Intermediate SQL: PostgreSQL, Subqueries, and more!
If you're in the early phases of learning SQL and have completed one or more introductory-level courses, you've probably learned most of the basic fundamentals and possibly even some high-level database concepts. As you prepare to embark on the next phase of learning intermediate SQL, it's important to not only understand SQL itself, but also the engine that makes it all possible: the database.

In most introductory-level courses, you'll typically use some sort of embedded database (e.g. SQLite).
Embedded databases are an excellent choice for beginners so that they can focus on learning SQL without the burden of allocating additional computing resources and mitigating the time to install configure the software. However, as the requirements of your application and/or data begin to scale, you may need a more robust solution.
Types of Databases
At a high level, there are two main types of databases: server-based, and file-based (also called embedded).
One of the most popular file-based databases is SQLite. It's ideal for small-scale applications, but as your needs become more complex, you may encounter its limitations. For example, an SQLite database is stored in a single large binary file with a theoretical maximum size of about 281 terabytes.
If you're thinking that this is larger than anything you'd ever need (at least any time soon), you're probably right. However, many filesystems limit the maximum size of a file to something far less than this. So if you wanted to develop a large scale web application, this would not be feasible.
Furthermore, there are security concerns, among many others. Server-based databases provide key functionality to larger and more robust applications, like high availability/failover, increased and more flexible security, scalability, increased performance, and more.
Our Data
Today, we're going to perform data discovery and analysis on two data sets from the Consumer Financial Protection Bureau (CFPB) using PostgreSQL (postgres). The data consists of consumer complaints regarding two types of financial services: bank accounts and credit cards.
First, we'll set up your database by creating tables, creating users, and loading the data from CSV files. Next, we'll dive into more advanced SQL concepts while analyzing the data and discovering valuable insights! Some of the SQL concepts we'll be covering today are below.
- Creating users, databases and tables,
- The
IS NULL/IS NOT NULLclause, - Views,
- Subqueries,
- Union/union all,
- Intersect/except,
- String concatenation, and
- Casting data types.
If you need to brush up on your SQL fundamentals, we recommend our blog post SQL Basics: Working with Databases.
Datasets
We’re going to be working with two different CSV files of consumer complaint data from the CFPB:
Bank_Account_or_Service_Complaints.csvCredit_Card_Complaints.csv
The files were originally downloaded from the CFPB website. Since the CFPB regularly updates their data, we've uploaded the exact versions used in this post to data.world, which you can download using the link once you're signed in. Both CSV files have identical fields. The table below consists of the data set’s fields and data type we intend to use for them:
| Field Name | Data Type |
|---|---|
complaint_id |
text |
date_received |
date |
product |
text |
sub_product |
text |
issue |
text |
sub_issue |
text |
consumer_complaint_narrative |
text |
company_public_response |
text |
company |
text |
state |
text |
zip_code |
text |
tags |
text |
consumer_consent_provided |
text |
submitted_via |
text |
date_sent |
date |
company_response_to_consumer |
text |
timely_response |
text |
consumer_disputed |
text |
You may be wondering why some of the numeric fields like zip_code and complaint_id are stored as text. The general rule of thumb is to always store numeric characters as text unless you are planning on doing some type of mathematical calculations on the values themselves. As an example, below is a field containing numbers that you’d want to store as a numeric type (age), and one that you wouldn’t (ID):
- Store as numeric type – An
agefield that stores people’s ages and they want to do things like find the average of a person living in a certain zip code. - Store as text – An
IDfield of some sort that you wouldn't perform any mathematical operations on. Generally speaking, you can’t add, multiply, or perform any other type of arithmetic on a zip code that would make any sense.
Downloading & Installing PostgreSQL
The first thing you’ll need to do is setup PostgreSQL if you don’t yet have it set up. Below are download links for the major operating systems:
Create New User, Database, and Tables
We need to create two new tables to store the data in the files that we downloaded, earlier. You can achieve this several different ways, but we’re going to use the psql shell throughout this tutorial. To open the psql shell, this can be achieved by opening a command prompt (Windows) or terminal (Mac) window, and typing psql and hitting enter.
This will launch the psql shell. If this is your first time using psql shell, your user will likely not have necessary permissions to launch the utility. First, you will need to use an account with administrator privileges, and then use psql -U postgres to login with the postgres user (which was created automatically during the install)
~$ psql
psql (9.5.3)
Type "help" for help.
postgres=#The postgres=# that you see is the psql prompt, and the postgres text will be replaced with whichever database you are connected to. We’re going to create a new user for our database.
For this tutorial we’ll call our user oracle, but you can use anything, and it’s convenient to use the same username you use for your operating system, as you then don’t have to worry about passwords or specifying a user moving forward. To create a new user, we use the following syntax:
CREATE ROLE name WITH options_go_here;Click here for the documentation regarding the CREATE ROLE statement. Here you’ll find all of the available options and relative DESCriptions. We’re going to give this new user the following permissions:
SUPERUSER: The user will be a superuser.CREATEDB: The user will be allowed to create databases.CREATEROLE: The user will be allowed to create new roles.LOGIN: The user will be able to login.INHERIT: The user will inherit all privelages of roles it’s a member of.
Let’s create the new user, oracle, with the password welcome1.
