Introduction to Apache Airflow
Imagine this: you’re a data engineer at a growing company that thrives on data-driven decisions. Every morning, dashboards must refresh with the latest numbers, reports need updating, and machine learning models retrain with new data.
At first, you write a few scripts, one to pull data from an API, another to clean it, and a third to load it into a warehouse. You schedule them with cron or run them manually when needed. It works fine, until it doesn’t.
As data volumes grow, scripts multiply, and dependencies become increasingly tangled. Failures start cascading, jobs run out of order, schedules break, and quick fixes pile up into fragile automation. Before long, you're maintaining a system held together by patchwork scripts and luck. That’s where data orchestration comes in.
Data orchestration coordinates multiple interdependent processes, ensuring each task runs in the correct order, at the right time, and under the right conditions. It’s the invisible conductor that keeps data pipelines flowing smoothly from extraction to transformation to loading, reliably and automatically. And among the most powerful and widely adopted orchestration tools is Apache Airflow.
In this tutorial, we’ll use Airflow as our case study to explore how workflow orchestration works in practice. You’ll learn what orchestration means, why it matters, and how Airflow’s architecture, with its DAGs, tasks, operators, scheduler, and new event-driven features- brings order to complex data systems.
By the end, you’ll understand not just how Airflow orchestrates workflows, but why orchestration itself is the cornerstone of every scalable, reliable, and automated data engineering ecosystem.
What Workflow Orchestration Is and Why It Matters
Modern data pipelines involve multiple interconnected stages, data extraction, transformation, loading, and often downstream analytics or machine learning. Each stage depends on the successful completion of the previous one, forming a chain that must execute in the correct order and at the right time.
Many data engineers start by managing these workflows with scripts or cron jobs. But as systems grow, dependencies multiply, and processes become more complex, this manual approach quickly breaks down:
- Unreliable execution: Tasks may run out of order, producing incomplete or inconsistent data.
- Limited visibility: Failures often go unnoticed until reports or dashboards break.
- Poor scalability: Adding new tasks or environments becomes error-prone and hard to maintain.
Workflow orchestration solves these challenges by automating, coordinating, and monitoring interdependent tasks. It ensures each step runs in the right sequence, at the right time, and under the right conditions, bringing structure, reliability, and transparency to data operations.
With orchestration, a loose collection of scripts becomes a cohesive system that can be observed, retried, and scaled, freeing engineers to focus on building insights rather than fixing failures.
Apache Airflow uses these principles and extends them with modern capabilities such as:
- Deferrable sensors and the triggerer: Improve efficiency by freeing workers while waiting for external events like file arrivals or API responses.
- Built-in idempotency and backfills: Safely re-run historical or failed workflows without duplication.
- Data-aware scheduling: Enable event-driven pipelines that automatically respond when new data arrives.
While Airflow is not a real-time streaming engine, it excels at orchestrating batch and scheduled workflows with reliability, observability, and control. Trusted by organizations like Airbnb, Meta, and NASA, it remains the industry standard for automating and scaling complex data workflows.
Next, we’ll explore Airflow’s core concepts, DAGs, tasks, operators, and the scheduler, to see orchestration in action.
Core Airflow Concepts
To understand how Airflow orchestrates workflows, let’s explore its foundational components, the DAG, tasks, scheduler, executor, triggerer, and metadata database.
Together, these components coordinate how data flows from extraction to transformation, model training, and loading results in a seamless, automated pipeline.
We’ll use a simple ETL (Extract → Transform → Load) data workflow as our running example. Each day, Airflow will:
- Collect daily event data,
- Transform it into a clean format,
- Upload the results to Amazon S3.
This process will help us connect each concept to a real-world orchestration scenario.
i. DAG (Directed Acyclic Graph)
A DAG is the blueprint of your workflow. It defines what tasks exist and in what order they should run.
