Setting Up Apache Airflow with Docker Locally (Part I)
Let’s imagine this: you’re a data engineer working for a company that relies heavily on data. Your everyday job? Extract data, transform it, and load it somewhere, maybe a database, maybe a dashboard, maybe a cloud storage system.
At first, you probably set all this up on your local machine. You write a script that scrapes data, another one that cleans and transforms it, and yet another that uploads it to a destination like Amazon S3. Sounds manageable, right?
But soon, things start piling up:
- The data source keeps changing → you need to update your script regularly.
- The machine shuts down → you have to restart tasks manually.
- You forget to run it → quickly, your data is out of date.
- A minor bug crashes your transformation step → your whole pipeline fails.
Now, you’re stuck in a never-ending ETL loop. Every failure, every delay, every update falls back on you. It’s exhausting, and it’s not scalable.
But what if the cloud could run this entire pipeline for you—automatically, reliably, and 24/7?
In our previous tutorials, we explored what cloud computing is, the different service models (IaaS, PaaS, SaaS), cloud deployment models, and cloud providers (AWS, Azure, GCP). Now, it’s time to put all that theory into practice.
In this tutorial, we’ll begin building a simple data pipeline using Apache Airflow, with tasks for extracting, transforming, and loading data into Amazon S3. This first part focuses entirely on developing and testing the pipeline locally using Docker Compose.
In the second part, we’ll configure the necessary cloud infrastructure on AWS. This will include an S3 bucket for storage, RDS PostgreSQL for Airflow metadata, IAM roles and security groups for secure access, and an Application Load Balancer to expose the Airflow UI.
The final part of the series walks you through running Airflow in containers on Amazon ECS (Fargate). You’ll learn how to define ECS tasks and services, push your custom Docker image to Amazon ECR, launch background components like the scheduler and triggerer, and deploy a fully functioning Airflow web interface that runs reliably in the cloud.
By the end, you’ll have a production-ready, cloud-hosted Airflow environment that runs your workflows automatically, scales with your workload, and frees you from manual task orchestration.
Feel free to check out our Intro to Docker Compose and Advanced Concepts in Docker Compose tutorials if you'd like a bit more background on using Docker Compose before getting into this tutorial series.
Why Apache Airflow and Why Use Docker?
Before we jump into building your first ETL project, let’s clarify what Apache Airflow is and why it’s the right tool for the job.
Apache Airflow is an open-source platform for authoring, scheduling, and monitoring data workflows.
Instead of chaining together standalone scripts or relying on fragile cron jobs, you define your workflows using Python as a DAG (Directed Acyclic Graph). This structure clearly describes how tasks are connected, in what order they run, and how they handle retries and failures.
Airflow provides a centralized way to automate, visualize, and manage complex data pipelines. It tracks every task execution, provides detailed logs and statuses, and offers a powerful web UI to interact with your workflows. Whether you're scraping data from the web, transforming files, uploading to cloud storage, or triggering downstream systems. Airflow can coordinate all these tasks in a reliable, scalable, and transparent way.
Prerequisites: What You’ll Need Before You Start
Before we dive into setting up Airflow project, make sure the following tools are installed and working on your system:
- Docker Desktop – Required to build and run your Airflow environment locally using containers. Check out our post for an Introduction to Docker and Docker Comose if they're completely new to you.
- Code editor, e.g., Visual Studio Code – For writing DAGs, editing configuration files, and running terminal commands.
- Python 3.8+ – Airflow DAGs and helper scripts are written in Python. Make sure Python is installed and available in your terminal or command prompt.
- AWS CLI – We’ll use this later in parts two and three of this tutorial series to authenticate, manage AWS services, and deploy resources from the command line.
Running Airflow Using Docker
Alright, now that we’ve got our tools ready, let’s get Airflow up and running on your machine.
We'll use Docker Compose, which acts like a conductor for all the Airflow services. It ensures everything (the scheduler, API server, database, DAG processor, triggerer) starts together and can communicate properly.
And don’t worry because this setup is lightweight and perfect for local development and testing. Later on, we’ll move the entire pipeline to the cloud.
What Is Docker?
Docker is a platform that lets you package applications and their dependencies into portable, isolated environments called containers. These containers run consistently on any system, so your Airflow setup will behave the same whether you're on Windows, macOS, or Linux.
Why Are We Using Docker?
Have you ever installed a tool or Python package that worked perfectly… until you tried it on another machine?
That’s exactly why we’re using Docker. It keeps everything—code, dependencies, config—inside isolated containers so your Airflow project works the same no matter where you run it.