CREATE ROLE oracle password 'welcome1' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN;Our new user should now be created. Let’s check to make sure our new user has sufficient privileges. Enter the command du and hit enter. Your user should have the following permissions:
postgres=# du
List of roles
Role name | Attributes | Member of
----------+------------+-----------
oracle | Superuser | {}
: Create role
: Create DB
postgres | Superuser | {}
: Create role
: Create DBThis will allow you to connect using the oracle user from now on. For now, we can switch over to the oracle user using the command
SET ROLE oracle;If we had quit the psql shell (using q) we can connect when we launch the psql shell:
~$ psql -U oracle postgres
psql (9.5.3)
Type "help" for help.
postgres=#The -U flag allows us to specify the user, and the postgres specifies the postgres account database (if we don’t specify a database here, we’ll get an error). Now that we’re logged in as the oracle user, we’re going to create a new database. To create a new database, we use the following syntax:
CREATE DATABASE database_name;The CREATE DATABASE statement has a lot more options that we don’t need right now – if you like you can read about them in the documentation. Now, let’s create the new database, consumer_complaints.
CREATE DATABASE consumer_complaints;To confirm that our database has been created, retrieve a list of the databases in the Postgres cluster by using the l (list) command. You should see the new database, as shown below.
postgres=# l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
---------------------+----------+----------+-------------+-------------+-----------------------
consumer_complaints | oracle | UTF8 | en_US.UTF-8 | en_US.UTF-8 |Let’s connect to our new database by using the connect command:
oracle=# connect consumer_complaints
You are now connected to database "consumer_complaints" as user "oracle".
consumer_complaints=#You can also launch psql directly conencted to your database from the command line:
~$ psql -U oracle consumer_complaints
psql (9.5.3)
Type "help" for help.
consumer_complaints=#Creating tables for the data
Next, we can create the tables to store our CSV data. The table names are as follows:
credit_card_complaintsbank_account_complaints
The fields and their respective data types will be the same in both tables. To create a new table, we use the following syntax:
CREATE TABLE name_of_table (
name_of_column data_type [PRIMARY KEY],
name_of_column data_type,
name_of_column data_type,
name_of_column data_type,
name_of_column data_type);Like the CREATE DATABASE statement, the CREATE TABLE has many more options which you can find in the documentation. To create our two databases, you’ll need to run the following two statements in the psql shell:
CREATE TABLE bank_account_complaints (
complaint_id text PRIMARY KEY,
date_received date,
product text,
sub_product text,
issue text,
sub_issue text,
consumer_complaint_narrative text,
company_public_response text,
company text,
state text,
zip_code text,
tags text,
consumer_consent_provided text,
submitted_via text,
date_sent date,
company_response_to_consumer text,
timely_response text,
consumer_disputed text);;CREATE TABLE credit_card_complaints (
complaint_id text PRIMARY KEY,
date_received date,
product text,
sub_product text,
issue text,
sub_issue text,
consumer_complaint_narrative text,
company_public_response text,
company text,
state text,
zip_code text,
tags text,
consumer_consent_provided text,
submitted_via text,
date_sent date,
company_response_to_consumer text,
timely_response text,
consumer_disputed text);;You should get the output 'CREATE TABLE' from these statements to let you know they were created correctly.
Loading Data into the Database
There are several ways to load external data into your postgres tables. Here are a few common ways to load data existing in a CSV file:
- Import utility in the pgAdmin client application.
- Reading file, instantiating database connection, and loading data via Python, Java, or other programming language.
- Postgres Copy utility.
Today, we’re going to load the data from our two CSV files into our two new tables, using the Postgres Copy utility via psql shell. Copy allows you to export data out of, or import data into, Postgres database. It supports the following formats:
- Binary
- Tab delimited
- Comma delimited
To copy data from a file to a database table using the copy statement, we use the following syntax:
COPY name_of_table (name_of_column, name_of_column, name_of_column)
FROM 'filename'
WITH options_go_hereWe’ll be using the WITH CSV HEADER option, but as before the documenation has full syntax and explanations. We’ll presume that the CSV files are in the same folder as where you launched your psql session. We’ll start by importing the data from the Credit_Card_Complaints.csv file into the credit_card_complaints postgres table.
consumer_complaints=# COPY credit_card_complaints (date_received, product, sub_product, issue, sub_issue, consumer_complaint_narrative, company_public_response, company, state, zip_code, tags, consumer_consent_provided, submitted_via, date_sent, company_response_to_consumer, timely_response, consumer_disputed, complaint_id)
FROM './Credit_Card_Complaints.csv'
WITH CSV HEADERNow let’s do the same for the Bank_Account_or_Service_Complaints.csv file and the bank_account_complaints postgres table.
consumer_complaints=# COPY bank_account_complaints (date_received, product, sub_product, issue, sub_issue, consumer_complaint_narrative, company_public_response, company, state, zip_code, tags, consumer_consent_provided, submitted_via, date_sent, company_response_to_consumer, timely_response, consumer_disputed, complaint_id)
FROM './Bank_Account_or_Service_Complaints.csv'
WITH CSV HEADERQuerying our Postgres database
We can run queries directly from our psql shell, however it can be difficult to understand the results, especially with many rows and columns. In this tutorial, we will be querying the database using Python. If we want to return the results of a query, we will use the Pandas module, which will allow us to store the results into a Dataframe object. This will make it easier to visualize and analyze the results. To do this, we have to first import the pandas, SQLAlchemy and psycopg2 modules. If you don’t have these, you can easily install them using pip:
~$ pip install pandas sqlalchemy pscopg2Or conda (although all come with the standard anaconda package):
~$ conda install pandas sqlalchemy pscopg2We will also need to create two helper functions – one to run our queries and one to run our commands (i.e. creating/dropping views, tables, sequences, etc.). Don’t worry if you don’t understand how these functions work, just know that they’ll help us interface with our database using Python and give us results that are easier to read.