Think of it as the pipeline skeleton that connects your data extraction, transformation, and loading steps:
collect_data → transform_data → upload_resultsDAGs can be triggered by time (e.g., daily schedules) or events, such as when a new dataset or asset becomes available.
from airflow.decorators import dag
from datetime import datetime
@dag(
dag_id="daily_ml_pipeline",
schedule="@daily",
start_date=datetime(2025, 10, 7),
catchup=False,
)
def pipeline():
passThe @dag line is a decorator, a Python feature that lets you add behavior or metadata to functions in a clean, readable way. In this case, it turns the pipeline() function into a fully functional Airflow DAG.
The DAG defines when and in what order your workflow runs, but the individual tasks define how each step actually happens.
If you want to learn more about Python decorators, check out our lesson on Buidling a Pipeline Class to see them in action.
- Don’t worry if the code above feels overwhelming. In the next tutorial, we’ll take a closer look at them and understand how they work in Airflow. For now, we’ll keep things simple and more conceptual.
ii. Tasks: The Actions Within the Workflow
A task is the smallest unit of work in Airflow, a single, well-defined action, like fetching data, cleaning it, or training a model.
If the DAG defines the structure, tasks define the actions that bring it to life.
Using the TaskFlow API, you can turn any Python function into a task with the @task decorator:
from airflow.decorators import task
@task
def collect_data():
print("Collecting event data...")
return "raw_events.csv"
@task
def transform_data(file):
print(f"Transforming {file}")
return "clean_data.csv"
@task
def upload_to_s3(file):
print(f"Uploading {file} to S3...")
Tasks can be linked simply by calling them in sequence:
upload_to_s3(transform_data(collect_data()))Airflow automatically constructs the DAG relationships, ensuring that each step runs only after its dependency completes successfully.
iii. From Operators to the TaskFlow API
In earlier Airflow versions, you defined each task using explicit operators, for example, a PythonOperator or BashOperator , to tell Airflow how to execute the logic.
Airflow simplifies this with the TaskFlow API, eliminating boilerplate while maintaining backward compatibility.
# Old style (Airflow 1 & 2)
from airflow.operators.python import PythonOperator
task_transform = PythonOperator(
task_id="transform_data",
python_callable=transform_data
)With the TaskFlow API, you no longer need to create operators manually. Each @task function automatically becomes an operator-backed task.
# Airflow 3
@task
def transform_data():
...Under the hood, Airflow still uses operators as the execution engine, but you no longer need to create them manually. The result is cleaner, more Pythonic workflows.
iv. Dynamic Task Mapping: Scaling the Transformation
Modern data workflows often need to process multiple files, users, or datasets in parallel.
Dynamic task mapping allows Airflow to create task instances at runtime based on data inputs, perfect for scaling transformations.
@task
def get_files():
return ["file1.csv", "file2.csv", "file3.csv"]
@task
def transform_file(file):
print(f"Transforming {file}")
transform_file.expand(file=get_files())Airflow will automatically create and run a separate transform_file task for each file, enabling efficient, parallel execution.
v. Scheduler and Triggerer
The scheduler decides when tasks run, either on a fixed schedule or in response to updates in data assets.
The triggerer, on the other hand, handles event-based execution behind the scenes, using asynchronous I/O to efficiently wait for external signals like file arrivals or API responses.
from airflow.assets import Asset
events_asset = Asset("s3://data/events.csv")
@dag(
dag_id="event_driven_pipeline",
schedule=[events_asset], # Triggered automatically when this asset is updated
start_date=datetime(2025, 10, 7),
catchup=False,
)
def pipeline():
...In this example, the scheduler monitors the asset and triggers the DAG when new data appears.
If the DAG included deferrable operators or sensors, the triggerer would take over waiting asynchronously, ensuring Airflow handles both time-based and event-driven workflows seamlessly.
vi. Executor and Workers
Once a task is ready to run, the executor assigns it to available workers, the machines or processes that actually execute your code.
For example, your ETL pipeline might look like this:
collect_data → transform_data → upload_resultsAirflow decides where each of these tasks runs. It can execute everything on a single machine using the LocalExecutor, or scale horizontally across multiple nodes with the CeleryExecutor or KubernetesExecutor.
