SQL Aggregate Functions: Selecting Ungrouped Columns

When is a SQL query that returns the correct answer actually wrong? In this article, we're going to take a close look at a very common mistake with SQL aggregate functions. It's one that will actually return the right answer, but it's still a mistake that's important to avoid.
That probably sounds rather mysterious, so let's dive right in. We'll illustrate the SQL mistake you might not even know you're making, and highlight how to approach the problem correctly.
For a structured learning experience, check out our Complete SQL Guide for Beginners.
The Problem: Right Answer, But Wrong SQL Query
At Dataquest, one of our favorite databases to teach SQL with is Chinook — a database of the records of a fictitious online music store. In one of the courses that we use it, learners are challenged to find the customer from each country who has spent the most money.
They often end up creating the following CTE. It contains a row per customer with their name, country, and total amount spent:
| country | customer_name | total_purchased |
|---|---|---|
| Argentina | Diego Gutiérrez | 39.6 |
| Australia | Mark Taylor | 81.18 |
| Austria | Astrid Gruber | 69.3 |
| Belgium | Daan Peeters | 60.39 |
| Brazil | Luís Gonçalves | 108.9 |
| Canada | François Tremblay | 99.99 |
| Chile | Luis Rojas | 97.02 |
| Czech Republic | František Wichterlová | 144.54 |
| Denmark | Kara Nielsen | 37.62 |
| Finland | Terhi Hämäläinen | 79.2 |
| France | Wyatt Girard | 99.99 |
| Germany | Fynn Zimmermann | 94.05 |
| Hungary | Ladislav Kovács | 78.21 |
| India | Manoj Pareek | 111.87 |
| Ireland | Hugh O’Reilly | 114.84 |
| Italy | Lucas Mancini | 50.49 |
| Netherlands | Johannes Van der Berg | 65.34 |
| Norway | Bjørn Hansen | 72.27 |
| Poland | Stanisław Wójcik | 76.23 |
| Portugal | João Fernandes | 102.96 |
| Spain | Enrique Muñoz | 98.01 |
| Sweden | Joakim Johansson | 75.24 |
| USA | Jack Smith | 98.01 |
| United Kingdom | Phil Hughes | 98.01 |
We’ll call this CTE customer_country_purchases.
Generally, they're getting to that output — which is correct — using this query:
SELECT country, customer_name,
MAX(total_purchased)
FROM customer_country_purchases
GROUP BY country;In English: select the country, the maximum amount spent for that country, and include the customer’s name.
This is a very natural try, and it yields correct output! However, as you may have expected from my wording, there’s more than meets the eye in this solution.
What's Wrong With That?
The goal of this post is to clarify what is objectionable about the approach above. To make it easier to visualize what’s going on, we’ll drop Chinook, and work with a smaller table. We’ll be using the elite_agent table.
(This is also a fictional database; think of it as a table of secret agents by city, gender, and age).
| id | city | gender | age |
| 1 | Lisbon | M | 21 |
| 2 | Chicago | F | 20 |
| 3 | New York | F | 20 |
| 4 | Chicago | M | 27 |
| 5 | Lisbon | F | 27 |
| 6 | Lisbon | M | 19 |
| 7 | Lisbon | F | 23 |
| 8 | Chicago | F | 24 |
| 9 | Chicago | M | 21 |
If you wish to experiment with it, here's a SQLite database with this table.
If we compare this table to the Chinook table we were using, we can see that they're very similar in terms of how we'll handle the data in each column:
countryin the Chinook database is similar to citynameis similar to gendertotal_purchasedis similar to age
Given that, we can structure a query for this new table that's essentially the same as the problematic query we were looking at with Chinook:
SELECT city, gender,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;Code-wise, the queries are equivalent.
So what’s so wrong with them? Let’s start answering this question.
Presumably, this query’s goal is to determine the ages of the oldest agents. If we didn’t want the names, we would run the query below.
SELECT city,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;Here is the output using the SQLite engine:
| city | max_age |
|---|---|
| Chicago | 27 |
| Lisbon | 27 |
| New York | 20 |
Because we grouped by city, each row represents a city. We also included the maximum age for each group.
