Pandas Tutorial: Data analysis with Python: Part 2
1058 online survey responses collected by FiveThirtyEight. Each survey respondent was asked questions about what they typically eat for Thanksgiving, along with some demographic questions, like their gender, income, and location. This dataset will allow us to discover regional and income-based patterns in what Americans eat for Thanksgiving dinner. As we explore the data and try to find patterns, we'll be heavily using the grouping and aggregation functionality of pandas. 
We're very into Thanksgiving dinner in America. Just as a note, we'll be using Python 3.5 and Jupyter Notebook to do our analysis.
Reading in and summarizing the data
Our first step is to read in the data and do some preliminary exploration. This will help us figure out how we want to approach creating groups and finding patterns. As you may recall from part one of this tutorial, we can read in the data using the
pandas.read_csv function. The data is stored using Latin-1 encoding, so we additionally need to specify the encoding keyword argument. If we don't, pandas won't be able to load in the data, and we'll get an error:
import pandas as pd
data = pd.read_csv("thanksgiving-2015-poll-data.csv", encoding="Latin-1")
data.head()As you can see above, the data has
65 columns of mostly categorical data. For example, the first column appears to allow for Yes and No responses only. Let's verify by using the pandas.Series.unique method to see what unique values are in the Do you celebrate Thanksgiving? column of data:
data["Do you celebrate Thanksgiving?"].unique()array(['Yes', 'No'], dtype=object)We can also view all the column names to see all of the survey questions. We'll truncate the output below to save you from having to scroll:
data.columns[50:]
Index(['Which of these desserts do you typically have at Thanksgiving dinner? Please select all that apply. - Other (please specify).1', 'Do you typically pray before or after the Thanksgiving meal?','How far will you travel for Thanksgiving?','Will you watch any of the following programs on Thanksgiving? Please select all that apply. - Macy's Parade','What's the age cutoff at your "kids' table" at Thanksgiving?','Have you ever tried to meet up with hometown friends on Thanksgiving night?','Have you ever attended a "Friendsgiving?"','Will you shop any Black Friday sales on Thanksgiving Day?','Do you work in retail?','Will you employer make you work on Black Friday?', 'How would you describe where you live?', 'Age', 'What is your gender?', 'How much total combined money did all members of your HOUSEHOLD earn last year?', 'US Region'],
dtype='object')
Using this Thanksgiving survey data, we can answer quite a few interesting questions, like:
- Do people in Suburban areas eat more Tofurkey than people in Rural areas?
- Where do people go to Black Friday sales most often?
- Is there a correlation between praying on Thanksgiving and income?
- What income groups are most likely to have homemade cranberry sauce?
In order to answer these questions and others, we'll first need to become familiar with applying, grouping and aggregation in Pandas.
Applying functions to Series in pandas
There are times when we're using pandas that we want to apply a function to every row or every column in the data. A good example is getting from the values in our
What is your gender? column to numeric values. We'll assign 0 to Male, and 1 to Female. Before we dive into transforming the values, let's confirm that the values in the column are either Male or Female. We can use the pandas.Series.value_counts method to help us with this. We'll pass the dropna=False keyword argument to also count missing values:
data["What is your gender?"].value_counts(dropna=False)
Female 544
Male 481
NaN 33
Name: What is your gender?, dtype: int64As you can see, not all of the values are
