10 R Skills You Need to Know
Back in 2017, I began my data journey by learning R while working at a leading environmental consulting firm. With dozens of R users in the company, I saw an exciting opportunity to learn from experienced practitioners. This choice ended up shaping my career in ways I never expected, eventually leading me to develop some of Dataquest's R courses and see firsthand the significant impact R skills can have.
R continues to be a valuable tool for many data professionals. Although some predicted its decline, recent data shows that R's robust capabilities in statistical computing and data visualization make it an essential skill in many domains.
In this post, we'll explore the key R skills you should consider learning and how to apply them in practical scenarios. We'll cover everything from basic syntax to machine learning, giving you a roadmap for improving your R proficiency and advancing your career.
If you're looking for a structured way to build these skills, consider checking out Dataquest's Data Analyst in R path. It's the applied, step-by-step learning approach that I wish was available when I started learning R.
Now let's get started.
Why You Should Pick Up Some R Skills
Here's the bottom line: while R isn't the best choice for everyone, it can be a valuable skill to learn, especially if you work in data-driven fields such as:
- Science
- Finance
- Academia
Companies like Facebook, Merck, and Pfizer actively seek out R professionals.
One of R's strengths is its versatility. It enables you to handle large datasets, perform advanced analytics, and even build machine learning models. I experienced this firsthand when I used R's statistical methods to predict bird fatalities at a solar farm. By analyzing the data and creating visualizations, we understood the patterns and made recommendations to address the issue.
R also excels at generating reproducible reports. Tools like R Markdown allow you to seamlessly combine code, analysis, and visualizations into dynamic documents. This simplifies communicating insights effectively, as I discovered when automating dozens of ggplot2 visualizations for a client, saving time and effort.
Another highlight of R is its extensive package, or tools, ecosystem. Packages like ggplot2 enable you to create sophisticated data visualizations that uncover hidden trends. By leveraging these tools, you can deliver actionable insights that drive business decisions. For example, in one project ggplot2 helped me identify data errors during exploratory analysis, underscoring the importance of visualization early in the data analysis process.
Should You Learn R or Python?
When people ask me this, my answer is always the same; it really depends on your situation, but learning SQL is a must. Wait, what? If that comes as a surprise to you, I say this because SQL continues to be the best language for querying databases, an essential skill for any data analyst. For this reason, Dataquest's R and Python paths include the same SQL fundamentals content.
That said, at Dataquest, we generally recommend starting with Python for most aspiring data professionals. As a general-purpose language and the most popular programming language worldwide, Python offers broad applicability and versatility. However, if you already know Python, adding R to your toolkit can help you stand out among other candidates, particularly if you're targeting roles in statistics-heavy domains.
Top 10 Programming in R Skills
While R may not be the best choice for everyone, it can be a valuable skill to add to your toolkit, especially if you already know Python or work in data-driven fields like science, finance, or academia. If you're considering learning R, here are the top 10 skills to focus on:
- Learn R Syntax and Data Structures
- Write Efficient R Code with Conditionals and Iteration Tools
- Create Reusable, Modular R Code with Functions
- Import and Manipulate Data in R
- Visualize Data Using ggplot2 in R
- Create Reproducible Reports with R Markdown
- Perform Statistical Analysis in R with Functions and Packages
- Build Interactive Dashboards in R with Shiny
- Implement Machine Learning in R
- Analyze Text Data with R Text Mining and NLP Techniques
By developing proficiency in these 10 R skills, you'll be well-equipped to tackle a range of data challenges. For instance, ggplot2 enables you to create compelling visualizations that bring insights to life, a key skill highlighted in recent industry discussions. Whether you're just starting out or looking to level up your abilities, investing time in these R skills can pay dividends in your data career.
In the following sections, we'll explore each of these R skills. In most sections, we'll be using a dataset about penguins in Antarctica from an R package called "palmerpenguins" to demonstrate R's capabilities. As someone who has worked in Antarctica myself, I couldn't resist the opportunity to work with this dataset. Let's check it out!
1. Learn R Syntax and Data Structures
If you're considering diving into R programming, getting comfortable with its syntax and data structures is a great place to start. Why? Because understanding these fundamentals lays the groundwork for efficiently analyzing data and collaborating with others.
