Tutorial: Demystifying Functions in Python
Progressing through the data science journey means encountering and dealing with increasingly complex tasks. In order to do this, you’ll need something that will “take in” data, process it in some manner, and then return some output. We can accomplish this multi-phasic process by using functions.
What are functions?
In the event that you would ever need to impress your job interviewer, the best way to summarize a function is a “self-contained block of code comprised of related statements used to accomplish some specific tasks.” Within Python, these functions exist as one of three types:
- Built-in function that are native to the Python language
- User-defined functions that are specific within the context wherein they’re being used and the data that they act on
- Lambda functions, which are non-defined and used within a short-term period (i.e., cannot be used outside a singular instance)
We’ll break down each of these types below. But before all of that, it’s necessary to ask the important question.
Why use functions?
Functions are highly valued for many reasons. First and foremost, using functions mainly enables you to avoid replicating a particular segment of code that you would often use across multiple locations within your application. Sure, you can just do the copy and paste route, but if you need to modify that segment of code at any point, you would have to repeat that process for each instance.
This saves times and eliminates potential bugs or errors. Plus, if you are working in a collaborative element, it means avoiding any messy or convoluted code.
(a)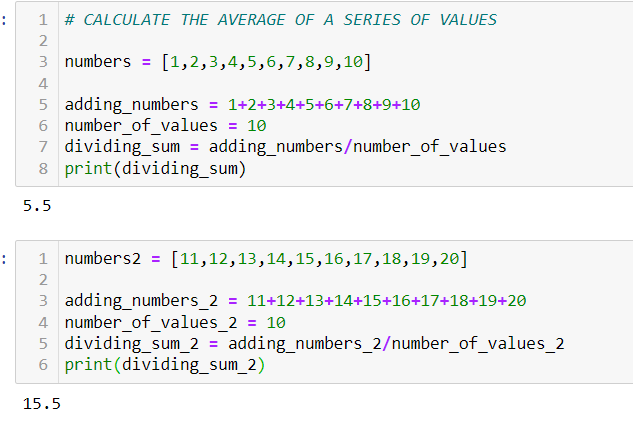
(b)
“Much better to do something where you can do less to achieve the same result ”
Aside from reducing the redundancy of a segment of code, it also enables us to be modular (i.e., breaking up complex processes into individual steps) when conceptualizing and processing complex tasks. Intuitively, we do this in everyday life (say, preparing for a big dinner party) where we break down the necessary tasks for the event into all of the necessary steps. This makes things easier for us to plan, scale, and debug.

(From Pexel by Andrea Piacquadio)
How do functions work in Python?
In this instance, we’ll be speaking about user-defined functions. At the most fundamental level, this involves several components:

| COMPONENTS | DESCRIPTION |
|---|---|
| def function name parameter(s) argument(s) : statement(s)* | The keyword that informs Python that you’re defining a function What you’re calling the function that satisfies the naming conventions in Python Optional inputs passed into the function that modulate how the function acts on the arguments Values assigned to a parameter when passed into a function Punctuation that denotes the end of the function header A block of statements that will execute the function whenever it is called |
*Statements make up the body of the function as signified by indentation Here’s is a quick example of how we can define a function
NOTE: As a matter of good practice, when creating a user-defined function, apply a document string to explain what this function does.
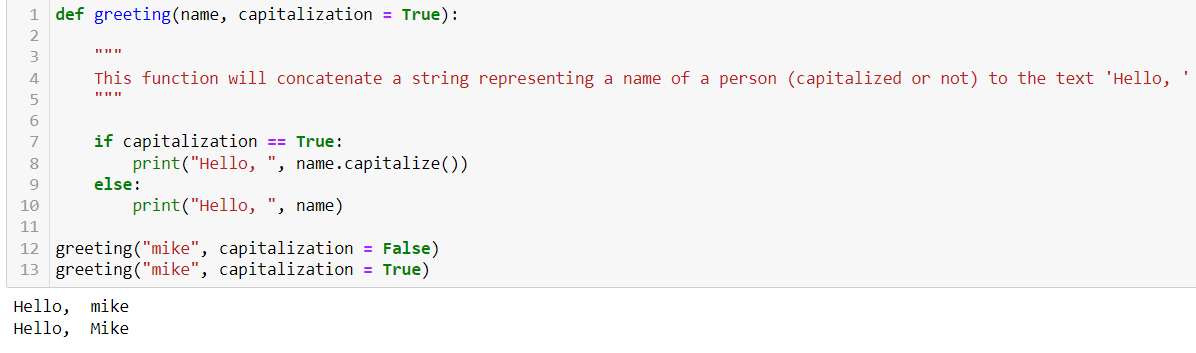
In this case, the first line uses the “def” keyword to indicate to Python that a new function (greeting) is being defined that takes in an argument (name), as well as a parameter (capitalization). The subsequent line that is indented signifies the body of the function, which executes the task. Here, we see that the parameter modulates this execution such that if it is true, it will print out a string with the capitalize method applied to the argument. Otherwise, it doesn’t. Also, in the case above, we have a default value attached to the capitalization parameter where it is normally set as True, unless otherwise stated.
By default, a function must be called with the correct number of arguments. That means that if a function expects some number of argument inputs to make it work, then you will need that number of arguments. Otherwise, you’ll get something like this:
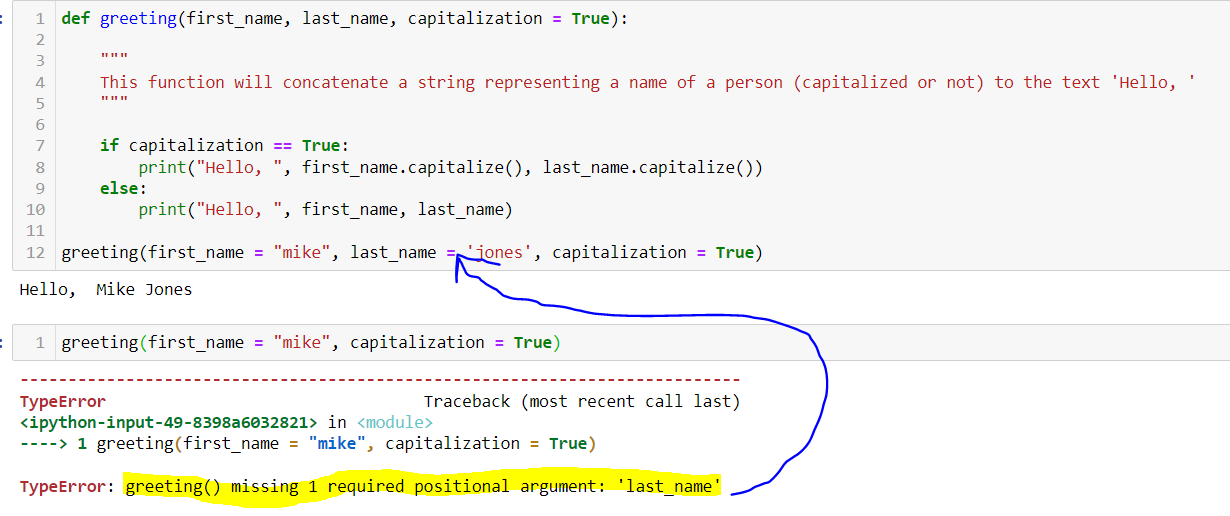
Sometimes, when planning what you would like the function to do, you may not be sure what the output should be. In these cases, it may be useful to run the function but produce no output or no error message. For this to work, we use the pass statement as shown below:

Another situation when we may need to apply this is when there is a condition that needs to be made for a particular output — we can use the pass statement as well.

In either of the scenarios above, we had an output that returns a printed value. Sometimes, we may just need to return the value for use within another context (say, funneling into another function). In that case, we can use return instead. Here the return statement serves two purposes:
- It immediately terminates the function and passes execution control back to caller
- It provides a mechanism for the function to pass data back to the caller
Now since the return statement can terminate a function, we can apply it in situations when we check for potential errors whereupon meeting that condition, we return back some kind of output indicating a fault.
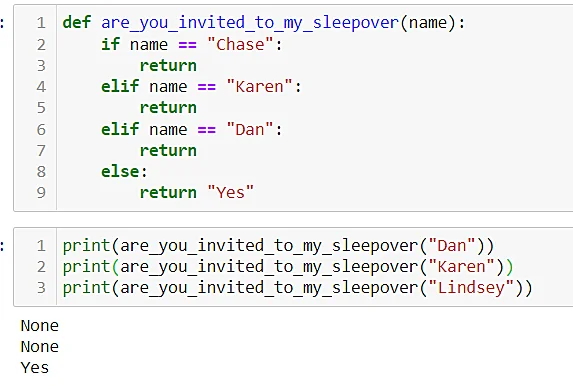
Interestingly with functions, we can have the defined function call itself, which enables looping through the data. However, this should be done carefully as it’s possible to create a function that can never terminate if not done properly.
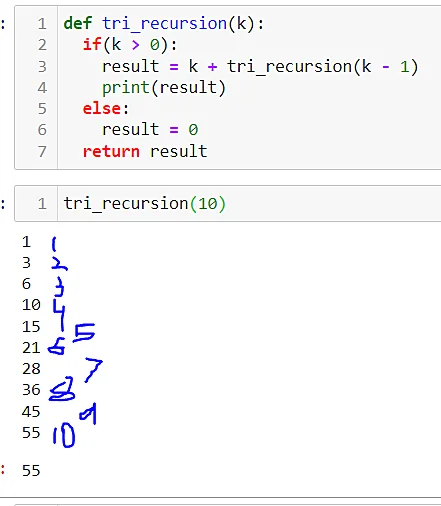
Notice how the function will continue on incorporating itself with the subsequent value until the last input.
About arguments
Just as there are different types of functions, there are two major types of arguments: keyword arguments and positional arguments. In the case above, the values inputted into the function are identifiable by a specific name (first_name, last_name) which are keyword arguments. With keyword arguments, It doesn’t matter where keyword arguments appear within the function since it’s already “mapped out” with the specific name.

Here are three ways to write out a function that all yield the same output.
The other type of argument is a positional argument, which is a value passed into a function based on the order in which the parameters were listed during the function definition. Here, these arguments are not defined as shown above; rather, they are inputted into the function and operated corresponding to the parameters laid out in the function.

Notice how without identifying which value is for what, we’ll see a default to whatever is laid out in the function.
So far, we’ve been dealing with fixed arguments (i.e., advance knowledge of the number of arguments that are inputted into a function). However, there will be instances when we might not be sure about which arguments to add. In some cases, these may be more than what was previously set. So, to resolve this, we can use arbitrary arguments, which are non-defined values passed into the function to be acted on. To indicate these kinds of arguments, we add a “” before the parameter (args for non-keyword/positional arguments; *kwargs for keyword arguments).

What are built-in functions?
As with any other programming language, there are a set of functions built into the Python language that perform common tasks relating to manipulating data — or to build other functions to perform more complex tasks such as those found within certain modules. There are a number of these functions, which you can explore here and here.

What are lambda functions?
So, lambda functions (also known as anonymous functions) aren’t so different from what we’ve talked about so far, in that they perform an expression for a given argument. The only big difference is that, unlike user-defined functions, these are not defined (i.e., there’s no specific name associated with this function).

Notice how the user-defined function uses the “def” as the keyword as opposed to the anonymous that uses
In the case above, we see that the argument (x) is evaluated and returned once it passes through the lambda function. This isn’t much different than a user-defined function that takes in the argument (name). However, this function isn’t really designed to be used more than once because there’s no way to call it back again.
Now you might be thinking to yourself, “Why not just use user-defined functions all the time?” While you certainly can do so, it creates inefficient coding wherein single-use functions could really make things difficult to read — and unnecessarily long. The idea is to try to make things as efficient as possible. With anonymous functions, you can substitute that need when performing simple logical operations such as what’s shown above when you know that the output would just be concatenating the x argument to the end of a string.
For instance, we can simply apply a lambda function to a single value like this:

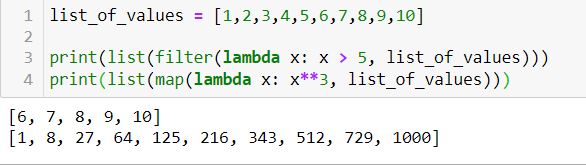
Alternatively, we can apply it to a list of values with some of python’s built-in functions like filter() or map(), like this:
We typically see these lambda functions used with series objects or DataFrames. For example, let’s say we have a list of several top draft prospects for the upcoming NFL Draft:


Bonus points if you get the reference
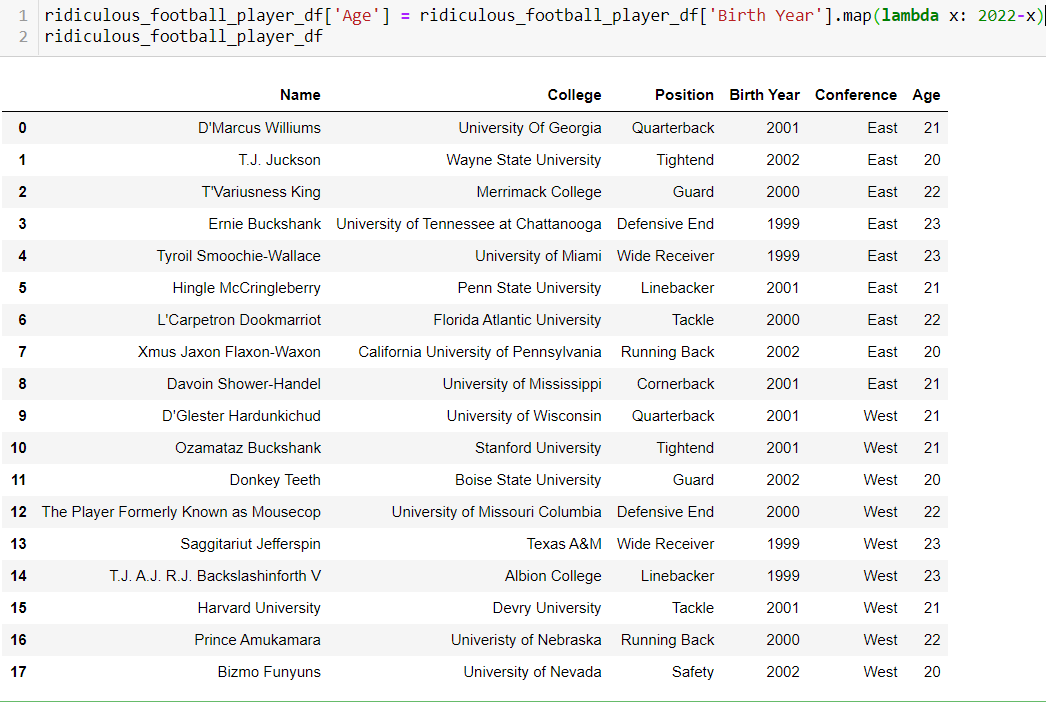
Say we would like to apply a function that would calculate the age of each of the draft prospects; we can simply use the apply() function or map() function:
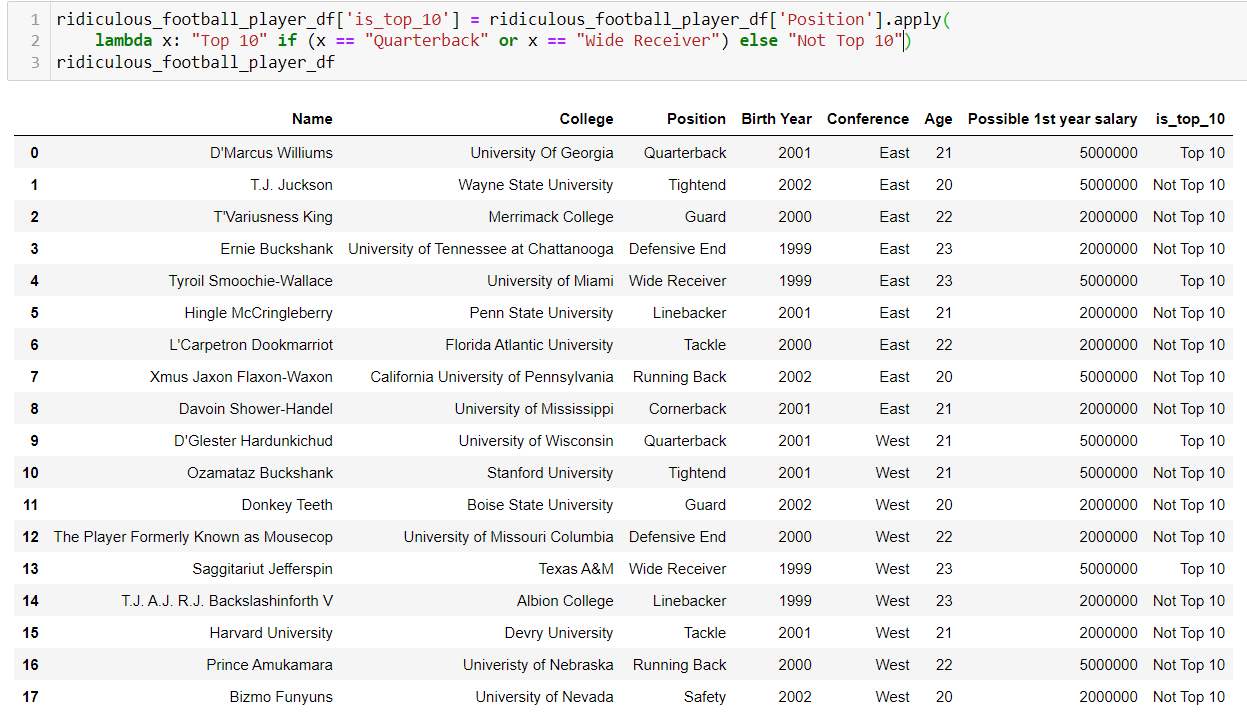
Alternatively, we can also apply lambda functions in situations when there is a conditional element. For instance, say we would like to establish projected first-year salaries for skill-based and non-skill-based positions (i.e., quarterbacks, wide receivers, running backs, and tight ends). We can use if/else statements in conjunction with the lambda function:

These examples of lambda functions are what would be typically considered as “sound” use of these functions. However, there are instances when we could use lambda functions but are generally discouraged from doing so due to stylistic reasons.
-
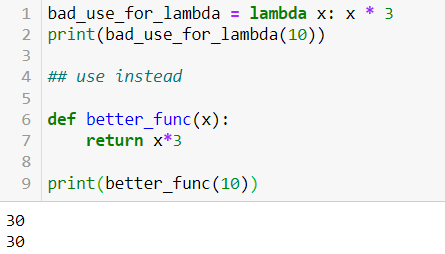
Applying a name to a lambda function, since this would enable reusability to a given function. Since lambda functions are typically for one-time use, a more apt use would be to create a user-defined function instead.
-
Having multiple lines of code corresponding to a lambda function — this can make things overly complicated and difficult to read, which can become problematic whenever a modification or correction becomes necessary.
Simplifying your code by eliminating repetitive input of large chunks of code makes it easier to read and interpret. While there are various built-in functions within the Python language and other modules, it’s also possible to create our own for a given task that we can define or leave undefined. Making these can be fairly simple or complex, depending on the task at hand.
Each function has its pros and cons, and understanding how and when to apply each will carry you further along the data science path. If you would like to know more within a hands-on context, check out the function module at Dataquest.