import pandas as pd
import psycopg2
# psycopg2 lets us easily run commands against our db
conn = psycopg2.connect("dbname=consumer_complaints user=oracle")
conn.autocommit = True
cur = conn.cursor()
def run_command(command):
cur.execute(command)
return cur.statusmessage
# sqlalchemy is needed to allow pandas to seemlessly connect to run queries
from sqlalchemy import create_engine
engine = create_engine('postgresql://oracle@localhost/consumer_complaints')
def run_query(query):
return pd.read_sql_query(query,con=engine)As a test query to show how these functions work, we’ll validate the data in our tables to ensure that all the data from the CSV files was loaded. A quick way to do this is to get the number of records for a specific table using the count function.
query = 'SELECT COUNT(*) FROM credit_card_complaints;'
run_query(query)| count | |
|---|---|
| 0 | 87718 |
query = 'SELECT COUNT(*) FROM bank_account_complaints;'
run_query(query)| count | |
|---|---|
| 0 | 84811 |
Counting with Conditionals
When comparing a column to null (no value), you cannot use the = operator. null denotes an undefined value. Since an undefined value cannot equal an undefined value, null cannot equal null.
- Instead of
= NULL, we useIS NULL. - Instead of
<> NULL, we useIS NOT NULL.
If we look at the data in each file, we can see that there are several fields with a large amount of null values. One of the biggest value propositions of this dataset is the consumer complaint narratives. This allows us to understand and analyze the sentiment of the consumers complaint. Let’s see how many records in each table have null values for the consumer complaint narrative field, starting with the credit_card_complaints table.
query =
'''
SELECT COUNT(*) FROM credit_card_complaints
WHERE consumer_complaint_narrative IS NOT NULL;
'''
run_query(query)| count | |
|---|---|
| 0 | 17433 |
There are 17,433 records with a consumer complaint narrative in the credit_card_complaints table. Since there are 87,718 records in the table, total, there must be 70,285 (87,718 – 17,433) records that do not have a consumer complaint narrative (or are null). Let’s check this manually:
query =
'''
SELECT COUNT(*) FROM credit_card_complaints
WHERE consumer_complaint_narrative IS NULL;
'''
run_query(query)| count | |
|---|---|
| 0 | 70285 |
Looks like our numbers line up! Next, we’ll look at null values for the consumer_complaint_narrative column for the bank_account_complaints table.
query =
'''
SELECT COUNT(*) FROM bank_account_complaints
WHERE consumer_complaint_narrative IS NOT NULL;
'''
run_query(query)| count | |
|---|---|
| 0 | 13860 |
There are 13,860 records with a consumer complaint narrative in the credit_card_complaints table. Since there are 84,811 records in the table, total, there must be 70,951 (84,811 – 13,860) records that do not have a consumer complaint narrative. Let’s see:
query =
'''
SELECT count(*) FROM bank_account_complaints
WHERE consumer_complaint_narrative IS NULL;
'''
run_query(query)| count | |
|---|---|
| 0 | 70951 |
Again, the numbers line up.
Using views
A view is essentially a logical representation of a query’s result. It behaves like a traditional table where you can select values, but you cannot insert into, update, or delete from it. Here are a few benefits of using views:
- Reusability – Views can be used to reuse complex queries that are frequently used.
- Security – Views are often made accessible to certain users so that they cannot view the underlying tables and only relevant data is available.
- Query Performance – Sometimes, writing complex queries consisting of several subqueries and aggregations will utilize a large amount of resources.