Male or Female. We'll preserve any missing values in the final output when we transform our column. Here's a diagram of the input and outputs we need: 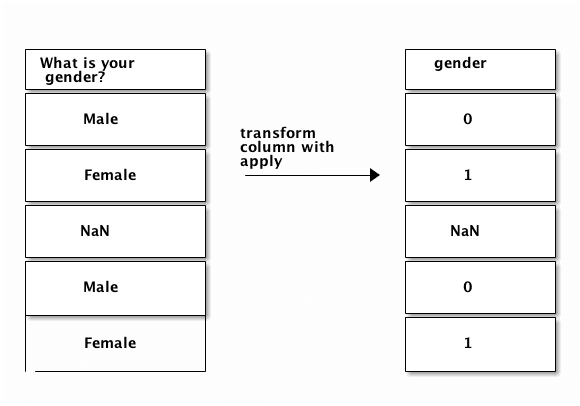 We'll need to apply a custom function to each value in the
We'll need to apply a custom function to each value in the What is your gender? column to get the output we want. Here's a function that will do the transformation we want:
import math
def gender_code(gender_string):
if isinstance(gender_string, float) and math.isnan(gender_string):
return gender_string
return int(gender_string == "Female")In order to apply this function to each item in the
What is your gender? column, we could either write a for loop, and loop across each element in the column, or we could use the pandas.Series.apply method. This method will take a function as input, then return a new pandas Series that contains the results of applying the function to each item in the Series. We can assign the result back to a column in the data DataFrame, then verify the results using value_counts:
data["gender"] = data["What is your gender?"].apply(gender_code)
data["gender"].value_counts(dropna=False)1.0 544
0.0 481
NaN 33
Name: gender, dtype: int64
Applying functions to DataFrames in pandas
We can use the
apply method on DataFrames as well as Series. When we use the pandas.DataFrame.apply method, an entire row or column will be passed into the function we specify. By default, apply will work across each column in the DataFrame. If we pass the axis=1 keyword argument, it will work across each row. In the below example, we check the data type of each column in data using a lambda function. We also call the head method on the result to avoid having too much output:
data.apply(lambda x: x.dtype).head()
RespondentID object
Do you celebrate Thanksgiving? object
What is typically the main dish at your Thanksgiving dinner? object
What is typically the main dish at your Thanksgiving dinner? - Other (please specify) object
How is the main dish typically cooked? object
dtype: object
Using the apply method to clean up income
We can now use what we know about the
apply method to clean up the How much total combined money did all members of your HOUSEHOLD earn last year? column. Cleaning up the income column will allow us to go from string values to numeric values. First, let's see all the unique values that are in the How much total combined money did all members of your HOUSEHOLD earn last year? column:
data["How much total combined money did all members of your HOUSEHOLD earn last year?"].value_counts(dropna=False)
$25,000 to $49,999 180
Prefer not to answer 136
$50,000 to $74,999 135
$75,000 to $99,999 133
$100,000 to $124,999 111
$200,000 and up 80
$10,000 to $24,999 68
$0 to $9,999 66
$125,000 to $149,999 49
$150,000 to $174,999 40
NaN 33
$175,000 to $199,999 27
Name: How much total combined money did all members of your HOUSEHOLD earn last year?, dtype: int64Looking at this, there are
4 different patterns for the values in the column:
-
X to Y— an example is$25,000 to $49,999.- We can convert this to a numeric value by extracting the numbers and averaging them.
-
NaN-
We'll preserve
NaNvalues, and not convert them at all.
-
We'll preserve
-
X and up— an example is$200,000 and up.- We can convert this to a numeric value by extracting the number.
-
Prefer not to answer-
We'll turn this into an
NaNvalue.
-
We'll turn this into an
Here is how we want the transformations to work:
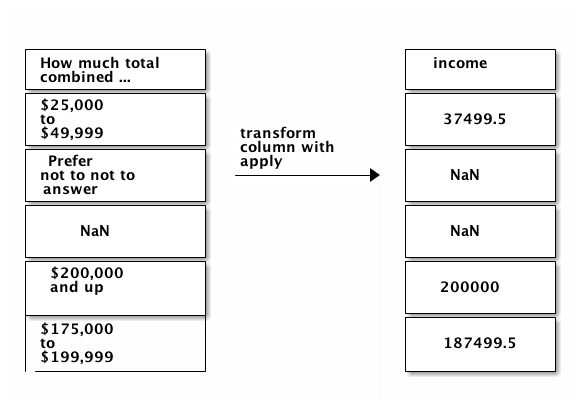 We can write a function that covers all of these cases. In the below function, we:
We can write a function that covers all of these cases. In the below function, we:
-
Take a string called
valueas input. -
Check to see if
valueis$200,000 and up, and return200000if so. -
Check if
valueisPrefer not to answer, and returnNaNif so. -
Check if
valueisNaN, and returnNaNif so. -
Clean up
valueby removing any dollar signs or commas. - Split the string to extract the incomes, then average them.