Deferrable tasks further improve efficiency by freeing up workers while waiting for long external operations like API responses or file uploads.
vii. Metadata Database and API Server: The Memory and Interface
Every action in Airflow, task success, failure, duration, or retry, is stored in the metadata database, Airflow’s internal memory.
This makes workflows reproducible, auditable, and observable.
The API server provides visibility and control:
- View and trigger DAGs,
- Inspect logs and task histories,
- Track datasets and dependencies,
- Monitor system health (scheduler, triggerer, database).
Together, they give you complete insight into orchestration, from individual task logs to system-wide performance.
Exploring the Airflow UI
Every orchestration platform needs a way to observe, manage, and interact with workflows, and in Apache Airflow, that interface is the Airflow Web UI.
The UI is served by the Airflow API Server, which exposes a rich dashboard for visualizing DAGs, checking system health, and monitoring workflow states. Even before running any tasks, it’s useful to understand the layout and purpose of this interface, since it’s where orchestration becomes visible.
Don’t worry if this section feels too conceptual; you’ll explore the Airflow UI in greater detail during the upcoming tutorial. You can also use our Setting up Apache Airflow with Docker Locally (Part I) guide if you’d like to try it right away.
The Role of the Airflow UI in Orchestration
In an orchestrated system, automation alone isn’t enough, engineers need visibility.
The UI bridges that gap. It provides an interactive window into your pipelines, showing:
- Which workflows (DAGs) exist,
- Their current state (active, running, or failed),
- The status of Airflow’s internal components,
- Historical task performance and logs.
This visibility is essential for diagnosing failures, verifying dependencies, and ensuring the orchestration system runs smoothly.
i. The Home Page Overview
The Airflow UI opens to a dashboard like the one shown below:
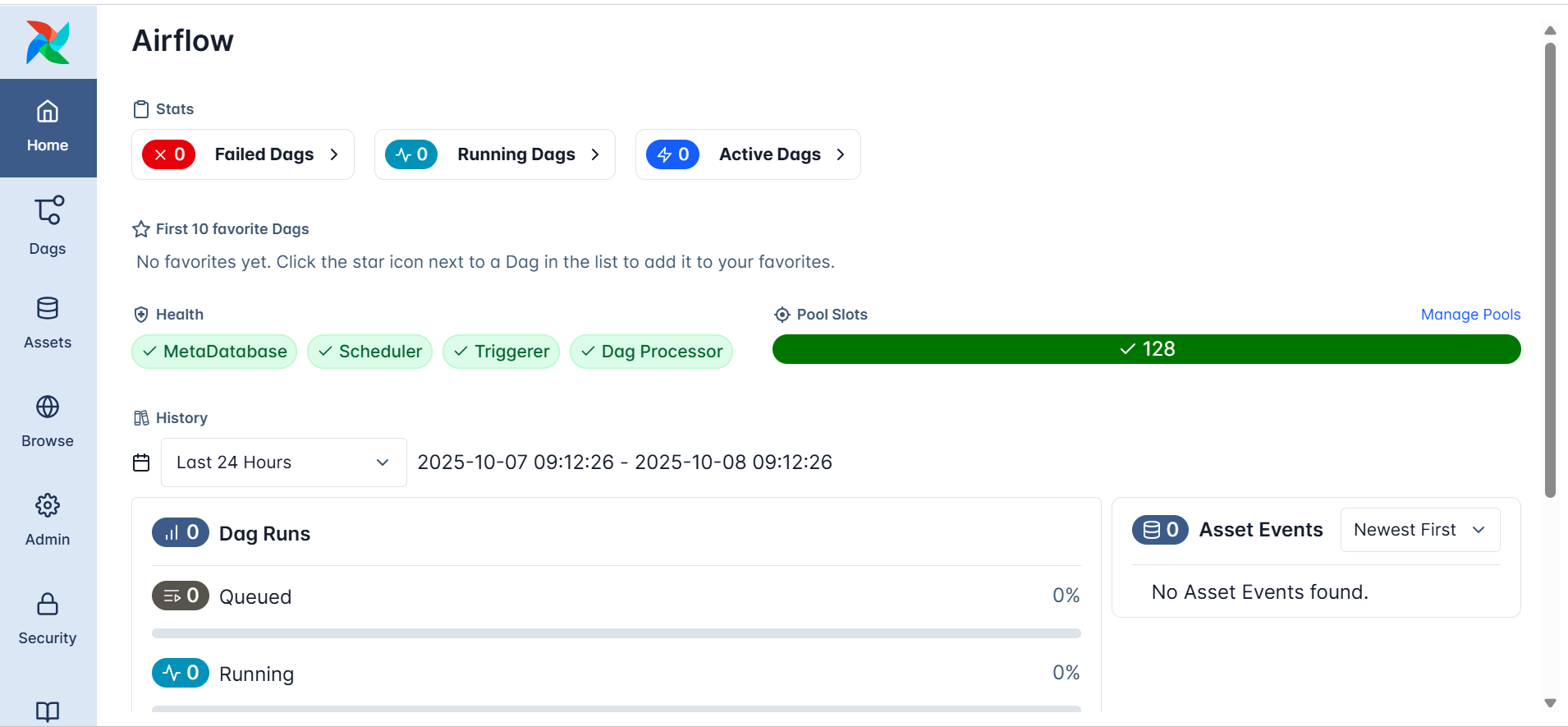
At a glance, you can see:
- Failed DAGs / Running DAGs / Active DAGs, A quick summary of the system’s operational state.
- Health Indicators — Status checks for Airflow’s internal components:
- MetaDatabase: Confirms the metadata database connection is healthy.
- Scheduler: Verifies that the scheduler is running and monitoring DAGs.
- Triggerer: Ensures event-driven workflows can be activated.
- DAG Processor: Confirms DAG files are being parsed correctly.
These checks reflect the orchestration backbone at work, even if no DAGs have been created yet.
ii. DAG Management and Visualization
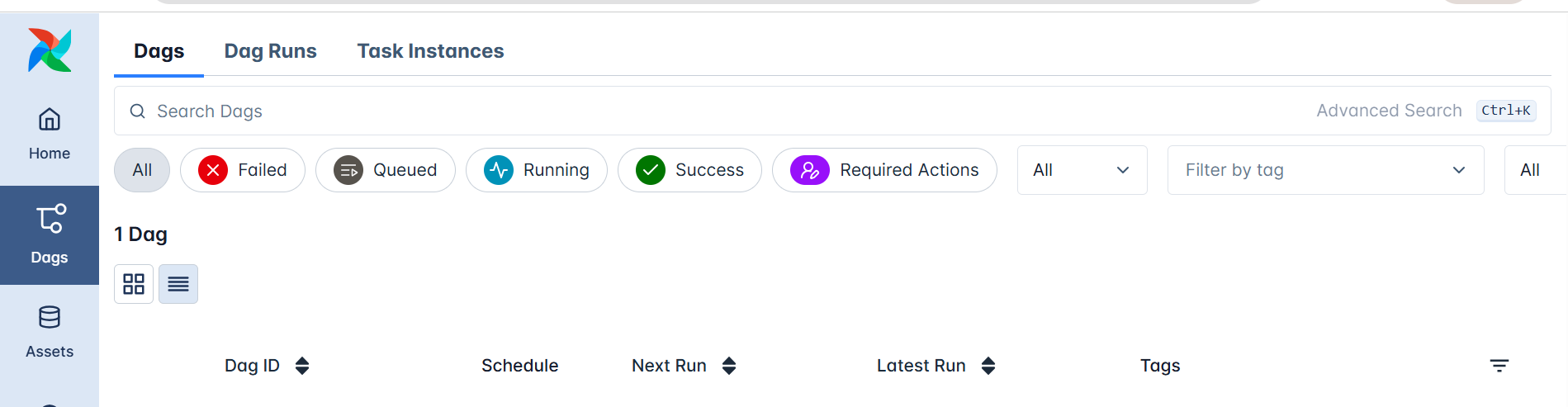
In the left sidebar, the DAGs section lists all workflow definitions known to Airflow.