Considering the last point in more detail, even if we have adequate resources we could potentially degrade performance of either processes running on the machine or it could take an extremely long time. We can use views to filter down the dataset ahead of time, thus tremendously mitigating the complexity and overall execution time. A temporary view (TEMPORARY or TEMP) is automatically dropped at the end of the current session. Depending on the use case, you may or may not want to use temporary view. For example, using temporary views can be extremely helpful while validating or testing certain data points that are created via several joins, tables, and calculations. Performing complex data validations often times require large and convoluted queries that are not only hard to read and understand, but also perform poorly. Large queries consisting of multiple subqueries/inline views can utilize a large amount of spool space and computing resources, thus resulting in poor query performance and degraded performance of the application. In these instances, it’s usually a much better idea and to create one or more views. In the previous section, we determined that a large amount of records had null values for the consumer complaint narrative field. Instead of having to filter on this field later on, we’ll create views instead for later use. We’ll create four views based on two dimensions: by product (eg credit card vs bank account), and whether they contain null values for consumer complaint narrative. 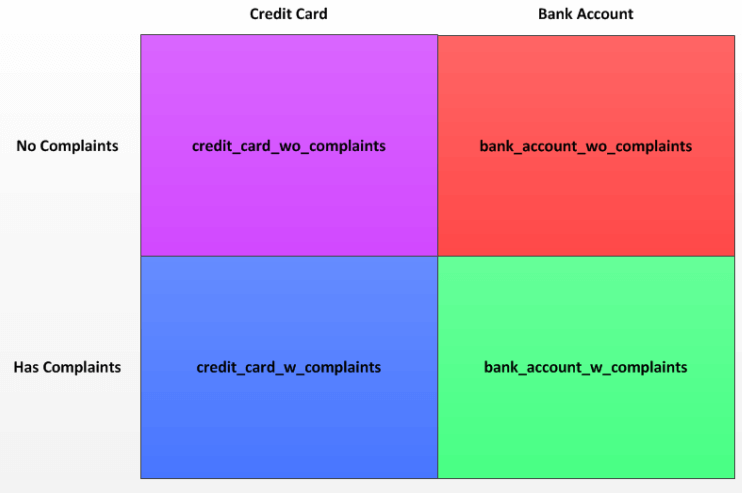 Our four views will be called
Our four views will be called
credit_card_w_complaintscredit_card_wo_complaintsbank_account_w_complaintsbank_account_wo_complaints
The syntax for creating a view is extremely simple:
CREATE VIEW view_name AS
[query_to_generate_view_goes_here];Let’s create our four views.
command =
'''
CREATE VIEW credit_card_w_complaints AS
SELECT * FROM credit_card_complaints
WHERE consumer_complaint_narrative IS NOT NULL;
'''
run_command(command)'CREATE VIEW'command =
'''
CREATE VIEW credit_card_wo_complaints as
SELECT * FROM credit_card_complaints
WHERE consumer_complaint_narrative IS NULL;
'''
run_command(command)'CREATE VIEW'command =
'''
CREATE VIEW bank_account_w_complaints AS
SELECT * FROM bank_account_complaints
WHERE consumer_complaint_narrative IS NOT NULL;
'''
run_command(command)'CREATE VIEW'command =
'''
CREATE VIEW bank_account_wo_complaints AS
SELECT * FROM bank_account_complaints
WHERE consumer_complaint_narrative IS NULL;
'''
run_command(command)'CREATE VIEW'Let’s take a quick look at one of our newly-created views so we can see that it works just like a table.
query =
'''
SELECT * FROM credit_card_w_complaints LIMIT 5;
'''
run_query(query)| complaint_id | date_received | product | sub_product | issue | sub_issue | consumer_complaint_narrative | company_public_response | company | state | zip_code | tags | consumer_consent_provided | submitted_via | date_sent | company_response_to_consumer | timely_response | consumer_disputed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1297939 | 2015-03-24 | Credit card | None | Other | None | Received Capital One charge card offer XXXX. A… | None | Capital One | OH | 440XX | None | Consent provided | Web | 2015-03-30 | Closed with explanation | Yes | No |
| 1 | 1296693 | 2015-03-23 | Credit card | None | Rewards | None | I ‘m a longtime member of Charter One Bank/RBS… | None | Citizens Financial Group, Inc. | MI | 482XX | None | Consent provided | Web | 2015-03-23 | Closed with explanation | Yes | Yes |
| 2 | 1295056 | 2015-03-23 | Credit card | None | Other | None | I attempted to apply for a Discover Card Onlin… | None | Discover | MD | 217XX | None | Consent provided | Web | 2015-03-23 | Closed with non-monetary relief | Yes | No |
| 3 | 1296880 | 2015-03-23 | Credit card | None | Late fee | None | XXXX Card services was bought out by Capital O… | None | Capital One | MI | 488XX | None | Consent provided | Web | 2015-03-23 | Closed with monetary relief | Yes | No |
| 4 | 1296890 | 2015-03-23 | Credit card | None | Billing disputes | None | I was reported late by Discover Card to the re… | None | Discover | OK | 741XX | Servicemember | Consent provided | Web | 2015-03-23 | Closed with explanation | Yes | No |
Union/Union All
The UNION operator combines the result-set of two or more queries. Think of 2 Lego bricks with the exact same dimensions. Since they both share the same dimensions, they will stack on top of each other perfectly. Unions behave in a similar fashion. If the select statements have the same number of columns, data types, and are in the same order (by data type), then they will “stack” on top of each other, similar to the Lego brick analogy I used earlier. There are two variations of union:
UNION ALLselects distinct (unique) values.UNIONselects all values (including duplicates).
If you recall from the last section, we have four views. What if we wanted to view the two products’ data together, and only differentiate by whether their records contain null values for consumer complaint narrative? Since all four views have the same number of columns and data types, this makes them a perfect candidate for a union. We’ll create two new views that will essentially consolidate the four current views down to two by performing a union on each products’ views.