Step 1: Let’s Create a Project Folder
First, open VS Code (or your preferred terminal), and set up a clean folder to hold your Airflow files:
mkdir airflow-docker && cd airflow-dockerThis folder will eventually hold your DAGs, logs, and plugins as you build out your Airflow project.
Step 2: Get the Official docker-compose.yaml File
The Apache Airflow team provides a ready-to-go Docker Compose file. Let’s download it:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/3.0.1/docker-compose.yaml'This file describes everything we need to run: the scheduler (which triggers your tasks based on the DAG schedule), the API server (your web UI), a SQLite database, the triggerer (used for deferrable tasks and efficient wait states), and the DAG processor (which parses and monitors your DAG files in the background). You can confirm this by exploring the docker-compose.yaml file generated in your airflow-docker project directory.
Pretty neat, right?
Step 3: Create the Needed Folders
Now, we need to make sure Airflow has the folders it expects. These will be mounted into the Docker containers:
mkdir -p ./dags ./logs ./plugins ./configdags/→ where you’ll put your pipeline codelogs/→ for task logsplugins/→ for any custom Airflow pluginsconfig/→ for extra settings, if needed
Step 4: Set the User ID
If you're on Linux, this step avoids permission issues when Docker writes files to your local system.
Run:
echo -e "AIRFLOW_UID=$(id -u)" > .envIf you’re on macOS or Windows, you may get a warning that AIRFLOW_UID is not set. To fix this, create a .env file in the same directory as your docker-compose.yaml and add:
AIRFLOW_UID=50000Step 5: Initialize the Database
Before anything works, Airflow needs to set up its metadata database. This is where it tracks tasks, runs, and logs. Make sure Docker Desktop is launched and running in the background (just open the app, no terminal commands are needed).
Run:
docker compose up airflow-initAfter running this command, you’ll see a bunch of logs scroll by. Once it finishes, it’ll say something like Admin user airflow created.
These are your default login credentials:
- Username:
airflow - Password:
airflow
Step 6: Time to Launch!
Let’s start the whole environment:
docker compose up -dThis will start all services: the api-server, scheduler, triggerer, and dag-processor.
Once everything’s up, open your browser and go to:
http://localhost:8080You should see the Airflow UI. Go ahead and log in. And that’s it! You now have Apache Airflow running locally.
You should also see all your containers running and hopefully marked as healthy.
If something keeps restarting or your local localhost page fails to load, you probably need to allocate more memory to Docker—at least 4 GB, but 8 GB is even better. You can change this in Docker Desktop under
Settings > Resources. On Windows, if you don’t see the memory allocation option there, you may need to switch Docker to use Hyper-V instead of WSL.Before switching, press Windows + R, type
optionalfeatures, and ensure both Hyper-V and Virtual Machine Platform are checked. Click OK and restart your computer if prompted.Then open Docker Desktop, go to Settings → General, uncheck “Use the WSL 2 based engine”, and restart Docker when prompted.
Configuring the Airflow Project
Now that Airflow is up and running, let’s customize it a bit. We'll start with a clean environment and set it up to match our needs.
When you first open the Airflow UI, you’ll notice a bunch of example DAGs. They’re helpful, but we won’t be using them. Let’s clean them out.
Disable Example DAGs and Switch to LocalExecutor
First, shut everything down cleanly:
docker compose down -vNext, open your docker-compose.yaml and find this line under environment::
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'Change 'true' to 'false'. This disables the default example DAGs.
Now, we’re not using CeleryExecutor in this project. We’ll keep things simple with LocalExecutor. So change this line:
AIRFLOW__CORE__EXECUTOR: CeleryExecutorto:
AIRFLOW__CORE__EXECUTOR: LocalExecutorRemove Celery and Redis Config
Since we have changed our executor from Celery to Local, we will delete all Celery-related components from the setup. LocalExecutor runs tasks in parallel on a single machine without needing a distributed task queue. Celery requires additional services like Redis, workers, and Flower, which add unnecessary complexity and overhead. Removing them results in a simpler, lighter setup that matches our production architecture. Let’s delete all related parts from the docker-compose.yaml:
- Any
AIRFLOW__CELERY__...lines inenvironment. - The
airflow-workerservice (used by Celery). - The optional
flowerservice (Celery dashboard).
Use CTRL + F to search for celery and redis, and remove each related block.
This leaves us with a leaner setup, perfect for local development using LocalExecutor.
Creating Our First DAG
With the cleanup done, let’s now create a real DAG that simulates an end-to-end ETL workflow.
This DAG defines a simple yet creative 3-step pipeline:
- Generate mock event data (simulating a daily data scrape)
- Transform the data by sorting it based on intensity and saving it to a new CSV
- Load the final CSV file into Amazon S3
In the dags/ directory, create a new Python file named our_first_dag.py and paste the DAG code into that file.
This DAG uses PythonOperator for all three tasks and writes intermediate files to a local directory (/opt/airflow/tmp) inside the container. You should not worry about S3 setup in task 3 at this point. The bucket and role permissions will be configured later in the tutorial.
Here’s the code:
from airflow import DAG
from datetime import datetime, timedelta
from airflow.operators.python import PythonOperator
import os
import pandas as pd
import random
import boto3
default_args = {
'owner': 'your-name',
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
output_dir = '/opt/airflow/tmp'
raw_file = 'raw_events.csv'
transformed_file = 'transformed_events.csv'
raw_path = os.path.join(output_dir, raw_file)
transformed_path = os.path.join(output_dir, transformed_file)
# Task 1: Generate dynamic event data
def generate_fake_events():
events = [
"Solar flare near Mars", "New AI model released", "Fusion milestone","Celestial event tonight", "Economic policy update", "Storm in Nairobi",
"New particle at CERN", "NASA Moon base plan", "Tremors in Tokyo", "Open-source boom"
]
sample_events = random.sample(events, 5)
data = {
"timestamp": [datetime.now().strftime("\%Y-\%m-\%d \%H:\%M:\%S") for _ in sample_events],
"event": sample_events,
"intensity_score": [round(random.uniform(1, 10), 2) for _ in sample_events],
"category": [random.choice(["Science", "Tech", "Weather", "Space", "Finance"]) for _ in sample_events]
}
df = pd.DataFrame(data)
os.makedirs(output_dir, exist_ok=True)
df.to_csv(raw_path, index=False)
print(f"[RAW] Saved to {raw_path}")
# Task 2: Transform data and save new CSV
def transform_and_save_csv():
df = pd.read_csv(raw_path)
# Sort by intensity descending
df_sorted = df.sort_values(by="intensity_score", ascending=False)
# Save transformed CSV
df_sorted.to_csv(transformed_path, index=False)
print(f"[TRANSFORMED] Sorted and saved to {transformed_path}")
# Task 3: Upload to S3
def upload_to_s3(**kwargs):
run_date = kwargs['ds']
bucket_name = 'your-bucket-name'
s3_key = f'your-directory-name/events_transformed_{run_date}.csv'
s3 = boto3.client('s3')
s3.upload_file(transformed_path, bucket_name, s3_key)
print(f"Uploaded to s3://{bucket_name}/{s3_key}")
# DAG setup
with DAG(
dag_id="daily_etl_pipeline_with_transform",
default_args=default_args,
description='Simulate a daily ETL flow with transformation and S3 upload',
start_date=datetime(2025, 5, 24),
schedule='@daily',
catchup=False,
) as dag:
task_generate = PythonOperator(
task_id='generate_fake_events',
python_callable=generate_fake_events
)
task_transform = PythonOperator(
task_id='transform_and_save_csv',
python_callable=transform_and_save_csv
)
task_upload = PythonOperator(
task_id='upload_to_s3',
python_callable=upload_to_s3,
)
# Task flow
task_generate >> task_transform >> task_uploadUnderstanding What’s Happening
This DAG simulates a complete ETL process:
It generates mock event data, transforms it by sorting based on intensity, and it should upload the final CSV to an S3 bucket.
The DAG is defined using with DAG(...) as dag:, which wraps all the tasks and metadata related to this workflow. Within this block:
dag_id="daily_etl_pipeline_with_transform"assigns a unique name for Airflow to track this workflow.start_date=datetime(2025, 5, 24)sets when the DAG should start running.schedule='@daily'tells Airflow to trigger the DAG once every day.catchup=Falseensures that only the current day’s run is triggered when the DAG is deployed, rather than retroactively running for all past dates.
This line task_generate >> task_transform >> task_upload defines the execution order of tasks, ensuring that data is generated first, then transformed, and finally uploaded to S3 in a sequential flow.
PythonOperatoris used to link your custom Python functions (like generating data or uploading to S3) to actual Airflow tasks that the scheduler can execute.
We haven’t configured the S3 bucket yet, so you can temporarily comment out the upload_to_s3 task (and don’t forget to remove >> task_upload from the task sequence). We’ll return to this step after setting up the AWS bucket and permissions in the second part of this tutorial.
Run It and See It in Action
Now restart Airflow:
docker compose up -dThen open:
You should now see daily_etl_pipeline_with_transform listed in the UI. Turn it on, then trigger it manually from the top-right corner.
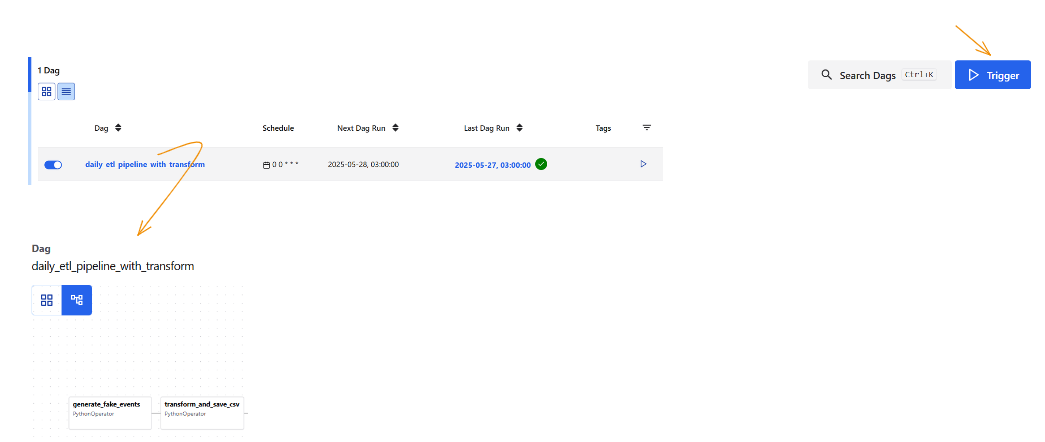
Click into each task to see its logs and verify that everything ran as expected.
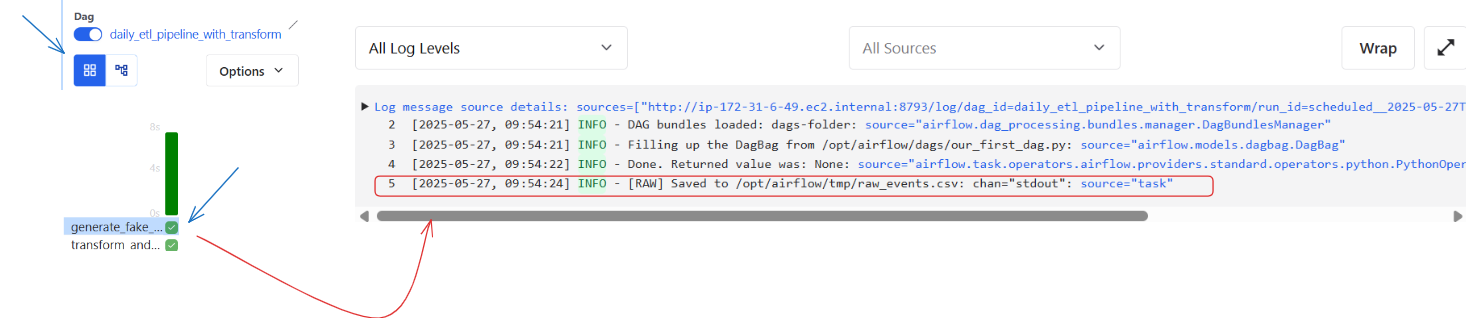
And just like that, you’ve written and run your first real DAG!
Wrap-Up & What’s Next
You’ve now set up Apache Airflow locally using Docker, configured it for lightweight development, and built your first real DAG to simulate an ETL process—from generating event data, to transforming it, and preparing it for cloud upload. This setup gives you a solid foundation in DAG structure, Airflow components, and local testing practices. It also highlights the limits of local workflows and why cloud-based orchestration is essential for reliability and scalability.
In Part II: Cloud Setup for Airflow of this tutorial series, we’ll move to the cloud. You’ll learn how to configure AWS infrastructure to support your pipeline. This will include setting up an S3 bucket, RDS for metadata, IAM roles, and security groups. You’ll also build a production-ready Docker image and push it to Amazon ECR, preparing for full deployment on Amazon ECS. By the end of Part 2, your pipeline will be ready to run in a secure, scalable, and automated cloud environment.
In Part III: Deploying Airflow to AWS ECS, you'll complete the cloud transition by deploying your entire Airflow environment to Amazon ECS using Fargate. You'll create custom Docker images with your DAGs embedded, configure ECS task definitions and services, and launch persistent background components like the scheduler, triggerer, and DAG processor. By the end of Part 3, you'll have a fully production-ready, cloud-native orchestration system that runs automatically and reliably—accessible from anywhere through your Application Load Balancer, with no dependency on your local machine.