This doesn’t require you to run anything; it’s simply where Airflow displays every DAG it has parsed from the dags/ directory.
Each DAG entry includes:
- The DAG name and description,
- Schedule and next run time,
- Last execution state
- Controls to enable, pause, or trigger it manually.
When workflows are defined, you’ll be able to explore their structure visually through:
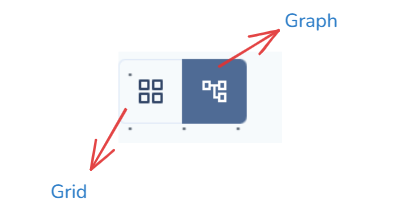
- Graph View — showing task dependencies
- Grid View — showing historical run outcomes
These views make orchestration transparent, every dependency, sequence, and outcome is visible at a glance.
iii. Assets and Browse
In the sidebar, the Assets and Browse sections provide tools for exploring the internal components of your orchestration environment.
-
Assets list all registered items, such as datasets, data tables, or connections that Airflow tracks or interacts with during workflow execution. It helps you see the resources your DAGs depend on. (Remember: in Airflow 3.x, “Datasets” were renamed to “Assets.”)

-
Browse allows you to inspect historical data within Airflow, including past DAG runs, task instances, logs, and job details. This section is useful for auditing and debugging since it reveals how workflows behaved over time.


Together, these sections let you explore both data assets and orchestration history, offering transparency into what Airflow manages and how your workflows evolve.
iv. Admin
The Admin section provides the configuration tools that control Airflow’s orchestration environment.
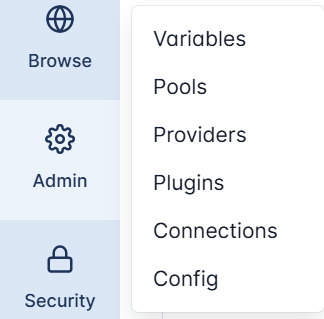
Here, administrators can manage the system’s internal settings and integrations:
- Variables – store global key–value pairs that DAGs can access at runtime,
- Pools – limit the number of concurrent tasks to manage resources efficiently,
- Providers – list the available integration packages (e.g., AWS, GCP, or Slack providers),
- Plugins – extend Airflow’s capabilities with custom operators, sensors, or hooks,
- Connections – define credentials for databases, APIs, and cloud services,
- Config – view configuration values that determine how Airflow components run,
This section essentially controls how Airflow connects, scales, and extends itself, making it central to managing orchestration behavior in both local and production setups.
v. Security
The Security section governs authentication and authorization within Airflow’s web interface.
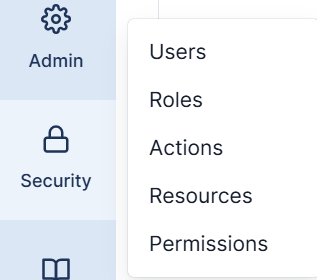
It allows administrators to manage users, assign roles, and define permissions that determine who can access or modify specific parts of the system.
Within this menu:
- Users – manage individual accounts for accessing the UI.
- Roles – define what actions users can perform (e.g., view-only vs. admin).
- Actions, Resources, Permissions – provide fine-grained control over what parts of Airflow a user can interact with.
Strong security settings ensure that orchestration remains safe, auditable, and compliant, particularly in shared or enterprise environments.
vii. Documentation
At the bottom of the sidebar, Airflow provides quick links under the Documentation section.
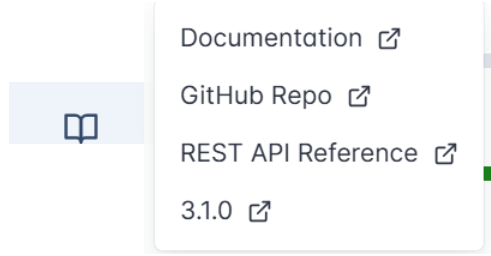
This includes direct access to:
- Official Documentation – the complete Airflow user and developer guide,
- GitHub Repository – the open-source codebase for Airflow,
- REST API Reference – detailed API endpoints for programmatic orchestration control,
- Version Info – the currently running Airflow version,
These links make it easy for users to explore Airflow’s architecture, extend its features, or troubleshoot issues, right from within the interface.
Airflow vs Cron
Many data engineers start automation with cron, the classic Unix schedulersimple, reliable, and perfect for a single recurring script.
But as soon as workflows involve multiple dependent steps, data triggers, or retry, logic, cron’s simplicity turns into fragility.
Apache Airflow moves beyond time-based scheduling into workflow orchestration, managing dependencies, scaling dynamically, and responding to data-driven events, all through native Python.
i. From Scheduling to Dynamic Orchestration
Cron schedules jobs strictly by time:
# Run a data cleaning script every midnight
0 0 * * * /usr/local/bin/clean_data.shThat works fine for one job, but it breaks down when you need to coordinate a chain like:
extract → transform → train → uploadCron can’t ensure that step two waits for step one, or that retries occur automatically if a task fails.
In Airflow, you express this entire logic natively in Python using the TaskFlow API:
from airflow.decorators import dag, task
from datetime import datetime
@dag(schedule="@daily", start_date=datetime(2025,10,7), catchup=False)
def etl_pipeline():
@task def extract(): ...
@task def transform(data): ...
@task def load(data): ...
load(transform(extract()))
Here, tasks are functions, dependencies are inferred from function calls, and Airflow handles execution, retries, and state tracking automatically.
It’s the difference between telling the system when to run and teaching it how your workflow fits together.
ii. Visibility, Reliability, and Data Awareness
Where cron runs in the background, Airflow makes orchestration observable and intelligent.
Its Web UI and API provide transparency, showing task states, logs, dependencies, and retry attempts in real time.
Failures trigger automatic retries, and missed runs can be easily backfilled to maintain data continuity.
Airflow also introduces data-aware scheduling: workflows can now run automatically when a dataset or asset updates, not just on a clock.
from airflow.assets import Asset
sales_data = Asset("s3://data/sales.csv")
@dag(schedule=[sales_data], start_date=datetime(2025,10,7))
def refresh_dashboard():
...
This makes orchestration responsive, pipelines react to new data as it arrives, keeping dashboards and downstream models always fresh.
iii. Why This Matters
Cron is a timer.
Airflow is an orchestrator, coordinating complex, event-driven, and scalable data systems.
It brings structure, visibility, and resilience to automation, ensuring that each task runs in the right order, with the right data, and for the right reason.
That’s the leap from scheduling to orchestration, and why Airflow is much more than cron with an interface.
Common Airflow Use Cases
Workflow orchestration underpins nearly every data-driven system, from nightly ETL jobs to continuous model retraining.
Because Airflow couples time-based scheduling with dataset awareness and dynamic task mapping, it adapts easily to many workloads.
Below are the most common production-grade scenarios ,all achievable through the TaskFlow API and Airflow’s modular architecture.
i. ETL / ELT Pipelines
ETL (Extract, Transform, Load) remains Airflow’s core use case.
Airflow lets you express a complete ETL pipeline declaratively, with each step defined as a Python @task.
from airflow.decorators import dag, task
from datetime import datetime
@dag(schedule="@daily", start_date=datetime(2025,10,7), catchup=False)
def daily_sales_etl():
@task
def extract_sales():
print("Pulling daily sales from API…")
return ["sales_us.csv", "sales_uk.csv"]
@task
def transform_file(file):
print(f"Cleaning and aggregating {file}")
return f"clean_{file}"
@task
def load_to_warehouse(files):
print(f"Loading {len(files)} cleaned files to BigQuery")
# Dynamic Task Mapping: one transform per file
cleaned = transform_file.expand(file=extract_sales())
load_to_warehouse(cleaned)
daily_sales_etl()
Because each transformation task is created dynamically at runtime, the pipeline scales automatically as data sources grow.
When paired with datasets or assets, ETL DAGs can trigger immediately when new data arrives, ensuring freshness without manual scheduling.
ii. Machine Learning Pipelines
Airflow is ideal for orchestrating end-to-end ML lifecycles, data prep, training, evaluation, and deployment.
@dag(schedule="@weekly", start_date=datetime(2025,10,7))
def ml_training_pipeline():
@task
def prepare_data():
return ["us_dataset.csv", "eu_dataset.csv"]
@task
def train_model(dataset):
print(f"Training model on {dataset}")
return f"model_{dataset}.pkl"
@task
def evaluate_models(models):
print(f"Evaluating {len(models)} models and pushing metrics")
# Fan-out training jobs
models = train_model.expand(dataset=prepare_data())
evaluate_models(models)
ml_training_pipeline()
Dynamic Task Mapping enables fan-out parallel training across datasets, regions, or hyper-parameters, a common pattern in large-scale ML systems.
Airflow’s deferrable sensors can pause training until external data or signals are ready, conserving compute resources.
iii. Analytics and Reporting
Analytics teams rely on Airflow to refresh dashboards and reports automatically.
Airflow can combine time-based and dataset-triggered scheduling so that dashboards always use the latest processed data.
from airflow import Dataset
summary_dataset = Dataset("s3://data/summary_table.csv")
@dag(schedule=[summary_dataset], start_date=datetime(2025,10,7))
def analytics_refresh():
@task
def update_powerbi():
print("Refreshing Power BI dashboard…")
@task
def send_report():
print("Emailing daily analytics summary")
update_powerbi() >> send_report()
Whenever the summary dataset updates, this DAG runs immediately; no need to wait for a timed window.
That ensures dashboards remain accurate and auditable.
iv. Data Quality and Validation
Trusting your data is as important as moving it.
Airflow lets you automate quality checks and validations before promoting data downstream.
- Run dbt tests or Great Expectations validations as tasks.
- Use deferrable sensors to wait for external confirmations (e.g., API signals or file availability) without blocking workers.
- Fail fast or trigger alerts when anomalies appear.
@task
def validate_row_counts():
print("Comparing source and target row counts…")
@task
def check_schema():
print("Ensuring schema consistency…")
validate_row_counts() >> check_schema()
These validations can be embedded directly into the main ETL DAG, creating self-monitoring pipelines that prevent bad data from spreading.
v. Infrastructure Automation and DevOps
Beyond data, Airflow orchestrates operational workflows such as backups, migrations, or cluster scaling.
With the Task SDK and provider integrations, you can automate infrastructure the same way you orchestrate data:
@dag(schedule="@daily", start_date=datetime(2025,10,7))
def infra_maintenance():
@task
def backup_database():
print("Triggering RDS snapshot…")
@task
def cleanup_old_files():
print("Deleting expired objects from S3…")
backup_database() >> cleanup_old_files()
Airflow turns these system processes into auditable, repeatable, and observable jobs, blending DevOps automation with data-engineering orchestration.
With Airflow, orchestration goes beyond timing, it becomes data-aware, event-driven, and infinitely scalable, empowering teams to automate everything from raw data ingestion to production-ready analytics.
Summary and Up Next
In this tutorial, you explored the foundations of workflow orchestration and how Apache Airflow modernizes data automation through a modular, Pythonic, and data-aware architecture. You learned how Airflow structures workflows using DAGs and the TaskFlow API, scales effortlessly through Dynamic Task Mapping, and responds intelligently to data and events using deferrable tasks and the triggerer.
You also saw how its scheduler, executor, and web UI work together to ensure observability, resilience, and scalability far beyond what traditional schedulers like cron can offer.
In the next tutorial, you’ll bring these concepts to life by installing and running Airflow with Docker, setting up a complete environment where all core services, the apiserver, scheduler, metadata database, triggerer, and workers, operate in harmony.
From there, you’ll create and monitor your first DAG using the TaskFlow API, define dependencies and schedules, and securely manage connections and secrets.
Further Reading
Explore the official Airflow documentation to deepen your understanding of new features and APIs, and prepare your Docker environment for the next tutorial.
Then, apply what you’ve learned to start orchestrating real-world data workflows efficiently, reliably, and at scale.