command =
'''
CREATE VIEW with_complaints AS
SELECT * from credit_card_w_complaints
UNION ALL
SELECT * from bank_account_w_complaints;
'''
run_command(command)'CREATE VIEW'command =
'''
CREATE VIEW without_complaints AS
SELECT * FROM credit_card_wo_complaints
UNION ALL
SELECT * FROM bank_account_wo_complaints;
'''
run_command(command)'CREATE VIEW'Intersect/Except
The INTERSECT operator returns all records that are in the result-sets of both queries, while the EXCEPT operator returns all records that are in the result-set of the first query but not the second. 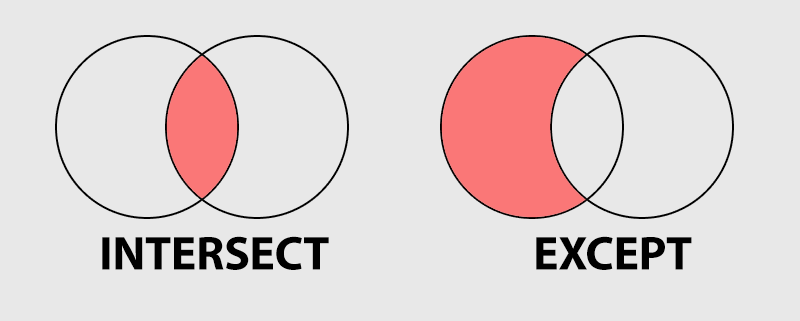
The syntax for INTERSECT/EXCEPT is simple; we just use these commands to connect two select statements:
SELECT * FROM name_of_table_one
INTERSECT [or EXCEPT]
SELECT * FROM name_of_table_two;In the previous section, we consolidated our four views into two new views by performing a union. If we want to validate to make sure our new views were created correctly, we can achieve this by using both INTERSECT and EXCEPT operator. First, let’s retrieve the record count for the credit_card_wo_complaints view.
query = 'SELECT count(*) FROM credit_card_wo_complaints;'
run_query(query)| count | |
|---|---|
| 0 | 70285 |
If our logic was correct in our union, we should be able to intersect the without_complaints view with the credit_card_wo_complaints view and return the same amount of records.
query =
'''
SELECT COUNT(*)
FROM (SELECT * FROM without_complaints
INTERSECT
SELECT * FROM credit_card_wo_complaints) ppg;
'''
run_query(query)| count | |
|---|---|
| 0 | 70285 |
Conversely, if we replace the intersect operator with an except operator, we should get difference in record counts between the without_complaints view and the 70,285 record count that was returned previously. The difference should be 70,951 (141,236 – 70,285).
query =
'''
SELECT COUNT(*)
FROM (SELECT * FROM without_complaints
EXCEPT
SELECT * FROM credit_card_wo_complaints) ppg;
'''
run_query(query)| count | |
|---|---|
| 0 | 70951 |
String Concatenation
String concatenation is simply combining two or more strings (text values) together into a single string. This is an extremely useful tool, in several instances. Let’s say we had a “year” field and a “month” field, but we wanted to show it as one field (i.e. “2017-March”), instead. We can achieve this by concatenating the values in both fields using the || operator. The syntax is as follows:
SELECT <string_1> || <string_2> FROM name_of_table;Let’s try it out by selecting complaint_id, product, company, zip_code, and concatenating all of those fields, separated by a hyphen (-), from credit_card_complaints.
query =
'''
SELECT complaint_id, product, company, zip_code,
complaint_id || '-' || product || '-' || company || '-' || zip_code AS concat
FROM credit_card_complaints
LIMIT 10
'''
run_query(query)| complaint_id | product | company | zip_code | concat | |
|---|---|---|---|---|---|
| 0 | 469026 | Credit card | Citibank | 45247 | 469026-Credit card-Citibank-45247 |
| 1 | 469131 | Credit card | Synchrony Financial | 98548 | 469131-Credit card-Synchrony Financial-98548 |
| 2 | 479990 | Credit card | Amex | 78232 | 479990-Credit card-Amex-78232 |
| 3 | 475777 | Credit card | Capital One | 32226 | 475777-Credit card-Capital One-32226 |
| 4 | 469473 | Credit card | Citibank | 53066 | 469473-Credit card-Citibank-53066 |
| 5 | 470828 | Credit card | Wells Fargo & Company | 89108 | 470828-Credit card-Wells Fargo & Company-89108 |
| 6 | 470852 | Credit card | Citibank | 78249 | 470852-Credit card-Citibank-78249 |
| 7 | 479338 | Credit card | JPMorgan Chase & Co. | 19809 | 479338-Credit card-JPMorgan Chase & Co.-19809 |
| 8 | 480935 | Credit card | Citibank | 07018 | 480935-Credit card-Citibank-07018 |
| 9 | 469738 | Credit card | Wells Fargo & Company | 95409 | 469738-Credit card-Wells Fargo & Company-95409 |
Subqueries
A subquery (technically known as an inline view and also referred to as a subselect statement, derived table) is a select statement in the FROM clause within another select statement. They’re extremely useful in many different scenarios. We actually saw an example of this earlier when we used COUNT(*) with our INTERSECT and EXCEPT example. Subqueries help to simplify otherwise complex queries and allow for more flexibility, and as their proper name (inline view) suggests, is just like creating a mini view within a single query. The syntax is:
SELECT [column_names_here]
FROM ( [subquery_goes_here] );The idea of subqueries can be a little difficult at first, so we’re going to show you a subquery in action and then break it down.
query =
'''
SELECT ccd.complaint_id, ccd.product, ccd.company, ccd.zip_code
FROM (SELECT complaint_id, product, company, zip_code
FROM credit_card_complaints
WHERE zip_code = '91701') ccd LIMIT 10;
'''
run_query(query)| complaint_id | product | company | zip_code | |
|---|---|---|---|---|
| 0 | 24857 | Credit card | Barclays PLC | 91701 |
| 1 | 33157 | Credit card | Citibank | 91701 |
| 2 | 12245 | Credit card | Bank of America | 91701 |
| 3 | 3151 | Credit card | Barclays PLC | 91701 |
| 4 | 352534 | Credit card | Citibank | 91701 |
| 5 | 1963836 | Credit card | JPMorgan Chase & Co. | 91701 |
| 6 | 2178015 | Credit card | Discover | 91701 |
| 7 | 2234754 | Credit card | Discover | 91701 |
| 8 | 2235915 | Credit card | Discover | 91701 |
The most important thing to realize with subqueries is that you need to read them from the inside out.

