Python Tutorial: Web Scraping with Scrapy (8 Code Examples)
In this Python tutorial, we'll go over web scraping using Scrapy — and we'll work through a sample e-commerce website scraping project.
By 2025 the internet will grow to more than 175 zetabytes of data. Unfortunately, a large portion of it is unstructured and not machine-readable. This means that you can access the data through websites and, technically speaking, in the form of HTML pages. Is there an easier way to not just access this web data but also download it in a structured format so it becomes machine-readable and ready to gain insights?
This is where web scraping and Scrapy can help you! Web scraping is the process of extracting structured data from websites. Scrapy, being one of the most popular web scraping frameworks, is a great choice if you want to learn how to scrape data from the web. In this tutorial, you'll learn how to get started with Scrapy and you'll also implement an example project to scrape an e-commerce website.
Before we get started, you might want to look at our Complete Python Tutorial for Beginners and bookmark the page for future reference!
Prerequisites
To complete this tutorial, you need to have Python installed on your system and it’s recommended to have a basic knowledge of coding in Python.
Installing Scrapy
In order to use Scrapy, you need to install it. Luckily, there’s a very easy way to do it via pip. You can use pip install scrapy to install Scrapy. You can also find other installation options in the Scrapy docs. It’s recommended to install Scrapy within a Python virtual environment.
virtualenv env
source env/bin/activate
pip install scrapyThis snippet creates a new Python virtual environment, activates it, and installs Scrapy.
Scrapy Project Structure
Whenever you create a new Scrapy project you need to use a specific file structure to make sure Scrapy knows where to look for each of its modules. Luckily, Scrapy has a handy command that can help you create an empty Scrapy project with all the modules of Scrapy:
scrapy startproject bookscraperIf you run this command, this creates a new Scrapy project - based on a template - that looks like this:
📦bookscraper
┣ 📂bookscraper
┃ ┣ 📂spiders
┃ ┃ ┗ 📜bookscraper.py
┃ ┣ 📜items.py
┃ ┣ 📜middlewares.py
┃ ┣ 📜pipelines.py
┃ ┗ 📜settings.py
┗ 📜scrapy.cfgThis is a typical Scrapy project file structure. Let’s quickly examine these files and folders on a high level so you understand what each of the elements does:
spidersfolder: This folder contains all of our future Scrapy spider files that extract the data.items: This file contains item objects that behave like Python dictionaries and provide an abstraction layer to store scraped data within the Scrapy framework.middlewares(advanced): Scrapy middlewares are useful if you want to modify how Scrapy runs and makes requests to the server (e.g., to get around antibot solutions). For simple scraping projects, you don’t need to modify middlewares.pipelines: Scrapy pipelines are for extra data processing steps you want to implement after you extract data. You can clean, organize, or even drop data in these pipelines.settings: General settings for how Scrapy runs, for example, delays between requests, caching, file download settings, etc.
In this tutorial, we focus on two Scrapy modules: spiders and items. With these two modules, you can implement simple and effective web scrapers that can extract data from any website.
After you’ve successfully installed Scrapy and created a new Scrapy project, let’s learn how to write a Scrapy spider (also called a scraper) that extracts product data from an e-commerce store.
Scraping Logic
As an example, this tutorial uses a website that was specifically created for practicing web scraping: Books to Scrape. Before coding the spider, it’s important to have a look at the website and analyze the path the spider needs to take to access and scrape the data.
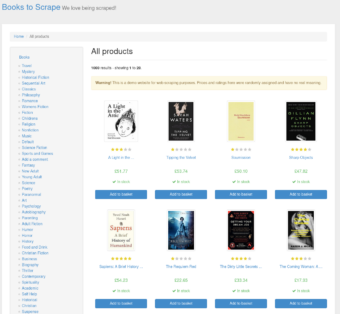
We'll use this website to scrape all the books that are available. As you can see on the site, there are multiple categories of books and multiple items in each category page. This means that our scraper needs to go to each category page and open each book page.
Let’s break down what the scraper needs to do on the website:
- Open the website (http://books.toscrape.com/).
- Find all the category URLs (like this one).
- Find all the book URLs on the category pages (like this one).
- Open each URL one by one and extract book data.
In Scrapy, we have to store scraped data in Item classes. In our case, an Item will have fields like title, link, and posting_time. Let’s implement the item!
Scrapy Item
Create a new Scrapy item that stores the scraped data. Let’s call this item BookItem and add the data fields that represent each book:
- title
- price
- upc
- image_url
- url
In code, this is how you create a new Item class in Scrapy:
from scrapy import Item, Field
class BookItem(Item):
title = Field()
price = Field()
upc = Field()
image_url = Field()
url = Field()As you can see in the code snippet, you need to import two Scrapy objects: Item and Field.
Item is used as the parent class for the BookItem so Scrapy knows this object will be used throughout the project to store and reference the scraped data fields.
Field is an object stored as part of an Item class to indicate the data fields within the item.
Once you created the BookItem class you can go ahead and work on the Scrapy spider that handles the scraping logic and extraction.
Scrapy Spider
Create a new Python file in the spiders folder called bookscraper.py
touch bookscraper.pyThis spider file contains the spider logic and scraping code. In order to determine what needs to go in this file, let’s inspect the website!
Website Inspection
Website inspection is a tedious, but important step in the web scraping process. Without a proper inspection, you won't know how to locate and extract the data from the websites efficiently. Inspection is usually done using your browser’s “inspect” tool or some 3rd party browser plugin that lets you “look under the hood” and analyze the source code of a website. It’s recommended that while you’re analyzing the website you turn off JS execution in your browser - this way you can see the website the same way your Scrapy spider will see it.
Let’s recap what URLs and data fields we need to locate in the source code of the website:
- category URLs
- book URLs
- finally, book data fields
Inspect the source code to locate category URLs in the HTML:
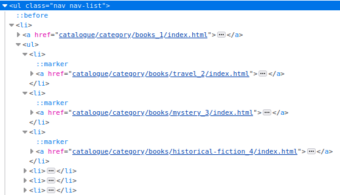
What you can notice by inspecting the website is that category URLs are stored within a ul HTML element with a class nav nav-list. This is crucial information, because you can use this CSS and the surrounding HTML elements to locate all of the category URLs on the page - exactly what we need!
Let’s keep this in mind and dig deeper to find other potential CSS selectors we can use in our spider. Inspect the HTML to find book page URLs:

Individual book page URLs are located under an article HTML element with the CSS class product pod. We can use this CSS rule to find the book page URLs with our scraper.
Finally, inspect the website to find individual data fields on the book page:
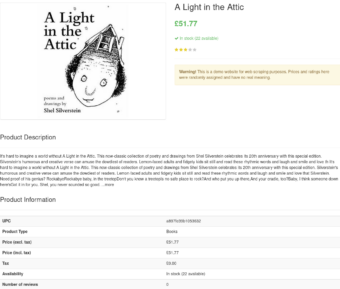
This time it’s slightly more tricky as we're looking for multiple data fields on the page, not just one. So we'll need multiple CSS selectors to find each field on the page. As you can see on the screenshot above, some data fields (like UPC and price) can be found in an HTML table, but other fields (like the title) are on the top of the page in a different kind of HTML element.
After inspection, and finding all the data fields and URL locators we need, you can implement the spider:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from bookscraper.items import BookItem
class BookScraper(CrawlSpider):
name = "bookscraper"
start_urls = ["http://books.toscrape.com/"]
rules = (
Rule(LinkExtractor(restrict_css=".nav-list > li > ul > li > a"), follow=True),
Rule(LinkExtractor(restrict_css=".product_pod > h3 > a"), callback="parse_book")
)
def parse_book(self, response):
book_item = BookItem()
book_item["image_url"] = response.urljoin(response.css(".item.active > img::attr(src)").get())
book_item["title"] = response.css(".col-sm-6.product_main > h1::text").get()
book_item["price"] = response.css(".price_color::text").get()
book_item["upc"] = response.css(".table.table-striped > tr:nth-child(1) > td::text").get()
book_item["url"] = response.url
return book_itemLet’s break down what’s happening in this code snippet:
- Scrapy will open the website http://books.toscrape.com/.
- It will start iterating over the category pages defined by the
.nav-list > li > ul > li > aCSS selector. - It will start iterating over all the book pages on all of the category pages using this CSS selector:
.product_pod > h3 > a. - Finally, once a book page is opened, Scrapy extracts the
image_url,title,price,upc, andurldata fields from the page and returns theBookItemobject.
Running The Spider
Finally, we need to test that our spider actually works and scrapes all the data we need. You can run the spider using the scrapy crawl command and referencing the name of the spider (as defined in the spider code, not the name of the file!):
scrapy crawl bookscraperAfter running this command, you'll see the output of Scrapy real-time as it’s in the process of scraping the whole website:
{'image_url': 'http://books.toscrape.com/media/cache/0f/76/0f76b00ea914ced1822d8ac3480c485f.jpg',
'price': '£12.61',
'title': 'The Third Wave: An Entrepreneur’s Vision of the Future',
'upc': '3bebf34ee9330cbd',
'url': 'http://books.toscrape.com/catalogue/the-third-wave-an-entrepreneurs-vision-of-the-future_862/index.html'}
2022-05-01 18:46:18 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/shoe-dog-a-memoir-by-the-creator-of-nike_831/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/fc/21/fc21d144c7289e5b1cb133e01a925126.jpg',
'price': '£23.99',
'title': 'Shoe Dog: A Memoir by the Creator of NIKE',
'upc': '0e0dcc3339602b28',
'url': 'http://books.toscrape.com/catalogue/shoe-dog-a-memoir-by-the-creator-of-nike_831/index.html'}
2022-05-01 18:46:18 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/the-10-entrepreneur-live-your-startup-dream-without-quitting-your-day-job_836/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/50/4b/504b1891508614ff9393563f69d66c95.jpg',
'price': '£27.55',
'title': 'The 10% Entrepreneur: Live Your Startup Dream Without Quitting Your '
'Day Job',
'upc': '56e4f9eab2e8e674',
'url': 'http://books.toscrape.com/catalogue/the-10-entrepreneur-live-your-startup-dream-without-quitting-your-day-job_836/index.html'}
2022-05-01 18:46:18 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/far-from-true-promise-falls-trilogy-2_320/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/9c/aa/9caacda3ff43984447ee22712e7e9ca9.jpg',
'price': '£34.93',
'title': 'Far From True (Promise Falls Trilogy #2)',
'upc': 'ad15a9a139919918',
'url': 'http://books.toscrape.com/catalogue/far-from-true-promise-falls-trilogy-2_320/index.html'}
2022-05-01 18:46:18 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/the-travelers_285/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/42/a3/42a345bdcb3e13d5922ff79cd1c07d0e.jpg',
'price': '£15.77',
'title': 'The Travelers',
'upc': '2b685187f55c5d31',
'url': 'http://books.toscrape.com/catalogue/the-travelers_285/index.html'}
2022-05-01 18:46:18 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/the-bone-hunters-lexy-vaughan-steven-macaulay-2_343/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/8d/1f/8d1f11673fbe46f47f27b9a4c8efbf8a.jpg',
'price': '£59.71',
'title': 'The Bone Hunters (Lexy Vaughan & Steven Macaulay #2)',
'upc': '9c4d061c1e2fe6bf',
'url': 'http://books.toscrape.com/catalogue/the-bone-hunters-lexy-vaughan-steven-macaulay-2_343/index.html'}Conclusion
I hope this quick Scrapy tutorial helps you get started with Scrapy and web scraping. Web scraping is a very fun skill to learn but it’s also very valuable to be able to download a huge amount of data from the web to build something interesting. Scrapy has a great community so you can be sure that whenever you get stuck in the future while scraping you'll find an answer to your problem there, or on Stack Overflow, Reddit, or in other places. Happy scraping!