Let's take a quick look at an example using the "palmerpenguins" dataset, which contains information about penguins in Antarctica:
# Install required packages
install.packages("tidyverse") # Installs the tidyverse package
install.packages("palmerpenguins") # Installs the palmerpenguins package
# Load the required packages
library(tidyverse) # Loads tidyverse, which includes ggplot2, dplyr, etc.
library(palmerpenguins) # Loads the palmerpenguins package
# Read the penguins dataset
data("penguins") # The palmerpenguins package includes a dataset named 'penguins'
# Inspect the first few rows of the dataset
head(penguins) # Displays the first 6 rows of the penguins data frame| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year |
|---|---|---|---|---|---|---|---|
| Adelie | Torgersen | 39.1 | 18.7 | 181 | 3750 | male | 2007 |
| Adelie | Torgersen | 39.5 | 17.4 | 186 | 3800 | female | 2007 |
| Adelie | Torgersen | 40.3 | 18.0 | 195 | 3250 | female | 2007 |
| Adelie | Torgersen | NA | NA | NA | NA | NA | 2007 |
| Adelie | Torgersen | 36.7 | 19.3 | 193 | 3450 | female | 2007 |
| Adelie | Torgersen | 39.3 | 20.6 | 190 | 3650 | male | 2007 |
In this code, we're installing and loading the necessary packages, then reading in the penguins dataset. The head() function lets us peek at the first few rows.
As you can see, R's syntax provides a clear way to load and inspect data. The data structure allows you to neatly organize information for easy manipulation and analysis.
Applying R Skills in the Real World
Picture this: you're a biologist studying penguin populations. With R's data frames, you could efficiently manage and analyze data on penguin species, locations, and physical characteristics. Or maybe you're a marketer looking to understand customer behavior. You might use vectors to examine purchasing patterns over time.
The more comfortable you become with R's syntax and data structures, the better equipped you'll be to work with complex datasets and uncover meaningful insights, no matter your field.
Riding the Learning Curve
Learning R's syntax and data structures takes practice, and working with multi-dimensional data or combining different data types can be challenging at first. But don't worry - there are excellent resources available. My favorite of all time is Hadley Wickham's R for Data Science book and website, which breaks down these concepts into manageable lessons.
Investing time to learn R fundamentals can be incredibly valuable for growing your data science skills. It provides a solid foundation for solving complex problems and making data-informed decisions across various industries.
Back to Top 10 programming in R Skills
2. Write Efficient R Code with Conditionals and Iteration Tools
Learning to use conditionals and iteration tools effectively can help you write cleaner, more efficient R code. By optimizing these fundamental structures, you'll streamline your workflow and handle complex analyses with greater ease.
Let's break it down using the "palmerpenguins" dataset, which contains information about penguins in Antarctica. Suppose we want to print the species of the first 5 penguins. We could use a for loop like this:
# For loop to print the species of the first 5 penguins
for (i in 1:5) {
print(penguins$species[i])
}This loop iterates through the first 5 rows of the "species" column in the penguins data frame, printing each value. The output would look like:
[1] Adelie
[1] Adelie
[1] Adelie
[1] Adelie
[1] AdelieAlternatively, we could use the sapply() function, which applies a given function to each element of a vector:
# Using sapply to print the species of the first 5 penguins
sapply(penguins$species[1:5], print)This code applies print() to each of the first 5 elements in the "species" column. It yields a similar result as the for loop but in fewer lines. sapply() can often be more concise and efficient, but for loops are great when you're starting out because the behavior is easier to see.
Vectorization: A Unique R Feature
It's important to note that overusing loops can sometimes slow your script down, especially when a vectorized operation could do the job faster. So what is vectorization? In simple terms, it lets you process entire arrays of data in one fell swoop, without the need for explicit looping.. It's one of R's unique, quirky features that can boost your code's efficiency.
Pro tip: try to avoid growing vectors inside loops, as this can bog down performance.
By writing cleaner, faster R code, you'll be better equipped to tackle impactful projects and drive data-informed decisions. So if you're considering adding R to your toolkit, don't be afraid to explore conditionals and iteration. Start simple, practice often, and soon you'll be writing efficient, readable code that makes your work easier and more effective.
Back to Top 10 programming in R Skills
3. Create Reusable, Modular R Code with Functions
Using functions in R can make your code more efficient, readable, and reusable. By "encapsulating" tasks into distinct blocks of code, you can streamline your workflow and reduce errors.
Let's look at an example using the "palmerpenguins" dataset about penguins in Antarctica. Say we want to categorize the penguins based on their body mass. We could write a function to handle this:
Categorizing Penguins by Body Mass
# Function to categorize penguins based on body mass
categorize_body_mass <- function(data) {
data %>%
mutate(body_mass_category = case_when(
body_mass_g < 3500 ~ "Small",
body_mass_g >= 3500 & body_mass_g <= 4500 ~ "Medium",
body_mass_g > 4500 ~ "Large",
TRUE ~ NA_character_ # Handles NA values
))
}
# Apply the function to the penguins dataset
penguins <- categorize_body_mass(penguins)
# View the first few rows to see the new column
head(penguins)| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year |
|---|---|---|---|---|---|---|---|
| Adelie | Torgersen | 39.1 | 18.7 | 181 | 3750 | male | 2007 |
| Adelie | Torgersen | 39.5 | 17.4 | 186 | 3800 | female | 2007 |
| Adelie | Torgersen | 40.3 | 18.0 | 195 | 3250 | female | 2007 |
| Adelie | Torgersen | NA | NA | NA | NA | NA | 2007 |
| Adelie | Torgersen | 36.7 | 19.3 | 193 | 3450 | female | 2007 |
| Adelie | Torgersen | 39.3 | 20.6 | 190 | 3650 | male | 2007 |
This code defines a function called categorize_body_mass() that takes a dataset as input, adds a new column called "body_mass_category", and assigns each penguin a size category based on its body mass. We then apply this function to the penguins dataset and view the result.