The innermost query (in purple) is executed first, which filters result set down by a specific zip code. Then the outermost query executes its select statement on the result-set derived from the innermost query. You’ll notice that we’ve given our subquery a name – ccd – that we then use to refer to the columns in the outer SELECT statement. This is something that PostgreSQL requires, but beyond that it makes the query easier to read and makes sure the SQL engine understands exactly your intention (which can avoid errors or unintended results). If you’re thinking that the query above could’ve been simplified and that you could’ve achieved the same result without a subquery, you’re correct. You didn’t actually need to use an inline view. It was merely a simple example to demonstrate how inline views are structured. A more efficient and simple way to structure the query is as follows.
query =
'''
SELECT complaint_id, product, company, zip_codefrom credit_card_complaints
WHERE zip_code = '91701'
LIMIT 10
'''
run_query(query)| complaint_id | product | company | zip_code | |
|---|---|---|---|---|
| 0 | 24857 | Credit card | Barclays PLC | 91701 |
| 1 | 33157 | Credit card | Citibank | 91701 |
| 2 | 12245 | Credit card | Bank of America | 91701 |
| 3 | 3151 | Credit card | Barclays PLC | 91701 |
| 4 | 352534 | Credit card | Citibank | 91701 |
| 5 | 1963836 | Credit card | JPMorgan Chase & Co. | 91701 |
| 6 | 2178015 | Credit card | Discover | 91701 |
| 7 | 2234754 | Credit card | Discover | 91701 |
| 8 | 2235915 | Credit card | Discover | 91701 |
So why are inline views/subqueries useful? Let’s look at a more complex example.
Subqueries in action
If we were a financial services company, one of the insights we might want to derive from this data is where the highest number of complaints are coming from. Moreover, it might also be useful to see the same metrics from our competitiors. To achieve this, we’ll need to return a distinct list of all companies, and then find the zip code associated with highest number of complaints, by each state. So for each company, there should be a distinct list of states, along with the zip code associated with the highest number of complaints in that state. Let’s start by querying the company name, the state, and zip code, associated with the number of complaints. Let’s also go ahead and filter the records that have a null state name. For now, let’s start with one company, Citibank.
query =
'''
SELECT company, state, zip_code, COUNT(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank' AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC
LIMIT 10;
'''
run_query(query)| company | state | zip_code | complaint_count | |
|---|---|---|---|---|
| 0 | Citibank | NY | 100XX | 80 |
| 1 | Citibank | TX | 750XX | 67 |
| 2 | Citibank | CA | 945XX | 58 |
| 3 | Citibank | NY | 112XX | 52 |
| 4 | Citibank | CA | 900XX | 50 |
| 5 | Citibank | GA | 300XX | 46 |
| 6 | Citibank | IL | 606XX | 44 |
| 7 | Citibank | NJ | 070XX | 44 |
| 8 | Citibank | FL | 331XX | 39 |
| 9 | Citibank | CA | 926XX | 38 |
Now that we have a list of states, zip codes, and amount of complaints by company, sorted by the number of complaints, we can take this a step further. Next using the query above as a subquery we can return the records with the highest number of complaints by each state. We’re still going to use Citibank, for now.
 Our first query has become the subquery, highlighted in purple, and is executed first. The outer query is then run on the results of our subquery. Let’s take a look at the results.
Our first query has become the subquery, highlighted in purple, and is executed first. The outer query is then run on the results of our subquery. Let’s take a look at the results.
query =
'''
SELECT ppt.company, ppt.state, max(ppt.complaint_count) AS complaint_count
FROM (SELECT company, state, zip_code, count(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank' AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC) ppt
GROUP BY ppt.company, ppt.state
ORDER BY 3 DESC
LIMIT 10;
'''
run_query(query)| company | state | complaint_count | |
|---|---|---|---|
| 0 | Citibank | NY | 80 |
| 1 | Citibank | TX | 67 |
| 2 | Citibank | CA | 58 |
| 3 | Citibank | GA | 46 |
| 4 | Citibank | IL | 44 |
| 5 | Citibank | NJ | 44 |
| 6 | Citibank | FL | 39 |
| 7 | Citibank | VA | 32 |
| 8 | Citibank | MD | 32 |
| 9 | Citibank | DC | 31 |
Next, let’s continue to expand on our query and return the state and zip code with the highest number of complaints.
 This is a complex query, so let’s look at it one subquery at a time.
This is a complex query, so let’s look at it one subquery at a time.