If we include the gender, we'll reproduce the first query we saw for this table — the one that is incorrect.
Why does including gender in this query matter? Our results are a row per group — in this case, a row per city. Cities don’t have genders, so we could argue it is not meaningful at a conceptual level to include the gender in this query.
But that's not the actual problem here.
The "Bare Columns" Problem
We’ll call columns/expressions that are in SELECT without being in an aggregate function, nor in GROUP BY , barecolumns. In other words, if our results include a column that we're not grouping by and we're also not performing any kind of aggregation or calculation on it, that's a bare column.
In the above query, gender will produce a bare column — we're not grouping by gender, and we're not doing any sort of aggregation of gender data. The gender data point here is essentially "just along for the ride."
Now, in our course, we’re using SQLite, and this is also very common in real-world work. Even though bare columns don't add meaning to the query, SQLite does allow them to exist:
SELECT city, gender,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;| city | gender | max_age |
|---|---|---|
| Chicago | M | 27 |
| Lisbon | F | 27 |
| New York | F | 20 |
Presented with these results, one could potentially argue that the query is meaningful by saying that including the gender means including the gender of the agent whose age equals max_age.
But that defense crumbles when, instead of the maximum age, we compute a statistic like the mean:
SELECT city, gender,
AVG(age) AS mean_age
FROM elite_agent
GROUP BY city;| city | gender | mean_age |
|---|---|---|
| Chicago | M | 23.0 |
| Lisbon | F | 22.5 |
| New York | F | 20.0 |
Here, we see a city, the mean age of agents in that city, and a gender. But what does this gender column mean?
Inspecting the table, we see that for each of the given cities, there is no agent whose age equals the mean for their city. In this case, the output is complete nonsense.
Even if there were any agents whose age equaled the mean, that wouldn’t make the output correct.
We can also see that this isn’t correct in the world of pivot tables in spreadsheets.
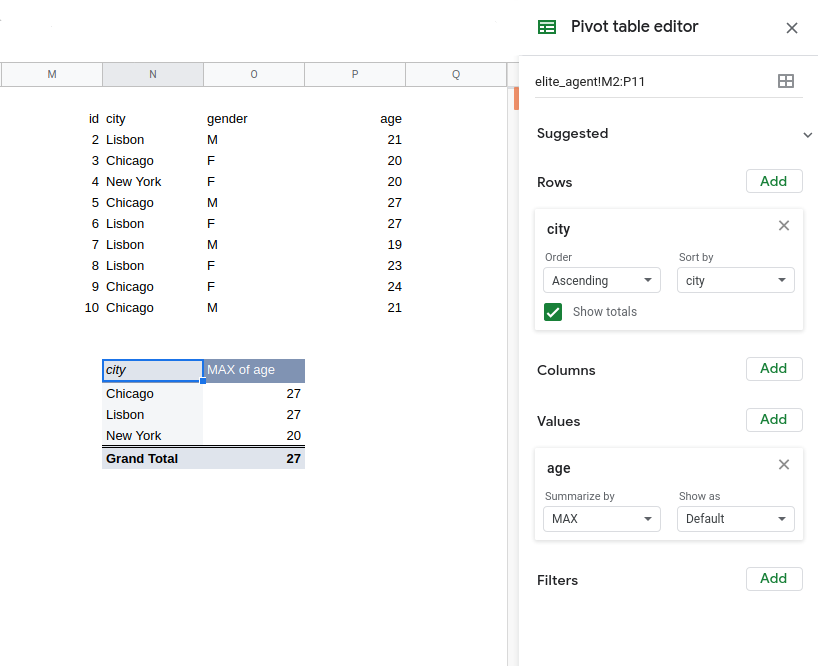
In the pivot table above, if we include gender as a value, we’re forced to choose an aggregate function, and if we include it as a row, we get the following table instead:
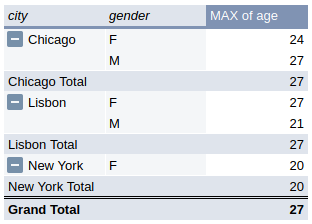
It created a group for every existing combination of city and gender, which isn’t what we wanted.
Why is it, then, that the query below worked fine?
SELECT city, gender,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;This query worked (i.e., it output the correct result) because of a special feature in SQLite. From the documentation:
When the min() or max() aggregate functions are used in an aggregate query, all bare columns in the result set take values from the input row which also contains the minimum or maximum
Avoid Bare Columns in SQL Queries
While SQLite handles the problem in this manner and thus outputs a correct result despite including the bare column, this behavior isn’t standardized across different databases. Thus, we should take care if we decide to rely on it — running the same query on something other than SQLite might produce a different result.
And more broadly, it's established SQL convention: Queries shouldn’t have bare columns. This convention was introduced in SQL:1999 — a set of rules about how SQL should work. From this standard:
In addition, when a
SELECTstatement includesGROUP BY, the statement’s select list may consist only of references to Columns that are single-valued per group – this means that the select list can’t include a reference to an interim result Column that isn’t also included in theGROUP BYclause unless that Column is an argument for one of the set functions (AVG,COUNT,MAX,MIN,SUM,EVERY,ANY,SOME; each of which reduce the collection of values from a Column to a single value).
Avoiding bare columns has the following benefits:
- It allows for code to be portable to other databases. Some SQL engines won’t accept bare columns as a valid query. Those that do run it may exhibit unexpected behavior.
- It makes code more readable: someone who doesn’t have experience with SQLite will have an easier time understanding the code if bare columns aren’t used.
- It makes the code more intuitive — as we saw above, bare columns are often meaningless, so including them can make the data harder to interpret.
The first point may be the most important. T-SQL, for instance, yields the following error for the same query:
Column 'elite_agent.gender' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
Similarly, Postgres will give us ERROR: column "elite_agent.gender" must appear in the GROUP BY clause or be used in an aggregate function Position: 14.
Finally, Oracle gives us ORA-00979: not a GROUP BY expression.
This error message isn’t particularly informative, but the documentation gives us this:
The GROUP BY clause does not contain all the expressions in the SELECT clause. SELECT expressions that are not included in a group function, such as AVG, COUNT, MAX, MIN, SUM, STDDEV, or VARIANCE, must be listed in the GROUP BY clause.
MySQL is another good example of the first point above, as its results with this sort of query aren’t consistently the same (contrary to SQLite). Another one is SAS which repeats the gender value for each result:
| city | gender | age |
|---|---|---|
| Chicago | F | 23.0 |
| Chicago | M | 23.0 |
| Lisbon | F | 22.5 |
| Lisbon | M | 22.5 |
| New York | F | 20.0 |
How Do We Fix It?
Let’s return to our initial query and review why it's problematic even though it does produce the correct output (at least when using SQLite):
SELECT country, customer_name,
MAX(total_purchased)
FROM customer_country_purchases
GROUP BY country;We can now make the following observations:
- It doesn’t make sense to include
customer_namewhen each row (group) represents a country. - This solution is ultimately technically correct, but that’s only because SQLite handles queries like these differently from what is standard.
- The main takeaway is: queries employing a
GROUP BYclause shouldn’t have bare columns.
After all this, we still haven’t provided a proper way to solve this problem. One way to do it can be strategically broken down like this:
- Create a table that finds the maximum amount spent on each country.
- Join
customer_country_purchaseswith the table created above on the amount columns.
SELECT ccp.country,
ccp.customer_name,
ccp.total_purchases AS total_purchased
FROM customer_country_purchases AS ccp
INNER JOIN (SELECT country,
MAX(total_purchases) AS max_purchase
FROM customer_country_purchases
GROUP BY 1) AS cmp
ON ccp.country = cmp.country
AND ccp.total_purchases = cmp.max_purchase
ORDER BY ccp.country;
A complete solution to the exercise can be found in this post in the community. Although the solution was written by the author of this blog post, the main ideas were suggested by one of our learners!
Another resource you may find helpful: our SQL cheat sheet, available online and as a downloadable PDF.