By creating a function for this task, we can easily reuse it anytime we need to categorize penguins (or even other animals) by body mass. This makes our code more modular and less prone to errors than copying and pasting the same code multiple times.
So if you're learning R, consider focusing on functions as a key skill. Start simple, practice often, and soon you'll be writing clean, reusable code that makes your work easier.
Back to Top 10 programming in R Skills
4. Import and Manipulate Data in R
Being able to import and work with data is an essential skill for any aspiring data analyst using R. It opens up a world of possibilities for uncovering valuable insights from all kinds of datasets.
Filtering and Summarizing Data with dplyr
Let's take a look at an example using the "palmerpenguins" dataset. Suppose we want to filter the data to only include Adelie penguins and calculate the average bill length and depth for that species:
# Example of data manipulation: Filtering and summarizing
penguins %>%
filter(species == "Adelie") %>%
summarize(
average_bill_length = mean(bill_length_mm, na.rm = TRUE),
average_bill_depth = mean(bill_depth_mm, na.rm = TRUE)
)In this code, we're using the dplyr package from the tidyverse to filter the dataset to only include rows where the species is "Adelie". We then use the summarize() function to calculate the mean bill length and depth for those penguins, handling missing values with na.rm = TRUE.
The output would look something like this:
# A tibble: 1 × 2
average_bill_length average_bill_depth
<dbl> <dbl>
1 38.8 18.3This is just a small taste of what's possible with data manipulation in R. Whether you're a financial analyst looking at stock market trends or a healthcare researcher working with patient records, the process is similar: import your data, clean it up, and start your analysis.
Getting comfortable with data manipulation in R can take some practice, as you'll need to learn various packages and functions. But it's a skill that can really boost your career prospects by showing employers you have the technical abilities to handle complex data projects.
The key is to start simple, practice often, and don't be afraid to experiment with different data wrangling techniques.
Back to Top 10 programming in R Skills
5. Visualize Data Using ggplot2 in R
Learning to create compelling data visualizations with ggplot2 can be a major asset for aspiring R programmers. It enables you to explore datasets, uncover insights, and effectively communicate findings to stakeholders.
ggplot2 is a powerful package that allows you to craft customized, professional-grade visuals from your data. It's highly flexible, supporting everything from basic bar charts to intricate scatter plots that reveal patterns hidden in the numbers. It's one of my favorite tools in R. When I create data visualizations, I use ggplot2.
To see ggplot2 in action, let's use it to visualize the relationship between flipper length and body mass in the "palmerpenguins" dataset:
# Load the ggplot2 library
library(ggplot2)
# Create a basic scatter plot with ggplot2
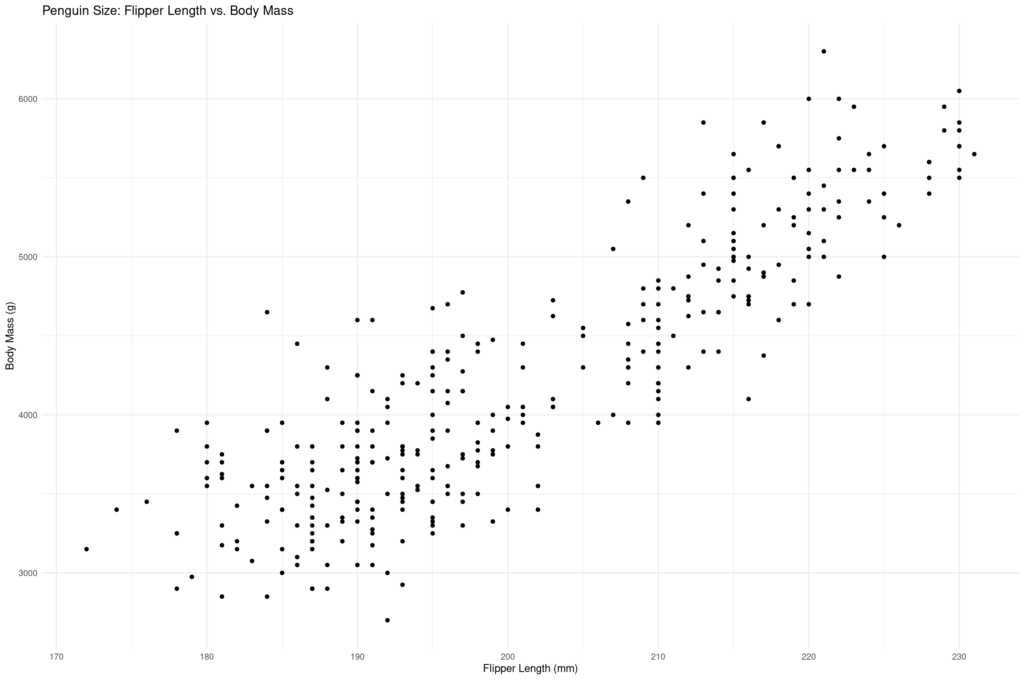
ggplot(data = penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point() +
labs(title = "Penguin Size: Flipper Length vs. Body Mass",
x = "Flipper Length (mm)",
y = "Body Mass (g)") +
theme_minimal()Here's the plot:
Here's a high-level overview of what this code does:
- We load the ggplot2 library, which provides the tools for making the plot.