- We start with our first subquery in purple, which counts the number of complaints grouped by
company,stateandzip_code. - Next, we join the results to a subquery that contains two more subqueries. Remembering that we need to read subqueries from the inside out, let’s look at these one at a time:
- Our innermost subquery in orange we have seen before. It’s the first query from this section that selects complaint numbers for Citibank grouped by
stateandzip_code. - Our next subquery in blue we’ve also seen before, it’s the outer query from our last example, minus the
LIMITstatement. - Our outermost subquery in red finds just the maximum complaint count from all states/zip-codes.
- Our innermost subquery in orange we have seen before. It’s the first query from this section that selects complaint numbers for Citibank grouped by
query =
'''
SELECT ens.company, ens.state, ens.zip_code, ens.complaint_count
FROM (SELECT company, state, zip_code, COUNT(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE state IS NOT NULL
GROUP BY company, state, zip_code) ens
INNER JOIN
(SELECT ppx.company, MAX(ppx.complaint_count) AS complaint_count
FROM (SELECT ppt.company, ppt.state, MAX(ppt.complaint_count) AS complaint_count
FROM (SELECT company, state, zip_code, COUNT(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank' AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC) ppt
GROUP BY ppt.company, ppt.state
ORDER BY 3 DESC) ppx
GROUP BY ppx.company) apx
ON apx.company = ens.company AND apx.complaint_count = ens.complaint_count
ORDER BY 4 DESC;
'''
run_query(query)| company | state | zip_code | complaint_count | |
|---|---|---|---|---|
| 0 | Citibank | NY | 100XX | 80 |
Finally, we can remove the company filter from the innermost (orange) subquery so that we can see the state and zip code where each company receives the most complaints, and how many complaints they’ve received.
query =
'''
SELECT ens.company, ens.state, ens.zip_code, ens.complaint_count
FROM (SELECT company, state, zip_code, COUNT(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE state IS NOT NULL
GROUP BY company, state, zip_code) ens
INNER JOIN
(SELECT ppx.company, MAX(ppx.complaint_count) AS complaint_count
FROM (SELECT ppt.company, ppt.state, MAX(ppt.complaint_count) AS complaint_count
FROM (SELECT company, state, zip_code, COUNT(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank' AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC) ppt
GROUP BY ppt.company, ppt.state
ORDER BY 3 DESC) ppx
GROUP BY ppx.company) apx
ON apx.company = ens.company AND apx.complaint_count = ens.complaint_count
ORDER BY 4 DESC;
'''
run_query(query)| company | state | zip_code | complaint_count | |
|---|---|---|---|---|
| 0 | Citibank | NY | 100XX | 80 |
| 1 | JPMorgan Chase & Co. | NY | 100XX | 44 |
| 2 | Amex | NY | 100XX | 43 |
| 3 | Bank of America | NY | 10024 | 34 |
| 4 | Capital One | NY | 112XX | 30 |
| 5 | Capital One | GA | 300XX | 30 |
| 6 | Synchrony Financial | NY | 112XX | 29 |
| 7 | Barclays PLC | FL | 337XX | 28 |
| 8 | Discover | MN | 551XX | 19 |
| 9 | U.S. Bancorp | DC | 200XX | 19 |
Now we can see which companies receive the most complaints, and where the most complaints are generated from!
Casting Data Types
Sometimes you’ll need to change a field’s data type on the fly. For example, if the field
Age is has a text data type, but you need it to be a numeric data type so that you can perform calculations on that data, you can simply use the CAST() function to temporarily accommodate for the calculation you’re trying to perform. To cast a field to a new data type, we use the following syntax:
CAST(source_column AS type);Each data type may or may not have additional required parameters, so please check the documentation for your current version of PostgreSQL to be sure. When we created our tables earlier, we declared the complaint_id field as our primary key. However, we declared the data type as text. Let’s assume we want to create a view by querying this table, but want to add an index on complaint_id for increased performance. Indexing on numeric data types is faster than string (text) data types, simply because they take up less space. So let’s first run a simple query on the bank_account_complaints table to return the complaint_id as a float data type.
query =
'''
SELECT CAST(complaint_id AS float) AS complaint_id
FROM bank_account_complaints LIMIT 10;
'''
run_query(query)| complaint_id | |
|---|---|
| 0 | 468889.0 |
| 1 | 468879.0 |
| 2 | 468949.0 |
| 3 | 468981.0 |
| 4 | 469185.0 |
| 5 | 475273.0 |
| 6 | 469309.0 |
| 7 | 469414.0 |
| 8 | 469446.0 |
| 9 | 469447.0 |
Next, let’s test our query that we’re going to use to define our new view. Our query should pull all of the fields’ values for Wells Fargo (company = ‘Wells Fargo & Company’) in the state of California (state = ‘CA’) where the consumer did not dispute the company’s response (consumer_disputed = ‘No’).
