that returns all customer service messages related to a particular ride.
A skilled data engineer will be able to build a pipeline that performs each of the above steps every time a new ride is added. This will ensure that the data served by the API is always up to date, and that whatever analysis the data scientist does is valid.
Data engineering skills
A data engineer needs to be good at:
- Architecting distributed systems
- Creating reliable pipelines
- Combining data sources
- Architecting data stores
- Collaborating with data science teams and building the right solutions for them
Note that we didn't mention any tools above. Although tools like Hadoop and Spark and languages like Scala and Python are important to data engineering, it's more important to understand the concepts well and know how to build real-world systems. We'll continue this focus on concepts over tools throughout this series on data engineering.
Data Engineering Roles
Although data engineers need to have the skills listed above, the day to day of a data engineer will vary depending on the type of company they work for. Broadly, you can classify data engineers into a few categories:
- Generalist
- Pipeline-centric
- Database-centric
Let's go through each one of these categories.
Generalist
A generalist data engineer typically works on a small team. Without a data engineer, data analysts and scientsts don't have anything to analyze, making a data engineer a critical first member of a data science team.
When a data engineer is the only data-focused person at a company, they usually end up having to do more end-to-end work. For example, a generalist data engineer may have to do everything from ingesting the data to processing it to doing the final analysis. This requires more data science skill than most data engineers have. However, it also requires less systems architecture knowledge -- small teams and companies don't have a ton of users, so engineering for scale isn't as important. This is a good role for a data scientist who wants to transition into data engineering.
When our hypothetical Uber competitor, Rebu, is small, a data engineer might be asked to create a dashboard that shows the number of rides taken for each day in the past month, along with a forecast for the next month.
Pipeline-centric
Pipeline-centric data engineers tend to be necessary in mid-sized companies that have complex data science needs. A pipeline-centric data engineer will work with teams of data scientists to transform data into a useful format for analysis. This entails in-depth knowledge of distributed systems and computer science.
As Rebu grows, a pipeline-centric data engineer might be asked to create a tool that enables data scientists to query metadata about rides to use in a predictive algorithm.
Database-centric
A database-centric data engineer is focused on setting up and populating analytics databases. This involves some work with pipelines, but more work with tuning databases for fast analysis and creating table schemas. This involves ETL work to get data into warehouses. This type of data engineer is usually found at larger companies with many data analysts that have their data distributed across databases.
After Rebu takes over the world, a database centric data engineer might design an analytics database, then create scripts to pull information from the main app database into the analytics database.

A data warehouse takes in data, then makes it easy for others to query it.
Data Engineering Skills
In this post, we covered data engineering and the skills needed to practice it at a high level. If you're interested in architecting large-scale systems, or working with huge amounts of data, then data engineering is a good field for you.
It can be very exciting to see your autoscaling data pipeline suddently handle a traffic spike, or get to work with machines that have terabytes of RAM. There's satisfaction in building a robust system that can work for months or years with minimal tweaking.
Because data engineering is about learning to deal with scale and efficiency, it can be hard to find good practice material on your own. But don't give up hope — it's very possible to learn data engineering on your own and get a job in the field.
We've recently launched our new interactive Data Engineering Path at Dataquest, designed to teach you the skills you need to become a data engineer. If you're interested, you can sign up start learning for free.