- We call the
ggplot()function, specifying thepenguinsdataset and the variables we want to plot on the x and y axes. - We add a layer with
geom_point()to create a scatter plot. - We customize the plot labels with
labs()and apply a minimalist theme withtheme_minimal().
The resulting plot allows us to visually examine the relationship between flipper length and body mass across different penguin species. We can see that penguins with longer flippers tend to have greater body mass, though there is some variation between species.
Why ggplot2 is Worth Learning
If you're an aspiring R programmer, here's why you should consider adding ggplot2 to your skill set:
- It's the go-to tool for data visualization in R, used widely in industry and academia.
- It offers a high degree of customization, allowing you to fine-tune your visuals.
- The plots you create can be valuable for both exploratory analysis and stakeholder communication.
That said, ggplot2 does require some dedicated effort to learn, especially if you're new to R. Its "grammar of graphics" approach takes some adjustment, and there are many different options to tweak plots.
The key is to build a strong foundation in base R first. Then start incorporating ggplot2 gradually as you analyze real datasets. Leverage the wealth of learning resources available, from tutorials to forums, to understand ggplot2's core concepts like geometries, aesthetics, facets and scales.
Back to Top 10 programming in R Skills
6. Create Reproducible Reports with R Markdown
Why Use R Markdown? R Markdown provides a framework for weaving together narrative text and R code into a single document. This integration allows for automatic updates and ensures that your reports are reproducible, which is crucial in data analysis where results often need to be validated and updated with new data.
A practical Example: Reproducing a ggplot2 Visualization
Let's use R Markdown to recreate the ggplot2 visualization from our earlier example in the Visualize Data Using ggplot2 in R section. This exercise will show how R Markdown can be used to combine code, commentary, and visuals into a polished report.
Steps to Create Your First R Markdown Document:
- Set Up Your R Markdown File: Begin by creating a new R Markdown file in RStudio. This file will contain three main parts: the YAML header, narrative text, and code chunks.
- YAML Header: This section sets up the document’s metadata and output format. For this example, we'll generate an HTML document.
--- title: "Penguin Size Analysis" author: "Casey Bates" date: "April, 2024" output: html_document --- - Narrative Introduction: Write a brief introduction about what this document will cover, explaining the data source and the objective of the visualization.
This report explores the relationship between flipper length and body mass among penguins. We use data from the "palmerpenguins" dataset and ggplot2 for visualization. - Code Chunk for Setup: Include a code chunk to install and load necessary packages.
install.packages("tidyverse") install.packages("palmerpenguins") library(tidyverse) library(palmerpenguins) - Data Visualization Code Chunk: Add another chunk where you recreate the scatter plot using ggplot2. This should mirror the example given in the blog post.
ggplot(data = penguins, aes(x = flipper_length_mm, y = body_mass_g)) + geom_point() + labs(title = "Penguin Size: Flipper Length vs. Body Mass", x = "Flipper Length (mm)", y = "Body Mass (g)") + theme_minimal() - Concluding Remarks: End with a brief paragraph that reflects on what the visualization reveals about the penguin data.
The scatter plot demonstrates a clear relationship between flipper length and body mass, indicating that larger penguins tend to have longer flippers. This type of insight is invaluable in ecological studies and conservation efforts.