query =
'''
SELECT CAST(complaint_id AS int) AS complaint_id,
date_received, product, sub_product, issue, company,
state, zip_code, submitted_via, date_sent, company_response_to_consumer,
timely_response, consumer_disputed
FROM bank_account_complaints
WHERE state = 'CA'
AND consumer_disputed = 'No'
AND company = 'Wells Fargo & Company'
LIMIT 5;
'''
run_query(query)| complaint_id | date_received | product | sub_product | issue | company | state | zip_code | submitted_via | date_sent | company_response_to_consumer | timely_response | consumer_disputed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 468889 | 2013-07-29 | Bank account or service | Checking account | Using a debit or ATM card | Wells Fargo & Company | CA | 95992 | Web | 2013-07-31 | Closed with explanation | Yes | No |
| 1 | 469185 | 2013-07-29 | Bank account or service | Other bank product/service | Deposits and withdrawals | Wells Fargo & Company | CA | 96088 | Web | 2013-08-01 | Closed with explanation | Yes | No |
| 2 | 469446 | 2013-07-29 | Bank account or service | Checking account | Deposits and withdrawals | Wells Fargo & Company | CA | 92277 | Web | 2013-08-05 | Closed with explanation | Yes | No |
| 3 | 471075 | 2013-07-31 | Bank account or service | Savings account | Account opening, closing, or management | Wells Fargo & Company | CA | 91214 | Web | 2013-08-02 | Closed with explanation | Yes | No |
| 4 | 463525 | 2013-07-22 | Bank account or service | Other bank product/service | Account opening, closing, or management | Wells Fargo & Company | CA | 95376 | Phone | 2013-07-30 | Closed with explanation | Yes | No |
Now let’s create our new view named wells_complaints_v.
command =
'''
CREATE VIEW wells_complaints_v AS (
SELECT CAST(complaint_id AS int) AS complaint_id,
date_received, product, sub_product, issue, company,
state, zip_code, submitted_via, date_sent,
company_response_to_consumer,
timely_response, consumer_disputed
FROM bank_account_complaints
WHERE state = 'CA'
AND consumer_disputed = 'No'
AND company = 'Wells Fargo & Company')
'''
run_command(command)'CREATE VIEW'SQL Challenges
Learning the fundamentals of SQL is relatively straight-forward. However, learning the syntax and memorizing all the concepts that are typically taught in SQL tutorials or database classes, is just the tip of the iceberg. Your ability to apply the concepts that you’ve learned thus far, and translating a set of requirements by leveraging your critical thinking and problem solving skills is the most important piece of the puzzle. With that said, subsequent sections will consist different scenarios that will include a short list of requirements. All scenarios are using the same database tables/views that were created during this tutorial. The solutions to all scenarios are posted at the end of this section.
Challenge 1
- Return a unique list of companies (
company), along with the total number of records associated a distinct company name (company_amt) from thecredit_card_complaintstable. - Sort by the
company_amtfield, from greatest to least. - Output Sample:
| company | company_amt |
|---|---|
| Citibank | 16561 |
| Capital One | 12740 |
| JPMorgan Chase & Co. | 10203 |
| Bank of America | 8995 |
| Synchrony Financial | 8637 |
Challenge 2
- Build on the query created in Challenge 1, adding a third column (
total) that reflects the total number of records in thecredit_card_complaintstable. Each row should contain the same number. - Output Sample:
| company | company_amt | total |
|---|---|---|
| Citibank | 16561 | 87718 |
| Capital One | 12740 | 87718 |
| JPMorgan Chase & Co. | 10203 | 87718 |
| Bank of America | 8995 | 87718 |
| Synchrony Financial | 8637 | 87718 |
Challenge 3
- Build on the query created in Challenge 2, adding a a fourth column (
percent) that reflects the percentage of records associated with each company in thecredit_card_complaintstable. - Output Sample:
| company | company_amt | total | percent |
|---|---|---|---|
| Citibank | 16561 | 87718 | 18.879819 |
| Capital One | 12740 | 87718 | 14.523815 |
| JPMorgan Chase & Co. | 10203 | 87718 | 11.631592 |
| Bank of America | 8995 | 87718 | 10.254452 |
| Synchrony Financial | 8637 | 87718 | 9.846326 |
Solutions – SQL Challenges
Here are the solutions to each challenge.
Solution 1
SELECT company, COUNT(company) AS company_amt
FROM credit_card_complaints
GROUP BY company
ORDER BY 2 DESC;Solution 2
SELECT company, COUNT(company) as company_amt,
(SELECT COUNT(*) FROM credit_card_complaints) AS total
FROM credit_card_complaints
GROUP BY company
ORDER BY 2 DESC;Solution 3
SELECT ppg.company, ppg.company_amt, ppg.total,
((CAST(ppg.company_amt AS double precision) / CAST(ppg.total AS double precision)) * 100) AS percent
FROM (SELECT company, COUNT(company) as company_amt, (SELECT COUNT(*) FROM credit_card_complaints) AS total
FROM credit_card_complaints
GROUP BY company
ORDER BY 2 DESC) ppg;Next Steps
In this tutorial we’ve analyzed financial services consumer complaints data while learning the intermediate concepts of SQL, including:
- Creating users, databases and tables,
- The
IS NULL/IS NOT NULLclause, - Views,
- Subqueries,
- Union/union all,
- Intersect/except,
- String concatenation, and
- Casting data types.
Although we covered each concept in great detail and even tested our knowledge with the SQL scenario problems, it’s important that you practice each concept on your own. You can do this by coming up with your own scenarios using the data and then writing queries to return that data. If you’d like to dive into SQL in more detail, you can sign up for free and check out our interactive course Intermediate SQL for Data Analysis which covers a lot of the content taught in this tutorial and more.