import numpy as np
def clean_income(value):
if value == "$200,000 and up":
return 200000
elif value == "Prefer not to answer":
return np.nan
elif isinstance(value, float) and math.isnan(value):
return np.nan
value = value.replace(",", "").replace("
income_high, income_low = value.split(" to ")
return (int(income_high) + int(income_low)) / 2
After creating the function, we can apply it to the
How much total combined money did all members of your HOUSEHOLD earn last year? column:
data["income"] = data["How much total combined money did all members of your HOUSEHOLD earn last year?"].apply(clean_income)
data["income"].head()0 87499.5
1 62499.5
2 4999.5
3 200000.0
4 112499.5
Name: income, dtype: float64
Grouping data with pandas
Now that we've covered applying functions, we can move on to grouping data using pandas. When performing data analysis, it's often useful to explore only a subset of the data. For example, what if we want to compare income between people who tend to eat homemade cranberry sauce for Thanksgiving vs people who eat canned cranberry sauce? First, let's see what the unique values in the column are:
data["What type of cranberry saucedo you typically have?"].value_counts()
Canned 502
Homemade 301
None 146
Other (please specify) 25
Name: What type of cranberry sauce do you typically have?, dtype: int64We can now filter
data to get two DataFrames that only contain rows where the What type of cranberry saucedo you typically have? is Canned or Homemade, respectively:
homemade = data[data["What type of cranberry saucedo you typically have?"] == "Homemade"]
canned = data[data["What type of cranberry saucedo you typically have?"] == "Canned"]Finally, we can use the
pandas.Series.mean method to find the average income in homemade and canned:
print(homemade["income"].mean())
print(canned["income"].mean())94878.1072874
83823.4034091We get our answer, but it took more lines of code than it should have. What if we now want to compute the average income for people who didn't have cranberry sauce? An easier way to find groupwise summary statistics with pandas is to use the
pandas.DataFrame.groupby method. This method will split a DataFrame into groups based on a column or set of columns. We'll then be able to perform computations on each group. Here's how splitting data based on the What type of cranberry saucedo you typically have? column would look:  Note how each resulting group only has a single unique value in the
Note how each resulting group only has a single unique value in the What type of cranberry saucedo you typically have? column. One group is created for each unique value in the column we choose to group by. Let's create groups from the What type of cranberry saucedo you typically have? column:
grouped = data.groupby("What type of cranberry saucedo you typically have?")
grouped<pandas.core.groupby.DataFrameGroupBy object at 0x10a22cc50>As you can see above, the
groupby method returns a DataFrameGroupBy object. We can call the pandas.GroupBy.groups method to see what value for the What type of cranberry sauce do you typically have? column is in each group:
grouped.groups{'Canned': Int64Index([ 4, 6, 8, 11, 12, 15, 18, 19, 26, 27,
...
1040, 1041, 1042, 1044, 1045, 1046, 1047, 1051, 1054, 1057],
dtype='int64', length=502),
'Homemade': Int64Index([ 2, 3, 5, 7, 13, 14, 16, 20, 21, 23,
...
1016, 1017, 1025, 1027, 1030, 1034, 1048, 1049, 1053, 1056],
dtype='int64', length=301),
'None': Int64Index([ 0, 17, 24, 29, 34, 36, 40, 47, 49, 51,
...
980, 981, 997, 1015, 1018, 1031, 1037, 1043, 1050, 1055],
dtype='int64', length=146),
'Other (please specify)': Int64Index([ 1, 9, 154, 216, 221, 233, 249, 265, 301, 336, 380,
435, 444, 447, 513, 550, 749, 750, 784, 807, 860, 872,
905, 1000, 1007],
dtype='int64')}We can call the
pandas.GroupBy.size method to see how many rows are in each group. This is equivalent to the value_counts method on a Series:
grouped.size()What type of cranberry sauce do you typically have?
Canned 502
Homemade 301
None 146
Other (please specify) 25
dtype: int64We can also use a loop to manually iterate through the groups:
for name, group in grouped:
print(name)
print(group.shape)
print(type(group))
Canned
(502, 67)
<class 'pandas.core.frame.DataFrame'>
Homemade
(301, 67)
<class 'pandas.core.frame.DataFrame'>
None
(146, 67)
<class 'pandas.core.frame.DataFrame'>
Other (please specify)
(25, 67)
<class 'pandas.core.frame.DataFrame'>As you can see above, each group is a DataFrame, and you can use any normal DataFrame methods on it. We can also extract a single column from a group. This will allow us to perform further computations just on that specific column:
grouped["income"]<pandas.core.groupby.SeriesGroupBy object at 0x1081ef390>As you can see above, this gives us a
SeriesGroupBy object. We can then call the normal methods we can call on a DataFrameGroupBy object:
grouped["income"].size()What type of cranberry sauce do you typically have?