Here's how it looks when rendered to the screen:
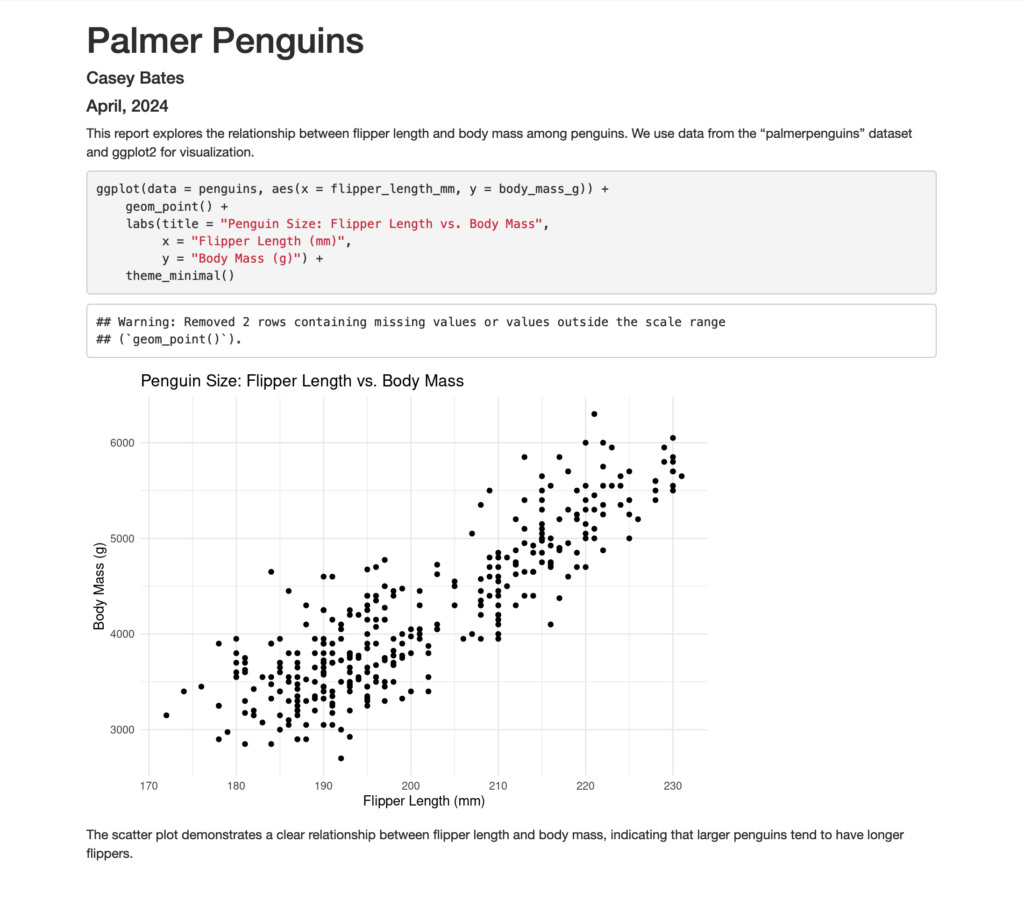
Notice that ggplot2 did us a favor and took care of some missing values, as indicated in the warning message. This is much better than getting an error!
As you become more familiar with R Markdown, explore more of its features, like parameterized reports, which can dynamically change the content based on specified parameters. This adaptability makes R Markdown an incredibly powerful tool for data scientists! R Markdown is hands-down one of my favorite things about programming in R. If you want to learn more about it, check out the R Markdown Cookbook.
Back to Top 10 Programming in R Skills
7. Perform Statistical Analysis in R with Functions and Packages
Performing statistical analysis in R is a valuable skill for aspiring data analysts to learn. R provides a wide range of functions and packages that make it easier to prepare data and perform complex analyses.
Why is this skill so important? Statistical analysis in R allows you to:
- Apply advanced data analysis techniques like predictive modeling
- Extract deeper insights to inform smarter decisions
- Work with popular machine learning packages like
caretandrandomForest
These capabilities are highly relevant across data-driven fields like finance and healthcare.
What Does Learning Statistical Analysis in R Involve?
Learning statistical analysis in R does require effort. Some of the methods are complex, and you'll need to stay current with new packages. But don't let that deter you. The key is to:
- Build a strong foundation in basic R programming first
- Practice with real datasets to learn by doing
- Engage with the R community for support
- Use tools like R Markdown to showcase your skills
Let's look at an example using the "palmerpenguins" dataset:
penguins %>%
group_by(species) %>%
summarize(
sd_bill_length = sd(bill_length_mm, na.rm = TRUE),
median_body_mass = median(body_mass_g, na.rm = TRUE)
)
| species | sd_bill_length | median_body_mass |
|---|---|---|
| Adelie | 2.663405 | 3700 |
| Chinstrap | 3.339256 | 3700 |
| Gentoo | 3.081857 | 5000 |
This code calculates the standard deviation of the bill length and median body mass for each penguin species. With time and practice, you can progress to more advanced techniques like building classification models to predict penguin species based on bill measurements
While mastering statistical analysis in R takes work, it's a skill that can really elevate your data science career. So if you're looking to grow your capabilities, consider adding it to your learning plan. Start small, practice regularly, and watch your skills flourish.
Back to Top 10 programming in R Skills
8. Build Interactive Dashboards in R with Shiny
Shiny is an R package that allows you to build interactive web applications directly from R. It's an excellent tool for making your data analyses more dynamic and engaging without needing web development skills. Whether you're presenting findings to stakeholders or exploring data interactively, Shiny can enhance the way you communicate and explore data.
Creating an Interactive Shiny App
Let's build off of our earlier data visualization by building an Shiny app that allows users to explore the relationship between flipper length and body mass among penguin species through a dynamic filter.
Step-by-step Guide to Enhancing the Shiny App
- Setup: Start by installing and loading the necessary packages if you haven’t already:
if (!require("shiny")) install.packages("shiny") library(shiny) if (!require("ggplot2")) install.packages("ggplot2") library(ggplot2) if (!require("palmerpenguins")) install.packages("palmerpenguins") library(palmerpenguins) - User Interface (UI): Define the user interface for your application. Here, we'll add a slider to dynamically filter penguins based on flipper length.
ui <- fluidPage( titlePanel("Interactive Penguin Size Visualization"), sidebarLayout( sidebarPanel( helpText("Explore the relationship between flipper length and body mass of penguins."), sliderInput("flipperLength", "Flipper Length:", min = min(penguins$flipper_length_mm, na.rm = TRUE), max = max(penguins$flipper_length_mm, na.rm = TRUE), value = c(min(penguins$flipper_length_mm, na.rm = TRUE), max(penguins$flipper_length_mm, na.rm = TRUE))) ), mainPanel( plotOutput("scatterPlot") ) ) ) - Server Logic: Update the server logic to render the ggplot2 plot based on the "palmerpenguins" dataset, filtered by the selected flipper length range.
server <- function(input, output) { output$scatterPlot <- renderPlot({ filtered_data <- penguins %>% filter(flipper_length_mm >= input$flipperLength[1] & flipper_length_mm <= input$flipperLength[2]) ggplot(data = filtered_data, aes(x = flipper_length_mm, y = body_mass_g)) + geom_point() + labs(title = "Penguin Size: Flipper Length vs. Body Mass", x = "Flipper Length (mm)", y = "Body Mass (g)") + theme_minimal() }) } - Run the App: Finally, run the app using the
shinyAppfunction.shinyApp(ui = ui, server = server)
Check it out below:
Adding a slider input for flipper length allows users to dynamically explore how body mass distribution changes across different flipper lengths, making the app not only more interactive but also more informative. How cool!
Shiny is a powerful addition to any R user's toolkit, ideal for delivering interactive and engaging data presentations. For further learning, explore more complex examples and tutorials available online to truly leverage Shiny's capabilities.
Back to Top 10 Programming in R Skills
9. Implement Machine Learning in R
Machine learning can significantly enhance your data analysis skills by enabling predictive analysis and automation. R, with its comprehensive package ecosystem, is an excellent tool for beginners to start exploring machine learning. Here, we'll walk through a basic example using the "palmerpenguins" dataset to predict a penguin's species based on its physical measurements.
Step-by-step Machine Learning with R
1. Setting up Your Environment
# Install the packages if not already installed
if (!require("caret")) install.packages("caret", dependencies = TRUE)
if (!require("palmerpenguins")) install.packages("palmerpenguins")
if (!require("nnet")) install.packages("nnet")
# Load the packages
library(caret)
library(palmerpenguins)
library(nnet)2. Preparing the Data
# Load the dataset
data("penguins", package = "palmerpenguins")
# Remove rows with missing values
penguins_clean <- na.omit(penguins)
# Preview the data
head(penguins_clean)3. Splitting the Data
set.seed(123) # Set a random seed for reproducibility
training_indices <- createDataPartition(penguins_clean$species, p = 0.8, list = FALSE)
training_set <- penguins_clean[training_indices, ]
testing_set <- penguins_clean[-training_indices, ]4. Training a Model
# Define the training control
train_control <- trainControl(method = "cv", number = 10)
# Train the model using multinomial logistic regression
model <- train(species ~ bill_length_mm + flipper_length_mm, data = training_set, method = "multinom", trControl = train_control)5. Making Predictions and Evaluating the Model
# Make predictions
predictions <- predict(model, testing_set)
# Evaluate the model
confusionMatrix(predictions, testing_set$species)
# Visualize the results
library(ggplot2)
testing_set$predicted_species <- predictions
ggplot(testing_set, aes(x = bill_length_mm, y = flipper_length_mm, color = species, shape = predicted_species)) +
geom_point(alpha = 0.5) +
labs(title = "Actual vs. Predicted Penguin Species", x = "Bill Length (mm)", y = "Flipper Length (mm)") +
theme_minimal()The model achieved an accuracy of approximately 90.77%, which is quite high for a basic model. Here's how it performed across the different penguin species:
| Reference | Adelie | Chinstrap | Gentoo |
|---|---|---|---|
| Prediction: Adelie | 27 | 3 | 0 |
| Prediction: Chinstrap | 2 | 9 | 0 |
| Prediction: Gentoo | 0 | 1 | 23 |
And here's the plot:
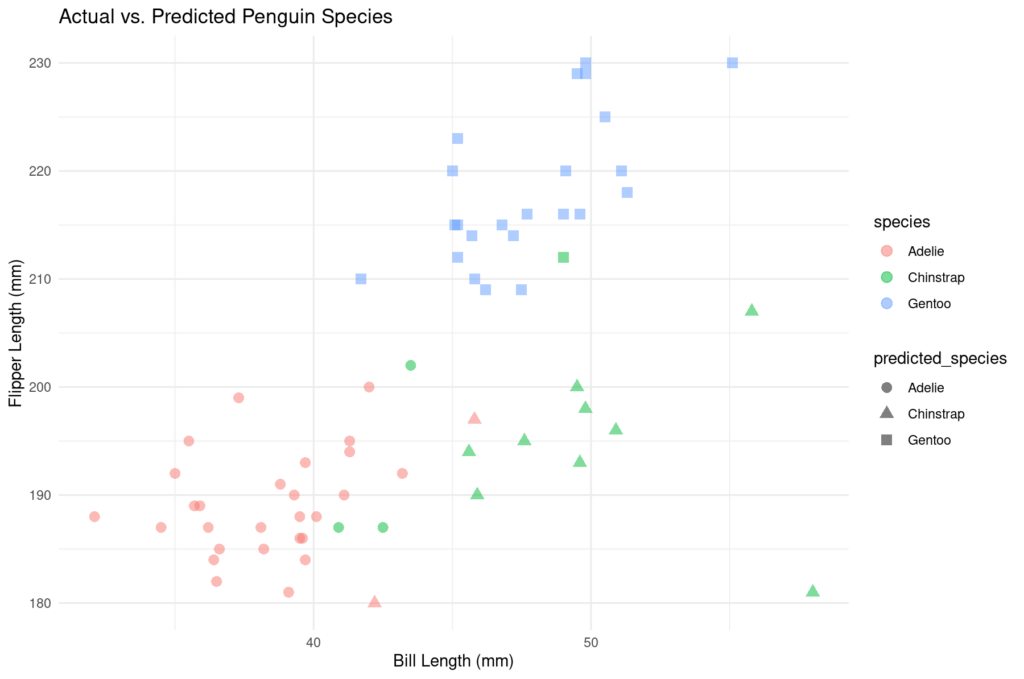
The sensitivity and specificity across the species were also quite strong, indicating a good predictive performance. This model serves as a great starting point for more complex machine learning tasks.
By following these steps, you will be well on your way to implementing more advanced machine learning models that can provide even deeper insights into your data.
Back to Top 10 Programming in R Skills
10. Analyze Text Data with R Text Mining and NLP Techniques
Want to extract meaningful insights from customer reviews or social media comments? Learning text mining in R can help you uncover valuable patterns and trends hidden in unstructured text data.
While structured datasets like the "palmerpenguins" data are great for learning the basics of data analysis in R, real-world data often comes in the form of text. A sample dataset of penguin research abstracts provides an excellent opportunity to explore how you can get started with text mining in R.
Basic Text Mining Steps with R
1. Setting Up Your Environment
# Install and load the necessary packages
if (!require("tm")) install.packages("tm") # for text mining
if (!require("tidytext")) install.packages("tidytext") # for handling text data
library(tm)
library(tidytext)2. Preparing the Text Data
# Example dataset: 'text_data' containing 'id' and 'abstract' columns
text_data <- data.frame(
id = 1:3,
abstract = c(
"Penguins are flightless birds living mostly in the southern hemisphere, particularly in Antarctica. Their adaptations to the cold include blubber and feathers which are crucial for insulation.",
"The diet of penguins includes krill, fish, and squid which they catch while swimming underwater. Penguins rely heavily on their ability to dive deep for food, often consuming a large volume of krill and small fish.",
"Global warming and climate change pose serious threats to penguin habitats, affecting their natural environment. Changes in temperature can impact penguin populations significantly by altering their food supply and breeding grounds."
),
stringsAsFactors = FALSE
)
# Create a text corpus
corpus <- VCorpus(VectorSource(text_data$abstract))
# Clean the text data
corpus_clean <- tm_map(corpus, content_transformer(tolower))
corpus_clean <- tm_map(corpus_clean, removePunctuation)
corpus_clean <- tm_map(corpus_clean, removeWords, stopwords("english"))3. Analyzing the Text Data
# Convert the corpus to a tidy text format
tidy_text <- tidy(corpus_clean)
# Count word frequencies
word_counts <- tidy_text %>%
unnest_tokens(word, text) %>%
count(word, sort = TRUE)
# Display the most common words
head(word_counts)| Word | Frequency |
|---|---|
| penguins | 3 |
| fish | 2 |
| food | 2 |
| krill | 2 |
| penguin | 2 |
| ability | 1 |
This example walks you through the process of transforming raw text into a clean, analysis-ready format and then examining word frequencies - a fundamental task in text mining.
As you build your text mining skills, you can move on to more advanced techniques like sentiment analysis to gauge the emotional tone of text, topic modeling to discover hidden themes, or text classification to automatically categorize documents. These powerful tools can help you gain deeper insights and make data-driven decisions in your work.
While text mining and NLP might seem challenging at first, starting with these basic tasks will help you build a strong foundation. With practice and persistence, you'll soon be ready to tackle complex text analysis projects and unlock valuable insights from unstructured data - a highly sought-after skill in today's job market.
Back to Top 10 Programming in R Skills
Common Misconceptions and Challenges with Programming in R
Learning to program in R can be tough at first, especially if you're new to coding. R's unique syntax and huge collection of packages can seem overwhelming in the beginning. But with the right strategies and mindset, you can overcome these challenges and use R to do amazing things with data.
So what are some of the most common misconceptions and mistakes that trip up new R learners?
One is not realizing that R is case-sensitive - meaning it treats upper and lowercase letters differently. Another is using inefficient "loops" to repeat operations instead of built-in R functions that can do the same thing much faster. Don't let these issues discourage you, though. They're normal parts of the learning process.
To get past the initial hurdles and really master R, consider these proven strategies:
- Practice writing code regularly, even if you start small
- Take advantage of free online courses from expert instructors
- Engage with the vibrant R community for support and motivation
As you put in the time and effort, you'll start to see how powerful and versatile R really is. From generating interactive visualizations to building web apps, R can do so much more than just stats and data analysis. Keeping that big picture in mind can help you stay focused and motivated.
So if you're feeling overwhelmed by R at first, just remember: you're not alone, and you can absolutely learn this skill if you stick with it. With practice and persistence, the "common challenges" will start to feel a lot less challenging before you know it.
How to Get Started with Programming in R

If you're looking to start learning R programming, here's what you need to know. By focusing on the basics, getting hands-on practice, and using the right resources, you can begin building R skills for a data career.
Learn the Basics
First, get familiar with R fundamentals like:
- R syntax
- Data structures (vectors, lists, data frames)
- Functions
To do this, you'll need to install R or start using it on positCloud. I recommend positCloud. It's a cloud computing application for working in RStudio, R's most popular development environment. In fact, all of the code in this blog post was written and executed in positCloud. It's really convenient and fun to work with!
Apply Your R Skills
Once you understand R basics, reinforce your knowledge with practical projects. Hands-on experience is key for improving your R abilities. For example, you could analyze a dataset or create a visualization using ggplot2. This helps you practice data manipulation and presentation - critical for data professionals. Find projects that motivate you!
Remember that R for Data Science is an amazing resource for applied learning. Another great resource is Posit Cheatsheets.
Choose Quality Resources for Learning R Skills
Look for learning platforms that combine theory and practice, like Dataquest. It offers an organized way to progress, at your own pace. Plus, you'll find plenty of projects to test out your new R skills.
Focus Your Learning
Consider which R capabilities matter most for your dream data job. Planning to work in healthcare or finance? Prioritize stats and machine learning in R.
Tools like dplyr for data wrangling and caret for predictive modeling are valuable. This targeted approach helps you learn the right skills faster.
Why Choose Dataquest for Learning R Skills?
Looking to learn R programming and launch your career in data? Dataquest is your go-to learning platform. Here's why:
Project-based Learning
Our project-based curriculum immerses you in real data science challenges from day one. You'll work hands-on with actual datasets, building practical skills in data manipulation, statistical analysis, and visualization with R. This bridges the gap between theory and application, ensuring you're ready to tackle professional projects.
Interactive Lessons
The interactive learning experience at Dataquest is second to none. You'll code along with our lessons, getting immediate feedback. This active approach boosts knowledge retention and builds your problem-solving confidence. What's more, you'll hone your skills in environments that simulate industry tools and workflows.
Supportive Community
At Dataquest, you're never alone in your learning journey. Our vibrant community is a constant source of support, collaboration, and inspiration. Connect with peers to share knowledge, get unstuck, and even find career advice from experienced data professionals.
Job-ready R Skills
We've carefully designed our Data Analyst in R path to align with the demands of top employers like Facebook, Google, Twitter, and Uber. Every lesson, project, and challenge is purposefully crafted to equip you with the tools and knowledge needed to succeed in the job market.
So if you're serious about becoming a skilled, job-ready data professional, Dataquest is your comprehensive solution. Join our community of motivated learners and expert instructors to start your journey to R programming mastery today.
Next Steps
Ready to advance your data career? Learning R programming is a great place to start. Companies are looking for skills in data manipulation, visualization, and machine learning - and R is a powerful tool for learning all of those skills.
So how do you get started with R? Follow these steps:
- First, install R or start using it on positCloud and get comfortable with the fundamentals, such as syntax and data structures.
- Second, move on to more advanced topics like statistical modeling and machine learning, following along with R for Data Science.
- Finally, consider using a structured learning resource, like Dataquest's Data Analyst in R path, to guide your progress.
So if you're ready to boost your data skills, why not start learning R today? With the right tools and mindset, there's no limit to what you can achieve.