Canned 502
Homemade 301
None 146
Other (please specify) 25
dtype: int64
Aggregating values in groups
If all we could do was split a DataFrame into groups, it wouldn't be of much use. The real power of groups is in the computations we can do after creating groups. We do these computations through the
pandas.GroupBy.aggregate method, which we can abbreviate as agg. This method allows us to perform the same computation on every group. For example, we could find the average income for people who served each type of cranberry sauce for Thanksgiving (Canned, Homemade, None, etc). In the below code, we:
-
Extract just the
incomecolumn fromgrouped, so we don't find the average of every column. -
Call the
aggmethod withnp.meanas input.- This will compute the mean for each group, then combine the results from each group.
grouped["income"].agg(np.mean)
What type of cranberry sauce do you typically have?
Canned 83823.403409
Homemade 94878.107287
None 78886.084034
Other (please specify) 86629.978261
Name: income, dtype: float64If we left out only selecting the
income column, here's what we'd get:
grouped.agg(np.mean)The above code will find the mean for each group for every column in
data. However, most columns are string columns, not integer or float columns, so pandas didn't process them, since calling np.mean on them raised an error.
Plotting the results of aggregation
We can make a plot using the results of our
agg method. This will create a bar chart that shows the average income of each category. In the below code, we:
%matplotlib inline
sauce = grouped.agg(np.mean)
sauce["income"].plot(kind="bar")<matplotlib.axes._subplots.AxesSubplot at 0x109ebacc0>
Aggregating with multiple columns
We can call
groupby with multiple columns as input to get more granular groups. If we use the What type of cranberry saucedo you typically have? and What is typically the main dish at your Thanksgiving dinner? columns as input, we'll be able to find the average income of people who eat Homemade cranberry sauce and Tofurkey, for example:
grouped = data.groupby(["What type of cranberry sauce do you typically have?", "What is typically the main dish at your Thanksgiving dinner?"])
grouped.agg(np.mean)As you can see above, we get a nice table that shows us the mean of each column for each group. This enables us to find some interesting patterns, such as:
-
People who have
TurduckenandHomemadecranberry sauce seem to have high household incomes. -
People who eat
Cannedcranberry sauce tend to have lower incomes, but those who also haveRoast Beefhave the lowest incomes. -
It looks like there's one person who has
Cannedcranberry sauce and doesn't know what type of main dish he's having.
Aggregating with multiple functions
We can also perform aggregation with multiple functions. This enables us to calculate the mean and standard deviation of a group, for example. In the below code, we find the sum, standard deviation, and mean of each group in the
income column:
grouped["income"].agg([np.mean, np.sum, np.std]).head(10)
Using apply on groups
One of the limitations of aggregation is that each function has to return a single number. While we can perform computations like finding the mean, we can't for example, call
value_counts to get the exact count of a category. We can do this using the pandas.GroupBy.apply method. This method will apply a function to each group, then combine the results. In the below code, we'll apply value_counts to find the number of people who live in each area type (Rural, Suburban, etc) who eat different kinds of main dishes for Thanksgiving:
grouped = data.groupby("How would you describe where you live?")["What is typically the main dish at your Thanksgiving dinner?"]
grouped.apply(lambda x:x.value_counts())How would you describe where you live? How would you describe where you live?
Rural Turkey 189
Other (please specify) 9
Ham/Pork 7
I don't know 3
Tofurkey 3
Turducken 2
Chicken 2
Roast beef 1
Suburban Turkey 449
Ham/Pork 17
Other (please specify) 13
Tofurkey 9
Roast beef 3
Chicken 3
Turducken 1
I don't know 1
Urban Turkey 198
Other (please specify) 13
Tofurkey 8
Chicken 7
Roast beef 6
Ham/Pork 4
Name: What is typically the main dish at your Thanksgiving dinner?, dtype: int64The above table shows us that people who live in different types of areas eat different Thanksgiving main dishes at about the same rate.
Free Pandas Cheat Sheet
If you're interested in learning more about pandas, check out our interactive course on
NumPy and pandas. You can register and do the first lessons for free. You also might like to take your pandas skills to the next level with our free pandas cheat sheet!
Further reading
In this tutorial, we learned how to use pandas to group data, and calculate results. We learned several techniques for manipulating groups and finding patterns. In the next tutorial, we'll dive more into combining and filtering DataFrames. If you want to learn more about pandas and the material covered in this tutorial, here are some resources: